
目录
[1.OpenClaw 是什么?](#1.OpenClaw 是什么?)
[2.1.Gateway 中央控制平面](#2.1.Gateway 中央控制平面)
[2.4.Agents 智能体](#2.4.Agents 智能体)
[1. files 表:文件元数据管理器](#1. files 表:文件元数据管理器)
[2. chunks 表:核心事实存储 (主表)](#2. chunks 表:核心事实存储 (主表))
[3. chunks_vec 表:语义搜索引擎 (向量表)](#3. chunks_vec 表:语义搜索引擎 (向量表))
[4. chunks_fts 表:关键词索引 (全文检索表)](#4. chunks_fts 表:关键词索引 (全文检索表))
[5.附录二:token 消耗的计算](#5.附录二:token 消耗的计算)
[1. 系统固定开销 (System & Tools)](#1. 系统固定开销 (System & Tools))
[2. 工具定义消耗 (Tool Schemas)](#2. 工具定义消耗 (Tool Schemas))
[3. 动态交互与记忆成本](#3. 动态交互与记忆成本)
1.OpenClaw 是什么?
OpenClaw 是一个自托管 Gateway 网关 ,可将你喜爱的聊天应用和渠道表面------包括内置渠道,以及内置或外部渠道插件(如 Discord、Google Chat、iMessage、Matrix、Microsoft Teams、Signal、Slack、Telegram、WhatsApp、Zalo 等)------连接到像 Pi 这样的 AI 编码智能体。你只需在自己的机器(或服务器)上运行一个 Gateway 网关进程,它就会成为你的消息应用与始终可用的 AI 助手之间的桥梁。它适合谁? 适合开发者和高级用户,他们希望拥有一个可以随时随地发消息的个人 AI 助手------同时又不放弃对自己数据的控制,也不依赖托管服务。它有什么不同?
- 自托管:运行在你的硬件上,遵循你的规则
- 多渠道:一个 Gateway 网关可同时服务内置渠道以及内置或外部渠道插件
- 智能体原生:专为支持工具使用、会话、记忆和多智能体路由的编码智能体打造
- 开源:采用 MIT 许可证,由社区驱动
2.OpenClaw--总体架构
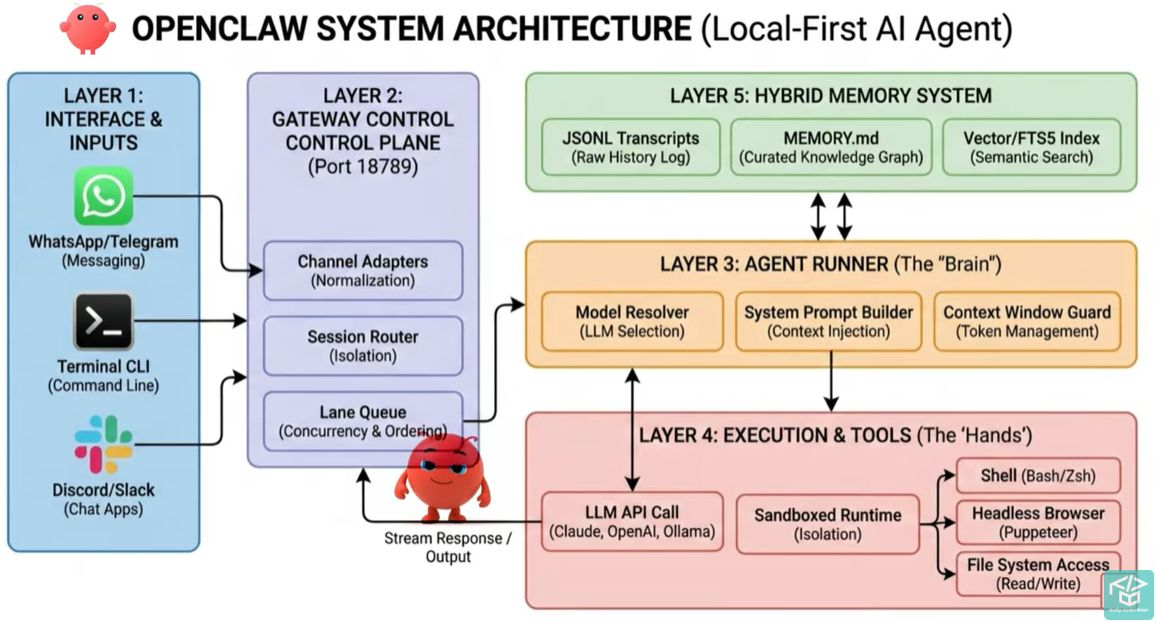
| 层级 | 名称 | 核心组件/渠道 | 关键功能与设计亮点 |
|---|---|---|---|
| L1 | 接口与输入层 | 1. 即时通讯 :WhatsApp, Telegram 2. 终端CLI :命令行输入 3. 团队协作 :Discord, Slack 4. 扩展支持:Cron定时任务, Webhooks | 全场景事件入口 作为系统的"感官",统一接入多渠道事件,覆盖个人、团队及无人值守的自动化触发场景。 |
| L2 | 网关控制平面 | 1. 通道适配器 :格式归一化 2. 会话路由器 :Session Isolation 3. 车道队列:Lane Queue | 流量的归一化、路由与隔离 作为系统的"交通枢纽"。核心亮点是基于车道的串行化执行,消除竞态条件,确保任务可预测、可复现。 |
| L3 | Agent 运行器 | 1. 模型解析器 :LLM Selection 2. 系统提示词构建器 :Context Injection 3. 上下文窗口防护:Token Management | 核心决策与规划中枢 负责任务拆解与规划。独创上下文窗口防护机制,通过摘要压缩而非粗暴截断,解决长周期任务溢出跑偏问题。 |
| L4 | 执行与工具层 | 1. LLM API 调用 :流式响应/异常兜底 2. 沙箱运行时 : - Shell (Bash/Zsh) - 无头浏览器 (Puppeteer) - 文件系统访问 | 真实世界的执行能力 "工具优先"设计理念的体现。开放Shell、浏览器自动化及文件读写能力,实现从"对话"到"做事"的跨越。 |
| L5 | 混合内存系统 | 1. JSONL 对话日志 :Raw History 2. MEMORY.md :知识图谱 3. 向量/FTS5 索引:语义搜索 | 长期记忆与状态持久化 解决Agent"失忆"问题。结合原始日志、Markdown规则库与语义检索,实现精准的记忆召回与审计追溯。 |
根据文档描述,这五层协同工作遵循以下闭环逻辑:
- 输入:事件经L1接入,由L2转化为标准任务。
- 决策:L3调用L5的记忆信息构建Prompt,进行任务规划。
- 执行:L4调用工具操作真实世界,并将结果回传L3。
- 存储:全流程数据持久化写入L5。
- 输出:结果经L2流式返回L1,直至任务完成。
2.1.Gateway 中央控制平面
| 功能模块 | 关键机制与设计 | 核心价值 |
|---|---|---|
| 基础架构 | Node.js 守护进程 + WebSocket 通信 | 提供高并发、长连接的实时通信能力,作为系统常驻入口。 |
| IM 平台适配 | 统一消息模型 | 屏蔽 WhatsApp、Slack 等不同平台的格式差异,将外部消息转换为标准的内部 Message events。 |
