引言:算力碎片化下的"资源孤岛"
在 AI 赋能千行百业的当下,作为安防架构师,我们面临着一个尴尬的现实:算力的极度碎片化 。客户的现场环境往往是"万国牌":数据中心里可能是 NVIDIA 的 A100,机房里堆着海思的服务器,而前端边缘端则可能是瑞芯微、比特大陆甚至是华为昇腾的 NPU 盒子。传统的视频管理平台通常绑定特定的硬件 SDK,导致企业不得不为不同的芯片维护多套代码分支。这种重复的适配工作,消耗了企业约 95% 的研发成本,却无法产生任何核心业务价值。
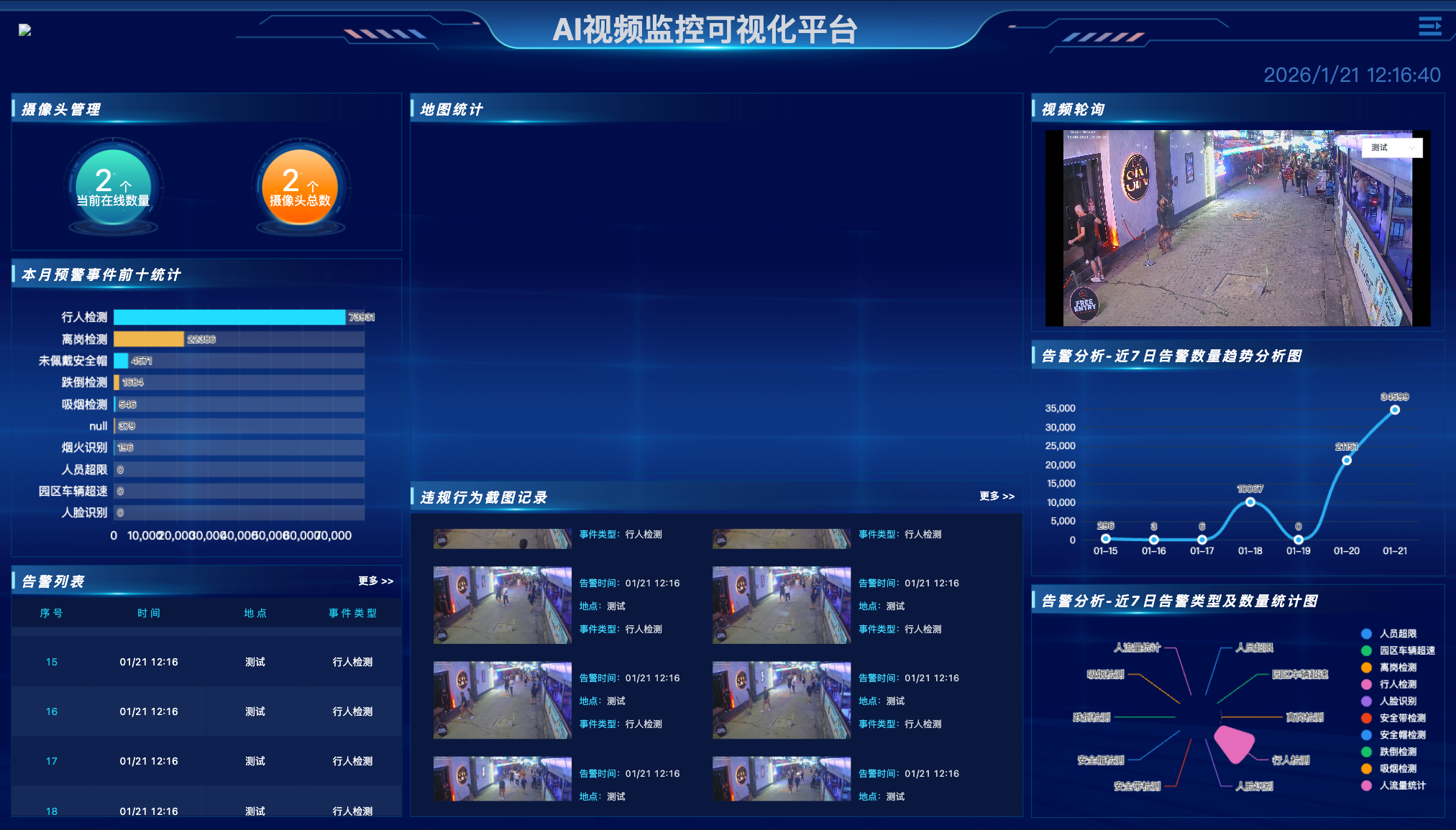
如何构建一个"一次开发,处处运行"的统一视频底座?YiheCode Server 给出的答案是"软硬解耦"。作为一个企业级 AI 视频管理平台,它通过抽象化的设备管理层和容器化部署策略,成功实现了从 x86 到 ARM,从 GPU 到 NPU 的全场景异构计算支持。本文将深入解析其如何通过微服务架构,打通芯片厂商间的壁垒,实现算力资源的统一调度。
一、 底层架构:指令集无关性与容器化部署
YiheCode Server 的核心架构设计哲学是"环境隔离"与 "架构中立"。基于 Spring Boot 2.7 后端与 Vue 2.6 前端的纯 Java 技术栈,保证了应用层的跨平台能力。
1.1 跨平台指令集支持 (x86 vs ARM)
平台设计之初就考虑了国产化与多样化的硬件环境,支持在不同指令集架构下无缝迁移:
- 服务端:支持标准的 x86 服务器,同时也完美适配基于 ARM 架构的国产服务器(如鲲鹏、飞腾等)。
- 部署方式 :推荐使用 Docker 容器化部署。通过构建多架构镜像(Multi-Architecture Images),系统可以自动识别底层 CPU 指令集(AMD64/ARM64),无需修改代码即可运行。
1.2 边缘-云协同架构
系统采用了标准的分层架构:
- 边缘层:部署轻量级 Agent 或直接在 NPU 盒子上运行推理程序。
- 平台层:中心化管理,负责配置下发、告警汇聚与数据存储。
- 解耦逻辑:中心平台不直接依赖边缘的硬件 SDK,而是通过标准化的通信协议(如 HTTP/WebSocket)与边缘节点交互,实现了业务逻辑与硬件驱动的彻底分离。
二、 异构计算:多芯片 NPU/GPU 的统一纳管
这是 YiheCode Server 最具技术含量的部分。文档明确指出平台支持"全硬件适配",这意味着它必须解决不同 AI 芯片(NPU/GPU)的算子差异问题。
2.1 硬件抽象层 (HAL) 设计
平台并没有试图用一套 C++ 代码兼容所有芯片,而是采用了"插件化算法"策略:
- 自定义模型注入:开发者可以将针对特定芯片(如瑞芯微 RK3588、华为 Ascend 310)编译好的模型文件(.om, .rknn 等)上传至平台。
- 运行时隔离:算法在边缘侧独立运行,平台只关心"结果"不关心"过程"。
