在开发现代 C++ Vulkan 仿真引擎时,很多图形程序员初期的噩梦往往从初始化 VkInstance 和 VkDevice 开始------面对动辄几十个宏定义和长长一串的 VK_... 扩展列表,难免会感到头晕目眩。
与 OpenGL "大包大揽"的黑盒驱动不同,Vulkan 的核心设计哲学是**"微内核 + 庞大扩展"**。这种设计绝非有意刁难开发者,而是为了适应现代 GPU 架构的快速迭代。对于需要处理海量多边形(如复杂工业级模型渲染、高精度物理仿真)的引擎来说,理解并驾驭 Vulkan 的扩展机制,是实现极致性能优化、打通多硬件平台壁垒的必经之路。
本文将深入解析 Vulkan 扩展体系的演进生命周期,并结合实际的引擎架构,探讨如何优雅地处理不同层级的扩展。
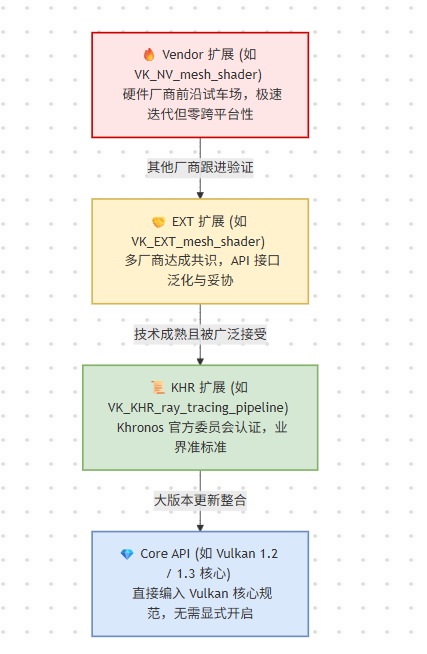
1. 扩展的"阶级":从试验田到行业标准
Vulkan 的扩展并非杂乱无章,它们有着极其森严的命名规范和生命周期。我们可以将其看作是一个图形特性从"独占"走向"普适"的升职记。
第一层:Vendor 扩展(硬件厂商的"自留地")
-
标识符:
VK_NV_...,VK_AMD_...,VK_INTEL_...,VK_ARM_... -
本质: 前沿技术的试验田。当某家硬件厂商推出了全新的 GPU 架构(例如 NVIDIA 的 Turing 架构),他们会迫不及待地将新特性通过 Vendor 扩展暴露给开发者。
-
工程考量: 这类扩展能让你压榨出该硬件的极限性能,但代价是零跨平台能力。在你的 C++ 引擎中如果强依赖它,换一张显卡程序就会直接崩溃。
第二层:EXT 扩展(多边妥协的产物)
-
标识符:
VK_EXT_...(Multi-vendor Extension) -
本质: 跨厂商的联合标准。当一个 Vendor 特性被证明极具价值,其他厂商(比如 AMD、Intel)也决定在自家硬件上支持时,大家会坐下来制定一个通用的 API 接口。
-
工程考量:
EXT扩展在保留了高级特性的同时,大幅提升了兼容性。很多功能在正式转正前,都会在这个阶段停留数年,供引擎开发者在复杂的工业场景中进行测试。
第三层与第四层:KHR 标准与 Core API(官方认证)
-
标识符:
VK_KHR_...以及 Vulkan 1.1/1.2/1.3 核心规范。 -
本质: Khronos Group 的官方背书。一旦成为
KHR,意味着它已是业界公认的标准。而在随后的 Vulkan 大版本更新中,一些极其重要的扩展会被直接编入核心(Core API),此时开发者甚至不再需要显式开启扩展即可使用。
2. 实战案例透视:Mesh Shader 的"飞升之路"
为了更直观地理解这一过程,我们以现代渲染引擎解决几何瓶颈的终极武器------Mesh Shader(网格着色器) 为例。
在处理极其复杂的工业装配体模型时,传统的 Vertex / Index Buffer 配合固定几何管线往往会遇到严重的 Draw Call 瓶颈。传统基于 Compute Shader 的 GPU 剔除(Culling)虽然好用,但需要将数据写回显存再由 Draw Indirect 消费,存在同步开销。
-
破局者
VK_NV_mesh_shader: NVIDIA 率先发力,推出了 NV 版本的扩展。它允许开发者像写 Compute Shader 一样处理几何体,完美契合了细粒度 LOD(Level of Detail)和 Cluster 级别的视锥体/遮挡剔除。 -
走向统一的
VK_EXT_mesh_shader: 随着 AMD 的 RDNA 架构也支持了类似硬件,业界推出了 EXT 版本。两者的 API 并不完全相同:EXT 版本为了兼容更广泛的硬件,在跨平台的 Payload 传递机制、Local Workgroup 的行为定义上做了妥协与泛化。
对于追求高水平架构的渲染引擎来说,理解这种 API 层面的微调,比单纯实现效果更为重要。
3. 现代 C++ 引擎中的扩展架构实践
在开发底层仿真引擎时,我们不能假设用户的机器永远拥有最新、最好的显卡。一个健壮的渲染器架构,必须具备优雅的特性查询(Feature Querying)和降级回退(Fallback)机制。
3.1 动态加载与特性查询
