文章目录
-
- 1.环境准备
-
- [1.1 基础环境要求](#1.1 基础环境要求)
- [1.2 安装PostgreSQL](#1.2 安装PostgreSQL)
- [2.1 修改PostgreSQL主配置文件](#2.1 修改PostgreSQL主配置文件)
- [2.2 修改客户端认证配置文件](#2.2 修改客户端认证配置文件)
- [2.3 创建复制专用用户](#2.3 创建复制专用用户)
- [2.4 重启主库使配置生效](#2.4 重启主库使配置生效)
- [2.5 备份主库数据(供从库初始化)](#2.5 备份主库数据(供从库初始化))
- 3.从库配置
-
- [3.1 停止从库PostgreSQL服务并清理原有数据目录](#3.1 停止从库PostgreSQL服务并清理原有数据目录)
- [3.2 解压主库备份到从库数据目录](#3.2 解压主库备份到从库数据目录)
- [3.3 验证 / 修改从库复制配置](#3.3 验证 / 修改从库复制配置)
- [3.4 启动从库服务](#3.4 启动从库服务)
- 4.验证主从复制是否生效
-
- [4.1 主库验证复制状态](#4.1 主库验证复制状态)
- [4.2 从库验证复制状态](#4.2 从库验证复制状态)
- [4.3 验证主从数据一致性](#4.3 验证主从数据一致性)
- 5.主从复制常用操作
-
- [5.1 切换主从(故障转移,简易版)](#5.1 切换主从(故障转移,简易版))
- [5.2 监控复制延迟](#5.2 监控复制延迟)
- 5.3新增从库
- [5.4 拓展](#5.4 拓展)
- 6.实现随时随地开发
-
- [6.1 它是什么?](#6.1 它是什么?)
- [6.2 部署](#6.2 部署)
- 7.配置公网地址
- 8.保留固定TCP公网地址
- 总结

之前做运维时遇到过这么一件事:凌晨三点,数据库服务器突然宕机,业务直接停摆。值班电话一个接一个,翻箱倒柜找备用方案,结果发现根本没有------就一台单机 PostgreSQL,挂了就是挂了。
那时候最痛苦的是:每次做数据备份都要手动停库,恢复时间以小时计;监控报警了还得 SSH 登录查日志;最怕的是主库挂了之后,从库还傻乎乎等着指令。量化一下痛点:一次宕机损失至少 2 小时业务时间,数据恢复要 30 分钟到 1 小时,而且还得人工介入。
后来换了 PostgreSQL 主从复制,情况变了。
主库挂了可以直接从库切换,业务中断时间从小时级缩短到分钟级;自动同步保证数据不丢失;监控一看就知道同不同步、延迟多少。最核心的改变就是:不再把鸡蛋放在一个篮子里,也不再半夜被电话叫醒修数据库。
如果你也经历过单点故障的痛,或者正在考虑给数据库做高可用,下面这套方案可以直接用。
本文将摒弃空泛理论,以CentOS/Ubuntu 环境下的PostgreSQL 14为例,手把手带你完成从零搭建、配置调优到故障演练的完整流程。无论你是DevOps工程师、DBA,还是希望提升系统容灾能力的开发者,都能通过本指南,真正掌握PostgreSQL高可用的核心实践。
让数据多一份副本,让服务少一分风险。
从今天起,告别单点故障,构建属于你的高可用数据库基石。

1.环境准备
