哈喽,我是我不是小upper~
今儿和大家详细的聊聊,统计检验方法中最为重要的一个:皮尔逊相关系数检验~
最初,大家可能听过这句话:相关不等于因果。
但相关到底是什么?
怎么检验它?
我们在机器学习和数据分析里,最常用的起手式就是皮尔逊相关系数检验
01 皮尔逊相关系数到底是干嘛的?
在数据分析、机器学习特征工程、统计学检验中,皮尔逊相关系数(Pearson Correlation Coefficient) 是最常用、最基础的指标之一。
它本质上只干两件事:
- 判断两个数值型变量 之间是否存在线性关系
- 评估这种线性关系是真实存在,还是仅仅由随机波动导致的巧合
这里的线性关系可以简单理解为:
- 变量 A 上升时,变量 B 也跟着上升 → 正相关
- 变量 A 上升时,变量 B 反而下降 → 负相关
- A 怎么变,B 都没有明显规律 → 无线性关系
皮尔逊相关系数通常记为 r ,取值范围严格落在 -1, 1 之间:
- r 接近 1:强正线性相关
- r 接近 -1:强负线性相关
- r 接近 0:无线性相关(但不代表没有非线性关系)
除此之外,我们通常还会搭配 p 值(显著性水平) 一起看:
- p 值很小(如 p < 0.05):观测到的相关性极不可能是随机巧合 → 相关性显著
- p 值很大(如 p > 0.05):当前相关很可能只是运气导致 → 无显著线性相关
可以简单记:
- r:衡量线性关系强弱与方向的 "温度计"
- p 值:判断这个 "温度计读数" 是不是误差的校验器
02 一个通俗例子
用一个发糖果的场景,让你瞬间理解相关系数的含义。
规则:每个小朋友做对 X 道题(0~10 题),你按照 糖果数 Y = 做对题数 × 2 发糖。
示例:
小明做对 5 题 → 得到 10 颗糖
小红做对 8 题 → 得到 16 颗糖
小强做对 0 题 → 得到 0 颗糖
把 X(做对题数)和 Y(糖果数)画在坐标系里,几乎就是一条完美直线。
此时皮尔逊相关系数 r ≈ 1,代表极强正线性相关。
如果加入一点随机扰动,比如偶尔多发或少发 1~2 颗糖,数据会轻微抖动,r 可能从 1 降到 0.95 左右,但依然极强。此时做显著性检验:
如果真实世界中 X 和 Y 完全无关,纯靠随机能碰巧得到 0.95 这么高的相关吗?
概率极低,因此 p 值会非常小(如 p < 0.001) ,我们认为相关性显著。
再看反例:鞋带颜色 和 做题正确率,两者基本无关。此时 r 接近 0,p 值很大(如 0.6、0.7),说明没有证据表明二者存在线性关系。
03 核心点
1. 统计检验思想
皮尔逊相关系数的检验基于假设检验:
- 原假设 H₀:总体中两个变量不存在线性相关(总体相关系数 ρ = 0)
- 备择假设 H₁:总体中两个变量存在线性相关(总体相关系数 ρ ≠ 0)
2. 皮尔逊相关系数公式
总体皮尔逊相关系数:
样本皮尔逊相关系数:
公式拆解:
- 分子:X 与 Y 的协方差,衡量两个变量同向 / 反向变化的趋势
- 分母:X 标准差 × Y 标准差,用于归一化,把结果约束在 -1,1
计算出 r 后,可构造 t 统计量进行显著性检验:
服从自由度 df = n - 2 的 t 分布,据此计算双侧 p 值。
3. 关键假设与注意事项
皮尔逊相关系数并非万能,它有严格适用条件:
- 只捕捉线性关系对非线性关系(U 型、抛物线、环形、周期波动)会失效,可能出现 r≈0 但实际明显相关。
- 要求成对观测值相互独立
- 理想情况下服从双变量正态分布
- 对异常值(离群点)极其敏感少数极端点就能大幅拉高 / 拉低 r 值,导致结果失真。
- 样本量较大时,对正态性的偏离会更稳健,但离群点的影响始终存在。
04 什么时候用?什么时候别用?
