1 引言
现代消费类高性能计算硬件正处于"分水岭"两端:桌面端追求极致的性能天花板,而移动端则是一场关于资源节约的精密艺术。不同于桌面 GPU 可以依靠巨大的功耗空间和独立显存来换取性能,移动 GPU 自诞生之初就被嵌套在三个严苛的物理维度中:
- 功耗 (Power Envelope): 电池容量的上限与极小的散热空间,决定了性能必须在"能效比"的毫厘间取舍。
- 带宽 (Memory Bandwidth): 移动端采用统一内存架构,GPU 必须与 CPU 争夺内存带宽,且高频数据交换是耗电的"元凶"。
- 面积 (Die Area): 芯片面积直接关乎制造成本。在移动 SoC(片上系统)中,每一平方毫米的面积都必须产出最大的算力价值。
移动端 GPU 的生态版图主要由三大核心阵营构成:高通(Qualcomm)的 Adreno、Arm 的 Mali 以及苹果(Apple)的自研GPU。与NVIDIA、AMD桌面GPU不同------桌面GPU采用Immediate-mode Rendering(IMR)架构,追求高吞吐,而 Mali 自始至终坚持 Tile-Based Rendering(TBDR),以带宽优化为核心,适配移动设备的资源约束。
1.1 Tile-Based Rendering
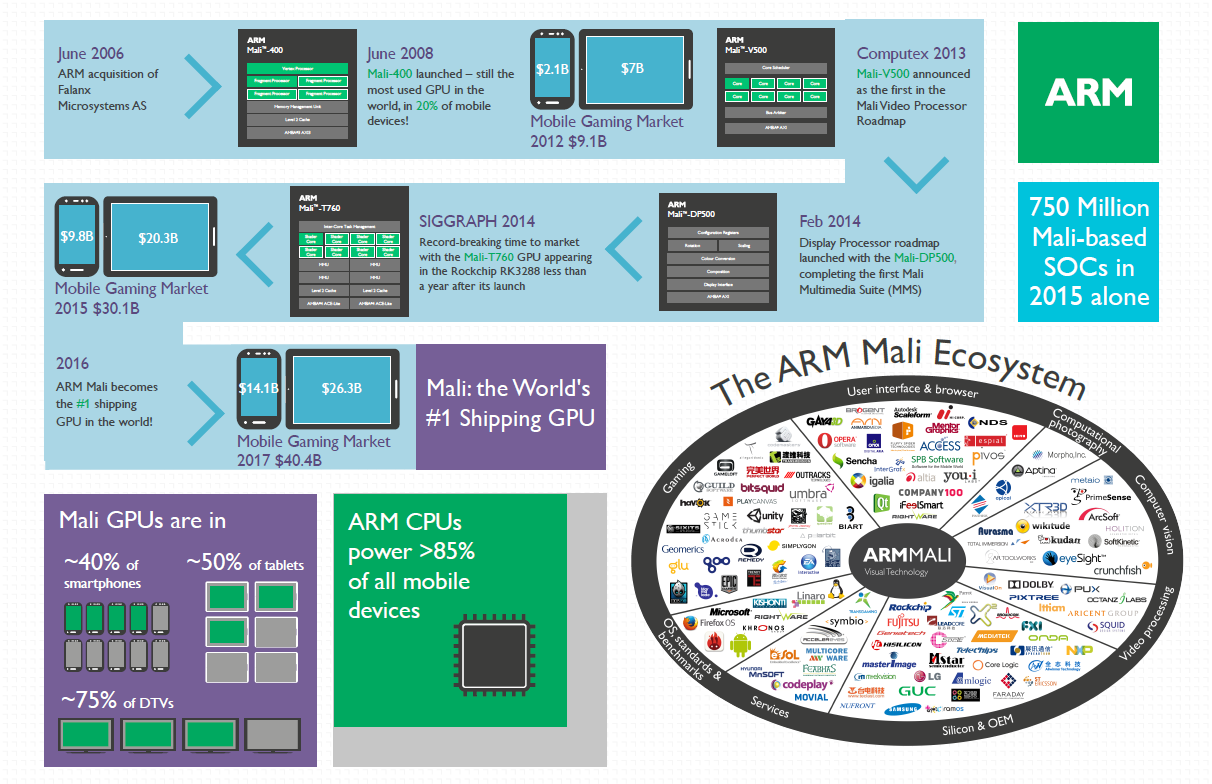
Mali GPU 采用基于图块的渲染架构(Tile-based Rendering)。这意味着 GPU 将输出的帧缓冲区划分为若干个独立的 16x16 像素小区域(图块),并在渲染完成后将每个处理完的图块写入内存。
立即模式 GPU (Immediate Mode Rendering)
传统桌面 GPU 架构遵循严格的命令流,在每次绘制调用(Draw Call)中,按顺序对每个图元完整执行顶点着色器和片元着色器。
伪代码示例:
python
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
for fragment in primitive:
execute_fragment_shader(fragment)- 优点 :
- 实现简单:无需预先处理几何数据,适合复杂的固定渲染管线。
- 低延迟:无需等待所有几何体处理完成,发现图元即可立即渲染。
- 缺点 :
- 内存带宽瓶颈:高频率地读写外部显存以获取纹理和更新深度/颜色缓冲区,导致功耗大、带宽占用极高。
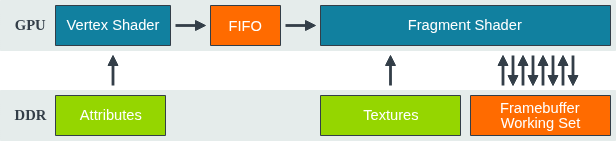
基于图块的 GPU (Tile-based Rendering)
Mali GPU 采用双通道渲染方式,最大限度减少了片元着色期间对外部内存的访问需求。
伪代码示例:
python
# Pass one
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
append_tile_list(primitive)
# Pass two
for tile in renderPass:
for primitive in tile:
for fragment in primitive:
execute_fragment_shader(fragment)- 优点 :
- 内存效率极高:通过片上缓存(Tile Buffer)处理像素,避开了繁重的外部内存带宽,显著降低了功耗(这对于移动设备至关重要)。
- 局部性好:纹理采样和深度测试在高速片上存储器完成,性能更优。
