1. 什么是STL
STL 的全称是Standard Template Library ,中文译为"标准模板库",是C++标准库中最核心,最常见的组成部分,也是C++泛型编程思想最经典的落地实践。
它本质上是一套官方预先实现好,经过工业级严验证的通用工具框架:你不需要再去重复写链表,栈,队列,排序查找这些基础数据结构和算法,直接调用STL的组件就能够快速完成开发,同时还能够保证性能和稳定性。和普通的工具库不同,STL的所有组件都是基于模板实现的,天然支持适配任意数据类型---你既可以用它存int,double这些内置类型,也可以直接存自定义的类,不需要为不同类型单独修改逻辑,完美契合了C++"复用代码,提升开发效率"的设计理念。
现在STL已经是C++开发的基础设施,几乎所有C++项目都会用到它,比如后端服务,嵌入式软件,高性能计算等场景下,STL都是必不可少的工具,它把开发者从底层数据结构的重复实现中解放出来,让大家可以更专注于业务逻辑的本身。
2. STL的版本演进
STL 的设计思想最早诞生于 1990 年代,至今所有主流的 STL 实现版本,都继承自惠普实验室的原始开源版本,后续不同厂商基于原始版本做了适配和优化,衍生出了几个主流分支:
1. 原始 HP 版本:所有 STL 的共同始祖
STL 最早由程序员 Alexander Stepanov 和 Meng Lee 在惠普实验室研发完成,是 STL 的初代实现版本。
两位开发者以开源精神公开了全部代码,并且声明:所有人都可以免费使用、拷贝、修改、分发甚至商用这套代码,唯一要求是衍生版本也需要保持开源。
这个版本也被称为 HP 版本,是后续所有 STL 实现的上游基础。
2. P.J. 版本:Windows 平台 VC++ 的默认实现
该版本由 P.J. Plauger 开发,在 HP 版本的基础上适配了 Windows 平台,是微软 Visual Studio 系列编译器(MSVC)内置的 STL 版本。
不过这个版本属于闭源实现,不允许开发者修改或二次分发,同时内部代码的可读性较低,符号命名风格比较特殊,对新手阅读源码不太友好。
3. RW 版本:C++ Builder 的内置实现
该版本由 Rogue Wave 公司开发,同样继承自 HP 版本,曾是老牌 IDE C++ Builder 的默认 STL 实现。它也是闭源版本,代码可读性一般,现在随着 C++ Builder 的式微,已经比较少见。
4. SGI 版本:最适合学习的开源实现
该版本由硅谷图形公司(Silicon Graphics Computer Systems, Inc.)开发,继承自 HP 版本,是 GCC 编译器(Linux/macOS 等平台默认编译器)的内置 STL 实现,也是目前应用最广泛的版本之一。
它完全开源、跨平台可移植性强,不仅允许自由修改、分发,甚至支持商用售卖;更重要的是它的代码风格清晰、命名规范易懂,可读性非常高,后续我们学习 STL 原理、阅读源码时,主要参考的就是 SGI 版本。
3. STL的六大组件
STL 之所以能成为 C++ 开发的 "万能工具箱",核心在于它的六大组件相互配合,形成了一套高度解耦、灵活复用的架构:你可以用不同容器 存储数据,用迭代器 统一访问数据,用算法 处理数据,过程中还可以通过仿函数 自定义规则、配接器 改造容器、空间配置器 管理内存,几乎覆盖了日常开发的所有基础需求。
六大组件的关系和包含的常用内容可以参考下面这张架构图:
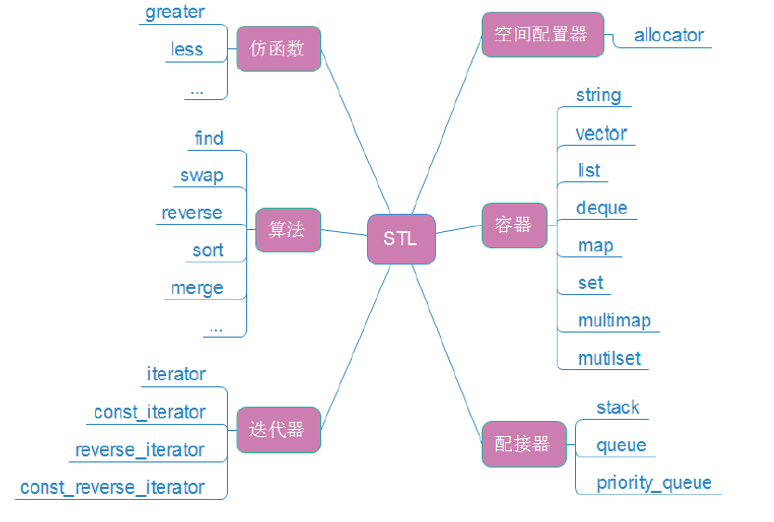
3.1 容器
了解完 STL 的整体架构,我们最先要攻克的就是容器模块 ------ 它是 STL 的基础载体,我们日常开发中所有需要暂存数据的场景,都可以在 STL 容器里找到最适配的实现。你不需要再手动实现动态数组、链表、栈、队列这些基础数据结构,STL 已经把这些轮子打磨到了工业级性能,而且所有容器都提供了风格统一的接口,学会之后能直接复用在任意项目里。
STL 的容器主要分为三大类,我们可以根据自己的场景需求选:如果只需要按插入顺序存数据,选序列式容器 ;如果需要自动排序、快速按键查找,可以选关联式容器 ;如果追求极致查找速度、不需要排序,就选 C++11 新增的无序关联式容器。
3.1.1 序列式容器:元素顺序完全由插入时机决定
序列式容器是 STL 里最基础的容器类别,它不会对存储的元素做任何排序或者重排,你先插进去的元素就排在前面,后插的就在后面,位置完全由你插入的顺序决定。日常开发里 80% 的基础存储场景都可以用这类容器解决,常用的有以下几种:
1. vector:最常用的动态数组
- 底层逻辑:和 C 语言的动态数组是一个思路,一整块连续的内存空间,存满了就自动申请更大的空间、拷贝数据,完全不需要手动管理扩容。