1.1 基础环境要求
| 节点类型 | 服务器地址 | 系统版本 | PostgreSQL 版本 | 核心要求 |
|---|---|---|---|---|
| 主库(Master) | 192.168.42.140(示例) |
CentOS 7/8/9或Ubuntu 20.04+ | 14 | 开启网络端口、关闭防火墙 / 放行5432端口 |
| 从库(Slave/Standby) | 192.168.42.145(示例) |
与主库一致 | 与主库完全一致 | 与主库网络互通、磁盘空间不小于主库 |
1.2 安装PostgreSQL
还没安装PostgreSQL的小伙伴可以去cpolar官网参考《谁说没公网IP不能远程连数据库?PostgreSQL+cpolar打通任督二脉》这篇文章哦~
2.1 修改PostgreSQL主配置文件
主配置文件路径:/var/lib/pgsql/14/data/postgresql.conf
shell
vim /var/lib/pgsql/14/data/postgresql.conf修改以下核心参数(取消注释并调整值):
shell
# 1. 监听地址(允许从库连接,可指定从库IP或0.0.0.0允许所有)
listen_addresses = '*'
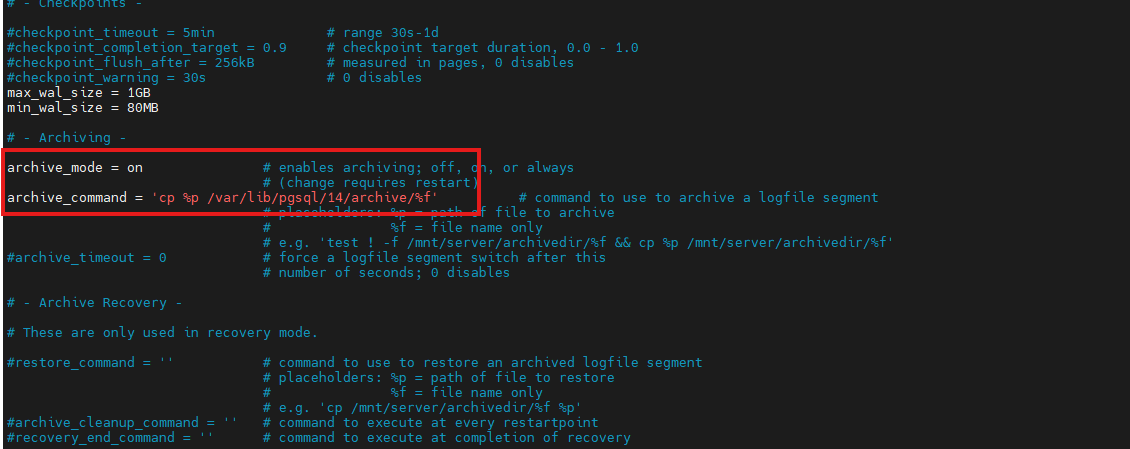
# 2. 开启归档模式(主从复制依赖)
archive_mode = on
archive_command = 'cp %p /var/lib/pgsql/14/archive/%f' # %p=归档文件路径,%f=归档文件名
# 提前创建归档目录
mkdir -p /var/lib/pgsql/14/archive && chown -R postgres:postgres /var/lib/pgsql/14/archive
# 3. WAL日志配置(保证复制可靠性)
wal_level = replica # 复制所需的WAL级别(replica/archive/logical,replica足够)
wal_buffers = 16MB # 根据内存调整,默认通常足够
max_wal_senders = 10 # 最大并发复制连接数,大于从库数量即可
wal_keep_size = 1GB # 保留WAL日志的大小,防止从库同步滞后导致日志被清理
# 4. 同步模式(可选,按需配置)
# synchronous_commit = on # 默认同步提交,保证主从数据一致性;追求性能可设为off
# synchronous_standby_names = 'slave1' # 指定从库名称(需与从库recovery.conf对应)
# 5. 其他优化(可选)
max_connections = 1000 # 大于从库的max_connections
2.2 修改客户端认证配置文件
文件路径:/var/lib/pgsql/14/data/pg_hba.conf
bash
vim /var/lib/pgsql/14/data/pg_hba.conf添加从库的连接授权(允许从库 IP 通过复制用户连接):
shell