适用场景
- 快速探索两组数值变量之间的线性关联强度与方向
- 机器学习中特征初筛:快速找出与标签相关性较强的特征
- 回归分析前,判断自变量与因变量是否存在线性趋势
- 简单的线性关联验证与显著性检验
不适用 / 需谨慎场景
- 存在明显非线性关系(环形、抛物线、指数关系等)
- 数据包含重度离群点,未做清洗直接计算
- 变量是分类变量(性别、是否患病、等级等),此时应使用:
- 点二列相关
- 斯皮尔曼秩相关
- 卡方检验等
- 存在多重共线性,变量之间高度互相解释,需结合 VIF 方差膨胀因子进一步分析
- 数据不独立、不满足近似正态分布(小样本尤其要注意)
05完整案例
我们先合成一组有强正相关、强负相关、弱相关、非线性相关、独立噪声的数据。
用PyTorch实现皮尔逊r与p值计算
数据集说明
-
构造X1,令Y_pos≈0.8×X1+噪声(强正),Y_neg≈-0.7×X1+噪声(强负)
-
构造X2≈0.6×X1+噪声(多变量里也会体现正相关)
-
构造Y_nl=sin(X1)+噪声(非线性但皮尔逊不一定高)
-
构造Noise随机噪声(与X1近似独立)
-
再构造一个圆环结构(A=cosθ+噪声, B=sinθ+噪声),A和B之间非线性强相关但r≈0
python
import torch
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
torch.manual_seed(42)
n = 2000
# 1) 线性相关与噪声
X1 = torch.randn(n)
X2 = 0.6 * X1 + 0.8 * torch.randn(n) # 与X1中等正相关
Y_pos = 0.8 * X1 + 0.5 * torch.randn(n) # 强正相关
Y_neg = -0.7 * X1 + 0.5 * torch.randn(n) # 强负相关
Y_nl = torch.sin(X1) + 0.3 * torch.randn(n) # 非线性关系(sin)
Noise = torch.randn(n) # 近独立噪声
# 2) 圆环结构(相关系数r~0但关系显著非线性)
theta = 2 * torch.pi * torch.rand(n)
A = torch.cos(theta) + 0.15 * torch.randn(n)
B = torch.sin(theta) + 0.15 * torch.randn(n)
# 3) 构造标签
group = torch.where(X1 + 0.5*X2 > 0, 1, 0) # 0/1两类
group = group.numpy()