- 缺点 :
- 预处理开销:必须先执行完一遍几何处理(Tiling Pass)才能开始着色,导致增加了额外的几何存储开销。
- 内存需求:在处理极其复杂的场景时,生成的"图块列表"数据结构可能会占用额外的片上或系统内存。
2 Utgard 架构
Utgard作为Mali系列GPU的第一代产品,属于移动GPU的早期过渡阶段,典型代表包括Mali-200、Mali-400、Mali-450及Mali-470,其设计核心聚焦于"满足基础图形渲染需求",尚未实现真正的可编程与通用计算能力。
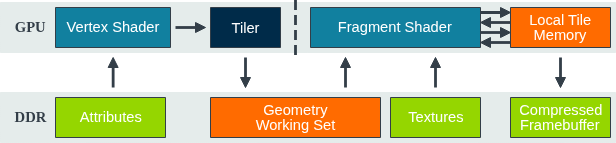
Utgard GPU采用两种不同的着色器核心设计------顶点着色器和片元着色器,所有Utgard GPU均支持单个顶点着色核心,而硅芯片中着色核心的具体数量则因芯片型号而异。Arm向各芯片合作方提供可配置设计授权,合作方可根据自身性能需求与芯片面积限制,灵活配置其特定芯片组中的GPU:例如Mali-400和Mali-470最多支持四个片段着色器核心,Mali-450则最多支持八个。
顶点着色器核心与分块器共享一个小型L2缓存,该缓存在着色管线的数据交换过程中充当缓冲区,有效减少数据从顶点着色器传递至固定功能图元汇编单元时的内存带宽占用。Utgard顶点着色器核心处理串行流中的着色顶点,随后将结果传递至固定功能的平铺单元,完成图元组装、裁剪、剔除及图块列表生成等操作;需要注意的是,Utgard GPU始终仅配备一个顶点着色器核心,其几何处理能力不会随片段着色器核心数量的增加而提升。
片段着色器核心则共享一个更大的L2缓存,以此降低因共享数据获取(如顶点输入、跨多个图块的图元纹理等)产生的内存带宽消耗。Utgard片段着色器核心由一条可编程单一流水线构成,流水线中封装了用于生成新片段线程和回收已完成片段线程的固定功能逻辑。
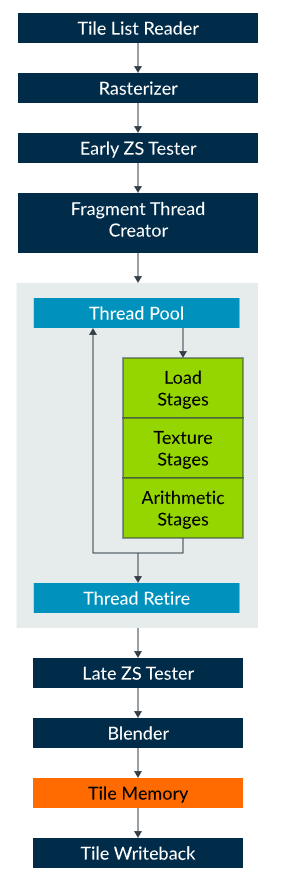
可编程片段着色器核心是一款多线程处理引擎,可同时运行多达128个线程,每个运行线程对应一个片段着色器程序实例。大量线程的设计目的的是隐藏缓存未命中和内存读取延迟的成本:若线程在L1缓存中未找到目标数据,可从L2缓存中获取且不产生任何性能损失,或仅以一个时钟周期的开销从主内存中获取(具体取决于内存延迟)。Utgard可编程流水线负责执行所有着色器程序,包含三种可在单个指令发出周期内使用的处理阶段,具体如下:
- 加载阶段:负责所有与纹理采样器无关的着色器内存访问,包括统一内存访问、可变内存访问、插值及线程堆栈访问;按时钟周期计算,可加载64位均匀数据、插值64位变化数据,或加载/存储64位堆栈数据。
- 纹理阶段:负责所有纹理内存访问,对于大多数纹理格式,每个时钟周期可返回一个经过双线性滤波的纹素,部分纹理格式与滤波模式的性能会有所差异。
- 算术阶段:属于单指令多数据(SIMD)向量处理引擎,算术单元对vec4 fp16值进行操作,每条流水线每秒可处理14个FP16 FLOPS。
3 Midgard 架构
Midgard是第二代Mali GPU架构,也是首个支持OpenGL ES 3.0和OpenCL标准的Mali架构,其产品系列涵盖Mali-T600、Mali-T700及Mali-T800系列。该架构核心亮点是采用统一着色器核心设计,即硬件层面仅存在一种着色器处理器,可灵活执行各类着色器代码,包括顶点着色器、片段着色器和计算着色器。为进一步提升性能、减少重复数据读取带来的内存带宽浪费,系统内所有着色器核心共享一个二级缓存,实现数据高效复用。