host replication repl_user 192.168.42.145/32 md5 # 从库IP,repl_user为复制专用用户
host all all 192.168.42.0/24 md5 # 可选,允许内网其他机器连接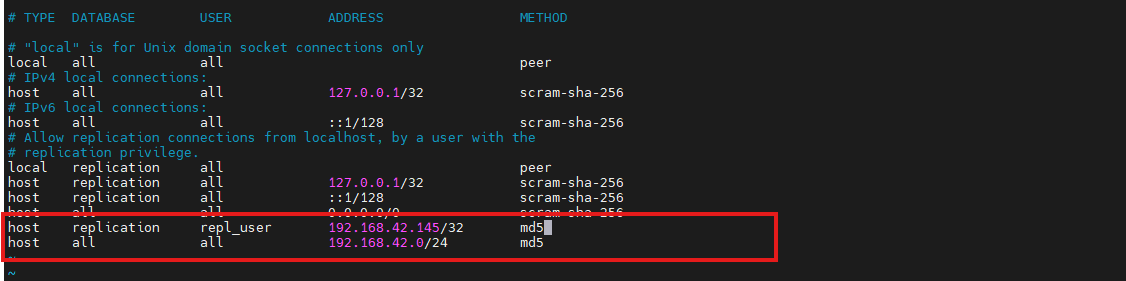
2.3 创建复制专用用户
切换到postgres用户,执行 SQL 命令创建用于主从复制的专用用户(需授予复制权限):
shell
su - postgres
psql执行SQL:
shell
-- 创建复制用户(密码自定义,示例:Repl@123456)
CREATE ROLE repl_user WITH REPLICATION LOGIN ENCRYPTED PASSWORD '********';
-- 验证用户(可选)
\du repl_user;
-- 退出psql
\q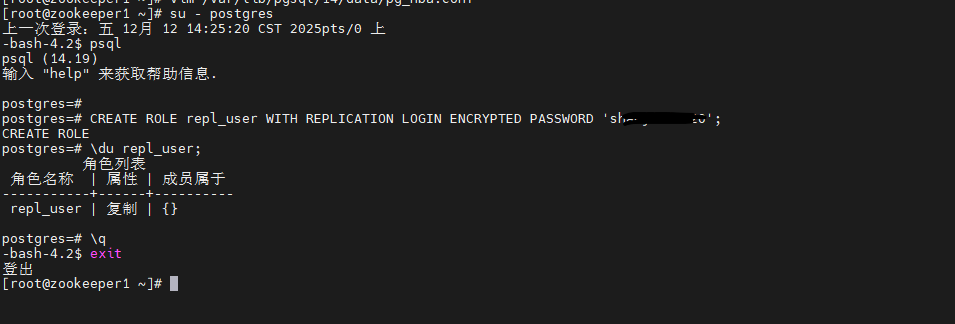
2.4 重启主库使配置生效
shell
systemctl restart postgresql-14
systemctl status postgresql-14
sudo -u postgres psql -c "SELECT pg_is_in_recovery();" # 主库返回f(非恢复模式)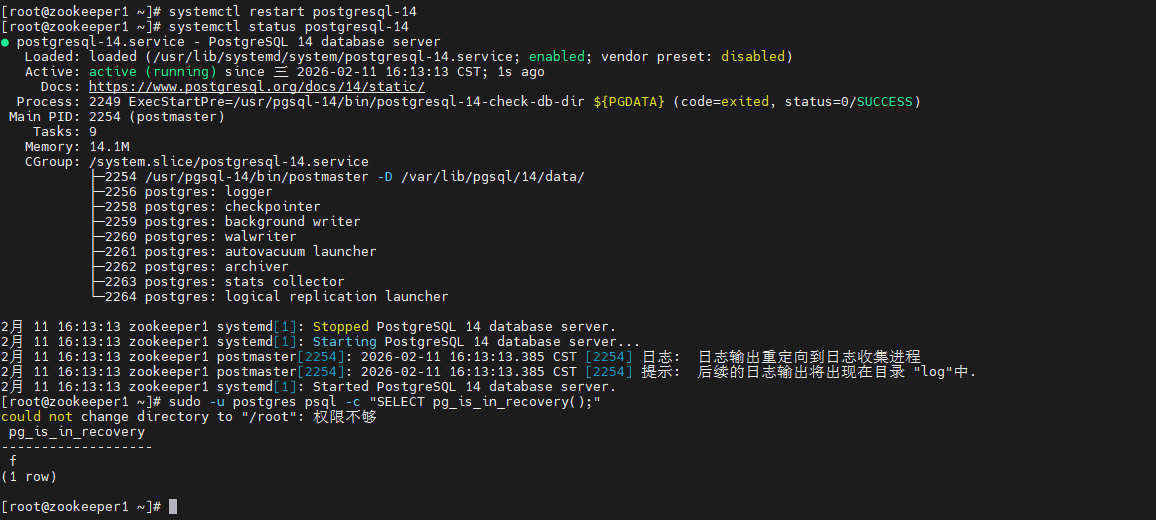
2.5 备份主库数据(供从库初始化)
使用pg_basebackup工具备份主库数据,该工具专门用于PostgreSQL复制环境的从库初始化:
shell
# 切换到postgres用户
su - postgres
# 执行备份(备份到临时目录,后续拷贝到从库)
pg_basebackup -h 192.168.42.140 -U repl_user -p 5432 -D /tmp/pg_master_backup -F p -X s -P -R
# 参数说明:
# -h:主库地址
# -U:复制用户
# -p:主库端口
# -D:备份目录
# -F p:输出格式为普通文件(与主库数据目录结构一致)
# -X s:备份过程中同步复制WAL日志,保证备份一致性
# -P:显示备份进度
# -R:自动生成复制所需的standby.signal文件和postgresql.auto.conf配置,简化从库配置
备份完成后,将备份目录打包拷贝到从库的/var/lib/pgsql/14/目录下(可通过 scp 传输):
shell
tar -zcvf pg_master_backup.tar.gz /tmp/pg_master_backup # 主库上打包备份
scp pg_master_backup.tar.gz root@192.168.1.101:/var/lib/pgsql/14 # 传输到从库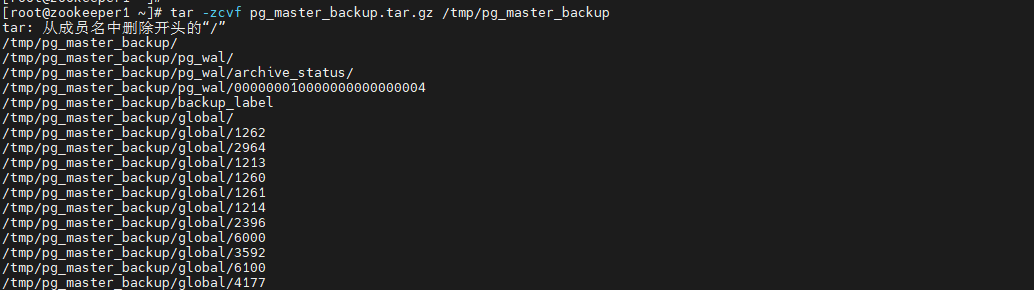

到从库所在地址查看一下是否传送成功到/var/lib/pgsql/14:

3.从库配置
3.1 停止从库PostgreSQL服务并清理原有数据目录
shell
# 停止从库服务
systemctl stop postgresql-14