# 拼接到DataFrame
df = pd.DataFrame({
"X1": X1.numpy(),
"X2": X2.numpy(),
"Y_pos": Y_pos.numpy(),
"Y_neg": Y_neg.numpy(),
"Y_nl": Y_nl.numpy(),
"Noise": Noise.numpy(),
"A": A.numpy(),
"B": B.numpy(),
"group": group
})实现皮尔逊相关与显著性检验
-
写一个函数pearsonr_torch(x, y)计算r与p
-
写一个函数corr_p_matrix_torch(M)对矩阵每对列做检验,得到r矩阵和p矩阵
-
使用t分布求p值:
,
python
import torch
import numpy as np
import pandas as pd
from scipy.stats import t # 这里加了 scipy 的 t 分布
def pearsonr_torch(x: torch.Tensor, y: torch.Tensor):
"""
输入: x,y (1-D张量,长度n)
输出: r, p (标量tensor)
"""
assert x.ndim == 1 and y.ndim == 1 and x.shape[0] == y.shape[0]
n = x.shape[0]
x = x - x.mean()
y = y - y.mean()
r = (x @ y) / (torch.sqrt((x @ x)) * torch.sqrt((y @ y)))
# 数值稳定:截断到[-1+eps, 1-eps]
eps = 1e-12
r = torch.clamp(r, -1+eps, 1-eps)
# t统计量
df_val = n - 2
t_val = r * torch.sqrt(torch.tensor(df_val, dtype=torch.float64) / (1 - r**2))
t_val = t_val.to(torch.float64)
# ---------------- 修复:用 scipy 计算 t 分布 p 值 ----------------
t_np = np.abs(t_val.cpu().numpy())
p_np = 2 * (1 - t.cdf(t_np, df=df_val))
p = torch.tensor(p_np, dtype=torch.float32, device=x.device)
# ----------------------------------------------------------------
return r.to(torch.float32), p
