1.定义
Redis是一个基于内存 的键值对存储系统,常用作缓存服务
Redis断电关机后会清空内存里的数据
Redis储存在内存中,为保证数据的可靠性,Redis会将数据备份到硬盘上,用于故障发生时的数据恢复(如断电关机等)。
2.特点
- 高性能:Redis主要将数据存储在内存中,因此读写速度非常快,适合对速度有较高要求的场景。
- 支持多种数据结构:Redis中键值对的值(Value)支持多种数据结构,如字符串、哈希表、列表、集合等。
- 持久化 :Redis可以通过定期快照 或者实时记录写操作日志的方式将内存中的数据持久化到硬盘,确保数据在重启后不会丢失。
- 灵活的数据过期策略:可以为每个键设置过期时间,一旦过期,Redis会自动删除
3.使用场景
Redis最为常见的一个应用场景就是用作缓存 ,缓存可以显著提升访问速度,降低数据库压力。
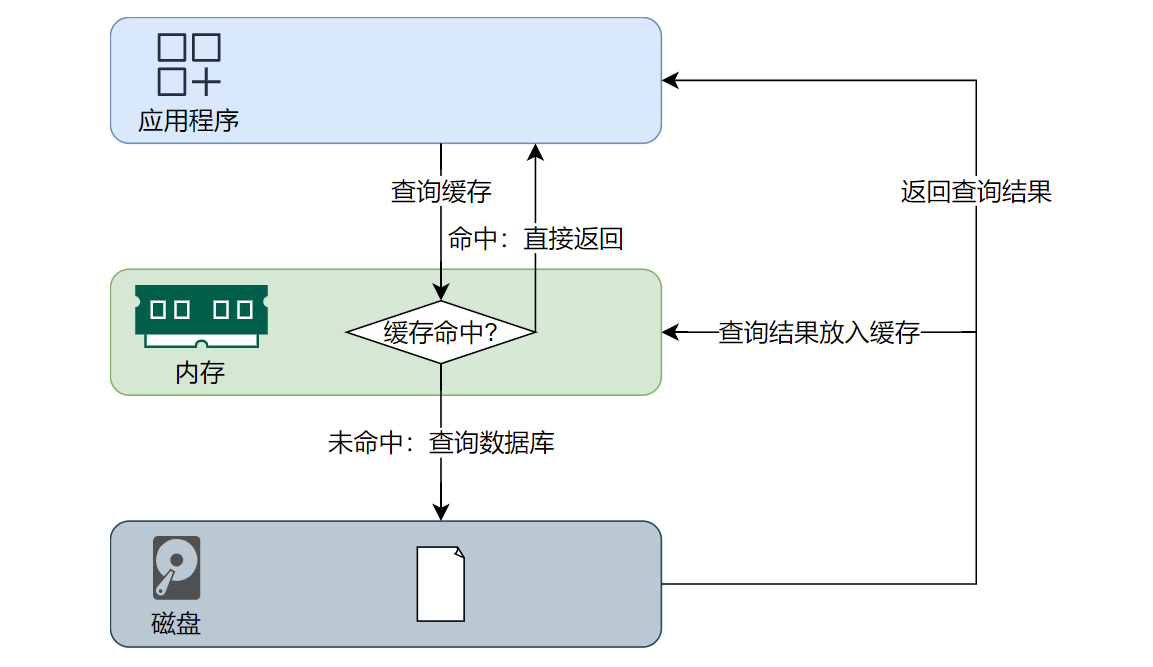
4.使用方法
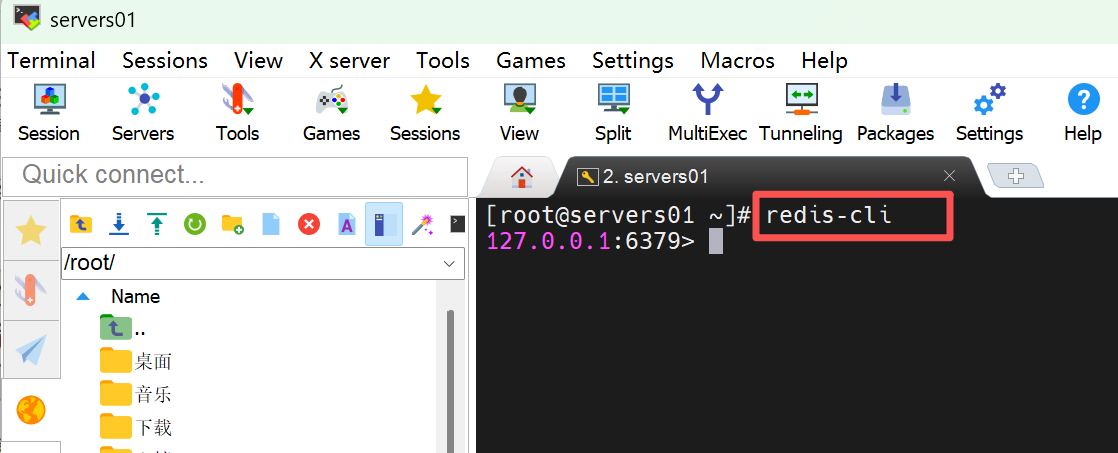
1.通过命令行使用Redis
-
在虚拟机启动客户端
redis-cli -h 127.0.0.1 -p 6379 # 安装redis没有指定IP地址和端口号可以省略不写