# 清理原有数据目录(初始化后的空目录,需替换为主库备份)
mv /var/lib/pgsql/14/data /var/lib/pgsql/14/data_bak # 备份原有目录,防止误删
mkdir -p /var/lib/pgsql/14/data
3.2 解压主库备份到从库数据目录
shell
# 切换到postgres用户
su - postgres
# 解压备份包
tar -zxvf /var/lib/pgsql/14/pg_master_backup.tar.gz -C /var/lib/pgsql/14/
# 移动备份数据到data目录
mv /var/lib/pgsql/14/tmp/pg_master_backup/* /var/lib/pgsql/14/data/
# 修改目录权限(必须为postgres用户和组)
chown -R postgres:postgres /var/lib/pgsql/14/data
chmod 700 /var/lib/pgsql/14/data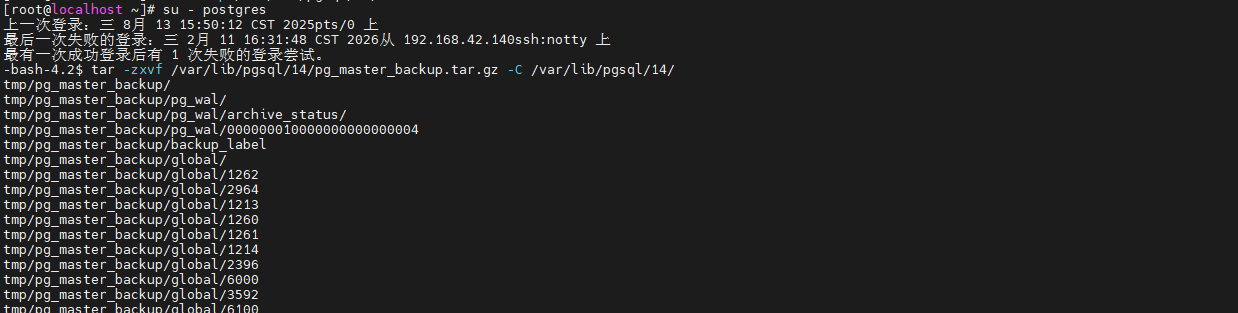

3.3 验证 / 修改从库复制配置
由于主库备份时使用了-R参数,会自动生成standby.signal(标识从库身份)和postgresql.auto.conf(包含复制连接信息),无需手动创建:
shell
# 查看自动生成的复制配置
cat /var/lib/pgsql/14/data/postgresql.auto.conf
ls /var/lib/pgsql/14/data/
若没有,则手动创建standby.signal并修改postgresql.conf:
shell
# 手动创建standby.signal(标识为从库)
touch /var/lib/pgsql/14/data/standby.signal
# 编辑postgresql.conf,添加复制配置,添加以下参数:
vim /var/lib/pgsql/14/data/postgresql.conf
# 从库专属配置
hot_standby = on # 允许从库处于恢复模式时提供查询服务(只读)
max_connections = 500 # 小于主库的max_connections
primary_conninfo = 'user=repl_user password=Repl@123456 host=192.168.42.140 port=5432' # 主库连接信息3.4 启动从库服务
shell
# 启动从库
systemctl start postgresql-14
systemctl enable postgresql-14
# 验证从库状态
systemctl status postgresql-144.验证主从复制是否生效
4.1 主库验证复制状态
shell
su - postgres
psql
# 查看复制连接状态(可看到从库的连接信息)
SELECT * FROM pg_stat_replication;