def corr_p_matrix_torch(M: torch.Tensor):
"""
输入: M (n x d), 每列一个变量
输出: R (d x d), P (d x d) 对称矩阵
"""
assert M.ndim == 2
n, d = M.shape
R = torch.zeros((d, d), dtype=torch.float32)
P = torch.zeros((d, d), dtype=torch.float32)
for i in range(d):
for j in range(i, d):
r, p = pearsonr_torch(M[:, i], M[:, j])
R[i, j] = R[j, i] = r
P[i, j] = P[j, i] = p
return R, P
# 只对数值型列做矩阵计算
num_cols = ["X1", "X2", "Y_pos", "Y_neg", "Y_nl", "Noise", "A", "B"]
M = torch.tensor(df[num_cols].values, dtype=torch.float32)
R, P = corr_p_matrix_torch(M)
# 转成DataFrame便于可视化
R_df = pd.DataFrame(R.numpy(), index=num_cols, columns=num_cols)
P_df = pd.DataFrame(P.numpy(), index=num_cols, columns=num_cols)快速检查:几对关键变量的r与p
python
pairs = [("X1","Y_pos"), ("X1","Y_neg"), ("X1","Y_nl"), ("X1","Noise"), ("A","B")]
for a,b in pairs:
r, p = pearsonr_torch(torch.tensor(df[a].values), torch.tensor(df[b].values))
print(f"{a} vs {b}: r={r.item():.3f}, p={p.item():.3g}")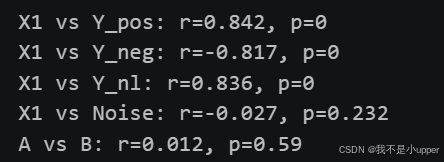
会看到:
-
X1 vs Y_pos: r较高(~0.85左右),p极小
-
X1 vs Y_neg: r较低(~-0.8左右),p极小
-
X1 vs Y_nl: r接近0或较小,p可能不显著(尽管X1和Y_nl有明显的sin非线性关系)
-