-h <hostname>选项用于声明Redis服务器的主机名或IP地址,默认值为127.0.0.1。
-p <port>选项用于声明Redis服务器监听的端口号,默认值为6379。
-
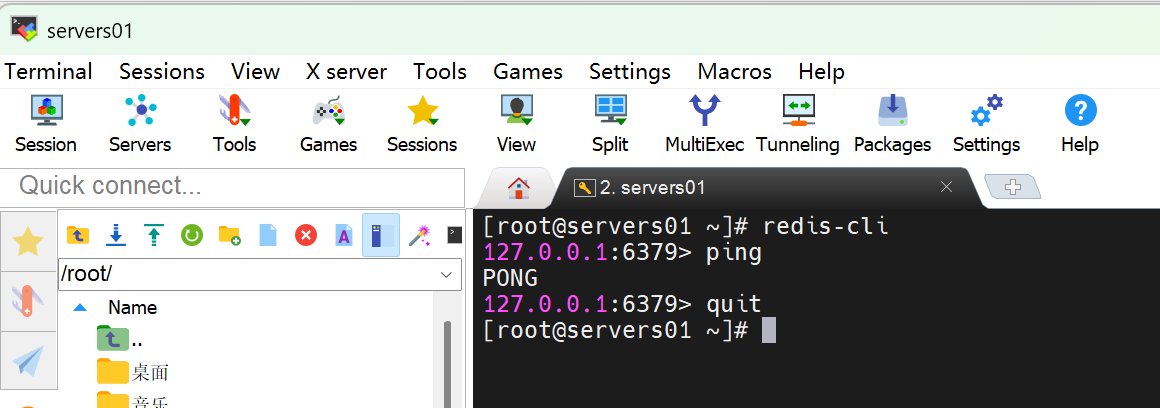
测试链接状态
ping # 返回PONG连接正常
quit # 断开客户端与服务端的连接,并退出客户端
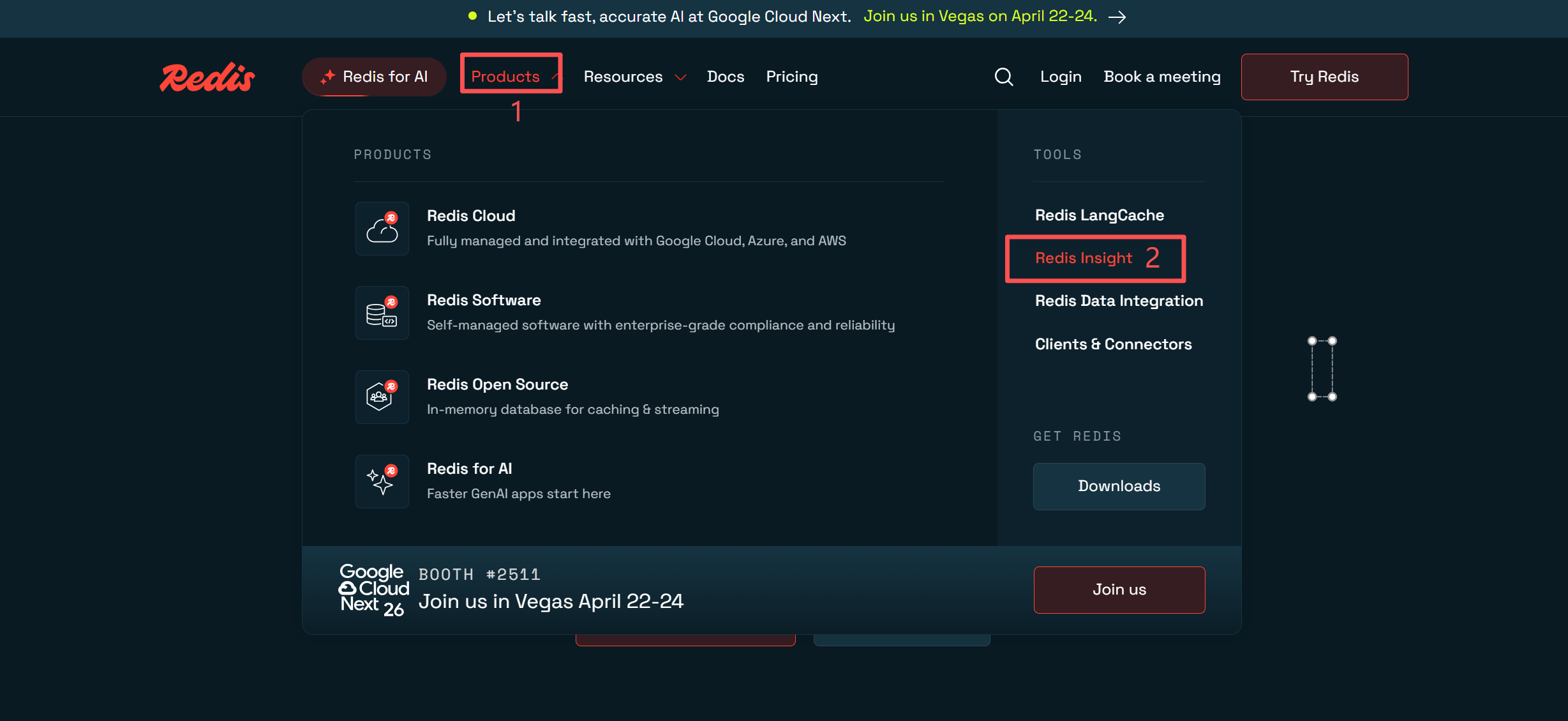
2.通过图形化工具使用Redis
- 下载并安装图形化工具RedisInsight 官网地址