# 输出说明:
# - usename:repl_user(复制用户)
# - client_addr:192.168.1.101(从库IP)
# - state:streaming(表示正在流式复制)
# - sync_state:async(异步复制)或 sync(同步复制,需主库配置synchronous_commit=on)
从提供的pg_stat_replication查询结果来看,PostgreSQL主从复制已经成功建立,并且处于正常运行状态。这是一个非常关键的监控视图,用于查看 主库上的复制连接状态。
4.2 从库验证复制状态
shell
su - postgres
psql
# 1. 验证是否处于恢复模式(从库返回t,主库返回f)
SELECT pg_is_in_recovery();
4.3 验证主从数据一致性
shell
# 主库创建测试表并插入数据
# 主库执行:
CREATE DATABASE test_repl;
\c test_repl;
CREATE TABLE user_info (id int, name varchar(50));
INSERT INTO user_info VALUES (1, 'test_replication');
# 从库执行(查看是否同步到数据)
\c test_repl;
SELECT * FROM user_info; 主库:

从库:

从上图我们可以看出,主从复制成功啦!
5.主从复制常用操作
5.1 切换主从(故障转移,简易版)
当主库故障时,可将从库提升为主库:
shell
# 从库执行(停止恢复模式,提升为主库)
su - postgres
psql -c "SELECT pg_promote();"
# 验证:提升后从库pg_is_in_recovery()返回f
psql -c "SELECT pg_is_in_recovery();"5.2 监控复制延迟
shell
# 从库执行,查看复制延迟(单位:秒)
SELECT
now() - pg_last_xact_replay_timestamp() AS replication_delay;5.3新增从库
只需重复 "从库配置" 步骤,使用主库(或现有从库,需开启级联复制)的pg_basebackup备份初始化即可。
5.4 拓展
主从复制已经成功搭建,但我们的目标远不止于此。
回想一下,在开发、测试,甚至小型项目交付中,你是否也曾陷入这样的困境:
- "我在家搭了个PostgreSQL数据库,同事怎么连不上?"
- "客户急着看Demo,可服务跑在内网,根本没法访问!"
- "没有公网IP,难道只能租云服务器,或者干脆放弃远程演示?"
别焦虑------没有公网IP,并不意味着你的服务只能困在局域网里。借助一个轻量级但强大的内网穿透工具,你可以轻松将本地运行的PostgreSQL服务"暴露"到公网,自动生成一个安全、可分享的HTTPS隧道地址。无论你身处家庭宽带、公司防火墙后,还是校园网深处,外部用户都能像访问普通网站一样,通过标准端口安全连接你的数据库。本文将手把手带你完成这一过程:从零配置,到安全地将PostgreSQL服务映射至公网,打通内网与外部世界的连接通道。从此,"我的数据库在哪,服务就在哪" 不再是一句空话。准备好了吗?让我们开启这场高效、安全、低成本的"内网突围"之旅!
6.实现随时随地开发
6.1 它是什么?