- 实际使用体验:它几乎是日常开发的首选,只要你不需要频繁在头部 / 中间插删数据,用 vector 就对了,下标访问的速度是所有容器里最快的,遍历效率也最高。唯一要注意的是尽量避免在头部或者中间删数据,每删一个元素后面所有元素都要往前挪,数据量大的时候性能掉得很明显。
- 常用场景:比如存接口返回的用户列表、程序运行的临时缓存、或者你不确定长度的数组场景,都可以直接用 vector。
代码示例如下:
cpp
int main()
{
vector<string>name_list;
//批量新增用户
name_list.push_back("张三");
name_list.push_back("李四");
name_list.push_back("王五");
//直接用下标取第二个用户名字,和数组下标用法一致
cout <<"第二个用户名字是:"<< name_list[1] << endl;
//使用范围for遍历打印所有用户名字
cout << "所有用户名字:";
for (const string& name : name_list)
{
cout << name << " ";
}
cout << endl;
// 删除最后一个新增的用户
name_list.pop_back();
cout << "删除后剩余用户数:" << name_list.size() << endl;
return 0;
}2. deque:支持头尾高效操作的双端队列
- 底层逻辑:不像 vector 是一整块内存,deque 是把好几段小的连续内存块拼起来用,靠一个中控数组记录这些内存块的位置,所以看起来是连续的,实际物理上是分段的。
- 实际使用体验 :
它最大的优势就是头尾插删都和 vector 尾部操作一样快,还支持下标访问,刚好补上了 vector 头插效率低的缺点。不过下标访问需要先查中控数组找对应的内存块,速度比 vector 慢一点,中间插删也还是要移动元素,性能不高。- 常用场景:比如做任务队列的时候需要头删尾插、或者滑动窗口类的需求,用 deque 就比 vector 合适很多。
代码示例如下:
cpp
//任务ID队列
//新任务从尾部加,紧急任务从头部插入
//打印出当前要处理的第一个任务
//处理完从头部弹出,在尾部添加新任务
//打印出下一个要处理的任务
int main()
{
deque<int> task;//实例化
task.push_back(1);
task.push_back(2);
task.push_front(3);//紧急任务
cout << "第一个任务:" << task.front() << endl;
task.pop_front();
task.push_back(4);
cout << "下一个任务:" << task.front() << endl;
return 0;
}3. list:任意位置插删都快的双向链表
- 底层逻辑:就是经典的双向循环链表结构,每个元素都是独立的节点,靠指针串起来,节点之间内存不连续。
- 实际使用体验:它和 vector 刚好互补:vector 快在访问、慢在中间插删,list 刚好反过来,不能用下标访问,找元素必须从头遍历,但是不管在哪个位置插删元素,只要找到位置,改一下前后节点的指针就行,速度特别快,而且除了被删的节点,其他迭代器都不会失效。
- 常用场景:如果你的场景需要频繁在数据中间插删元素,比如维护一个动态更新的排行榜、或者频繁增删的消息列表,用 list 比 vector 性能好很多。
代码示例:
cpp
int main() {
list<int> score_list; // 游戏分数排行榜
score_list.push_back(85);
score_list.push_back(92);
score_list.push_back(78);
// 找到92的位置,插入新分数90
auto it = score_list.begin();
while (it != score_list.end() && *it != 92) {
++it;
}
score_list.insert(it, 90); // 在92前面插入90
// 遍历输出分数
cout << "排行榜分数:";
for (int score : score_list) {
cout << score << " ";
}
cout << endl;
// 删除最低分78
score_list.remove(78);
return 0;
}4. stack 和 queue:封装好的专用适配器
这两个不是原生容器,属于「容器适配器」------ 说白了就是把其他容器包了一层,限制住功能,只暴露符合特性的接口。默认它们都是用 deque 封装的,你也可以手动指定用 vector 或者 list 当底层。
- stack 是后进先出的栈结构,只能操作最顶部的元素,常用于括号匹配、逆序输出、深度优先搜索这类场景。