RedisInsight 是Redis官方推荐的图形化工具,开源免费,且功能强大- 根据步骤进行下载,下载后直接进行下一步安装
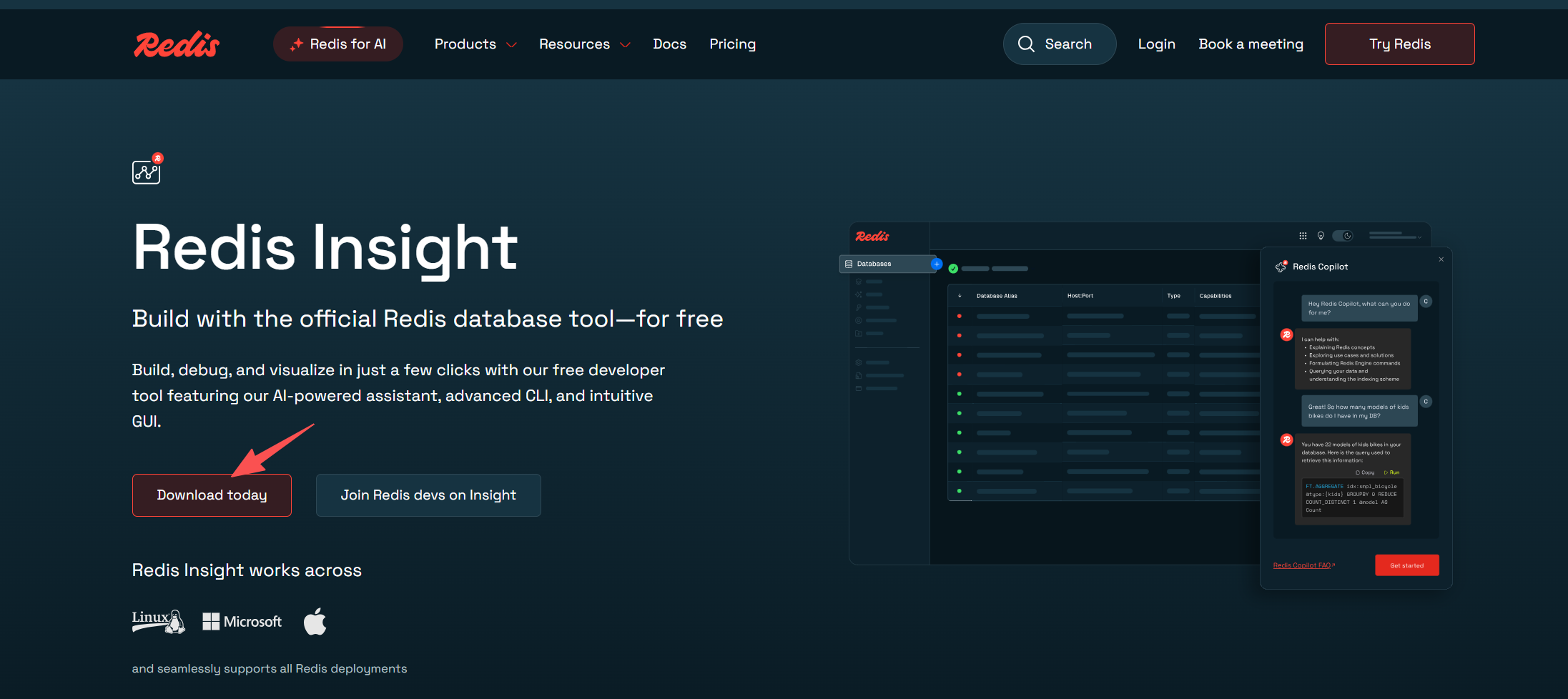
- 根据步骤进行下载,下载后直接进行下一步安装
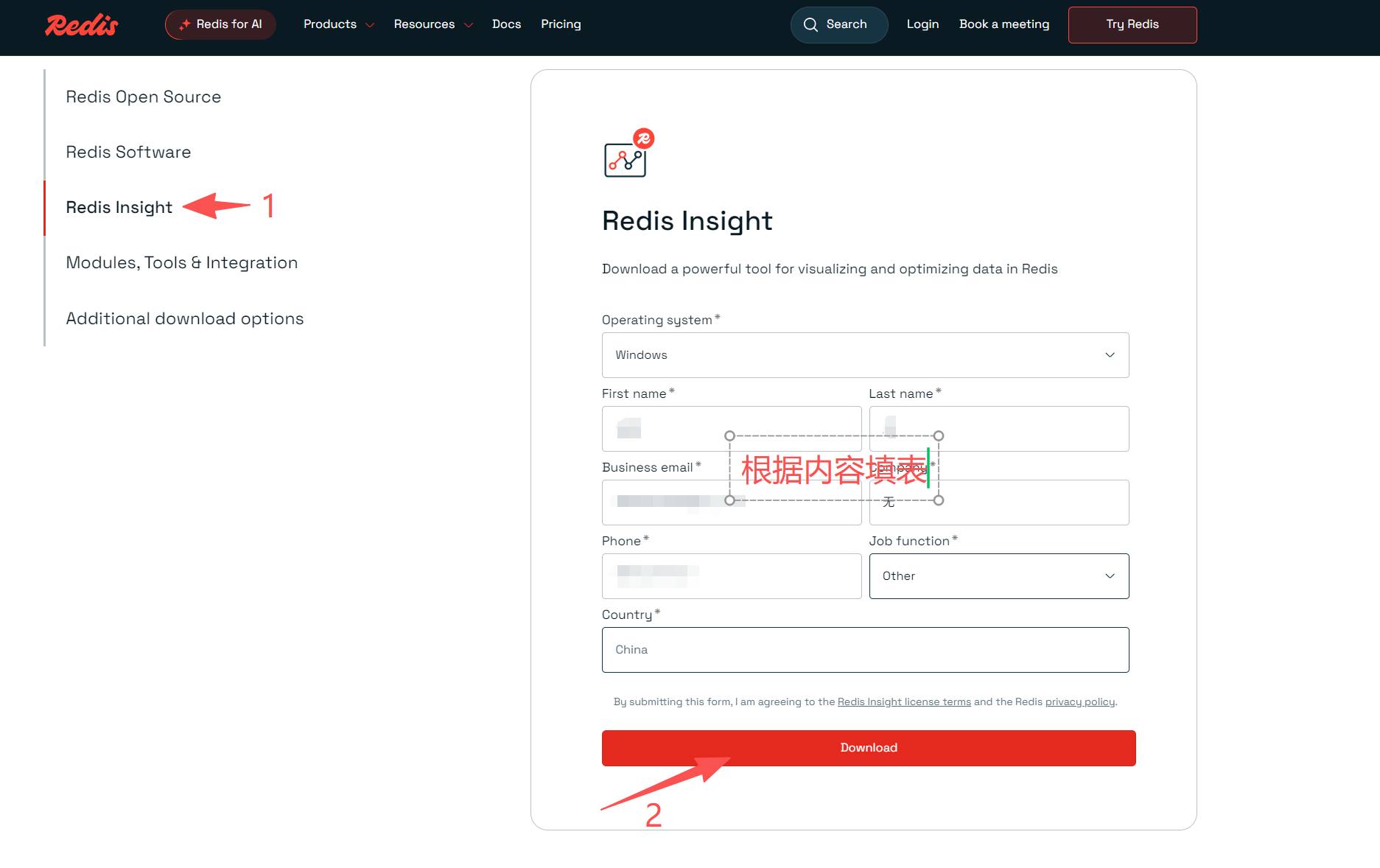
- 使用图形化工具
新版本与老版本界面有所不同-
打开图形化工具,点击添加数据库
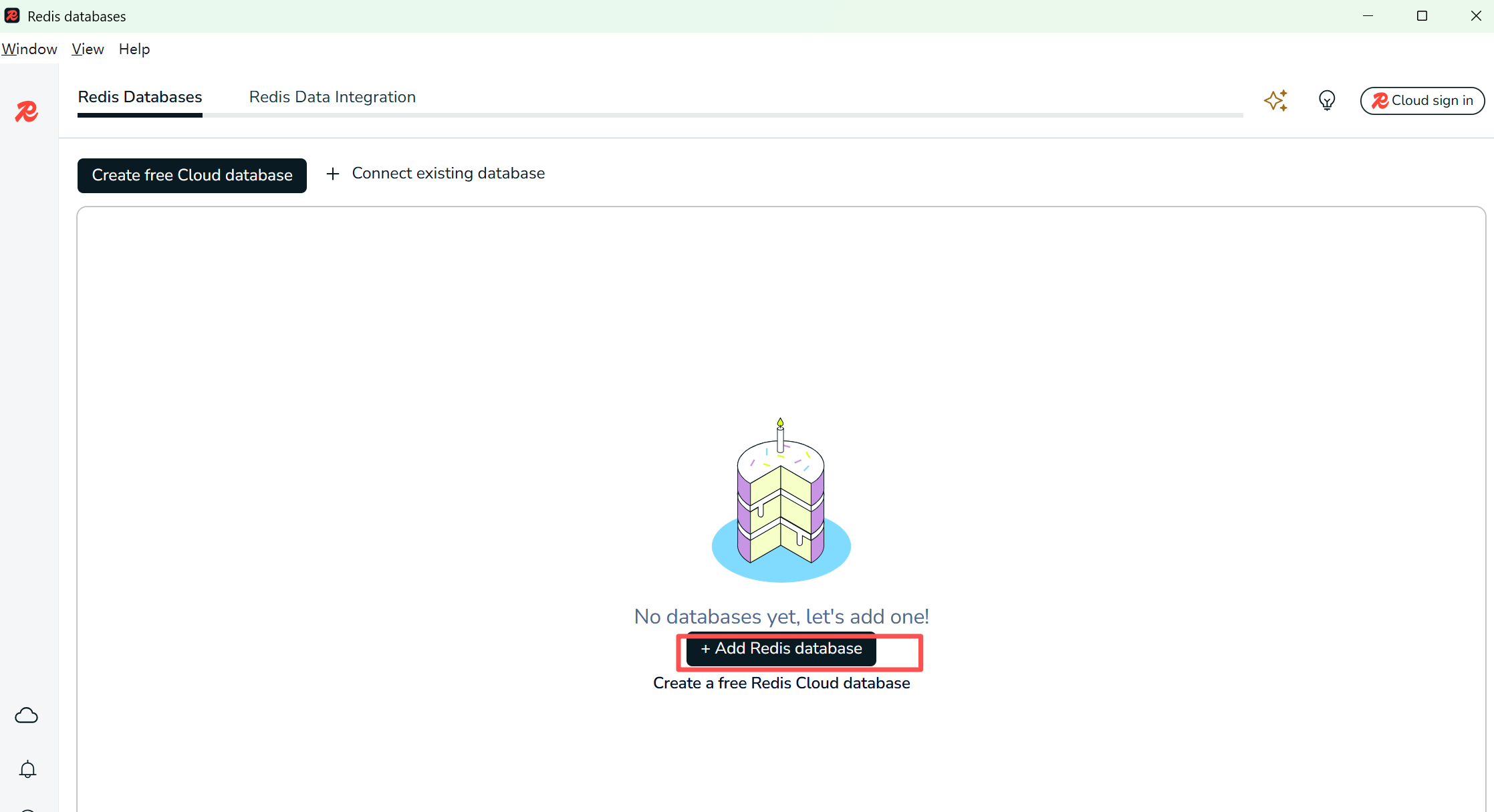
-
设置添加数据库配置
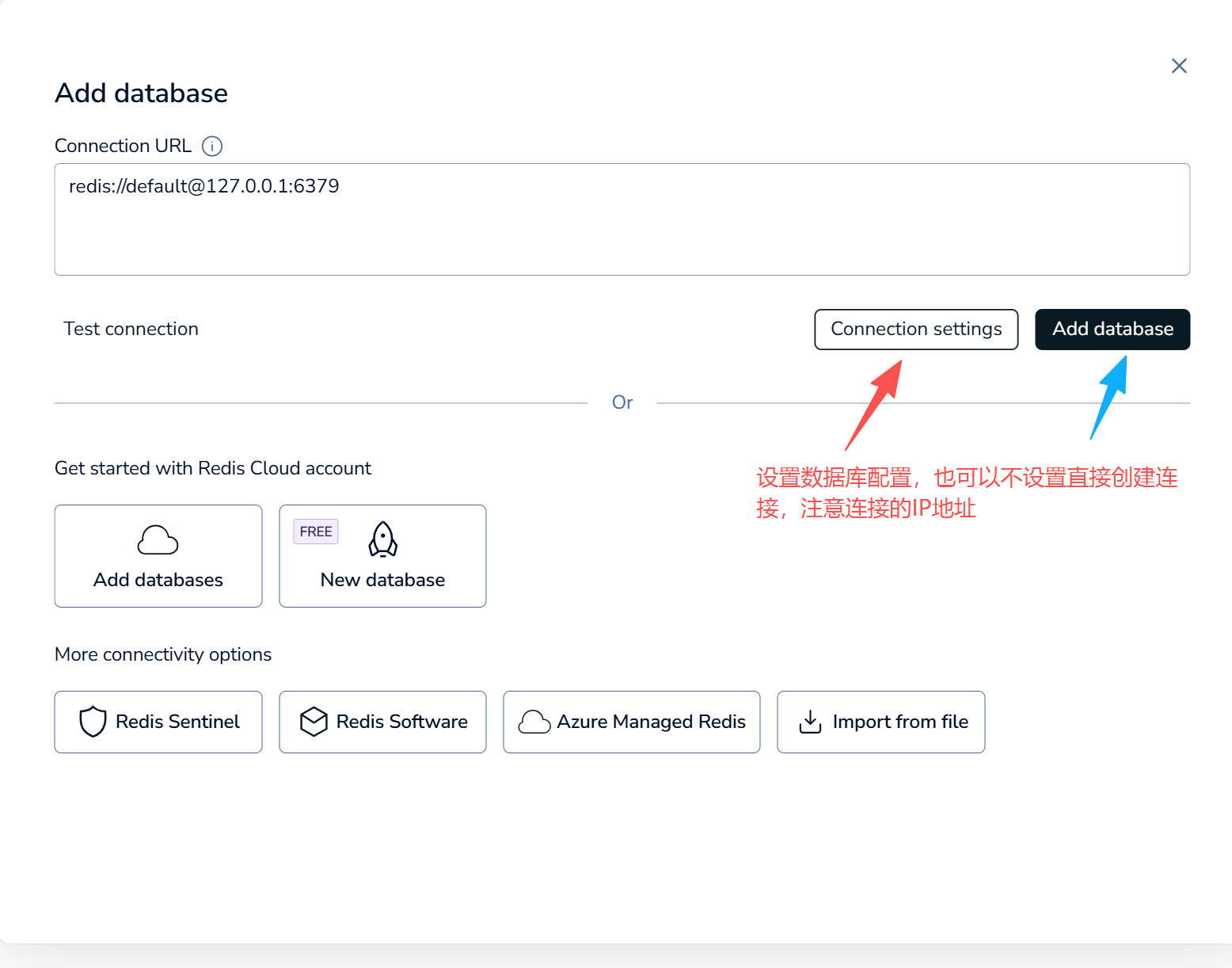