| 安全与鉴权 | 集中式 ACL | 统一处理身份认证与权限校验,确保只有合法请求能路由到正确的 Agent,保障系统安全。 |
| 会话路由 | 三要素路由 1. 用户身份 2. 工作区归属 3. 会话上下文 | 精准定位请求归属,确保多用户、多工作区环境下的上下文隔离与正确分发。 |
| 车道队列 | 并发控制层 | 解决高并发场景(如群聊刷屏)下的状态竞争问题。确保每个对话的状态独立维护,防止系统过载崩溃。 |
| 会话管理 | 全生命周期管理 | 负责 Session 的创建、维护、回收。智能处理上下文缓存、截断、归档与重建,管理对话状态。 |
| Agent 装备 | 运行上下文准备 | 在任务执行前,自动加载历史 Session、查找可用 Skills、计算 Tool Policy。让 Agent 拿到一套"即插即用"的完整上下文。 |
| 远程执行审批 | 安全审批网关 | 当 Agent 需要调用远程节点工具(如控制手机拍照)时,Gateway 充当"守门人",进行安全审批后再下发指令。 |
2.2.会话路由
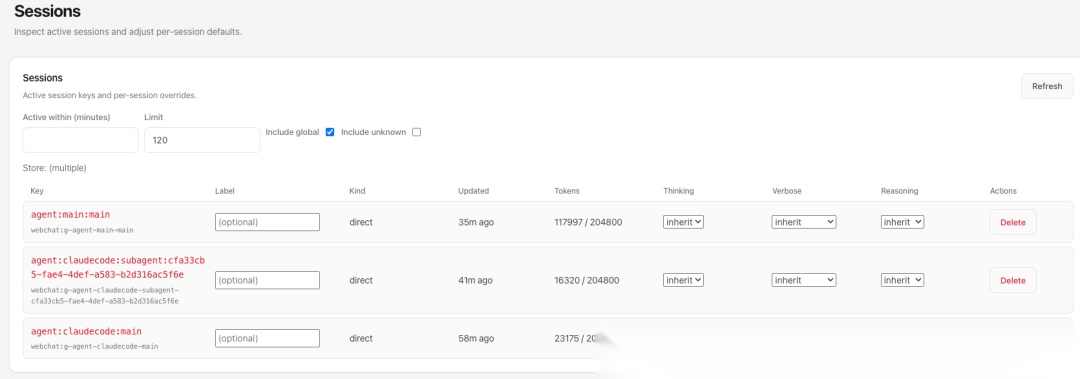
当 Gateway 从 Channel 接收到 Message 后,Gateway 的 Session Router 会根据 Message Session Key 负责将 Message 路由到某个 Agent 的 Session 中。以此来保证 Message 和 Session 的准确匹配。
查看 Session Key:默认的,每个 Agent 至少一个 main Session。此外,在 Subagent 和 Multi-Agent 中还会用于 Agent 之间通信的 Session。
2.3.agent之前
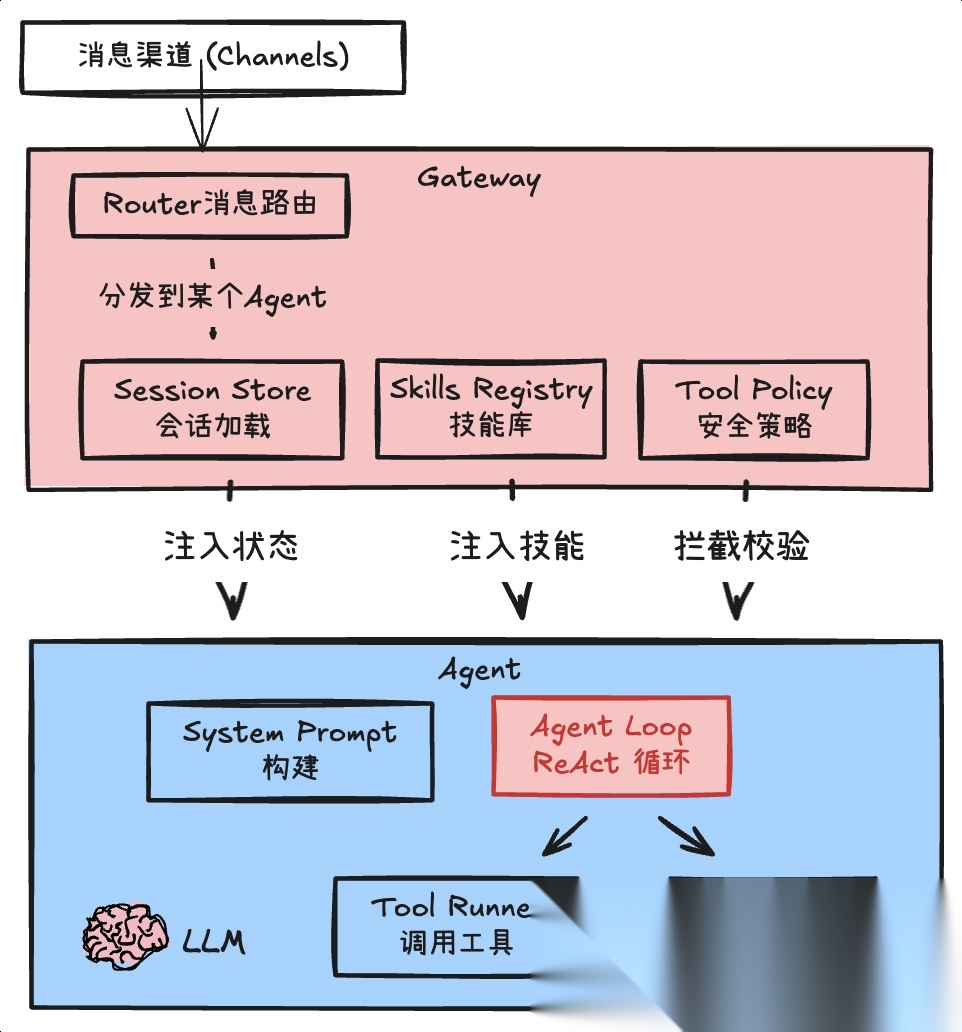
在 OpenClaw 中,Agent 本质上是一个ReAct 循环,而不是一个 Daemon。它不知道自己处于哪个会话、该使用哪些工具、能访问哪些能力。所有这些 "装备",都由 Gateway 在交给 Agent 任务前完成组装,包括:需要将 Session Store、Skill、Tool -Policy 相关的信息加载。
- Session Store:~/.openclaw/agents/main/sessions/,该目录下记录了 Agent 的会话信息。
- Skills:~/.openclaw/workspace/skills,记录了 Agent 安装的技能。
- Tool Policy:记录了 Agent 的工具黑白名单。
2.4.Agents 智能体
OpenClaw 支持 multi-Agent 架构,主智能体称之为 Main Agent,是一个精简高效的编程智能体。 OpenClaw Agent 采用 Agent Loop 运行模式,处理用户消息、执行工具调用、将结果反馈给 LLM,循环直到 LLM 生成无工具调用的响应为止。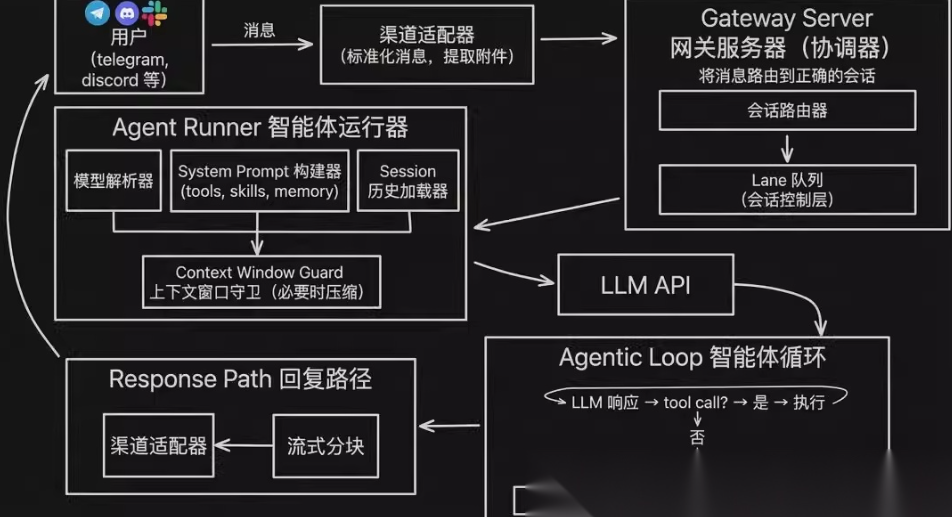
智能体运行器(Agent Runner)
在调用 LLM 之前,Agent Runner 会进行 Context Engineering(上下文工程) 的工作,包括:
- LLM 解析器:动态选择最适用于当前任务的 LLM。
- System Prompt 构建器:根据当前启用的 Skills(如浏览器自动化、文件访问等)动态组装 System Prompt,动态加载和构建可以剩下很多上下文窗口。
- 会话历史加载器:从本地存储的 Workspace 目录下读取持久化的记忆数据。
- 上下文窗口卫士(Context Window Guard):当 Context Windows 接近 LLM OpenAPI 的 Max token 限制时(如 80%),Agent 就会自动压缩,以此来确保对话不中断。但是压缩过后的 Context Windows 很可能会丢失关键对话记录。
准备好最终的 Prompt 集合后,Agent Runner 才会调用 LLM OpenAPI 发送请求,并将 LLM 返回的结果交由下一层 Agentic Loop 来处理。可见在 Agent Runner 环节,token 的用量优化,以及 Context Windows 的有效压缩就成为重要的考量之一。
Agent核心文件:
~/.openclaw/openclaw.json 是全局配置文件,而 Agent 的专属配置文件在 Workspace 目录下,包含了几个关键的 *.md 配置文件。
- AGENTS.md:定义了 Agent 的行为准则,例如:要保障安全、要像人一样回话、要维护记忆等等。推荐仔细阅读。
- IDENTITY.md:定义了 Agent 的身份信息,例如:编程专家、设计师、工程师等等。
- SOUL.md:定义了 Agent 的人格,例如:开朗的、幽默的等等。
- USER.md:定义了主人的信息,例如:主人称呼、主人爱好等等。
- TOOLS.md:定义 Tool 的白名单/黑名单,用于安全控制。
- HEARTBEAT.md(可选):定义了定时任务的配置,当你想让 Agent 定期检查某些内容时,在这里添加任务。
