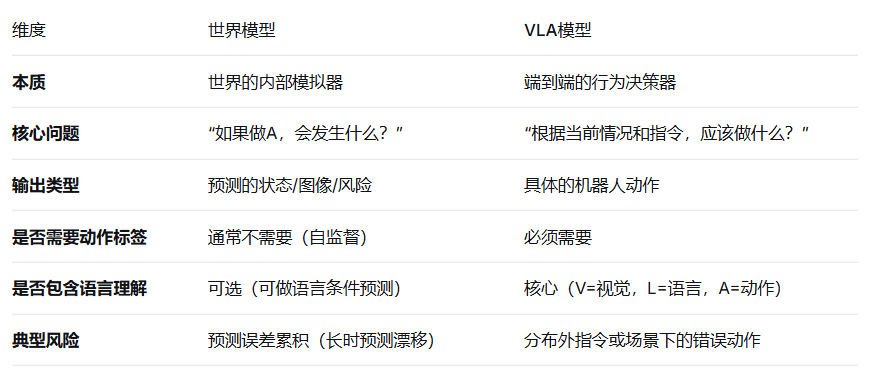
世界模型指给定当前状态和一个动作,它预测下一步会变成什么状态。本质是一个模拟器或预测器。例如:"我拿起杯子 → 杯子的位置变了,水可能洒出来"。
视觉语言行为模型指给定视觉观察和人类语言指令,它直接输出机器人要执行的动作。本质是一个策略网络或控制器。例如:"看到红色杯子 + 听到'拿起杯子'指令 → 输出机械臂的关节角度"。

世界模型:通常使用无标签或自监督的视频/状态序列数据。学习的是物理常识(如物体运动学、动力学),不需要动作标签。训练目标是最小化预测误差。
VLA模型:必须使用有动作标签的机器人操控数据。通常需要(图像,指令,动作轨迹)三元组。训练目标是最大化给定观测和指令下正确动作的概率。
VLA + 世界模型 = 更强的智能体 :VLA负责"做什么"(策略),世界模型负责"会发生什么"(模拟)。
典型应用:
规划:VLA采样多个动作,世界模型预测每个动作的未来结果,VLA选择结果最好的动作执行。
想象增强:VLA在实际执行前,先在世界模型中"想象"执行后果,进行试错(类似AlphaGo的自我对弈)。
数据生成:用世界模型生成海量虚拟机器人交互数据,用来训练VLA(解决真实数据稀缺问题)。
想要简单直接:先做VLA(端到端模仿学习),快速出效果。想要鲁棒、适应性强:在VLA中加入世界模型作为内部模拟器,实现想象规划。目标是通用机器人:两者缺一不可------VLA负责意图,世界模型负责常识。