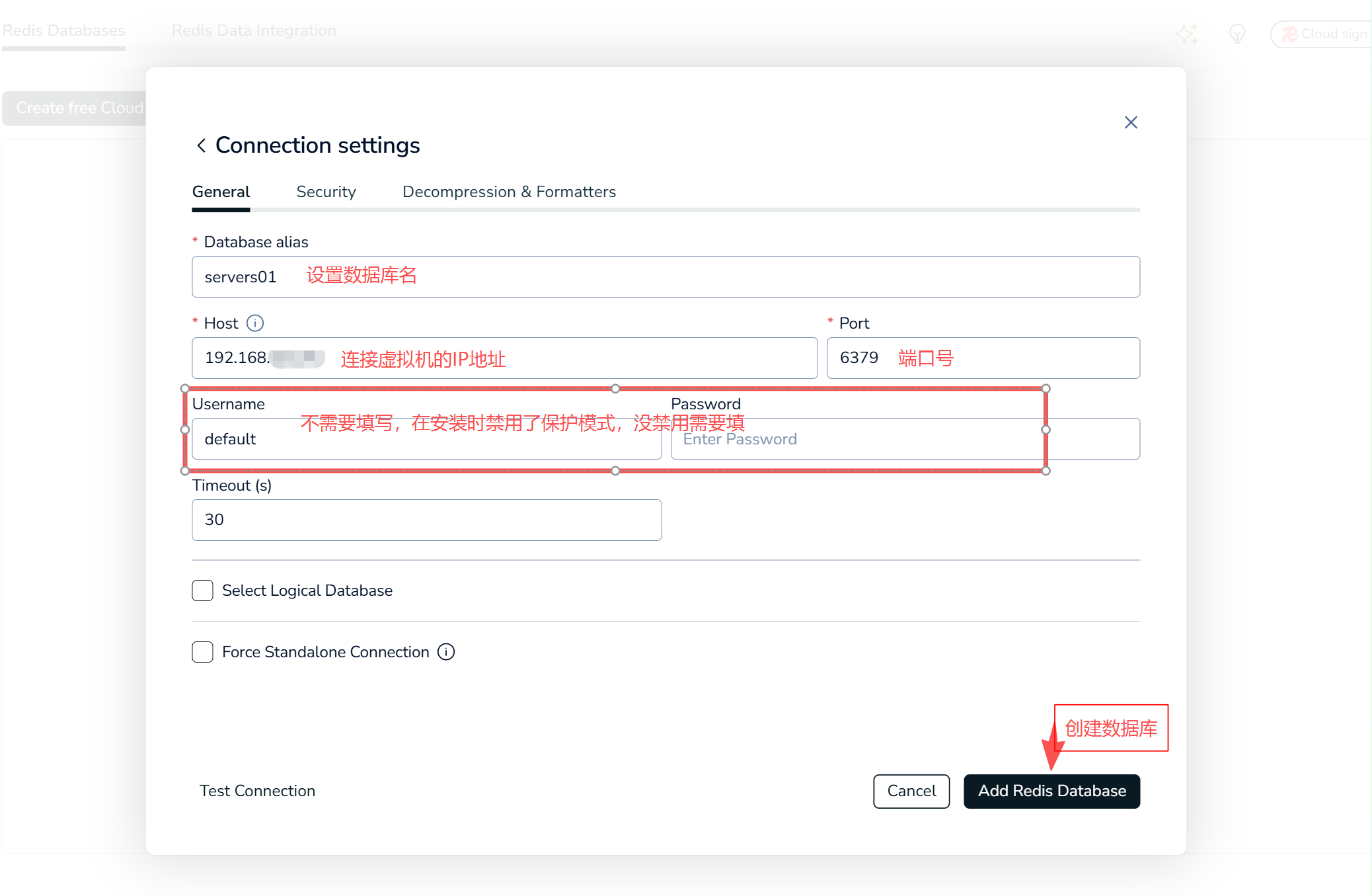
-
创建后会有对应的数据库
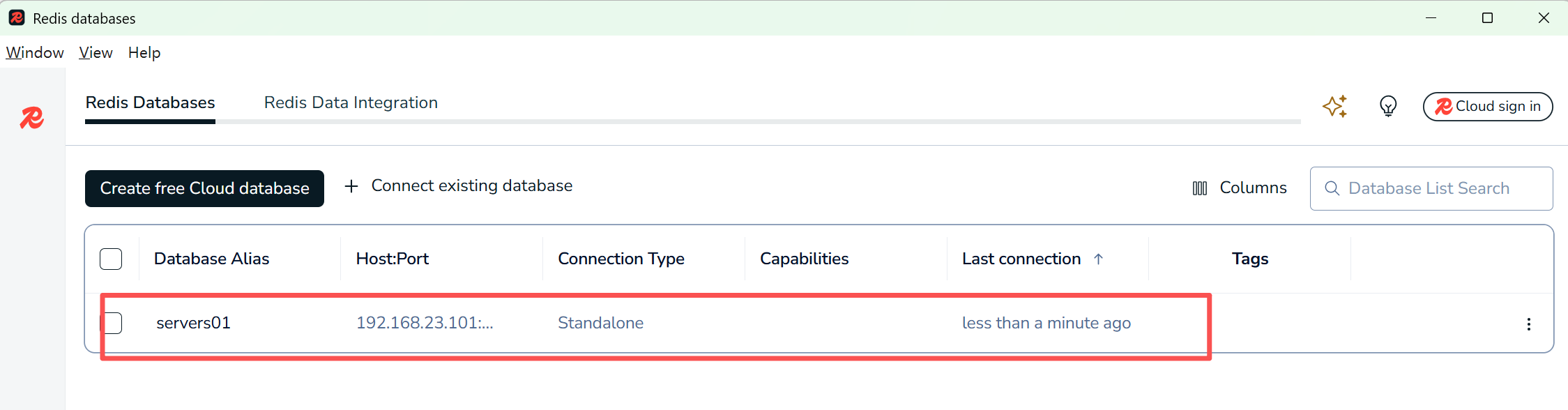
-
点击对应的数据库进入数据主页
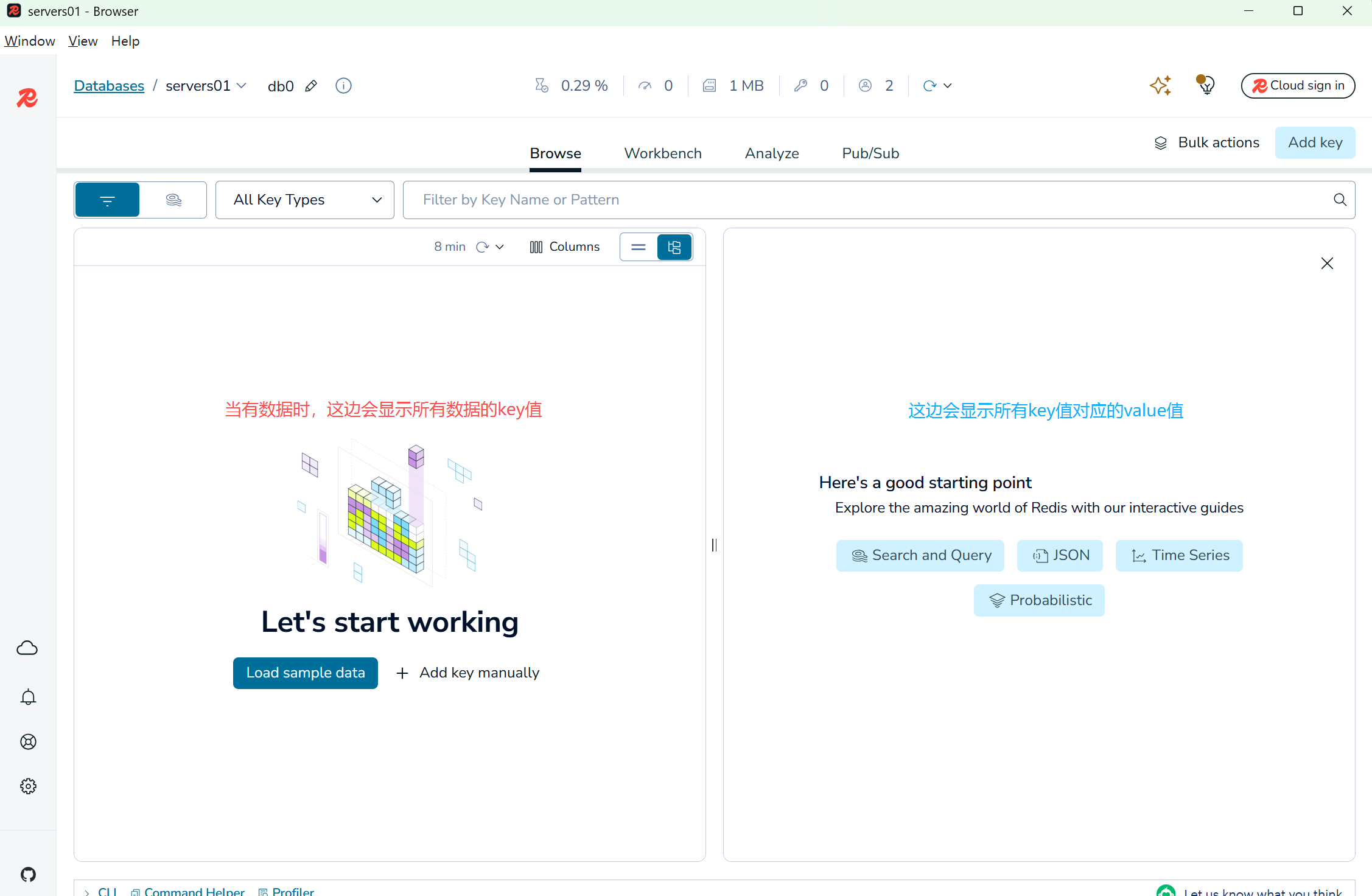
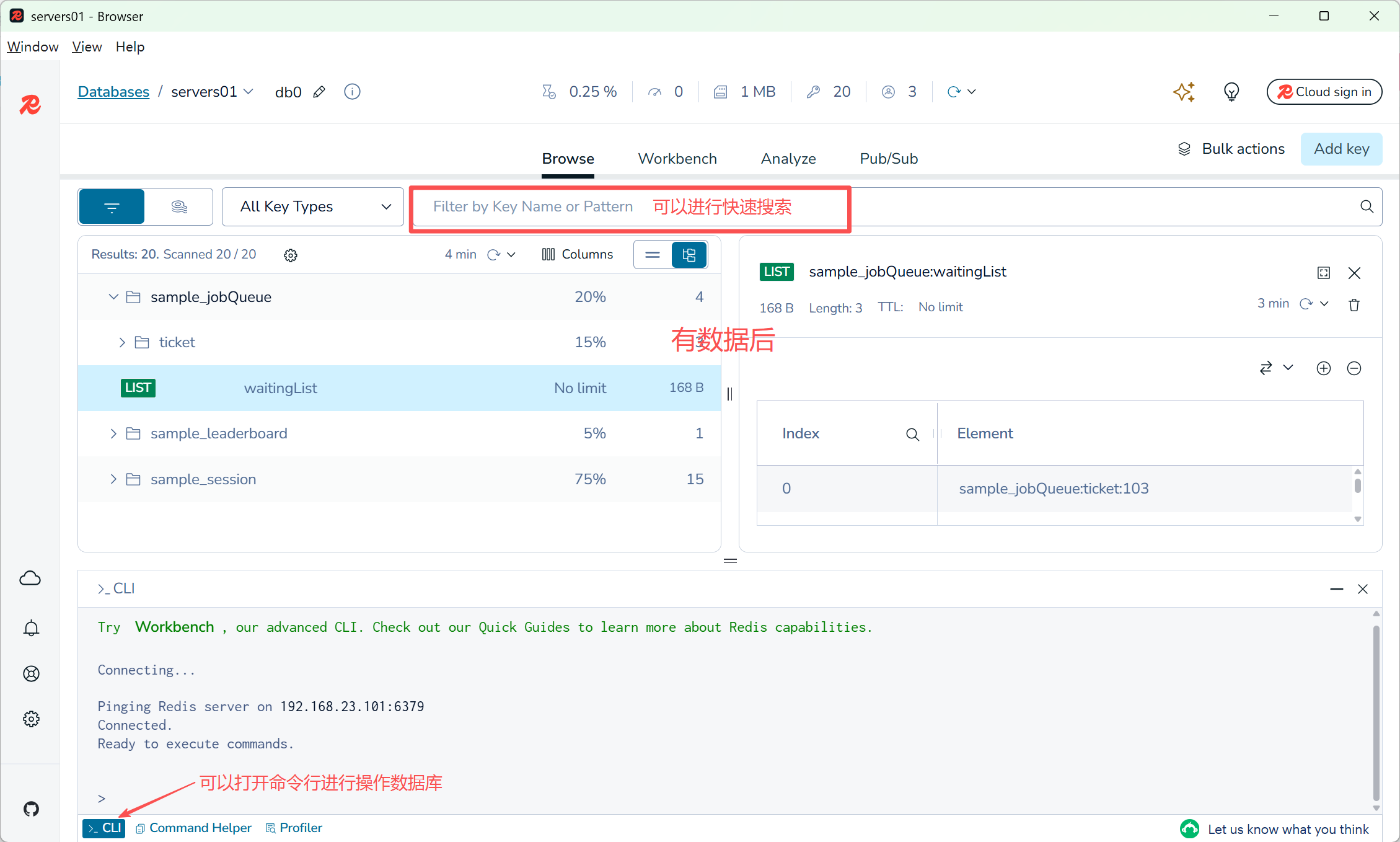
-
5.Redis常用数据类型及命令
[ ]包着的属性时可选的,可以不传
命令可以在虚拟机或图形化工具里使用
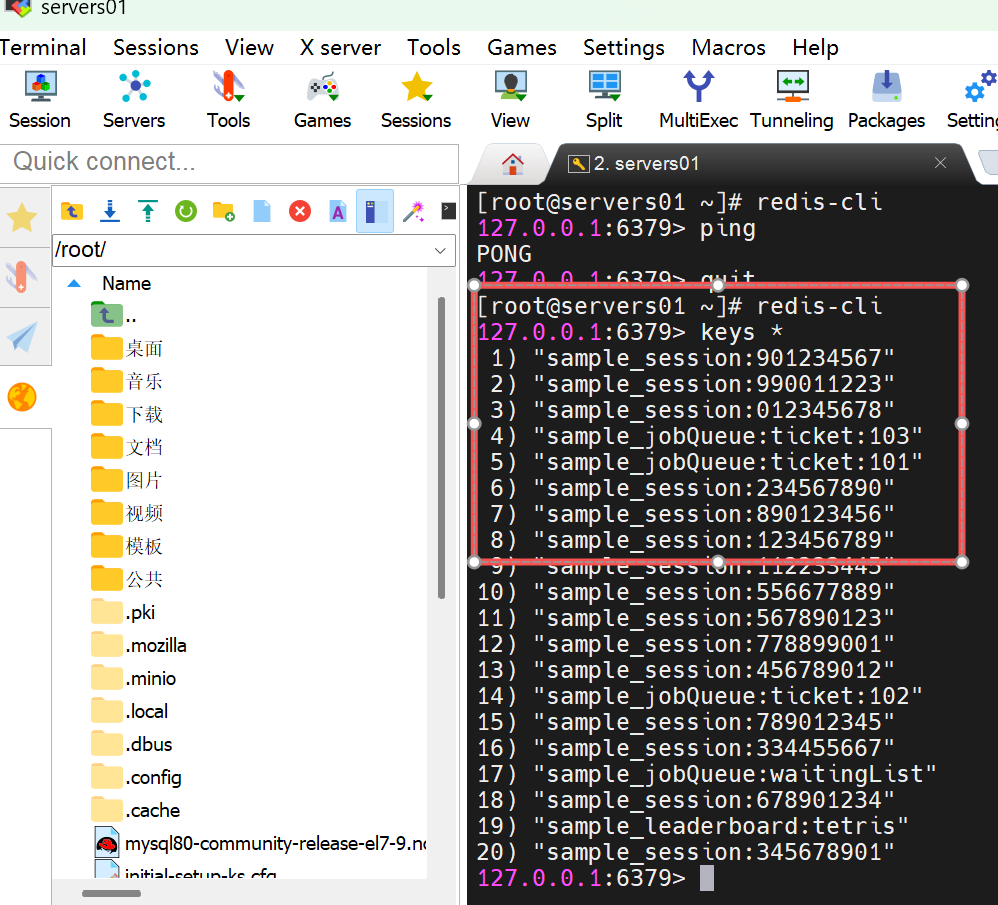
