三、决策树回归算法(Decision Tree)
1、核心思想
通过不断选择特征进行划分:
- 将数据空间划分为多个区域
- 每个区域对应一个预测值
本质类似一系列 if-else 规则。
简单地说是从样本数据的特征属性中,通过学习简单的决策规则,也就是我们耳熟能详的 IF ELSE 规则,来预测目标变量的值。这个算法的核心是划分点的选择和输出值的确定。
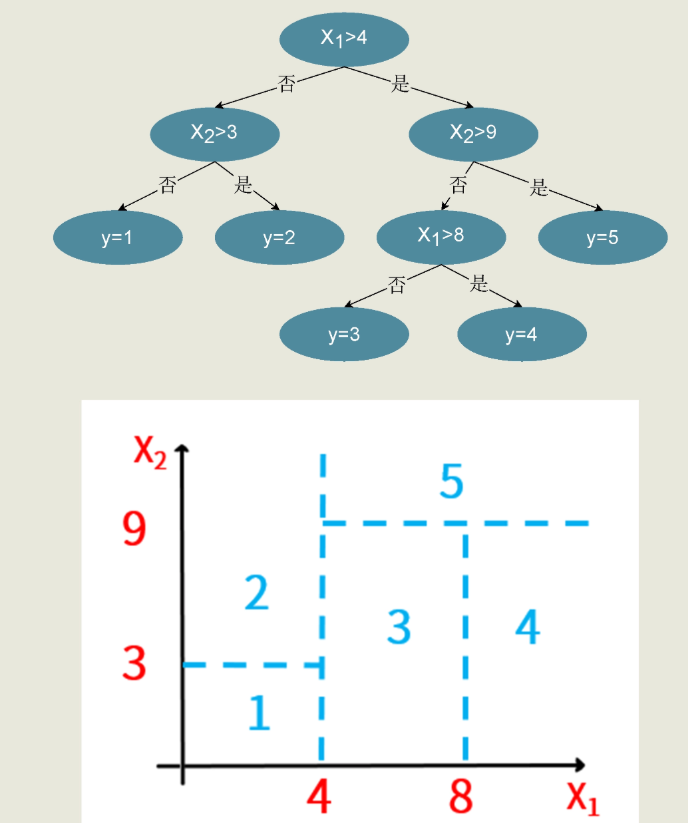
这种算法是根据两个特征 x1 和 x2 的值,以及标签 y 的取值,来对二维平面上的区域进行精准分割,以确定从特征到标签的映射规则。根据树的深度和分叉时所选择的特征的不同,我们可以训练出很多棵不一样的树来。
2、划分标准
回归问题中通常使用:
- 最小化均方误差(MSE)
- 或最小化方差
3、代码示例
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(max_depth=3)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)4、优缺点
优点:
- 能处理非线性关系
- 可解释性强
缺点:
- 容易过拟合
- 对数据波动敏感
四、随机森林回归算法(Random Forest)
1、定义
随机森林是一种典型的集成学习方法:
通过构建多棵决策树,并对结果进行平均来提高模型性能。
由多棵决策树构成的集成学习算法。它既能用于分类问题,也能用于回归问题。而且无论是解决哪类问题,它都是相对优秀的算法。在训练模型的过程中,随机森林会构建多个决策树,如果解决的是分类问题,那么它的输出类别是由个别树输出的类别的众数而定;如果解决的是回归问题,那么它会对多棵树的预测结果进行平均。
随机森林纠正了决策树过度拟合其训练集的问题,在很多情况下它都能有不错的表现。这里的"过拟合",其实就是说模型对训练集的模拟过头了,反而不太适合验证集和测试集。
2、核心机制
- Bootstrap 采样(有放回抽样)
- 随机选择特征
- 多模型集成
3、预测方式
- 回归:取平均值
4、代码示例
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
from sklearn.linear_model import LinearRegression #导入线性回归模型
from sklearn.tree import DecisionTreeRegressor #导入决策树回归模型
from sklearn.ensemble import RandomForestRegressor #导入随机森林回归模型
#创建模型
model_lr = LinearRegression() #创建线性回归模型
model_dtr = DecisionTreeRegressor() #创建决策树回归模型
model_rfr = RandomForestRegressor() #创建随机森林回归模型
#训练,不要小看这几个简单的 fit 语句,这是模型进行自我学习的关键过程。
model_lr.fit(X_train, y_train) #拟合线性回归模型
model_dtr.fit(X_train, y_train) #拟合决策树模型
model_rfr.fit(X_train, y_train) #拟合随机森林模型5、优点
- 抑制过拟合
- 泛化能力强
- 表现稳定
对于决策树和随机森林算法来说,它们既有回归算法(Regressor),也有分类算法(Classifer)。
在线性回归算法中,机器是通过梯度下降,逐步减少数据集拟合过程中的损失,让线性函数对特征到标签的模拟越来越贴切。而在决策树模型中,算法是通过根据特征值选择划分点来确定输出值的;在随机森林算法中,机器则是生成多棵决策树,并通过 Bagging 的方法得到最终的预测模型。