它是一款安全高效的内网穿透工具,无需公网IP或复杂配置,只需一条命令,即可将本地服务器、Web服务或任意端口映射到公网,让你随时随地远程访问内网应用,特别适合开发调试、远程运维和应急部署等场景。
6.2 部署
它可以将你本地电脑中的服务(如 SSH、Web、数据库)映射到公网。即使你在家里或外出时,也可以通过公网地址连接回本地运行的开发环境。
❤️以下是安装步骤:
使用一键脚本安装命令:
shell
sudo curl https://get.cpolar.sh | sh
安装完成后,执行下方命令查看
shell
sudo systemctl status cpolar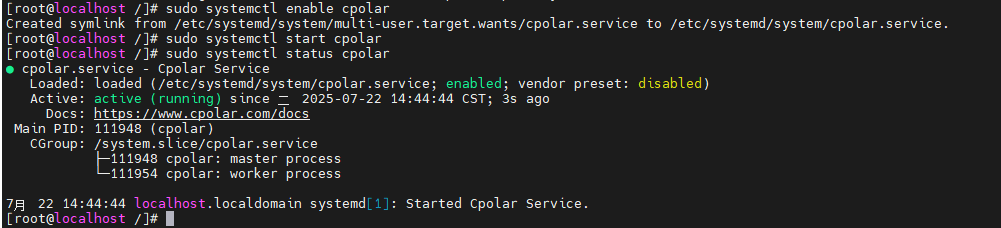
安装和成功启动服务后,在浏览器上输入虚拟机主机IP加9200端口即:http://localhost:9200访问管理界面,使用官网注册的账号登录,登录后即可看到web 配置界面,接下来在web 界面配置即可:
打开浏览器访问本地9200端口,使用账户密码登录即可,登录后即可对隧道进行管理。
7.配置公网地址
通过配置,你可以在本地 WSL 或 Linux 系统上运行 SSH 服务,并通过 它将其映射到公网,从而实现从任意设备远程连接开发环境的目的。
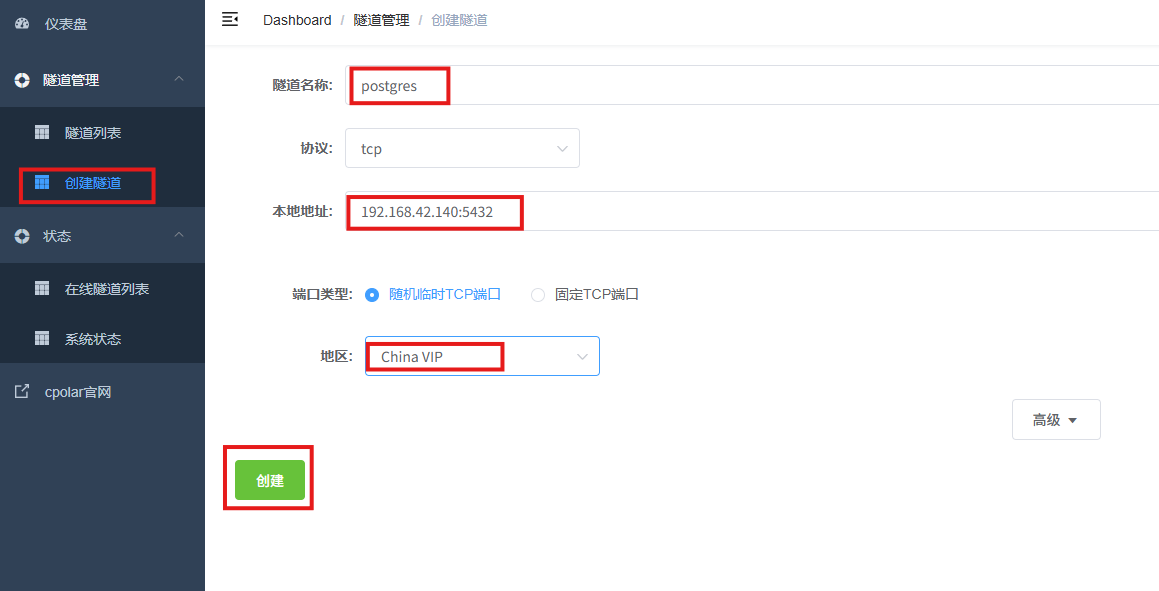
- 隧道名称:可自定义,本例使用了:postgres,注意不要与已有的隧道名称重复
- 协议:tcp
- 本地地址:192.168.42.140:5432