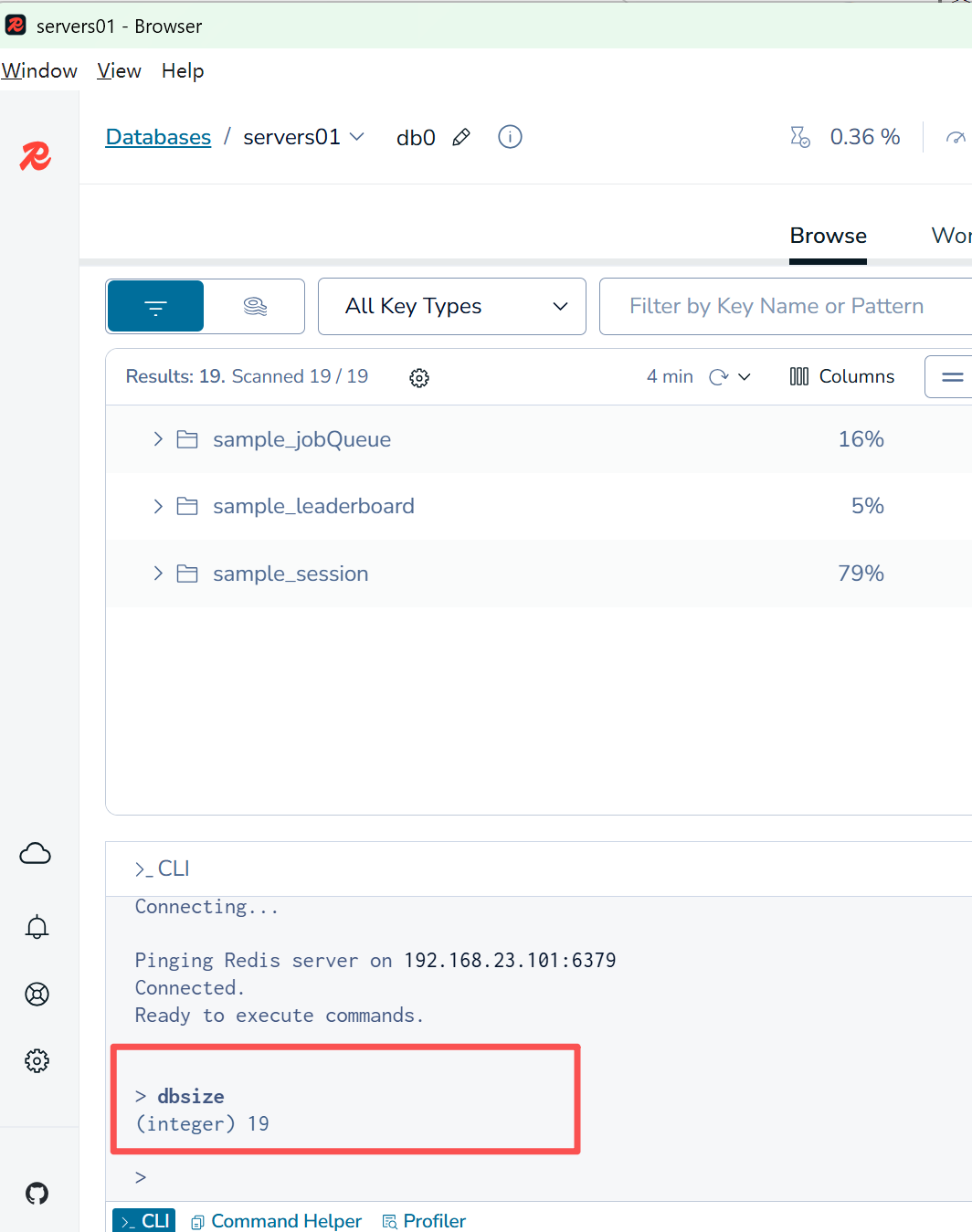
1.通用命令
概述: 所有数据类型都可用
-
keys查看所有键keys pattern
pattern用于匹配key,其中*表示任意个任意字符,?表示一个任意字符
注意:该命令会遍历Redis服务器中保存的所有键,因此当键很多时会影响整个Redis服务的性能,线上环境需要谨慎使用。
-
dbsize查看键的总数
返回总键数dbsize
-
del删除指定键
返回值为成功删除键的个数,若删除一个不存在的键,则返回0。del key1 key2...