- queue 是先进先出的队列结构,只能尾部进、头部出,常用于广度优先搜索、任务排队这类场景。
代码示例:
cpp
// stack 示例:逆序输出字符串
int main() {
string s = "hello world";
stack<char> st;
for (char c : s) {
st.push(c); // 每个字符依次入栈
}
cout << "逆序结果:";
while (!st.empty()) {
cout << st.top(); // 从栈顶依次弹出就是逆序
st.pop();
}
cout << endl;
return 0;
}
// queue 示例:排队叫号
int main() {
queue<int> num_queue;
// 顾客取号
num_queue.push(1);
num_queue.push(2);
num_queue.push(3);
while (!num_queue.empty()) {
cout << "请" << num_queue.front() << "号顾客办理业务" << endl;
num_queue.pop(); // 办理完出队
}
return 0;
}3.1.2 关联式容器:自动按 key 排序,查找效率稳定
和序列式容器不一样,关联式容器存的是带 key 的结构,你插入元素的时候,它会自动按照 key 的值给你排好序,所以你不管按什么顺序插,最终容器里的元素都是有序的。
这类容器默认底层是红黑树实现的,不管插入、删除还是查找,效率都稳定在 O (logn),不会出现特别差的情况,适合需要频繁查找、且需要元素有序的场景。常用的有**set** (存单一 key 的集合)、map(存 key-value 的映射),加multi前缀的版本支持重复 key,我们后面单独展开讲。
3.1.3 无序关联式容器(C++11 新增):查找速度更快的哈希实现
这是 C++11 之后新增的一类容器,功能和上面的关联式容器类似,也是按 key 存,但底层是用哈希表实现的,不会给元素排序,平均查找、插入速度是 O (1),比红黑树快很多,缺点是极端情况(哈希冲突严重)下性能会降到 O (n)。
如果你的场景只需要快速查找,不需要元素有序,优先用这类容器就对了,常用的有**unordered_set、unordered_map** ,同样有**multi**前缀的版本支持重复 key。
3.2 STL算法
STL 是 C++ 为开发者封装的强大 "武器库",而其中的算法部分,就是封装好的、可以直接作用在容器上的通用逻辑,能帮我们省去大量重复写基础逻辑的时间。按照功能特性,STL 的算法可以分为三大类,我们逐个来看。
3.2.1 质变算法:会修改容器本身数据
这类算法执行后,会改变容器里存储的元素内容、或者元素的顺序 / 数量,属于 "会改变容器状态" 的操作,常见场景包括排序、增删元素、替换内容等。
典型代表:
- sort:对容器内的元素进行排序,默认是升序,也可以自定义排序规则
insert:向容器的指定位置插入元素erase:删除容器中指定位置 / 指定范围的元素replace:把容器中符合条件的元素替换为新值
3.2.2 非质变算法:不会修改容器数据
这类算法只会做 "读取、查询" 类的操作,执行后完全不会改动容器里原有的数据,常用于查找元素、统计数量、比较内容、找极值等场景。
典型代表:
find:在容器中查找等于目标值的元素,找到就返回对应迭代器,找不到返回尾后迭代器count:统计容器中等于目标值的元素总个数equal:比较两个容器的元素序列是否完全相等max_element:遍历容器,返回指向最大值元素的迭代器- 同类型还有**
min_element** (找最小值)、search(查找子序列)等。
3.3.3 数值算法:专门做数值计算
这类算法针对数值场景设计,用来完成数学类的计算,使用它们需要额外引入头文件 <numeric>。
典型代表:
accumulate:对容器内的元素做累加求和,也可以自定义累加规则(比如做乘积)。inner_product:计算两个序列的内积,也就是对应位置元素相乘后再相加的结果。
3.3 迭代器
迭代器本质是一个类指针对象,它封装了指针的基础操作(比如*取值、++移动),相当于给所有容器提供了一套统一的 "访问接口"。算法只需要和迭代器打交道,不需要关心容器底层是数组、链表还是红黑树,就能通用地遍历、操作元素,是真正的容器和算法之间的 "粘合剂"。
3.3.1 迭代器的 5 种类型
不同容器的底层结构不同,支持的迭代器操作也不同,STL 把迭代器按照支持的操作能力分为 5 类,能力越强支持的操作越多:
1. 输入迭代器(Input Iterator)
- 能力:仅支持单向只读 ,只能通过
++向前移动,用*读取指向的元素,不能修改元素- 限制:同一个序列只能遍历一次