- 端口类型:随机临时TCP端口
- 地区:China Vip
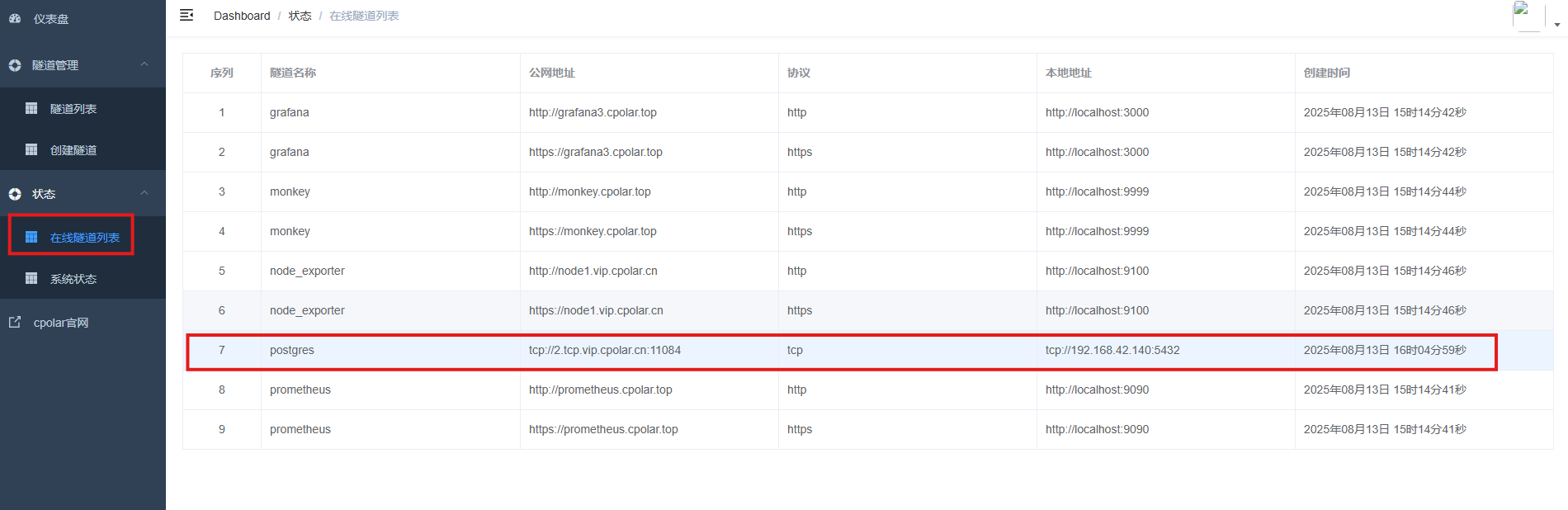
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了公网地址,接下来就可以在其他电脑或者移动端设备(异地)上,使用任意一个地址在终端中访问即可。
-
tcp 表示使用的协议类型
-
2.tcp.vip.cpolar.cn是 Cpolar 提供的域名
-
11084是随机分配的公网端口号
通过它提供的公网地址和端口,使用 SSH 协议从任意一台主机连接到postgres账号啦!
shell
psql -h 2.tcp.vip.cpolar.cn -p 11084 -U postgres -d mydb
8.保留固定TCP公网地址
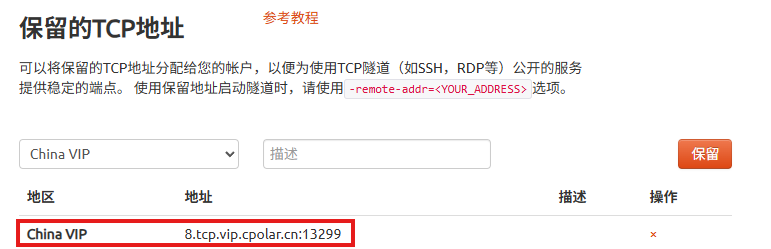
使用为其配置TCP地址,该地址为固定地址,不会随机变化。
选择区域和描述:有一个下拉菜单,当前选择的是"China VIP"。
右侧输入框,用于填写描述信息。
保留按钮:在右侧有一个橙色的"保留"按钮,点击该按钮可以保留所选的TCP地址。
列表中显示了一条已保留的TCP地址记录。
-
地区:显示为"China VIP"。
-
地址:显示为"8.tcp.vip.cpolar.cn:13299"。
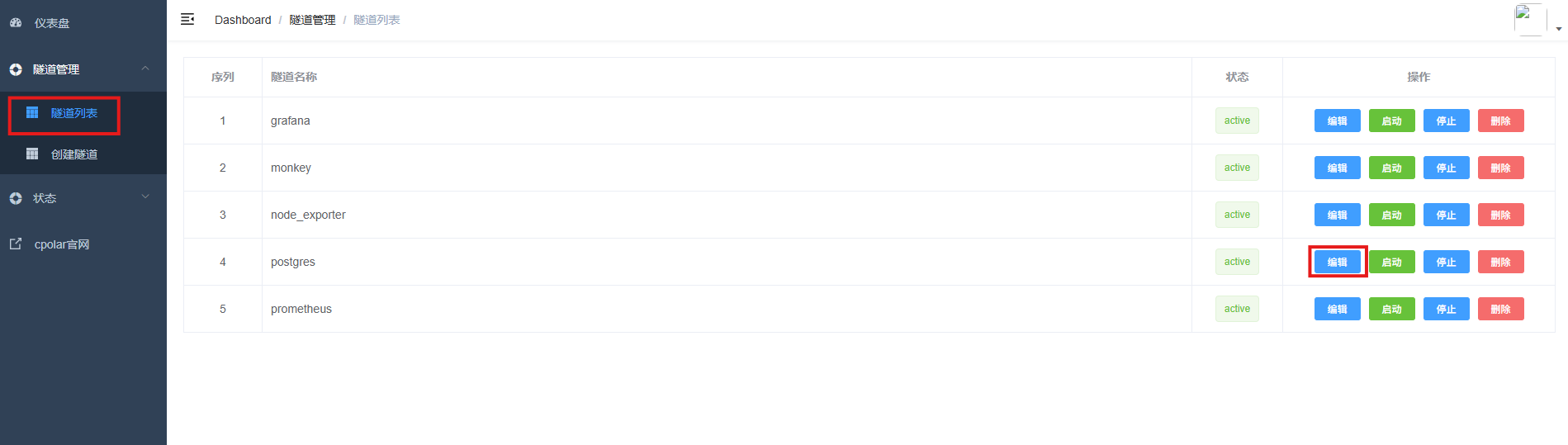