X1 vs Noise: r≈0,p不显著
-
A vs B: r≈0,p不显著(但实际上是圆环结构,非线性强)
这正说明了皮尔逊相关只盯线性。
可视化分析
咱们一眼看出变量之间线性相关的强弱与方向(红=正相关,蓝=负相关)
可用于特征之间的冗余分析、初步筛选
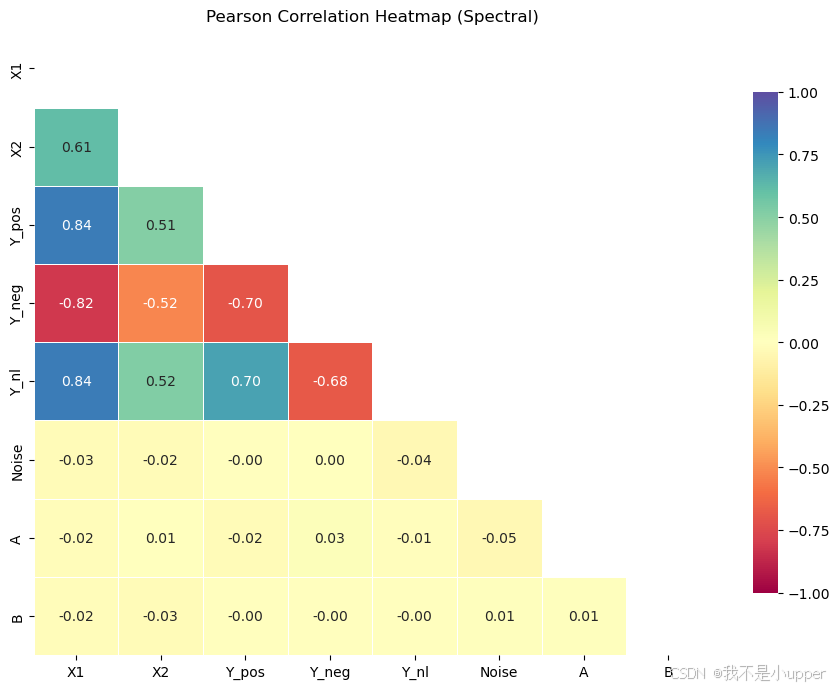
-
X1与Y_pos强正(颜色偏红),X1与Y_neg强负
-
X1与X2中度正相关
-
Y_nl与X1颜色不显著------尽管它们有非线性关系
-
A与B的r也不突出(几乎0),但别被它骗了
成对散点矩阵:
-
检查每对变量之间的形状关系(线性、曲线、团簇、离群点)
-
按group着色呈现类别差异,揭示潜在混杂
python
use_cols = ["X1", "X2", "Y_pos", "Y_neg", "Y_nl"]
pair_df = df[use_cols + ["group"]].copy()
pair_df["group"] = pair_df["group"].astype("category")
# 强制轻量绘图
g = sns.pairplot(
pair_df,
vars=use_cols,
hue="group",
palette="tab10",
corner=True,
kind="scatter",
diag_kind="hist",
plot_kws=dict(s=8, alpha=0.4)
)
plt.show()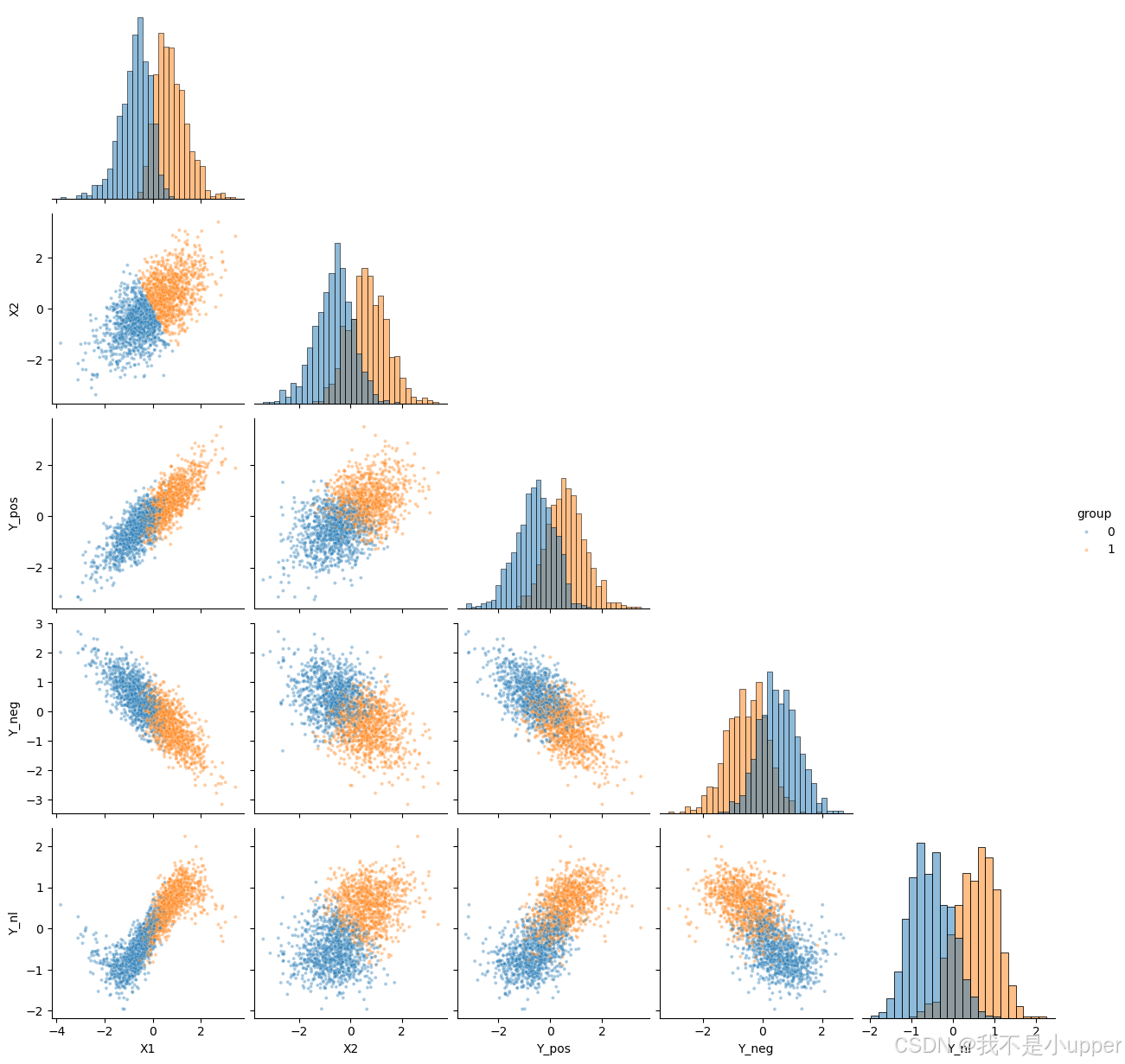
-
X1-Y_pos近似斜直线(正相关),X1-Y_neg近似斜直线但反方向(负相关)
-
X1-Y_nl出现S型或波浪形(非线性)
-
可看到不同群组的分布差异,这提醒我们分组变量可能影响相关解读,如有混杂需控制。
显著性热力图(-log10(p)):
-
和相关热力图互补:这张图专门看多显著
-
可快速识别统计上置信度高的关联对
python
neglogP_df = -np.log10(P_df + 1e-300) # 数值稳定
plt.figure(figsize=(9, 7))
mask = np.triu(np.ones_like(neglogP_df, dtype=bool))
sns.heatmap(neglogP_df, mask=mask, cmap="magma", annot=True, fmt=".1f",
linewidths=.5, cbar_kws={"shrink": .8})
plt.title("-log10(p) Significance Map (magma)")