- 典型例子:
istream_iterator(用于从输入流读取数据的迭代器)2. 输出迭代器(Output Iterator)
- 能力:仅支持单向只写 ,只能通过
++向前移动,用*给指向位置赋值,不能读取数据- 限制:同一个序列只能遍历一次
- 典型例子:
ostream_iterator(用于向输出流写入数据的迭代器)3. 前向迭代器(Forward Iterator)
- 能力:支持单向读写 ,兼具输入和输出迭代器的能力,既可以读取也可以修改元素,支持
++向前移动- 优势:同一个序列可以多次遍历
- 典型代表:
forward_list的迭代器、**unordered_set/unordered_map**的迭代器4. 双向迭代器(Bidirectional Iterator)
- 能力:在前向迭代器的基础上,额外支持向后移动 ,也就是可以用
--操作倒着遍历容器,同样支持多次遍历、读写元素- 典型代表:
list的迭代器、**set/map**的迭代器5. 随机访问迭代器(Random Access Iterator)
- 能力:是功能最强的迭代器,除了双向迭代器的所有操作,还支持
+/-偏移、[]下标式随机访问,也支持用</>等比较迭代器位置,访问效率最高- 典型代表:**
vector、deque、**原生数组的迭代器
常见容器对应的迭代器类型对照表:
| 容器 | 支持的迭代器类型 |
|---|---|
| vector | 随机访问迭代器 |
| deque | 随机访问迭代器 |
| list | 双向迭代器 |
| set / map | 双向迭代器 |
| unordered_set / unordered_map | 前向迭代器 |
| stack / queue | 不支持迭代器(仅支持访问顶部 / 队首元素) |
3.3.2 迭代器的基础操作演示
以功能最完整的vector随机访问迭代器为例,看一下迭代器的常用操作:
cpp
int main() {
vector<int> vec = { 10, 20, 30, 40 };
vector<int>::iterator it = vec.begin(); // 迭代器初始指向容器第一个元素
// 1. 用 * 解引用获取迭代器指向的元素
cout << "*it = " << *it << endl; // 输出:*it = 10
// 2. 用 ++ 向前移动迭代器
++it; // 移动后指向第二个元素20
cout << "*it = " << *it << endl; // 输出:*it = 20
// 3. 用 -- 向后移动迭代器(仅双向、随机访问迭代器支持)
--it; // 移动后回到第一个元素10
cout << "*it = " << *it << endl; // 输出:*it = 10
// 4. 随机访问操作(仅随机访问迭代器支持)
it += 2; // 直接偏移2个位置,指向第三个元素30
cout << "*it = " << *it << endl; // 输出:*it = 30
cout << "it[1] = " << it[1] << endl; // 下标访问,相当于*(it+1),输出40
cout << "it - vec.begin() = " << it - vec.begin() << endl; // 计算迭代器偏移量,输出2
// 5. 迭代器位置比较(仅随机访问迭代器支持<、>,所有迭代器都支持==、!=)
if (it < vec.end()) {
cout << "it 未到达容器末尾" << endl;
}
return 0;
}3.3.3 只读场景的安全选择:常量迭代器(const_iterator)
如果我们遍历容器的时候只需要读取数据,不需要修改元素,更推荐使用const_iterator,也就是常量迭代器。
- 它可以正常读取指向的元素,但禁止修改元素(**
*it**不能被赋值)- 可以提升代码安全性,避免误修改数据,也能让代码意图更清晰
- C++11 之后新增了**
cbegin()** 和**cend()**方法,可以直接获取常量迭代器,不需要手动声明类型
代码示例:
cpp
//常量迭代器代码示例
int main() {
vector<int> vec = { 10, 20, 30 };
// 常量迭代器:只能读,不能改
vector<int>::const_iterator cit = vec.cbegin();
cout << *cit << endl; // 正常读取,输出10
// *cit = 100; // 编译报错,不允许修改常量迭代器指向的内容
// C++11更简便的写法:用auto自动推导类型,配合cbegin/cend
for (auto it = vec.cbegin(); it != vec.cend(); ++it) {