Midgard架构的核心性能目标是:每个着色器核心每时钟周期可写入一个32位像素。据此可合理推算,一个八核设计的GPU,每时钟周期内读写操作的总内存带宽应为256位(8核×32位),不过具体数值会因芯片组的实际实现方式存在差异。
GPU的着色器核心由一个可编程的Tripipe执行核心,以及多个围绕其封装的固定功能单元组成。其中,固定功能单元主要负责执行着色器操作的初始化设置,以及着色器运行后的后续处理工作;可编程着色器核心则是一款多线程处理引擎,可同时运行数百个线程,每个线程对应一个着色器程序实例。大量线程的设计初衷,是为了掩盖缓存未命中和内存读取延迟带来的性能开销------只要每个周期有部分线程处于就绪状态,即便多数线程因读取数据而阻塞,也能有效避免缓存未命中导致的性能下降。
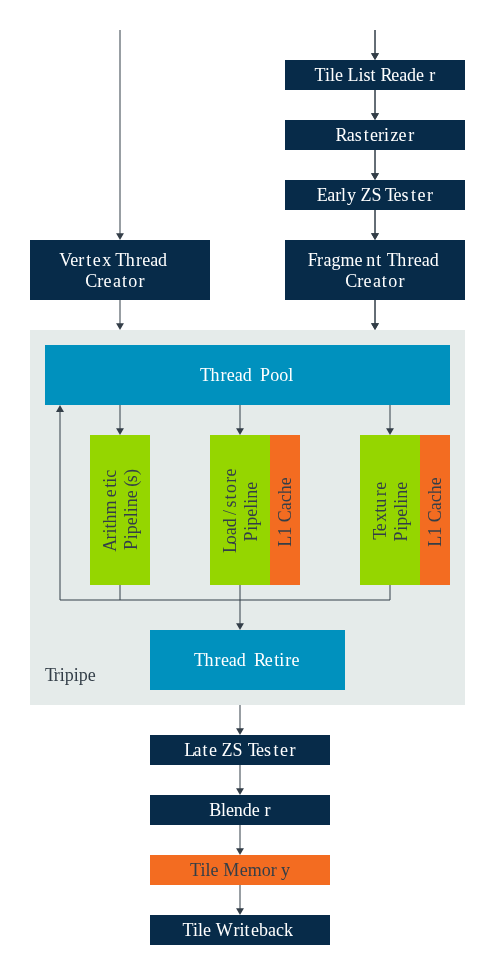
Tripipe作为核心中负责执行着色器程序的可编程部分,包含三类并行执行管线,各司其职、协同工作,具体如下:
- 算术流水线(又称A流水线):专门处理所有算术运算,属于单指令多数据流(SIMD)向量处理引擎,其算术单元可操作128位四字寄存器。这些寄存器支持多种数据类型访问,例如4个FP32/I32、8个FP16/I16或16个I8,因此一次算术向量运算可在一个周期内处理8个mediump类型的值。
- 加载/存储管线(又称LS流水线):负责所有通用内存访问、各类插值操作,以及图像的读/写访问,且不涉及纹理采样器相关的内存访问。具体包括通用指针式内存访问、缓冲区访问、可变插值、原子操作,以及通过imageLoad()和imageStore()实现的可变图像数据访问。尽管每条指令仅对应单周期内存访问操作,但硬件支持宽向量操作,可在一个周期内加载整个highp类型的vec4变量。
- 纹理流水线(又称T流水线):专注处理所有只读纹理访问和纹理过滤操作,对于大多数纹理格式,每时钟周期可返回一个经过双线性滤波的纹素;但针对部分特殊纹理格式和滤波模式,其性能会有所差异。
需要注意的是,所有Midgard着色器核心均配备一个加载/存储管线和一个纹理管线,而算术管线的数量则会因具体GPU型号的不同而有所区别。
4 Bifrost 架构
Bifrost 系列 Mali GPU 延续了早期 Midgard GPU 的顶层架构,核心仍采用统一着色器核心设计------即硬件层面仅有一种着色器处理器,可通用执行各类着色器代码(顶点着色器、片段着色器、计算内核等),无需为不同着色任务设计专用硬件,简化架构的同时提升了灵活性。着色器核心的数量可根据产品定位灵活调整,具备极强的扩展性。例如 Mali-G72 GPU,可从低端设备的单核配置,扩展到高性能设备的 32 核配置,适配不同终端的性能需求。
为提升性能、减少重复数据读取造成的内存带宽浪费,所有着色器核心共享一个二级缓存(L2 缓存)。该缓存的大小可由芯片合作伙伴根据自身需求配置,通常每着色器核心对应 64-128KB,最终大小取决于芯片可用面积。Bifrost 架构的核心性能目标的是:每个着色器核心每时钟周期可写入一个 32 位像素。据此推算,一个 8 核设计的 GPU,每时钟周期内读写内存的总带宽应为 256 位(8 核 × 32 位),实际数值会因芯片组的具体实现方式略有差异。
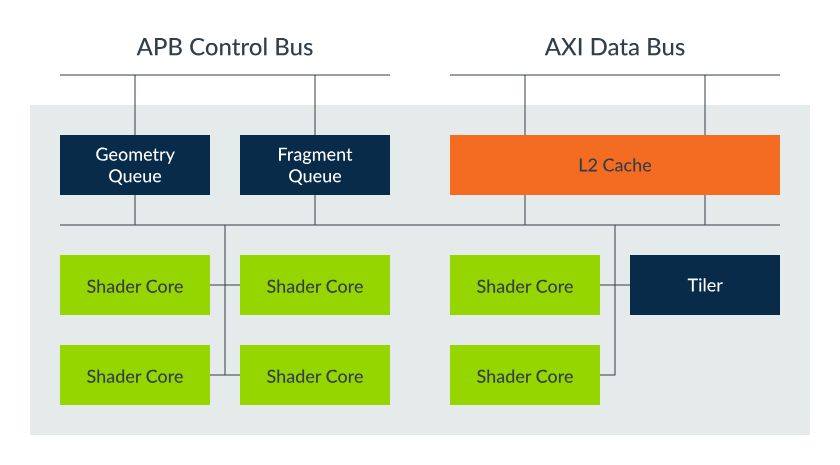
渲染通道与任务队列