plt.tight_layout()
plt.show()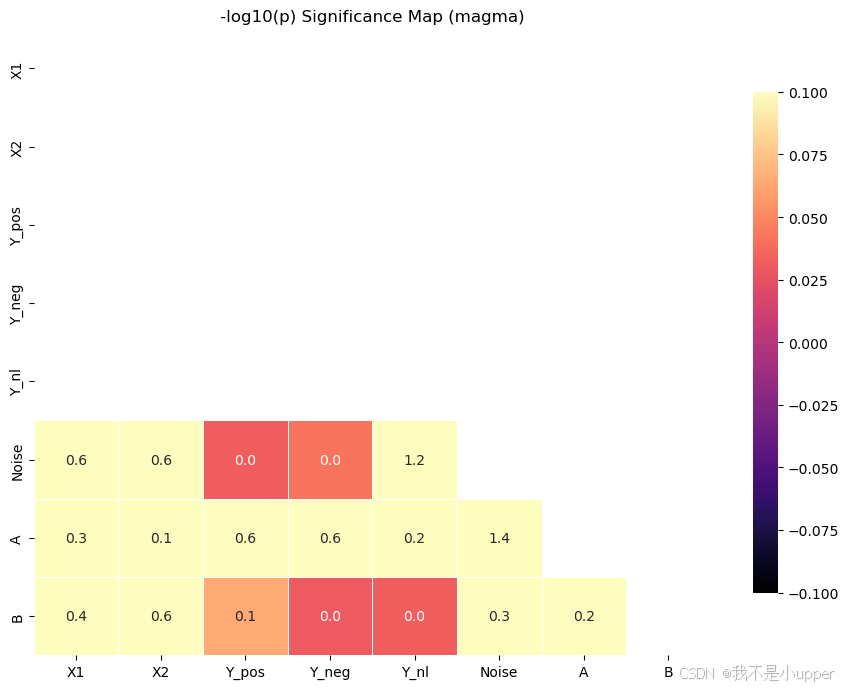
-
X1-Y_pos、X1-Y_neg对应位置显著性非常强
-
X1-Y_nl、A-B等位置不亮,说明线性相关不显著(尽管它们存在非线性关系)
-
可以用这张图来配合阈值(比如p<0.05,相当于-log10(p)>1.3)做显著对筛选
火山图:
-
横轴看相关强度(取|r|),纵轴看显著性(-log10(p))
-
右上角=又强又显著(重点),左下角=又弱又不显著(忽略)
python
pairs = []
for i, a in enumerate(num_cols):
for j, b in enumerate(num_cols):
if j <= i:
continue
pairs.append((a, b, abs(R_df.loc[a, b]), -np.log10(P_df.loc[a, b] + 1e-300)))
volcano = pd.DataFrame(pairs, columns=["VarA","VarB","abs_r","neglog10p"])
plt.figure(figsize=(8,6))
sc = plt.scatter(volcano["abs_r"], volcano["neglog10p"],
c=volcano["neglog10p"], s=80, cmap="rainbow", alpha=0.9, edgecolor="k")
plt.colorbar(sc, label="-log10(p)")
plt.axvline(0.3, color="deepskyblue", ls="--", lw=1.2) # 经验相关强度阈值
plt.axhline(1.3, color="crimson", ls="--", lw=1.2) # p=0.05阈值的-log10
for _, row in volcano.sort_values("neglog10p", ascending=False).head(5).iterrows():
plt.text(row["abs_r"]+0.01, row["neglog10p"]+0.1, f'{row["VarA"]}-{row["VarB"]}',
fontsize=9, color="black")
plt.xlabel("|r| (Correlation Strength)")
plt.ylabel("-log10(p) (Significance)")
plt.title("Volcano-style Plot of Pairwise Correlations")