登录web UI管理界面,点击左侧仪表盘的隧道管理------隧道列表,找到所要配置的隧道postgres,点击右侧的编辑。
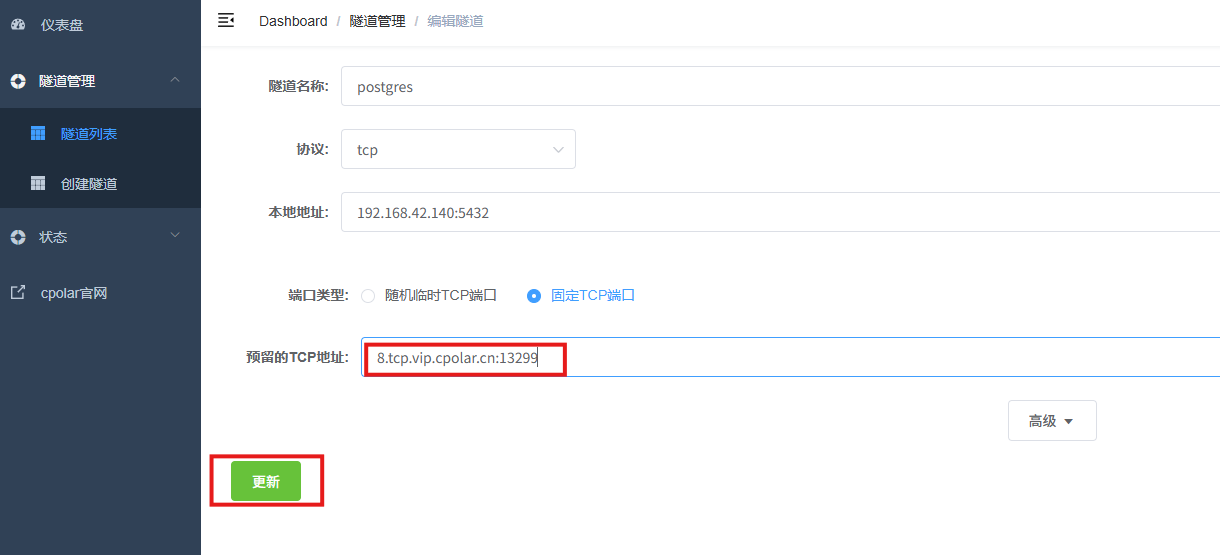
修改隧道信息,将保留成功的TCP端口配置到隧道中。
- 端口类型:选择固定TCP端口
- 预留的TCP地址:填写保留成功的TCP地址
点击更新。
创建完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的TCP地址。
最后测试一下固定的地址是否好用,测试命令:
shell
psql -h 8.tcp.vip.cpolar.cn -p 13299 -U postgres -d mydb
这样,我们成功打破了"没有公网 IP 就无法远程访问数据库"的固有认知。
总结
对比下来,单库和主从复制的差别很明显:
*不用主从复制时:*
- 数据库宕机 = 业务停摆,恢复靠手动
- 备份要停机,数据有丢失风险
- 维护升级必须 downtime
- 全靠人工救火
*用了主从复制后:*
- 主库挂了可以快速切换到从库
- 数据实时同步,最多丢失几秒
- 从库可以分担读取压力
- 运维从救火变成预防
不过也得承认,主从复制不是万能药:配置错了照样出问题,网络不稳定会有延迟,高并发场景还要考虑读写分离。而且,异步复制模式下主库挂了还是可能有数据丢失,真正要求不丢数据得上同步复制或者 PgPool 这种更复杂的方案。
如果你也有类似的痛点,比如担心单点故障、想降低运维压力,可以试试这个方案。先在测试环境跑通再上生产,别直接怼线上。