当应用程序定义完渲染通道后,Mali 驱动会为每个渲染通道提交两个独立的工作负载,对应 Bifrost GPU 支持的两个并行任务队列,实现工作负载的并行处理:
- 队列 1:处理所有几何体和计算相关工作负载;
- 队列 2:处理所有与片段相关的工作负载。
需注意,Bifrost GPU 属于基于图块的渲染器,必须先完成渲染通道的所有几何体处理,才能启动片段着色工作;同时需要生成最终的图块渲染列表,为片段处理提供图元覆盖率相关信息。两个队列的工作负载可由 GPU 并行处理,并均匀分布到所有可用的着色器核心,提升整体处理效率。
着色器核心结构(与 Midgard 核心差异)
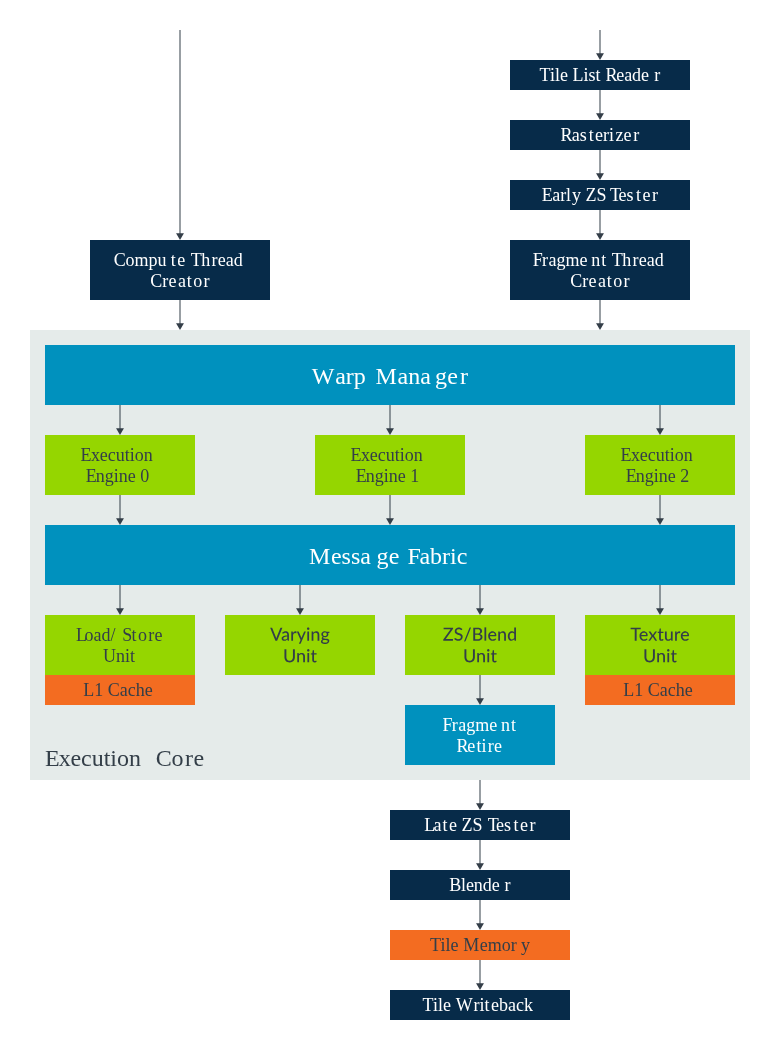
所有 Mali 着色器核心均采用"固定功能硬件模块 + 可编程核心"的结构,而可编程核心是 Bifrost 与早期 Midgard 最核心的差异点。Bifrost GPU 的可编程执行核心(EC)由一个或多个执行引擎(EE)组成,例如 Mali-G71 配备 3 个执行引擎,以及多个共享数据处理单元,所有组件通过消息传递结构连接,实现高效协同。
着色器核心尺寸(两种规格):
- 小型着色器核心:每时钟周期可读取 1 个纹理样本、混合 1 个片段、写入 1 个像素;
- 大型着色器核心:每时钟周期可读取 2 个纹理样本、混合 2 个片段、写入 2 个像素。
功能模块:
- 执行引擎(EE)。每个执行引擎(EE)负责执行可编程着色器指令,包含一个复合算术处理流水线,以及当前处理线程所需的线程状态,是实现着色器程序执行的核心单元。
- 线程状态 。Bifrost GPU 为着色器程序配备了通用寄存器文件,其容量远大于 Midgard GPU,大幅提升了复杂程序的性能和可扩展性:
- 线程占用率 100% 的程序,最多可使用 32×32 位寄存器;
- 更复杂的程序,最多可使用 64×64 位寄存器,但会牺牲部分线程可用性。
- 算术处理(线程束优化) 。为提升处理速度,Bifrost 采用"线程束(warp)"分组机制------将多个线程分组为线程束,由 GPU 并行执行;同时借助基于线程束的向量化方案,优化了 EE 中算术单元的功能效率。
- 对单个线程而言,处理过程如同一系列 32 位标量操作,便于着色器编译器充分利用硬件资源;而底层硬件仍保持向量单元的效率优势,仅需一套控制逻辑,即可分摊到线程束中的所有线程,避免资源浪费。
- Bifrost 着色器核心的线程束宽度随核心性能变化------单像素/周期产品的线程束宽度为 4,双像素/周期产品的线程束宽度为 8。
- 数据类型支持:原生支持 int8、int16、fp16 数据类型,这些数据可打包填充 128 位数据单元,既保留了小于 32 位数据类型的能效和性能优势,又充分利用了硬件带宽。其中,4 宽的 warp 运算单元,每时钟周期可执行 8 次 fp16/int16 运算,或 16 次 int8 运算。
- 加载/存储单元
- 负责所有与纹理采样器无关的着色器内存访问,具体包括:通用指针式内存访问、缓冲区访问、原子操作,以及通过 imageLoad()/imageStore() 实现的可变图像数据访问。
- 核心优化:每时钟周期可访问单个 64 字节缓存行的数据;线程束访问经过优化,可减少唯一缓存访问请求(例如,线程束中所有线程访问同一缓存行内的数据时,可在单个周期内返回结果)。
- 缓存配置:每个核心的加载/存储单元包含 16KB L1 数据缓存,由共享 L2 缓存提供备份。