-
exists判断一个键是否存在
若键存在则返回1,不存在则返回0。exists key
-
ttl查询键的剩余过期时间
-
查询一个定时键的剩余存活时间,返回值以秒为单位。
-
若查询的键的未设置过期时间,则返回
-1, -
若查询的键不存在,则返回
-2。ttl key
-
select切换数据库
Redis默认有编号为0~15的16个逻辑数据库,每个数据库之间的数据是相互独立的,所有连接默认使用的都是0号数据库。
index超出范围,会报错select index
-
flushdb清空当前所选用的数据库flushdb
-
flushall清空0~15号所有的数据库flushall
2.String类型数据
应用场景: 常用于缓存、计数器等场景
概述: string类型保存的是字节序列,因此任意类型的数据,只要经过序列化之后都可以保存到Redis的string类型中,包括文本、数字甚至是一个对象。
-
set添加string类型的键值对SET key value [NX|XX] [EX seconds|PX milliseconds]
各选项含义如下
- NX:仅在key不存在时set
- XX:仅在key存在时set
- EX:设置过期时间,单位为秒
- PX:设置过期时间,单位为毫秒
-
get获取某个string类型的键对应的值GET key
-
incr对数值做自增操作
若key对应的value是整数,则返回自增后的结果,若不是整数则报错,若key不存在则创建并返回1。INCR key
-
decr对数值做自减操作
若key对应的value是整数,则返回自减后的结果,若不是整数则报错,若key不存在则创建并返回-1。DECR key
3.List类型数据
应用场景:
- 社交应用中,可使用list缓存每个用户发布的最新的N条记录。
- list可用作异步消息队列
概述: list类型可用于存储多个string类型的元素,并且所有元素按照被添加的顺序存储
-
lpush向list左侧添加元素lpush key element1 element2 ...
-
rpush向list右侧添加元素rpush key element1 element2 ... -
linsert向list指定位置添加元素linsert key before|after pivot element -
lindex获取指定索引位置的元素
index从左到右依次是0,1,2...,从右到左依次是-1,-2,-3...lindex key index
-
lrange获取指定范围内的元素列表lrange key start stop
-
lpop移除并返回list左侧元素
count参数表示移除元素的个数lpop key [count]
-
rpop移除并返回list右侧的元素rpop key [count]
-
lrem移除list中的指定元素
count参数表示要移除element元素的个数(list中可以存在多个相同的元素),count的用法如下-
若count>0,则从左到右删除最多count个element元素
-
若count<0,则从右到左删除最多count(的绝对值)个element元素
-
若count=0,则删除所有的element元素
lrem key count element
-
-
lset修改指定索引位置的元素lset key index element
-
llen查看list长度llen key
4.Set类型数据
应用场景: 用于计算共同关注好友,随机抽奖系统等等
概述: 和list类型相似,set类型也可用来存储多个string类型的元素,但与list类型不同,set中的元素是无序的,且set中不会包含相同元素。
-
sadd向set中添加元素sadd key element1 element2 ...
-
smembers查询set中的全部元素smembers key
-
srem移除set中的指定元素srem key element1 element2 ...
-
spop随机移除并返回set中的n个元素spop key [count]
-
srandmember随机返回set中的n个元素(不删除)srandmember key [count]
-
scard查询set中的元素个数scard key
-
sismember元素是否在set中sismember key element
-
sinter计算多个集合的交集sinter key1 key2...
-
sunion计算多个集合的并集sunion key1 key2...
-
sdiff计算多个集合的差集sdiff key1 key2...
5.Hash类型数据
应用场景: 可用于缓存对象
概述: hash类型类似于Java语言中的HashMap,可用于存储键值对。
-
hset向hash中增加键值对
key:键
field:value值里保存的键
value:value值里保存的值hset key field1 value1 field2 value2...
-
hget获取hash中某个键对应的值hget key field
-
hdel删除hash中的指定的键值对hdel key field1 field2...
-
hlen查询hash中的键值对个数hlen key
-
hexists判断hash中的某个键是否存在hexists key field
-
hkeys返回hash中所有的键hkeys key
-
hvals返回hash中所有的值hvals key
-
hgetall返回hash中所有的键与值hgetall key