plt.tight_layout()
plt.show()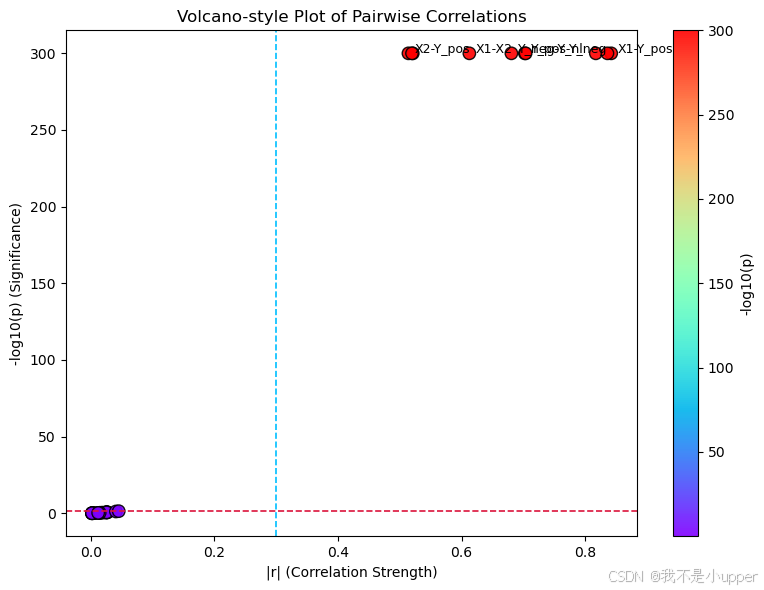
-
右上角的点(如X1-Y_pos、X1-Y_neg)最值得关注:相关强且显著
-
左下角(如X1-Noise)可忽略
-
有些点|r|不高但也许p还不错,说明样本量较大时即便弱相关也可能显著,但实际意义未必大
线性 vs 非线性对比散点:
-
强调皮尔逊相关只会抓线性
-
对比X1-Y_pos(线性)和A-B(圆环结构、非线性强)
python
fig, axes = plt.subplots(1, 2, figsize=(12,5))
# 线性:X1 vs Y_pos
axes[0].scatter(df["X1"], df["Y_pos"], c=df["X2"], cmap="viridis", s=30, alpha=0.9, edgecolor="white", linewidth=0.4)
axes[0].set_title("Linear: X1 vs Y_pos (colored by X2)")
axes[0].set_xlabel("X1")
axes[0].set_ylabel("Y_pos")
# 非线性:A vs B(圆环)
axes[1].scatter(df["A"], df["B"], c=df["Y_nl"], cmap="plasma", s=30, alpha=0.9, edgecolor="white", linewidth=0.4)
axes[1].set_title("Nonlinear: A vs B (Ring, colored by Y_nl)")
axes[1].set_xlabel("A")
axes[1].set_ylabel("B")
plt.suptitle("Linear vs Nonlinear Relationships (Bright Colors)")
plt.tight_layout()
plt.show()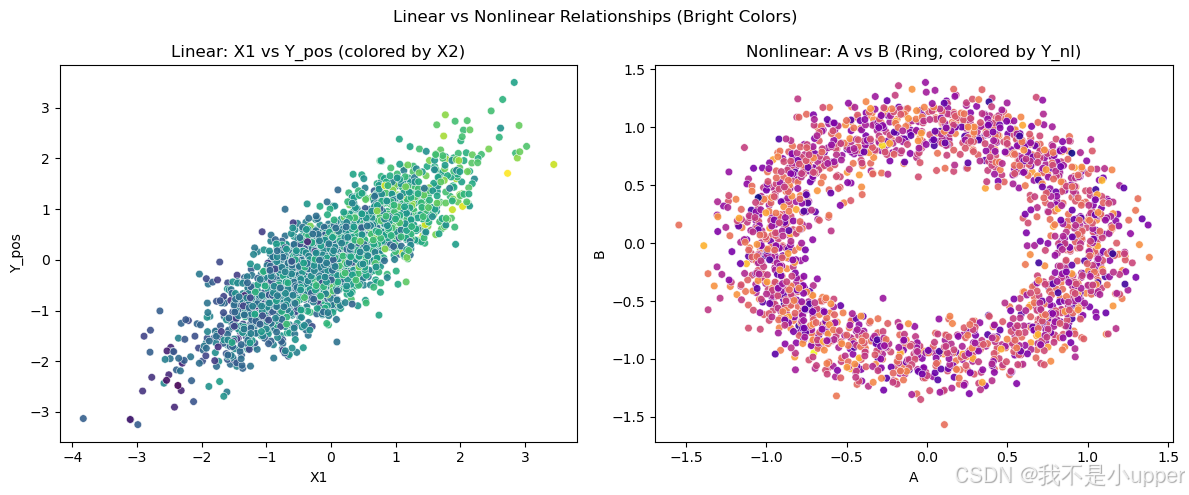
-
左图:X1与Y_pos像一条斜直线,皮尔逊r高
-
右图:A与B呈环状,r≈0,但结构非常清晰,告诉你相关系数抓不到它们的非线性关系
总结
皮尔逊相关系数r用来衡量两个数值变量的线性 强弱与方向;检验p值用来判断这种强弱是不是大概率不是巧合。
用法快、准,但只盯线性;非线性、离群点、分布偏态都可能让它失灵 或误判。
我们在实战中,最好图+数双保险:用热力图、pairplot、散点图去感受形状;用r和p去定量判断。