优化建议:建议使用支持广泛数据访问和跨线程合并功能的着色器算法,例如:线程内使用向量加载/存储、线程束中各线程访问顺序地址范围。
- 可变单元。专用固定功能可变插值器,采用形变矢量化技术,确保功能单元的高利用率。其性能特点为:每时钟周期可对线程束中的每个线程进行 32 位插值(例如,对一个 mediump-fp16 vec4 插值需 2 个时钟周期)。能效优势:mediump-fp16 插值的速度和能效,均高于 highp-fp32 插值。
- 纹理单元 。负责所有纹理内存访问,每个纹素/每时钟周期配备 16KB L1 数据缓存,由共享 L2 缓存提供备份。
- 性能特点:纹理单元的峰值性能(每时钟周期纹素数)与着色器核心的每时钟周期像素数匹配;根据产品配置不同,每时钟周期可进行 1 次或 2 次双线性滤波采样。
- 大多数纹理格式的基本性能为每时钟周期处理 1-2 个双线性滤波纹素,部分特殊纹理格式和滤波模式的性能会略有差异。
下图显示了 vec3 算术运算如何映射到纯 SIMD 单元,图中显示了每次运算的一个空闲周期:

下图展示在 4 路并行(4-wide)的 warp 计算单元上执行 vec3 向量运算:

索引驱动几何管道(IDVS)
Bifrost 最关键的创新是引入索引驱动顶点着色(IDVS)几何处理流水线,解决了早期 Mali GPU 几何处理的资源浪费问题,具体对比和优势如下:
- 早期 Mali GPU 在剔除图元(去除不可见的三角形等)之前,会先处理所有顶点着色任务,导致被剔除图元中使用的顶点,白白浪费计算资源和内存带宽。
- IDVS 流水线从构建图元开始,按图元顺序提交着色任务,将着色器拆分为两部分,优化处理顺序:
- 先进行位置着色,再执行裁剪和剔除操作;
- 仅对未被剔除的可见顶点,执行可变着色。
- 位置着色仅针对"被索引缓冲区引用"的顶点(每批顶点中至少有一个被引用),可跨越索引缓冲区中未被引用的空间间隙,减少无效计算;
- 可变着色仅应用于通过裁剪、剔除的可见图元,大幅减少冗余计算和带宽占用;
- 建议采用"解交错打包顶点缓冲区":将影响位置的属性和影响非位置可变的属性,分别存入两个缓冲区,确保被剔除顶点的非位置属性不会被缓存,进一步提升效率。


5 Valhall 架构
Valhall 系列 Mali GPU 延续了早期 Bifrost GPU 的顶层架构,核心依旧采用统一着色器核心设计------硬件层面仅有一种着色器处理器,可通用执行各类着色器代码,包括顶点着色器、片段着色器和计算内核,无需为不同着色任务设计专用硬件,兼顾架构简洁性与功能灵活性。
与 Bifrost 类似,Valhall 系列的着色器核心数量可根据产品定位灵活调整,芯片合作伙伴可结合终端设备的性能需求,配置不同数量的着色器核心,适配从低端到高端的全场景应用。
缓存与性能目标
为提升性能、减少重复数据读取造成的内存带宽浪费,所有着色器核心共享一个二级缓存(L2 缓存)。该缓存的大小由芯片合作伙伴自主配置,通常每着色器核心对应 64-128KB,最终大小取决于芯片可用面积,与 Bifrost 缓存配置逻辑一致。此外,芯片合作伙伴还可灵活配置 L2 缓存与外部存储器之间的内存端口数量及总线宽度,进一步优化内存访问效率,适配不同场景的带宽需求。