- BOOTSTRAP.md:首次 onboarding 引导,只在第一次启动的时候有效。
- MEMORY.md:长期记忆文档(RAG 源)
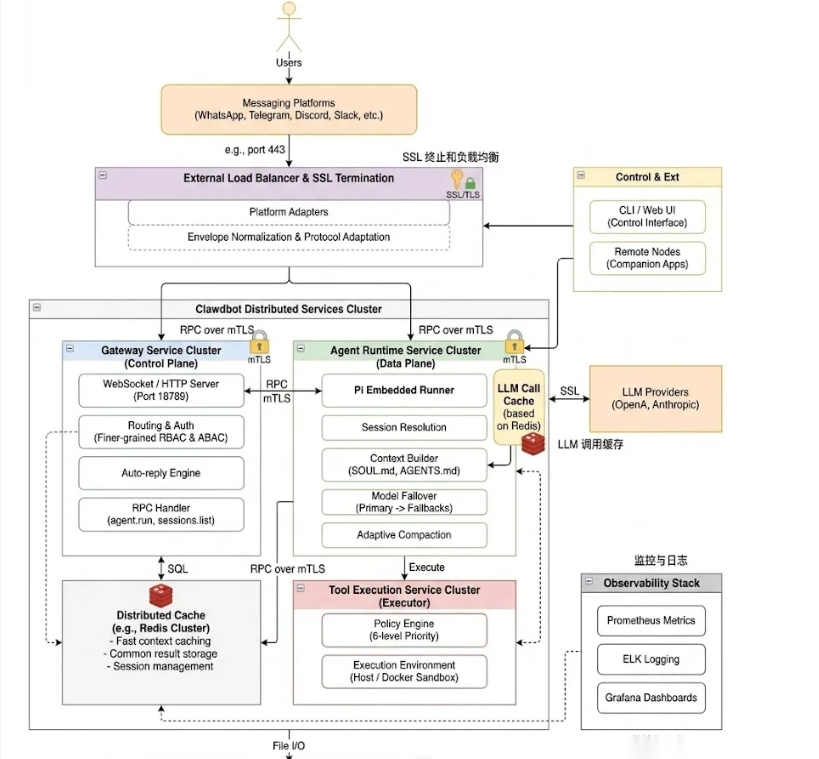
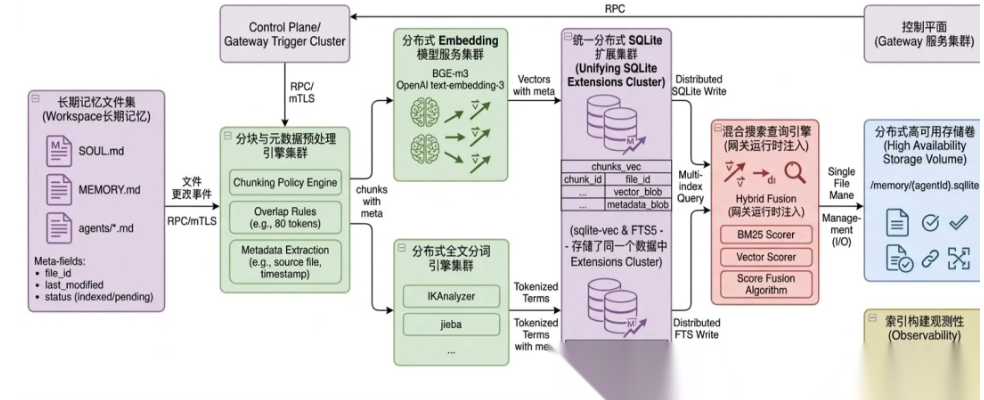
3.OpenClaw记忆系统
核心思想是通过统一的 Gateway 进程管理所有外部通讯平台的链接,通过 Agent Runtime 进行各个大模型的后台调用,所有产生的数据、记忆全部存储在本地磁盘上,其系统架构如下所示:
总结来看,OpenClaw 主要有以下三个优势:
- 使用便捷性:接入了聊天工具,让用户可以随时随地通过自己熟悉的聊天应用与 OpenClaw 交互,让他去完成任务;
- 主观能动性:可以帮用户完成定时任务,仅仅使用自然语言对话就可以让其创建任务,甚至会基于大模型来自主判断任务的紧急程度和执行顺序;
- 长期记忆:可以把用户的交互过程记录在本地,并不断更新,以便在以后的日常对话中进行搜索,将相关记忆捞回上下文中。
如何让类似的智能体真正拥有"记忆",是目前 AI 领域最棘手的问题之一。在行业侧,我们也看到了很多有关 AI 陪伴类、AI 分身类、AI 个人助手类的应用出现,其核心难点也是在解决如何让大模型"记住"与用户有关的尽可能多的信息。当前 AI 类应用面临的核心困境在于:大多数系统只是简单的把"上下文窗口"当作作为的"记忆"。根据 Anthropic 最新的开发者调研,有 68% 的 AI 应用团队都在为"上下文丢失"的问题苦恼。但是,上下文的特点是临时的、有限的(Claude 200K tokens、GPT-4 128K tokens)、昂贵的------当对话超过限制,模型要么会遗忘早期信息,要么因为成本暴涨而不得不重置会话窗口。
而 OpenClaw 的记忆管理系统与上述不同,他将记忆从上下文中剥离出来,构建了一个分层的、可搜索的、持久化的知识管理架构。使得 Agent 能够 7*24h 不间断地积累知识、记住用户偏好、延续历史上下文等,真正实现了从"无状态工具"到"有记忆伙伴"的进化。接下来,主要会针对 OpenClaw 的记忆系统进行分析,从架构设计和工程实现层面展示这个由 AI 自己创造的"大脑"。
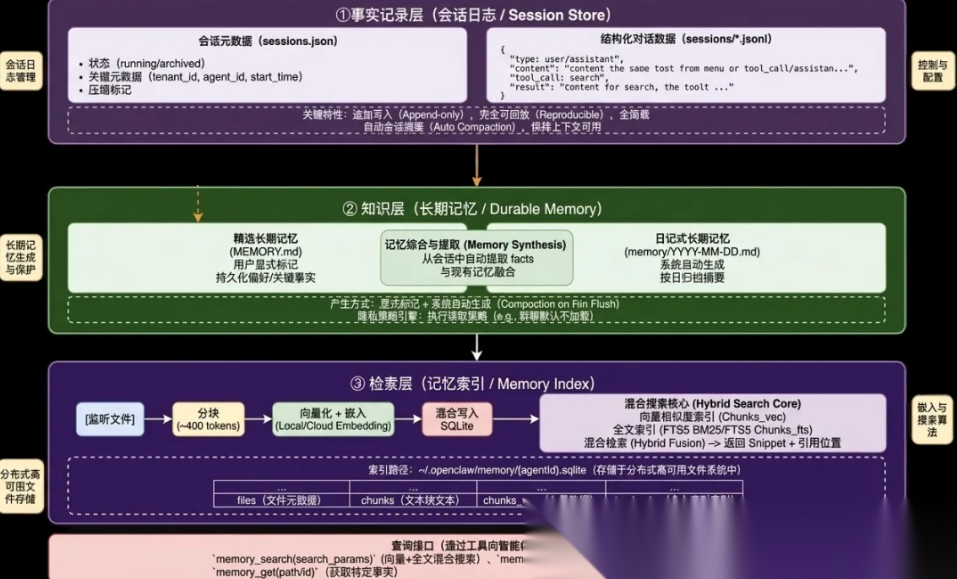
OpenClaw 的记忆系统采用了一个双源记忆架构的设计,其将记忆整体分为了两类:每日日志(动态记忆)和长期记忆 (静态记忆)。

从直觉上看,这是符合人类大脑的记忆机制的,人的记忆也是由一个个重点片段组成的,我们能记住的也只是某个特定的时刻、某件具体的事件,把这些片段串联起来才形成了人类所谓的记忆,至于每天发生的琐事,终究会随着时间而被淡忘。因此,此种记忆机制也可以说是实现了工程学和生物学上的高度统一。
3.1.动态记忆的产生
每次用户与 Agent 交互时,系统会自动将对话内容追加到 JSONL 格式的会话日志文件中,这是最原始的、未经处理过的记忆,存储位置如下:
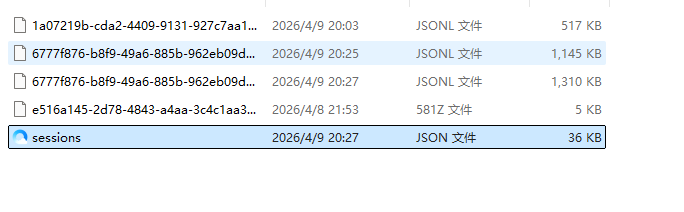
动态记忆的 JOSNL 格式示例如下:
代码转换读取:它的主要作用是将本地存储的 JSONL 格式对话日志,转换成系统(可能是向量索引或记忆模块)易于处理的标准化条目。
php
export async function buildSessionEntry(absPath: string): Promise<SessionFileEntry | null> {
// 读取 JSONL 文件
const raw = await fs.readFile(absPath, "utf-8");
const lines = raw.split("\n");
const collected: string[] = [];
for (const line of lines) {
const record = JSON.parse(line);
// 只提取 user 和 assistant 的消息
if (message.role === "user" || message.role === "assistant") {
const label = message.role === "user" ? "User" : "Assistant";
collected.push(`${label}: ${text}`);
}
}
return {
path: sessionPathForFile(absPath),
hash: hashText(content),
content, // "User: 帮我写... \n Assistant: 好的..."
};
}3.2.静态记忆的生成
静态记忆是整个系统的长期记忆,可以理解成是在短期的琐碎记忆中提炼出来的需要系统重点记住的内容,比如用户的性格、身份信息、回答偏好等,其文件存储结构如下:

静态记忆的产生途径分为以下三种:
- 途径一:用户手动创建。用户可以直接编辑 MEMORY.md 文件,写入需要 Agent 长期记住的信息,比如:"你要称呼我为老板"、"我喜欢简洁的回复"等。;