cout << *it << " "; // 只读遍历,输出10 20 30
}
cout << endl;
return 0;
}注意:理解迭代器的分类和能力,能帮你避开很多 STL 使用的坑:比如给不支持随机访问的list用sort通用算法会报错,给vector插入元素后原来的迭代器会失效,这是因为vector的底层是连续数组,当插入元素后容量不足时,会重新申请一块更大的连续内存,把原来的元素全部拷贝到新内存,再释放旧内存,这时候指向旧内存的所有迭代器就全部变成了 "野指针",再访问就会出问题 。这些本质都和迭代器的特性有关。
3.4 仿函数
仿函数也叫函数对象 ,本质是一个重载了**()运算符** 的类,它的对象可以像普通函数一样被调用,主要作用是给算法传递自定义的操作规则,比普通函数更灵活(比如可以自带状态)。
3.4.1 仿函数的分类
按照参数个数可以分为两类:
- 一元仿函数:调用时只接收 1 个参数,比如取反、计算绝对值等
- 二元仿函数:调用时接收 2 个参数,比如比较大小、加减乘除等
STL 已经给我们提供了很多预定义好的常用仿函数,只需要引入**头文件<functional>**就可以直接使用。
3.4.2 仿函数的用法
1. 预定义仿函数直接用
比如我们要给**vector** 降序排序,直接把**greater<int>()** 传给**sort**算法即可:
cpp
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional> // 预定义仿函数的头文件
using namespace std;
int main() {
vector<int> vec = { 6, 3, 7, 9 };
// 传入greater<int>()作为排序规则,实现降序排序
sort(vec.begin(), vec.end(), greater<int>());
cout << "降序排序后:";
for (int x : vec) {
cout << x << " "; //输出 9 7 6 3
}
return 0;
}2. 自定义仿函数
现在我们有一个存放字符串的**vector** ,默认的**sort** 排序是按字典序比较,现在我们想自定义规则,让它按字符串的长度从小到大排序,就可以用自定义仿函数实现:
cpp
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
// 自定义仿函数:比较两个字符串的长度,返回"a的长度 < b的长度"的结果
class CompareByLength {
public:
// 重载()运算符,接收两个字符串参数,返回bool类型
bool operator()(const string& a, const string& b) const {
// 自定义排序规则:按字符串长度从小到大排
return a.size() < b.size();
}
};
int main() {
vector<string> fruits = {"apple", "banana", "kiwi", "orange", "pear"};
// 默认sort排序:按字典序(a < b)排序
sort(fruits.begin(), fruits.end());
cout << "默认字典序排序结果:";
for (const auto& s : fruits) {
cout << s << " ";
}
cout << endl;
// 输出:apple banana kiwi orange pear
// 传入自定义仿函数,按字符串长度排序
sort(fruits.begin(), fruits.end(), CompareByLength());
cout << "按长度从小到大排序结果:";
for (const auto& s : fruits) {
cout << s << " ";
}
cout << endl;
// 输出:kiwi pear apple banana orange
// 长度分别是4、4、5、6、6,完全符合我们的自定义规则
return 0;
}自定义仿函数的语法格式如下:
cpp
// 1. 定义类/结构体,类名就是仿函数的名字
class 仿函数名 {
public: // 一定要是public权限,否则外部无法调用运算符
// 2. 重载()运算符,参数和返回值根据你的需求自定义
返回值类型 operator()(参数列表) const { // 建议加const,保证const对象也能调用
// 在这里写你的逻辑,最后返回对应结果
return 结果;
}
};3.5 空间配置器