Valhall 架构的核心性能目标相较于 Bifrost 大幅提升:每个着色器核心每时钟周期可写入两个 32 位像素。据此推算,一个 4 核设计的 GPU,每时钟周期内读写内存的总带宽应为 256 位(4 核 × 2 个 32 位像素),实际数值会因芯片组的具体实现方式略有差异。Valhall 核心每时钟周期可执行 32 次 FP32 FMA 操作,读取四个双线性滤波纹理样本,混合两个片段,并写入两个像素,综合处理性能较 Bifrost 有显著提升。
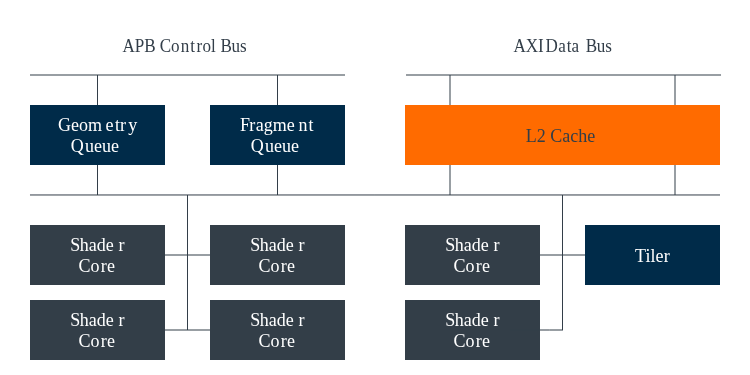
渲染通道与任务队列
当应用程序完成渲染通道的定义后,Mali 驱动程序会为每个渲染通道提交两个独立的工作负载,对应 Valhall GPU 支持的两个并行任务队列,实现工作负载的高效并行处理:
- 队列 1:处理渲染过程中所有与几何和计算相关的工作负载;
- 队列 2:处理渲染过程中所有与片段相关的工作负载。
与 Bifrost 一致,Valhall GPU 同样属于基于图块的渲染器,渲染过程中所有的几何处理必须在片段着色开始之前完成------核心原因是需要生成最终的图块列表,为片段处理提供所需的图元覆盖信息,确保片段渲染的准确性。
Valhall 的任务队列设计进一步优化了并行效率:两个队列的工作负载可由 GPU 同时处理,这意味着不同渲染通道的几何体处理和片段处理可并行运行,大幅提升整体渲染吞吐量。同时,单次渲染过程的工作负载通常具备规模大、高度可并行化的特点,GPU 会自动将工作负载分解为更小的任务单元,并均匀分配到所有可用的着色器核心,充分利用硬件资源。
着色器核心结构(与 Bifrost 核心差异)
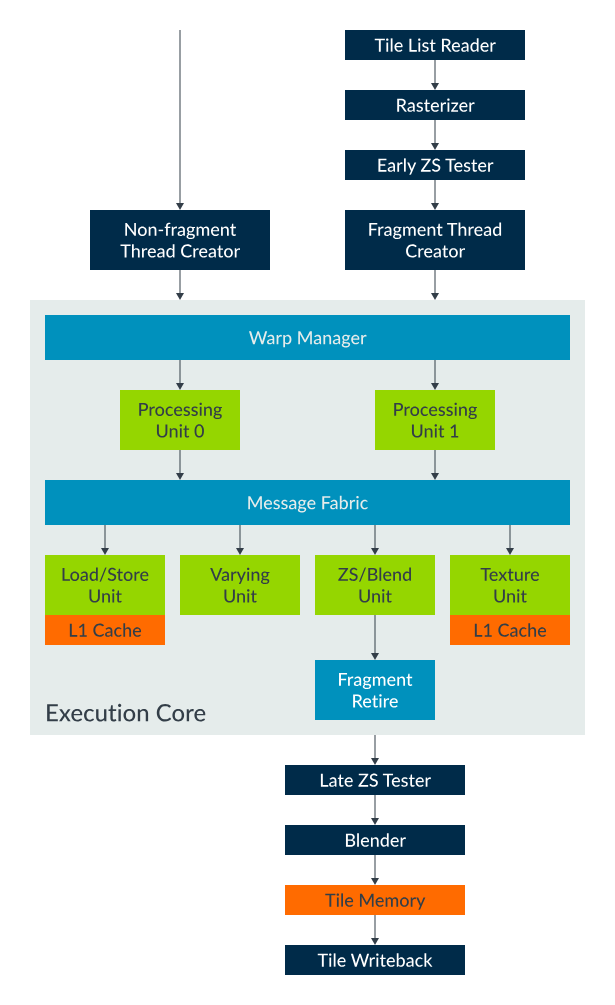
所有 Mali 着色器核心均采用"固定功能硬件模块 + 可编程核心"的经典结构,其中可编程核心是 Valhall 与早期 Bifrost 设计相比变化最大的部分,在架构设计和性能表现上有显著改进。
可编程执行核心(EC)。Valhall GPU 的可编程执行核心(EC)由一个或多个处理引擎(PE)组成(区别于 Bifrost 的执行引擎 EE)。典型代表如 Mali-G57 和 Mali-G77,均配备两个处理引擎,以及若干共享数据处理单元,所有组件通过消息传递结构连接,实现高效协同,提升指令执行效率。
-
处理引擎(PE)
- 每个处理引擎(PE)负责执行可编程着色器指令,是 Valhall 可编程核心的核心单元。与 Bifrost 的 EE 不同,每个 PE 内置三个独立的算术处理流水线,分工明确、协同工作,大幅提升算术处理效率:
- FMA 管道:专门处理复杂的数学运算,满足高精度、高复杂度的计算需求;
- CVT 管道:负责简单的数学运算(原文"SVT 管道"为笔误修正),快速处理基础运算任务,降低资源占用;
- SFU 管道:用于特殊功能运算,适配各类特殊场景的计算需求。
- 流水线宽度与吞吐量:FMA 管道和 CVT 管道的宽度均为 16,SFU 管道的宽度为 4,其吞吐量仅为前两条管道的四分之一,实现不同复杂度运算的合理资源分配。
- 每个处理引擎(PE)负责执行可编程着色器指令,是 Valhall 可编程核心的核心单元。与 Bifrost 的 EE 不同,每个 PE 内置三个独立的算术处理流水线,分工明确、协同工作,大幅提升算术处理效率:
-
线程状态
- Valhall GPU 的线程状态管理与 Bifrost 逻辑一致,但进一步优化了寄存器配置的灵活性:
- 程序最多可使用 32 个 32 位寄存器,同时保持线程满负荷运行,确保基础程序的高效执行;
- 更复杂的程序最多可使用 64 个寄存器,代价是减少线程数量,平衡程序复杂度与执行效率。