- 途径二:session-memory Hook 自动转换。当用户执行 /new 命令重置会话时,系统会触发 session-memory Hook,自动将上一个会话的关键内容转换为 Markdown 文件。大致的流程为:
读取会话日志:从 JSONL 文件中提取最近 N 条(默认 15 条)user/assistant 消息;
生成语义化文件名:使用 LLM 根据对话内容生成描述性 slug(如 api-design、bug-fix);
写入 Markdown 文件:生成 memory/YYYY-MM-DD-{slug}.md 文件。
- 途径三:Memory Flush 自动写入(类似于记忆刷新)。这是一个非常关键的自动化机制,当会话上下文接近 token 限制时,系统会在压缩(compaction)前触发一个特殊的 Agent 回合,在该回合中,Agent 被明确指示:将需要持久保存的重要信息写入 memory/YYYY-MM-DD.md 文件。
整个静态记忆系统的设计核心在于途径三,往往"健忘"的问题就出在这一步,即如何进行历史对话信息的压缩。其实此处OpenClaw 的处理方法比较粗暴,是使用 LLM 直接对历史对话信息进行处理。
首先,通过 Memory Flush 进行一次记忆筛选,让 Agent 自己判断什么是"durable memories"(持久记忆),代码如下:
php
export const DEFAULT_MEMORY_FLUSH_PROMPT = [
"Pre-compaction memory flush.",
"Store durable memories now (use memory/YYYY-MM-DD.md; create memory/ if needed).",
`If nothing to store, reply with ${SILENT_REPLY_TOKEN}.`,
].join(" ");然后,最终压缩就是再使用 LLM 对历史消息进行有损摘要,这里的默认指令只要求保留 "decisions, TODOs, open questions, constraints",不保留具体数值、时间点等细节,代码如下:
php
const MERGE_SUMMARIES_INSTRUCTIONS =
"Merge these partial summaries into a single cohesive summary. Preserve decisions," +
" TODOs, open questions, and any constraints.";这正是 OpenClaw 在记忆上的平衡,通过**把历史会话记录(JSONL 格式)压缩成记忆(Markdown 格式),来避免上下文溢出的问题,赋予系统记忆的能力,**但与此同时带来的问题也显而易见,在进行压缩时难免会有信息的流失,这在大多数场景下是合理的,但对于"具体几点"这类精确信息确实是弱点。但并这不是 bug,而是在"长期记忆完整性"和"系统效率/成本"之间的设计取舍。用户如果有重要的精确信息,可以主动要求 Agent 记录到长期记忆中。
好了,现在解释了第一个问题,OpenClaw 到底记住的是什么信息,下面我们来看这些所谓的"记忆"是怎么在需要的时候被"记起来"的。
3.3.记忆信息的检索
当产生并保存一个记忆文件(.md)时,后台会自动触发如下的索引构建流程,并在需要时进行检索:
3.3.1.索引构建
默认情况下,只有 Markdown 文件会被索引,而 JSONL 会话日志不会被索引。**Markdown 文件首先被分块(默认每个块包含 400 tokens,相邻块重叠 80 tokens),而后每个块同时生成向量 Embedding(支持三种,OpenAI、Gemini、本地) 和文本 Token,分别存入 sqlite-vec 和 FTS5 索引,这两个都是 SQLite 扩展,意味着整个系统只依赖一个轻量级数据库文件,不需要部署 ES 或者 Milvus。**SQLite 数据库的核心 Schema 如下所示:
php
-- 文件元数据
CREATE TABLE files (
path TEXT PRIMARY KEY, -- 'memory/projects.md'
source TEXT NOT NULL, -- 'memory' | 'sessions'
hash TEXT NOT NULL, -- SHA256 用于增量更新
mtime INTEGER NOT NULL,
size INTEGER NOT NULL
);
-- 文本块(带 embedding)
CREATE TABLE chunks (
id TEXT PRIMARY KEY, -- UUID
path TEXT NOT NULL, -- 来源文件
source TEXT NOT NULL, -- 'memory' | 'sessions'
start_line INTEGER,
end_line INTEGER,
hash TEXT NOT NULL,
model TEXT NOT NULL, -- 'text-embedding-3-small'
text TEXT NOT NULL, -- 原文
embedding TEXT NOT NULL, -- JSON 数组 [0.1, 0.2, ...]