6.Zset类型数据
应用场景: 主要用于各种排行榜
概述: zset被称为有序集合,同set相似,zset中也不会包含相同元素,但不同的是,zset中的元素是有序的。并且zset中的元素并非像list一样按照元素的插入顺序排序,而是按照每个元素的分数(score)排序。
zadd向zset中添加元素
-
NX:仅当member不存在时才add
-
XX:仅当member存在时才add
ZADD key [NX|XX] score member
-
zcard计算zset中的元素个数zcard key
-
zscore查看某个元素的分数zscore key member
-
zrank按照score的升序排序,名次从0开始。zrank key member
-
zrevrank按照score的降序排序,名次从0开始。zrevrank key member
-
zrem删除元素zrem key member1 member2...
-
zincrby增加元素的分数zincrby key increment member
-
zrange查询指定区间范围的元素
-
start/stop:用于指定查询区间,但是在不同模式下,其代表的含义也不相同
- 默认模式下,
start~stop表示的是名次区间,且该区间为闭区间。名次从0开始,且可为负数,-1表示倒数第一,-2表示倒数第二,以此类推。 - byscore模式下(声明了byscore参数),则
start~stop表示的就是分数区间,该区间默认仍为闭区间。在该模式下,可以在start或stop前增加(来表示开区间,例如(1 (5,表示的就是(1,5)这个开区间。除此之外,还可以使用-inf和+inf表示负无穷和正无穷。
- 默认模式下,
-
byscore:用于切换到分数模式
-
rev:表示降序排序。在byscore模式下使用rev参数需要注意查询区间,start应大于stop。
-
limit:该选项只用于byscore模式,作用和sql语句中的limit一致
-
withscores:用于打印分数
zrange key start stop [byscore] [rev] [limit offset count] [withscores]
6.Spring Boot连接Redis使用
1.Spring Data Redis介绍
Spring Data Redis 是Spring大家族中的一个子项目,主要用于Spring程序和Redis的交互。它基于的Redis Java客户端(Jedis和Lettuce)做了抽象,提供了一个统一的编程模型,使得Spring程序与Redis的交互变得十分简单。
Spring Data Redis 中有一个十分重要的类------RedisTemplate,它封装了与Redis进行的交互的各种方法,我们主要用使用它与Redis进行交互。
2.使用方法
1.创建SpringBoot项目
2.选择安装Spring Data Redis依赖
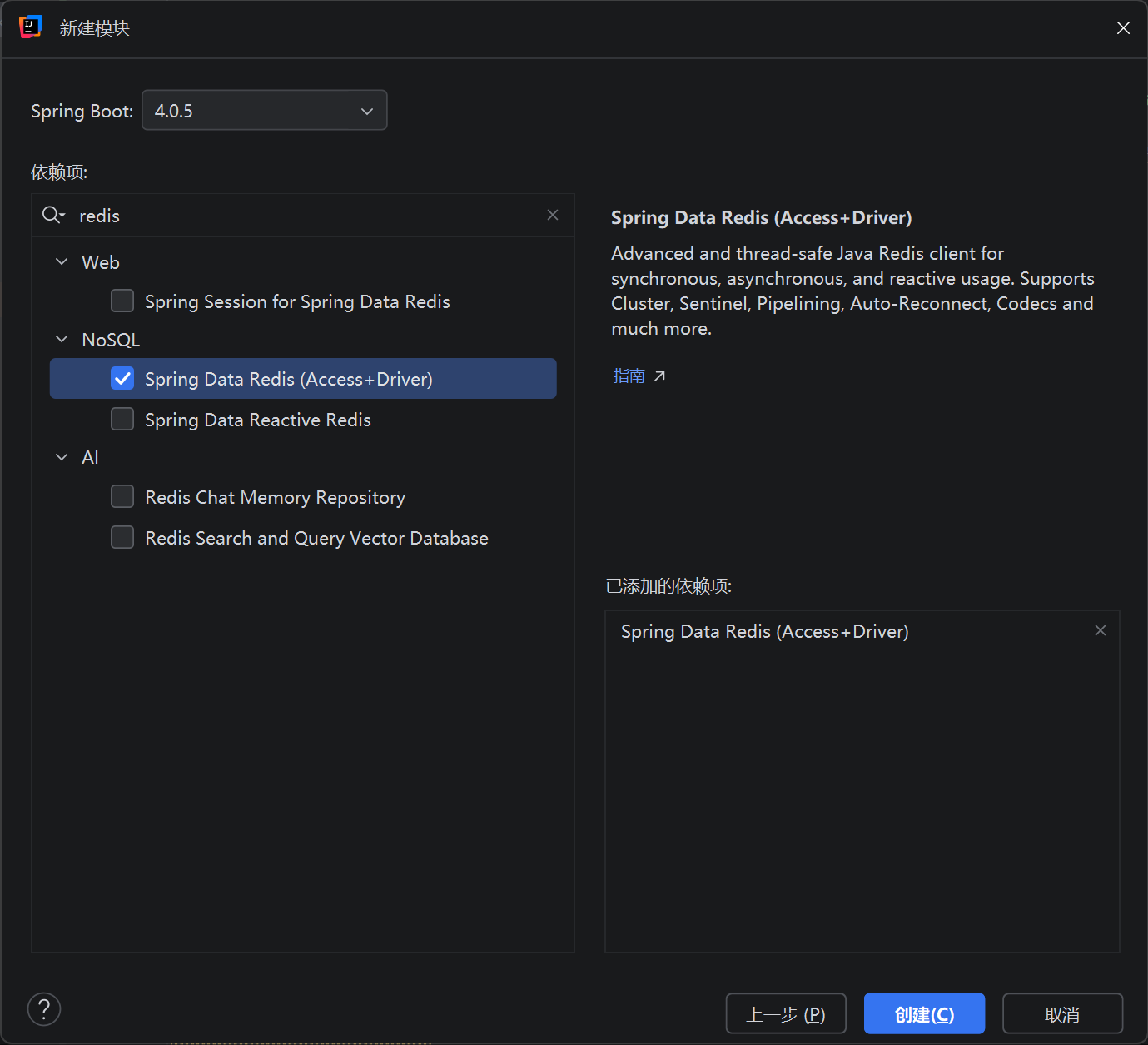
要是创建项目没有安装,需要在pom.xml文件里添加依赖配置,然后使用Maven下载依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>3.修改application.properties文件后缀为application.yml
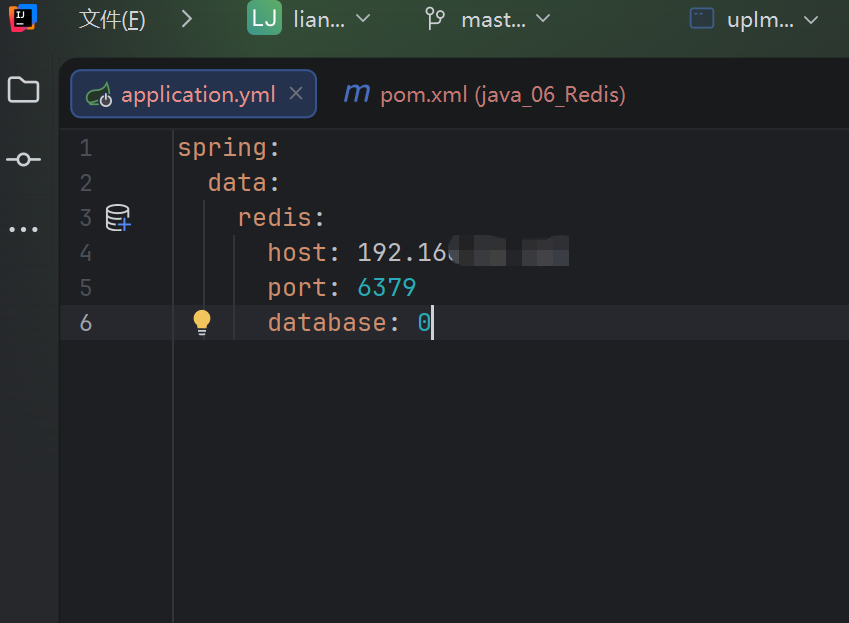
4.在application.yml文件里添加Redis配置
注意修改host为虚拟机的IP地址
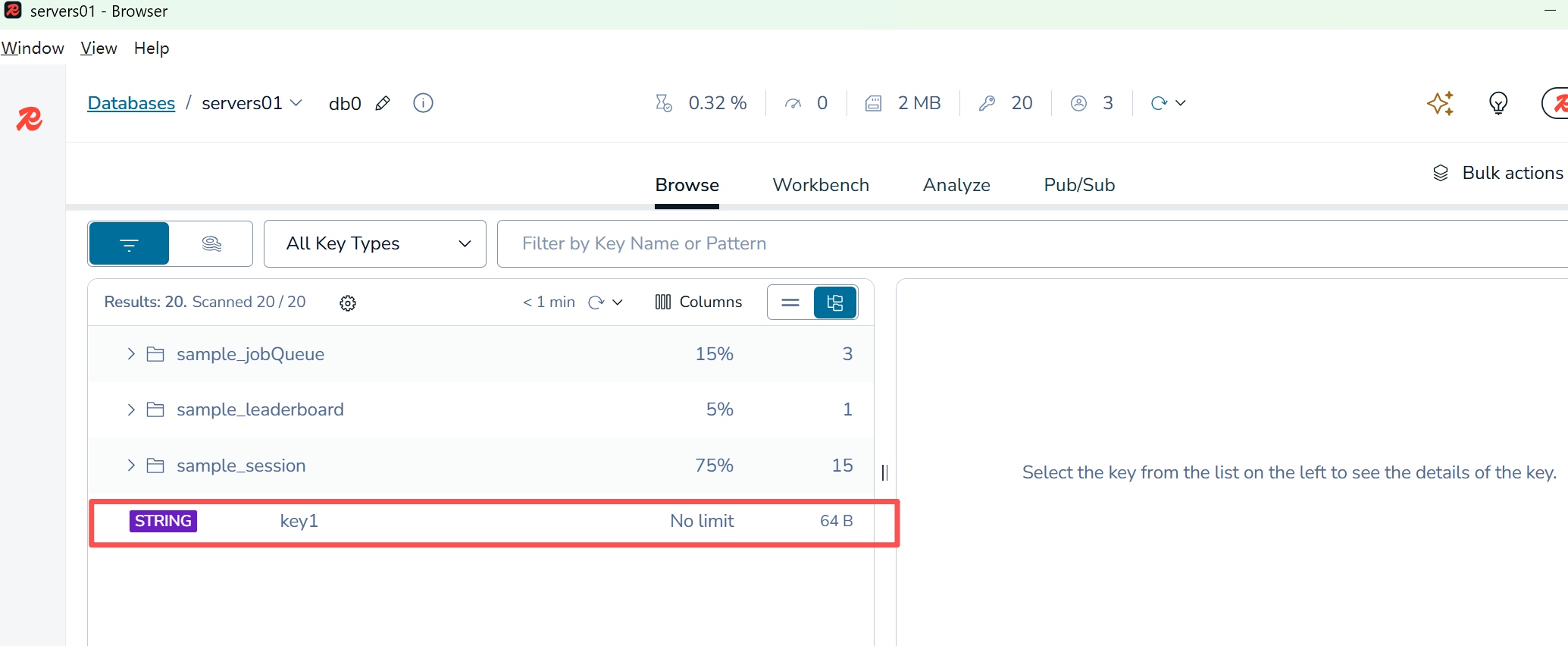
5.在项目里简单的使用
创建一个测试类,在内部调用方法
package com.redis.java_06_redis.redisTest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
public class TestRedisTemplate {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
public void testSet(){
redisTemplate.opsForValue().set("key1", "value1");
}
@Test
public void testGet(){
String result = redisTemplate.opsForValue().get("key1");
System.out.println(result);
}
@Test
public void testDel(){
redisTemplate.delete("key1");
}
}
6.根据Redis的数据类型,RedisTemplate对各种交互方法做了分组,以下是常用的几个分组
| 分组 | 说明 |
|---|---|
redisTemplate.opsForValue() |
操作string类型的方法 |
redisTemplate.opsForList() |
操作list类型的方法 |
redisTemplate.opsForSet() |
操作set类型的方法 |
redisTemplate.opsForHash() |
操作hash类型的方法 |
redisTemplate.opsForZSet() |
操作zset类型的方法 |
redisTemplate |
通用方法 |