- Valhall GPU 的线程状态管理与 Bifrost 逻辑一致,但进一步优化了寄存器配置的灵活性:
-
算术处理(线程束优化)
- Valhall 延续了 Bifrost 的"线程束(warp)"分组机制,将多个线程分组为线程束,由 GPU 并行执行,同时借助基于线程束的向量化方案,进一步提升功能单元的利用率,加快处理速度。
- 核心差异:Valhall 采用 16 宽的线程束(Bifrost 为 4 或 8 宽),并行处理能力更强。其架构优势与 Bifrost 一致:对单个线程而言,处理过程如同一系列 32 位标量操作,便于着色器编译器高效利用硬件资源;底层硬件仍保持向量单元的效率优势,仅需一套控制逻辑,即可分摊到线程束中的所有线程,避免资源浪费。
- 数据类型支持:原生支持 int8、int16 和 fp16 数据类型,这些数据类型可通过 SIMD 指令打包,填充每个 32 位数据处理通道,既保留了小于 32 位数据类型的能效和性能优势,又兼顾了其本身的局限性。
- 性能表现:一个 16 宽的 warp 运算单元,每时钟周期可执行 32 次 fp16/int16 运算,或 64 次 int8 运算,算术处理效率较 Bifrost 大幅提升。
-
加载/存储单元
- 功能与 Bifrost 一致,负责所有与纹理采样器无关的着色器内存访问,具体包括:通用指针式内存访问、缓冲区访问、原子操作,以及通过 imageLoad() 和 imageStore() 实现的可变图像数据访问。
- 核心优化:每时钟周期可访问单个 64 字节缓存行的数据;线程束访问经过优化,可减少唯一缓存访问请求(例如,线程束中所有线程访问同一缓存行内的数据时,可在单个时钟周期内返回结果),降低内存延迟。
- 缓存配置:每个核心的加载/存储单元包含 16KB L1 数据缓存,由共享的 L2 缓存提供备份,与 Bifrost 缓存配置保持一致。
- 优化建议:建议使用能够充分利用加载/存储单元的广泛数据访问和跨线程合并功能的着色器算法,例如:线程内使用向量加载和存储、线程束中各线程访问顺序地址范围,最大化内存访问效率。
-
可变单元
- 专用固定功能可变插值器,采用形变矢量化技术,确保功能单元的高利用率,与 Bifrost 可变单元的设计逻辑一致。
- 性能特点:每时钟周期可对线程束中的每个线程插值 32 位数据(例如,插值一个中等精度的 fp16 向量 vec4 需要两个时钟周期)。能效优势显著:插值中等精度的 fp16 数据比插值高精度的 fp32 数据更快、更节能,适配移动设备的低功耗需求。
-
纹理单元
- 负责所有纹理内存访问,性能较 Bifrost 有明显提升:基准性能为每时钟周期处理四个双线性滤波纹素,相当于一个时钟周期可处理一个 2x2 像素的四边形纹理,大幅提升纹理渲染效率。
- 该基准性能适用于大多数纹理格式,但对于某些特殊纹理格式和滤波模式,性能可能会略有差异,与 Bifrost 的纹理处理特性一致。
-
ZS 单元与颜色混合单元
- Valhall 新增并优化了 ZS 单元和颜色混合单元,两者共同负责处理所有 OpenGL ES 相关操作,以及对图块缓冲区的程序化访问。其中,颜色混合单元每时钟周期可向图块内存写入两个片段中的任意一个,提升片段处理效率。
- 抗锯齿支持:所有 Mali GPU(含 Valhall 系列)均设计为支持快速多重采样抗锯齿 (MSAA),既支持全速率片段混合,也支持在使用 4xMSAA 时进行像素解析,兼顾渲染质量与执行效率。