updated_at INTEGER
);
-- 向量索引(sqlite-vec 扩展)
CREATE VIRTUAL TABLE chunks_vec USING vec0(...);
-- 全文索引(FTS5)
CREATE VIRTUAL TABLE chunks_fts USING fts5(
path, source, model, text,
tokenize='porter unicode61'
);3.3.2.记忆搜索
OpenClaw 采用关键词 + 向量的混合加权搜索,结合了两者的优势。当 Agent 需要搜索记忆时,系统会启动两个搜索引擎:
- 向量搜索:基于语义相似度。把之前向量化之后的内容通过计算余弦相似度找到意思相近的内容,这个直接依赖 sqlite-vec 的扩展实现,无需外部向量数据库;
- BM25 关键词搜索:基于词频统计。使用 SQLite 内置的 FTS5 全文检索引擎,找到包含精确关键词的内容。
混合检索的代码实现方式如下:
php
async search(query: string, opts?: { maxResults?: number; minScore?: number }) {
// 1. 关键词搜索 (BM25)
const keywordResults = hybrid.enabled
? await this.searchKeyword(cleaned, candidates)
: [];
// 2. 向量搜索
const queryVec = await this.embedQueryWithTimeout(cleaned);
const vectorResults = await this.searchVector(queryVec, candidates);
// 3. 混合排序
if (!hybrid.enabled) {
return vectorResults.filter(r => r.score >= minScore).slice(0, maxResults);
}
const merged = this.mergeHybridResults({
vector: vectorResults,
keyword: keywordResults,
vectorWeight: 0.7, // 向量权重
textWeight: 0.3, // 关键词权重
});
return merged.filter(r => r.score >= minScore).slice(0, maxResults);
}两个引擎的搜索结果按照 70:30 的权重合并,最终得分 = 0.7 向量相似度 + 0.3 BM25 得分,且只有得分超过 0.35 的结果才会被返回。混合排序实现方式如下所示:
php
const merged = Array.from(byId.values()).map((entry) => {
// 最终得分 = 向量权重 × 向量相似度 + 关键词权重 × BM25 得分
const score = vectorWeight * entry.vectorScore + textWeight * entry.textScore;
return { path, startLine, endLine, score, snippet, source };
});
return merged.toSorted((a, b) => b.score - a.score);3.3.3.agent交互
基于上述介绍的记忆系统架构,在实际使用时,AI Agent 则是通过两个接口实现与整个记忆系统的交互。
- memory_search:语义搜索
php
return {
label: "Memory Search",
name: "memory_search",
// 工具描述:这是一个强制性的回忆步骤。在回答关于过往工作、决策、日期、人物、偏好或待办事项之前,
// 必须对 MEMORY.md、memory/*.md 以及可选的会话记录进行语义搜索。
description:
"Mandatory recall step: semantically search MEMORY.md + memory/*.md (and optional session transcripts) before answering questions about prior work, decisions, dates, people, preferences, or todos; returns top snippets with path + lines.",
parameters: MemorySearchSchema,
execute: async (_toolCallId, params) => {
// 1. 提取搜索参数
// 获取搜索查询文本(必填项)
const query = readStringParam(params, "query", { required: true });
// 获取期望返回的结果数量(默认为 6 条)
const maxResults = readNumberParam(params, "maxResults");
// 获取最低相关度阈值(默认为 0.35,用于过滤低质量匹配)
const minScore = readNumberParam(params, "minScore");
// 2. 初始化记忆搜索管理器
// 根据当前配置 (cfg) 和 Agent ID 获取管理器实例
const { manager, error } = await getMemorySearchManager({
cfg,
agentId,
});
// ... 执行搜索逻辑 ...
// 3. 执行实际搜索
const results = await manager.search(query, {
maxResults,
minScore,
// 传入当前会话的 Key,可能用于过滤或上下文关联
sessionKey: options.agentSessionKey,
});
// 4. 返回结果
// 将搜索结果以及提供程序、模型状态等信息封装为 JSON 返回
return jsonResult({
results,
provider: status.provider,
model: status.model,
fallback: status.fallback,
});
},
};{
"results": [
{
"path": "memory/2026-01-10.md",
"startLine": 15,
"endLine": 20,
"score": 0.85,
"snippet": "用户提到喜欢蓝色,特别是天空蓝...",
"source": "memory"
},
{
"path": "MEMORY.md",
"startLine": 5,
"endLine": 8,
"score": 0.72,
"snippet": "颜色偏好:蓝色系...",
"source": "memory"
}
],
"provider": "openai",
"model": "text-embedding-3-small"
}
- memory_get:精确读取
你可以把它看作是 Agent 的"精读"功能。与之前的语义搜索不同,这个工具不负责"找",而是负责"读"。它通常在 memory_search 找到大致位置后使用,用来精确读取特定文件的某几行内容,从而避免一次性加载整个大文件,保持上下文窗口的精简。
以下是添加了详细注释的代码:
php
return {
label: "Memory Get",
name: "memory_get",
// 工具描述:用于安全地读取 MEMORY.md、memory/*.md 或配置中的额外路径的片段。
// 支持指定起始行和行数。通常在 memory_search 之后使用,只拉取需要的行,以保持上下文精简。
description:
"Safe snippet read from MEMORY.md, memory/*.md, or configured memorySearch.extraPaths with optional from/lines; use after memory_search to pull only the needed lines and keep context small.",
parameters: MemoryGetSchema,
execute: async (_toolCallId, params) => {
// 1. 提取文件路径参数
// 获取文件的相对路径(例如:memory/2026-01-10.md),这是必填项
const relPath = readStringParam(params, "path", { required: true });
// 2. 提取范围参数
// 获取起始行号(必须是整数)
const from = readNumberParam(params, "from", { integer: true });
// 获取需要读取的行数(必须是整数)
const lines = readNumberParam(params, "lines", { integer: true });
// 3. 执行文件读取
// 调用管理器读取文件片段。如果 from 或 lines 未定义,则传入 undefined(即读取全文或默认行为)
const result = await manager.readFile({
relPath,
from: from ?? undefined,
lines: lines ?? undefined,
});
// 4. 返回结果
return jsonResult(result);
},
};{
"text": "用户提到喜欢蓝色,特别是天空蓝。\n在选择UI时偏好冷色调。\n...",
"path": "memory/2026-01-10.md"
}
- Agent 记忆交互的指令约束
Agent 被明确指示必须在特定场景下使用记忆工具:
php
return [
"## Memory Recall",
"Before answering anything about prior work, decisions, dates, people, preferences, or todos: run memory_search on MEMORY.md + memory/*.md; then use memory_get to pull only the needed lines. If low confidence after search, say you checked.",
"",
];- Agent 主动写入记忆
在 OpenClaw 的交互中,Agent 也可以主动写入记忆文件,使用标准的文件操作工具。比如,当 Agent 判断需要记住某些信息时,会使用 exec 或 write 工具写入对应的 memory/YYYY-MM-DD.md 文件,例如:
php
exec(command="echo '## 用户偏好\n- 喜欢蓝色' >> memory/...")