很多高级扩展的函数指针并不存在于 Vulkan 的核心 Loader 中。在现代 C++ 工程中,我们通常会引入 volk 这样的元加载器,或者自己封装 vkGetDeviceProcAddr。
在设备初始化阶段,引擎需要动态拉取并匹配能力:
cpp
// C++ 伪代码:健壮的扩展支持查询
bool checkDeviceExtensionSupport(VkPhysicalDevice device, const std::vector<const char*>& requiredExtensions) {
uint32_t extensionCount;
vkEnumerateDeviceExtensionProperties(device, nullptr, &extensionCount, nullptr);
std::vector<VkExtensionProperties> availableExtensions(extensionCount);
vkEnumerateDeviceExtensionProperties(device, nullptr, &extensionCount, availableExtensions.data());
std::set<std::string> requiredExts(requiredExtensions.begin(), requiredExtensions.end());
for (const auto& extension : availableExtensions) {
requiredExts.erase(extension.extensionName);
}
// 如果 requiredExts 为空,说明所有请求的扩展都得到了支持
return requiredExts.empty();
}3.2 渲染管线的 Fallback 策略 (以几何剔除为例)
针对复杂场景的渲染,我们可以设计三套渲染路径(Render Paths),引擎根据扩展的支持情况在运行时动态决定走哪一条:
-
极致性能路径(Tier 1): 如果设备支持
VK_EXT_mesh_shader,直接启用 Mesh Shader 管线。将 Cluster 级别的 Frustum Culling 和 LOD 判定全部放在 Task Shader 中完成,实现极限的几何吞吐。 -
主流性能路径(Tier 2): 如果不支持 Mesh Shader,但支持
VK_KHR_draw_indirect_count等扩展。回退到 Compute Shader Culling + Draw Indirect 方案。在 Compute Shader 中做剔除,然后生成间接绘制命令。 -
兼容路径(Tier 3): 如果是一些老旧设备,只能回退到 CPU 端的视锥体剔除和多线程 Draw Call 提交。
cpp
// 引擎管线初始化逻辑示例
if (deviceFeatures.supportsMeshShaderEXT) {
m_RenderPath = RenderPath::MeshShading;
Logger::Info("启用 VK_EXT_mesh_shader 管线");
} else if (deviceFeatures.supportsMultiDrawIndirectKHR) {
m_RenderPath = RenderPath::ComputeCullingIndirect;
Logger::Info("回退至 GPU Compute 剔除管线");
} else {
m_RenderPath = RenderPath::TraditionalCPU;
Logger::Warn("警告:硬件不支持高级剔除扩展,将使用 CPU 剔除");
}4. 结语
Vulkan 的扩展机制,看似繁琐,实则是其强大生命力的源泉。它解除了 API 规范对硬件创新的束缚。
作为引擎开发者,我们不仅要会"抄"官方示例,更要具备宏观的架构视野:面向 EXT/KHR 编写稳定的核心代码以保证跨平台兼容性,同时预留 NV/AMD 等 Vendor 扩展的接口,以便在特定工业场景或极致仿真需求下,释放硬件的终极潜能。
拥抱扩展,处理好 Fallback,这正是从"图形学初学者"迈向"引擎架构师"的必经之路。