空间配置器是 STL 里负责内存分配和释放 的组件,它封装了底层的内存管理逻辑,我们用 STL 容器的时候不需要自己手动**new/delete**,就是空间配置器在幕后工作,它还会处理内存对齐、碎片化等问题,比我们自己管理内存更高效安全。
核心功能
它的工作主要分为四个部分:
- 内存分配:给容器申请存储元素需要的堆内存
- 内存释放:容器销毁、元素删除时,把不用的内存还给系统
- 对象构造:在已经分配好的内存上,调用元素的构造函数初始化对象
- 对象析构:元素删除时,先调用对象的析构函数清理资源,再释放内存
STL 提供了默认的空间配置器**allocator** ,定义在**头文件<memory>**中,绝大多数容器(vector、list、map 等)默认都会用它作为内存管理器,我们平时用容器的时候不需要手动指定。
简单使用演示(模拟 vector 的内存管理逻辑):
cpp
#include <iostream>
#include <memory> // 包含allocator的头文件
#include <string>
using namespace std;
int main() {
// 1. 创建allocator对象,用于分配string类型的内存
allocator<string> alloc;
// 2. 分配3个string大小的未初始化内存(还没有构造对象)
string* ptr = alloc.allocate(3);
// 3. 在已分配的内存上构造对象
alloc.construct(ptr, "apple"); // 第0个位置构造"apple"
alloc.construct(ptr + 1, "banana");// 第1个位置构造"banana"
alloc.construct(ptr + 2, "orange");// 第2个位置构造"orange"
// 4. 访问构造好的对象
for (int i = 0; i < 3; ++i) {
cout << ptr[i] << " "; // 输出 apple banana orange
}
cout << endl;
// 5. 先析构对象(不释放内存)
for (int i = 0; i < 3; ++i) {
alloc.destroy(ptr + i);
}
// 6. 最后释放内存还给系统
alloc.deallocate(ptr, 3);
return 0;
}3.5.1 空间配置器与智能指针
| 对比维度 | 空间配置器 | 智能指针 |
|---|---|---|
| 核心定位 | 面向「容器 / 批量内存」的管理器 | 面向「单个对象 / 资源」的生命周期管理器 |
| 核心职责 | 负责大块连续内存的分配、释放,还要处理内存对齐、内存池优化、批量对象的构造 / 析构,主要给 STL 容器(vector、list 等)做底层内存支撑。 | 负责单个动态对象的自动释放,通过引用计数等机制,保证对象不用了的时候自动释放内存,避免内存泄漏,主要管理零散的动态对象。 |
| 释放时机 | 需要开发者手动调用**deallocate**释放,空间配置器本身不会自动释放内存,它只是把内存管理的步骤封装得更安全高效。 |
不需要手动释放,离开作用域、引用计数归 0 的时候会自动触发内存释放,自动化程度更高。 |
总结
两者是 C++ 内存管理体系里不同层级的工具:
- 你要实现容器、或者需要批量申请释放内存,就用空间配置器;
- 你要管理零散的动态对象,避免内存泄漏,就用智能指针;
- 复杂场景下两者可以搭配使用,各管一层,让内存管理更安全高效。
3.6 配接器
配接器也叫适配器 ,是 STL 里的 "组合转换工具",它可以把一个已有的组件,包装出一个新的接口,让原本不兼容的组件可以一起工作。STL 的配接器主要分三类:容器配接器、迭代器配接器、仿函数配接器。
3.6.1 容器配接器
它基于现有的容器包装,封装出新的容器类型,我们常用的三类容器适配器就是这么来的:
stack:底层默认基于**deque** 实现,封装出 "先进后出(LIFO)" 的接口,只提供**push** (入栈)、pop(出栈)、top(获取栈顶)等方法。queue:底层默认基于**deque** 实现,封装出 "先进先出(FIFO)" 的队列接口,只提供**push** (入队)、pop(出队)、front/back(获取队首 / 队尾)等方法。priority_queue:底层默认基于**vector**实现,内部封装了堆排序逻辑,是优先级队列,每次取出的都是优先级最高的元素(默认最大的元素)。
3.6.2 迭代器配接器
它用来转换迭代器的接口,生成新的迭代器类型,常见的有:
reverse_iterator:反向迭代器,可以把普通迭代器的遍历方向反转,实现从尾到头遍历容器。insert_iterator:插入迭代器,可以把迭代器的 "赋值" 操作转换为 "插入" 操作,避免迭代器越界。