write(path="memory/2026-02-05.md", content="用户喜欢蓝色")而后 MemoryIndexManager 检测到文件变更 (fs.watch),会触发增量同步和更新 SQLite 索引,这在上文提到的 Memory Flush 场景中特别重要。
- 限制了 Agent 能够读取的文件范围。
它通过层层校验,确保 Agent 只能访问特定的 Markdown 记忆文件,防止其越界读取系统敏感文件。
php
async readFile(params: {
relPath: string;
from?: number;
lines?: number;
}): Promise<{ text: string; path: string }> {
// ... 路径验证逻辑 ...
// 1. 检查工作区内的相对路径安全性
// 确保路径不为空、不以 ".." 开头(防止目录穿越)、且不是绝对路径
const inWorkspace =
relPath.length > 0 && !relPath.startsWith("..") && !path.isAbsolute(relPath);
// 2. 检查是否在允许的记忆目录中
// 结合上述安全检查,确认该路径属于合法的 memory 工作区
const allowedWorkspace = inWorkspace && isMemoryPath(relPath);
// 3. 核心安全限制:白名单校验
// 只允许读取以下三类文件:
// - MEMORY.md / memory.md (核心记忆)
// - memory/*.md (记忆目录下的文件)
// - 配置中指定的 extraPaths 下的 .md 文件
if (!allowedWorkspace && !allowedAdditional) {
throw new Error("path required"); // 如果不在白名单内,直接抛出错误拦截
}
// 4. 文件类型限制
// 强制要求文件必须以 .md 结尾,防止读取 .env、.json 或其他敏感配置文件
if (!absPath.endsWith(".md")) {
throw new Error("path required"); // 非 Markdown 文件将被拒绝
}
// ... 后续读取操作 ...
}3.4.实例:记忆系统交互流程
场景:用户询问 "我之前说过喜欢什么颜色?"
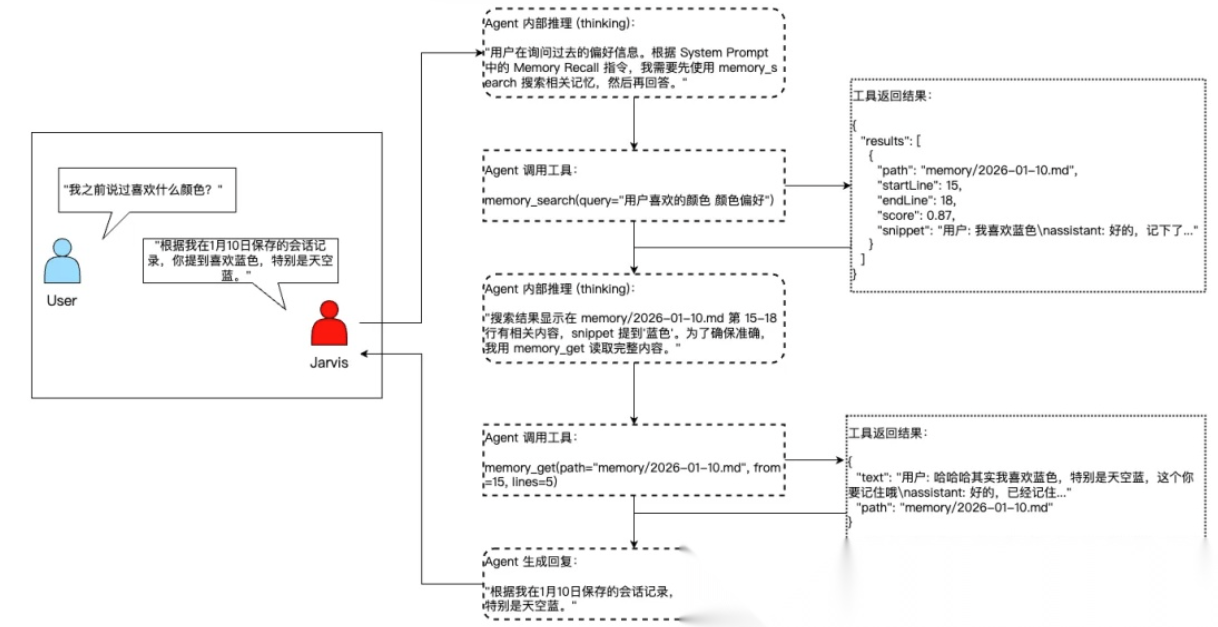
不难看出,类似 OpenClaw 类型的个人助手,使用体验大大依赖于所选用的基础大模型的性能,如果选择某些开源的轻量化模型,很容易陷入复杂工具调用的死循环,而选择更优性能的闭源模型又会带来不可避免的成本开销,那么问题来了:C 端用户到底需不需要更高性能的模型?