IDVS 几何处理流程支持
Valhall 系列延续了 Bifrost 引入的索引驱动顶点着色(IDVS)几何处理流程,进一步优化了几何处理的效率,避免无效计算和内存带宽浪费,与 Bifrost 的 IDVS 工作原理一致,确保几何处理的高效性和资源利用率。
6 总结
| 对比维度 | Utgard | Midgard | Bifrost | Valhall |
|---|---|---|---|---|
| 架构定位 | 初代 Mali,面向固定功能图形渲染 | 首代统一架构,引入通用计算 | 面向能效优化与执行模型重构 | 面向高性能与可扩展算力 |
| 着色器架构 | 分离式(Vertex / Fragment) | 统一着色器(Unified Shader) | 统一着色器(标量化执行) | 统一着色器(进一步解耦执行单元) |
| 核心执行模型 | 单流水线 + 多线程隐藏延迟 | Tripipe(三管线:ALU / LS / TEX) | Execution Engine(标量执行) | Processing Engine(多独立算术管线) |
| 指令模型 | 类 VLIW / pipeline 发射 | 向量 ISA(vec4 / 128-bit) | 标量 ISA(Scalar ISA) | 标量 ISA(更高 ILP) |
| 线程/并行模型 | 线程级并行(≤128线程/核心) | Warp-like(但偏向向量批处理) | ❌ 无传统 warp 概念(不是 4/8 宽 warp) | ❌ 无传统 warp(也不是固定 16 宽) |
| 向量/数据宽度 | vec4 FP16 | 128-bit 向量寄存器 | 标量执行(编译器负责向量拆分) | 标量执行(更高并行发射能力) |
| 寄存器设计 | 小规模寄存器文件 | 中等规模寄存器 | 大寄存器文件(降低 spilling) | 更高带宽寄存器访问 |
| 几何处理 | 固定功能 Tiler | 传统流程(无关键优化) | IDVS(Index-Driven Vertex Shading) | 延续并优化 IDVS |
| 调度机制 | CPU 驱动(Job Manager) | GPU 内部调度增强 | 硬件调度 + 双队列(更细粒度) | 更强并行调度 + 多队列 |
| 缓存结构 | 分离缓存 + 小 L2 | 统一 L2(共享) | L1(每核心)+ 共享 L2 | 类似 Bifrost,但带宽/端口增强 |
| Tile-based 渲染 | ✔(核心特性) | ✔ | ✔ | ✔ |
| 像素吞吐(趋势) | 低 | 中 | 中(更高能效) | 更高(架构级提升) |
| 算力特征 | FP16 为主,弱 ALU | 向量 ALU(支持 FP32) | 标量 ALU(更高利用率) | 更高吞吐 + 更好 ILP |
| 纹理单元 | 基础纹理采样 | 标准纹理单元 | 改进缓存与访问模式 | 更高吞吐与并发 |
| 新增关键技术 | TBDR | 统一 Shader + OpenCL | 标量化 + IDVS + 能效优化 | 执行解耦 + 并行度提升 |
| API 支持 | OpenGL ES 2.0 | OpenGL ES 3.x / OpenCL | Vulkan / OpenCL / GLES | Vulkan / 最新图形计算 API |
| 核心演进本质 | 图形专用 GPU | 向通用计算转型 | 执行模型重构(向标量化) | 高性能通用并行处理器 |