4.附录一:记忆索引的实现流程
将结合具体的例子,详细整理记忆索引的完整流程。
首先我们假设一个场景,用户在 1 月 10 日与 Agent 进行了一次对话,讨论了需要 Agent 设置提醒的事项,在用户执行 /new 命令后,session-memory 会自动将该对话进行提取并转化为 Markdown 文件如下:
文件路径:~/.openclaw/memory/2026-01-10-reminders.md
php
# Session: 2026-01-10 08:00:15 UTC
## Summary
用户请求设置每日提醒,讨论了健身计划安排。
## Key Points
- 用户想要每天下午3点收到健身提醒
- 健身计划包括:周一胸肌、周三背部、周五腿部
- 用户偏好使用 Telegram 接收提醒通知
## Conversation Highlights
User: 帮我设置一个每日提醒,下午3点提醒我去健身
Assistant: 好的,我已经为你设置了每日下午3点的健身提醒。
User: 对了,我的健身计划是周一练胸,周三练背,周五练腿
Assistant: 明白了,我已记录你的健身计划安排。
## Action Items
- [x] 设置每日 15:00 健身提醒
- [ ] 后续可添加具体训练动作细节Step 1: 文件发现与变更检测
当存入了新的记忆文件,会调用 sync() 方法,系统首先会扫描记忆目录,检测哪些文件需要索引,如果发现记忆文件没有变化,那么也就不需要重新构建一次索引。
- 列出所有记忆文件:
找到所有和记忆有关的文件,为下一步的判重做准备:
php
const files = await listMemoryFiles(this.workspaceDir, this.settings.extraPaths);
// 结果: ["~/.openclaw/MEMORY.md", "~/.openclaw/memory/2026-01-10-reminders.md", ...]- 构建文件元信息:
对每个文件调用 buildfileEntry(),只读取文件并计算整体 hash,不做分块等处理。
php
// buildFileEntry 实现
const stat = await fs.stat(absPath);
const content = await fs.readFile(absPath, "utf-8"); // 读取整个文件
const hash = hashText(content); // 计算整个文件的 hash
return {
path: "memory/2026-01-10-reminders.md",
absPath: "/Users/xxx/.openclaw/memory/2026-01-10-reminders.md",
mtimeMs: 1736496015000,
size: 847,
hash: "e4d909c290d0fb1ca068ffaddf22cbd0" // 整个文件内容的 MD5
};- 判断是否需要重新索引:
结合上述文件的 hash 就可以判断出新产生的记忆文件是否与原有的文件相同,如果相同就说明记忆没有变化,省去了重新索引这一步。
php
const record = this.db
.prepare(`SELECT hash FROM files WHERE path = ? AND source = ?`)
.get(entry.path, "memory");
// 情况A: 数据库中无记录,或 hash 不匹配 → 需要索引
// 情况B: hash 匹配 → 跳过,无需重新索引
if (!params.needsFullReindex && record?.hash === entry.hash) {
return; // 跳过
}
await this.indexFile(entry, { source: "memory" }); // 需要索引这个情境中我们假设记忆是新的,那么此时会输出结果:
php
[需要索引] memory/2026-01-10-reminders.md (hash: e4d909c290d0fb1ca068ffaddf22cbd0)6.2 Step 2: 文本分块
经过上一步,只有确定需要索引的文件,才会使用 indexFile() 方法进行分块处理。调用的分块函数如下:
php
const content = await fs.readFile(entry.absPath, "utf-8");
const chunks = chunkMarkdown(content, this.settings.chunking);
// 默认配置: { tokens: 400, overlap: 80 }
export function chunkMarkdown(
content: string,
chunking: { tokens: number; overlap: number },
): MemoryChunk[] {
const lines = content.split("\n");
const maxChars = Math.max(32, chunking.tokens * 4); // 1600 chars
const overlapChars = Math.max(0, chunking.overlap * 4); // 320 chars
const chunks: MemoryChunk[] = [];
let current: Array<{ line: string; lineNo: number }> = [];
let currentChars = 0;
const flush = () => {
// 将当前累积的行打包成一个 chunk
const text = current.map((entry) => entry.line).join("\n");
const startLine = firstEntry.lineNo;
const endLine = lastEntry.lineNo;
chunks.push({
startLine,
endLine,
text,
hash: hashText(text), // SHA-256(chunk文本)
});
};
const carryOverlap = () => {
// 保留最后 overlapChars 个字符到下一个 chunk(滑动窗口)
// ...
};
for (let i = 0; i < lines.length; i += 1) {
// 逐行累积,超过 maxChars 就 flush
if (currentChars + lineSize > maxChars && current.length > 0) {
flush();
carryOverlap(); // 保留重叠部分
}
current.push({ line: segment, lineNo });
currentChars += lineSize;
}
flush(); // 最后一批
return chunks;
}上述步骤中的分块算法按照以下规则切分文本:
- 按行遍历,累积字符数(默认约为 tokens * 4 个字符);
- 遇到 Markdown 标题(#)时优先断开,保持语义完整;
- 块之间有重叠(默认约 overlap * 4 个字符),确保跨块检索的连续性。
按照实例文件,分块之后可能会被切分为 2 个块:
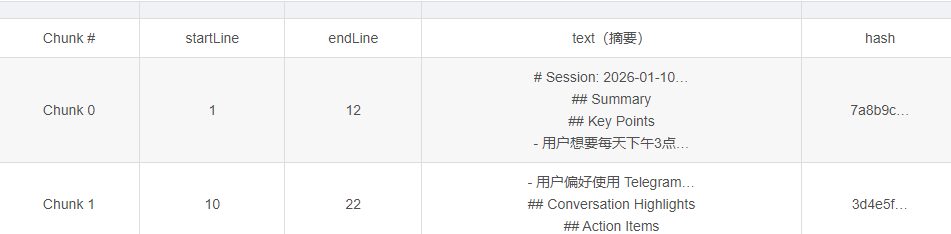
Step 3: 向量化(Embedding)
上述每个 Chunk 的文本需要转化为向量,用于进行语义搜索。首先系统会先查询已有的 embedding_cache 表,看是否已经有相同文本的向量缓存:
php
const cached = this.loadEmbeddingCache(chunks.map(chunk => chunk.hash));
// 如果 chunk.hash 在缓存中命中,直接复用向量,跳过 API 调用对于缓存未命中的 Chunk,调用配置好的 embedding provider(如 OpenAI),返回向量化后的结果。
php
// 批量请求 embedding
const batchEmbeddings = await this.provider.embedBatch([
"# Session: 2026-01-10 08:00:15 UTC\n\n## Summary\n用户请求设置每日提醒...",
"- 用户偏好使用 Telegram...\n\n## Conversation Highlights..."
]);
// 返回结果(1536维向量,text-embedding-3-small)
// Chunk 0: [0.0234, -0.0567, 0.0891, ..., -0.0123] (1536个浮点数)
// Chunk 1: [0.0345, -0.0678, 0.0902, ..., -0.0234] (1536个浮点数)而后更新向量缓存:
php
this.upsertEmbeddingCache([
{ hash: "7a8b9c...", embedding: [0.0234, -0.0567, ...] },
{ hash: "3d4e5f...", embedding: [0.0345, -0.0678, ...] }
]);Step 4: 持久化存储
向量化完成后,系统会将上述数据写入 SQLite 数据库中的三张表。
- 生成 Chunk ID:
首先,需要先为每个 chunk 生成唯一的标识,其是由多个因素组合 hash 生成。
php
const id = hashText(
`${source}:${path}:${startLine}:${endLine}:${chunkHash}:${model}`
);
// Chunk 0 的 id 计算:
// hashText("memory:memory/2026-01-10-reminders.md:1:12:7a8b9c...:text-embedding-3-small")
// → "a1b2c3d4e5f6..."
// Chunk 1 的 id 计算:
// hashText("memory:memory/2026-01-10-reminders.md:10:22:3d4e5f...:text-embedding-3-small")
// → "g7h8i9j0k1l2..."-
写入 chunks 主表:
phpthis.db.prepare(` INSERT INTO chunks (id, path, source, start_line, end_line, hash, model, text, embedding, updated_at) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) `).run( "a1b2c3d4e5f6...", // id "memory/2026-01-10-reminders.md", // path "memory", // source 1, // start_line 12, // end_line "7a8b9c...", // chunk hash "text-embedding-3-small", // model "# Session: 2026-01-10...", // 原始文本 "[0.0234, -0.0567, ...]", // 向量 (JSON 字符串) 1736496100000 // updated_at ); -
写入 chunks_vec 向量表:
此处的 sqlite_vec 为虚拟表,专门用于向量相似度(语义相似度)的搜索,表中存储的内容示例如下:
php
this.db.prepare(`INSERT INTO chunks_vec (id, embedding) VALUES (?, ?)`)
.run(
"a1b2c3d4e5f6...", // 与 chunks 表相同的 id
vectorToBlob([0.0234, ...]) // 转换为二进制 BLOB 格式
);- 写入 chunks_fts 全文搜索表:
此处的 FTS5 也是虚拟表,而且 SQLite FTS5 会自动对 text 字段进行分词,不需要手动进行分词处理。
php
this.db.prepare(`
INSERT INTO chunks_fts (text, id, path, source, model, start_line, end_line)
VALUES (?, ?, ?, ?, ?, ?, ?)
`).run(
"# Session: 2026-01-10...", // text (FTS5 自动分词)
"a1b2c3d4e5f6...", // id (UNINDEXED,不分词)
"memory/2026-01-10-reminders.md", // path (UNINDEXED)
"memory", // source (UNINDEXED)
"text-embedding-3-small", // model (UNINDEXED)
1, // start_line (UNINDEXED)
12 // end_line (UNINDEXED)
);上述有些字段标记为 UNINDEXED,意味着不会参与全文搜索索引,只是作为元数据进行存储,方便后续 JOIN 查询和过滤,只有 text 字段会被 FTS5 分词和建立倒排索引。
- 更新 files 表:
上述存储完成后,会再次记录文件级别的元信息,用于下次进行变更检测。
php
this.db.prepare(`
INSERT INTO files (path, source, hash, mtime, size) VALUES (?, ?, ?, ?, ?)
ON CONFLICT(path) DO UPDATE SET hash=excluded.hash, mtime=excluded.mtime, size=excluded.size
`).run(
"memory/2026-01-10-reminders.md",
"memory",
"e4d909c290d0fb1ca068ffaddf22cbd0", // 整个文件的 hash
1736496015000,
847
);| 表名 | 角色定位 | 核心功能与设计亮点 | 关键字段 |
|---|---|---|---|
| files | 元数据管理器 (目录) | 增量更新机制:记录文件宏观状态。通过比对 MD5 哈希值,若文件未变则跳过索引,极大提升同步效率。 | hash (MD5值) mtime (修改时间) |
| chunks | 核心事实存储 (The Truth) | 主数据表:存储所有可检索的记忆片段及其上下文。支持精准溯源(定位到具体文件)和精确行号读取。 | start_line / end_line (位置) path / source (溯源) text (原始文本) embedding (JSON字符串) |
| chunks_vec | 语义搜索引擎 (向量) | 高性能向量检索:基于 SQLite-Vec 扩展的虚拟表。使用 BLOB 格式存储向量,相比 JSON 速度更快、空间更省(约 6KB),实现毫秒级语义搜索。 | embedding (BLOB 二进制) |
| chunks_fts | 关键词索引 (全文) | 倒排索引:基于 SQLite FTS5 扩展。自动对文本分词,负责快速筛选包含特定关键词(如"蓝色")的候选集,用于混合检索。 | text (分词索引) |
1. files 表:文件元数据管理器
角色 :数据库的"目录"。
作用:记录文件的宏观状态(如修改时间、大小、哈希值),用于增量更新检测。系统通过比对哈希值判断文件是否变更,避免重复索引。
表格
| 字段名 | 值示例 | 说明 |
|---|---|---|
| path | memory/2026-01-10-reminders.md |
文件相对路径 (Primary Key) |
| source | memory |
数据来源类型 (memory 或 sessions) |
| hash | e4d909c290d0fb1ca068ffaddf22cbd0 |
文件内容的 MD5 哈希值,用于检测变更 |
| mtime | 1736496015000 |
文件最后修改时间 (Timestamp) |
| size | 847 |
文件大小 (Bytes) |
2. chunks 表:核心事实存储 (主表)
角色 :主数据表 (The Truth)。
作用:存储所有可供检索的记忆片段及其完整的上下文信息。它是一个宽表,包含了文本、位置信息以及 JSON 格式的向量。
表格
| 字段名 | 值示例 | 说明 |
|---|---|---|
| id | a1b2c3d4e5f6... |
块唯一 ID (由 source+path+行号+文本哈希生成) |
| path | memory/2026-01-10-reminders.md |
所属文件路径 |
| source | memory |
来源类型 |
| start_line | 1 |
该片段在原文件中的起始行号 |
| end_line | 12 |
该片段在原文件中的结束行号 |
| hash | 7a8b9c... |
该文本块内容的哈希值 |
| model | text-embedding-3-small |
生成向量所用的嵌入模型名称 |
| text | # Session: 2026-01-10...\n用户请求设置... |
原始文本片段 (Markdown 格式) |
| embedding | [0.0234,-0.0567,...] |
嵌入向量的 JSON 字符串形式 (便于读取) |
3. chunks_vec 表:语义搜索引擎 (向量表)
角色 :SQLite-Vec 虚拟表。
作用 :专为向量相似度搜索 (语义搜索)优化。它将 chunks 表中的向量转换为二进制格式,利用余弦相似度算法实现毫秒级的语义匹配。
表格
| 字段名 | 值示例 | 说明 |
|---|---|---|
| id | a1b2c3d4e5f6... |
对应 chunks 表的 ID |
| embedding | <binary: ...> |
BLOB 二进制数据。存储 float32 数组 (如 1536 维),计算速度快,占用空间小。 |
4. chunks_fts 表:关键词索引 (全文检索表)
角色 :SQLite FTS5 虚拟表。
作用 :专为关键词匹配设计。它会对文本进行分词(Tokenization),建立倒排索引,用于快速筛选包含特定关键词(如"提醒"、"Telegram")的候选集。
表格
| 字段名 | 值示例 | 说明 |
|---|---|---|
| text | # Session: 2026-01-10... |
被分词索引的原文本内容 |
| id | a1b2c3d4e5f6... |
关联 ID (UNINDEXED) |
| path | memory/2026-01-10-reminders.md |
文件路径 (UNINDEXED) |
| source | memory |
来源 (UNINDEXED) |
| model | text-embedding-3-small |
模型 (UNINDEXED) |
| start_line | 1 |
起始行 (UNINDEXED) |
| end_line | 12 |
结束行 (UNINDEXED) |
5.附录二:token 消耗的计算
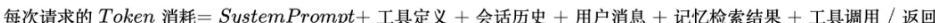
1. 系统固定开销 (System & Tools)
| 组成部分 | 大小估算 | 说明 |
|---|---|---|
| 核心指令 | ~3,000 字符 | 包含安全规则、回复格式、消息路由等 |
| 工具说明列表 | ~2,000 字符 | 每个工具的简要说明 |
| Bootstrap 文件 | 最大 20,000 字符 | 如 AGENTS.md, SOUL.md, IDENTITY.md 等 |
| 运行时信息 | ~500 字符 | 主机、时区、模型等信息 |
| 沙箱信息 | ~300 字符 | Sandbox 配置信息 |
| Skills 提示 | 可变 | 技能描述和位置信息 |
2. 工具定义消耗 (Tool Schemas)
| 工具名称 | Schema 复杂度 | 估算 Tokens |
|---|---|---|
| browser | 非常复杂 (16种 action) | ~800 |
| message | 复杂 (多种 action) | ~400 |
| nodes | 复杂 | ~300 |
| sessions_ | 中等 | ~400 |
| exec | 中等 | ~200 |
| cron | 中等 | ~200 |
| canvas | 中等 | ~200 |
| read/write/edit | 简单 | ~300 |
| memory_search/get | 简单 | ~150 |
| 总计估算 | --- | 3000-5000 (且无法压缩) |
3. 动态交互与记忆成本
| 成本类型 | 产生原因 | 详细说明 |
|---|---|---|
| 会话历史累积 | 上下文窗口机制 | 历史消息逐轮累积(System + Msg1 + Reply1 + Msg2...); 默认压缩阈值极高(约 20,000 字符),在此之前 Token 持续增长。 |
| Memory Flush | 记忆持久化 | 触发压缩前的独立 LLM 调用,需消耗完整的一轮 Prompt 成本。 |
| 检索结果注入 | 上下文增强 | memory_search 返回的片段(Snippet)和引用位置会被加入上下文。 |
| 工具调用链 | 双向计费 | 每次工具调用包含"请求+响应"; 例如查天气并发 Telegram 可能触发 3 次调用,双向计费。 |