边缘节点配置示例 (JSON):
json
{
"device_info": {
"device_id": "edge_node_001",
"chip_type": "Rockchip_RK3588", // 识别芯片类型
"architecture": "ARM64",
"compute_power": "10.0_Tops"
},
"algorithm_list": [
{
"algorithm_id": "smoke_detect_v1",
"model_file": "rk3588_smoke_detect.rknn", // 根据芯片类型加载特定模型
"input_source": "rtsp://camera01/stream",
"status": "running"
}
]
}2.2 动态算力调度策略
在多路视频接入的场景下,系统需要智能分配算力资源。平台通过"边缘推流"与"按需计算"机制来优化性能:
- 负载感知:中心平台定时获取边缘节点的 CPU/NPU 利用率。
- 动态启停:根据业务优先级,远程控制边缘盒子的算法开关。例如,夜间非工作时段自动关闭"玩手机检测",开启"离岗检测"。
三、 高可用与流媒体分发
除了硬件适配,海量视频流的稳定传输也是架构设计的难点。基于 Gitee 文档提及的"灵活组网"与"集群管理",系统采用了以下策略:
3.1 ZLMediaKit 流媒体集群
为了应对 x86 和 ARM 混合部署的网络环境,平台集成了 ZLMediaKit 作为流媒体引擎。
- 自动分配策略:当新增摄像头时,系统会根据现有 ZLM 节点的负载(Load),自动将流媒体流转到压力最小的节点上。
- 协议转换:无论前端是 GB28181 推流还是 RTSP 拉流,统一转码为标准的 FLV/HLS 流供前端播放,屏蔽了底层协议的差异。
3.2 边缘推流模式 (Edge Push)
针对复杂的网络拓扑(如边缘在内网,平台在公网),架构支持边缘主动推流模式:
- 逻辑 :边缘盒子拉取本地 IPC 视频流 →\rightarrow→ 硬件编码 →\rightarrow→ 推送 RTMP 至中心服务器。
- 优势:无需公网 IP,无需复杂 NAT 穿透,极大降低了网络部署门槛。
四、 总结
YiheCode Server 通过**"应用容器化"与 "算法插件化"的架构设计,成功构建了一个 异构计算统一底座。
对于技术决策者而言,这套架构的价值在于:它将"适配不同硬件 SDK"的沉没成本,转化为 "模型文件替换"的简单操作。无论是基于 x86 的高性能 GPU 服务器,还是基于 ARM 的低功耗 NPU 边缘盒子,都能在这个平台上被统一管理、调度和监控。这种"软硬解耦"的能力,正是实现"减少 95% 开发成本"并快速完成项目交付的技术基石。
架构师建议 :
在进行异构部署时,建议将 ZLMediaKit 流媒体节点 与 AI 推理节点物理分离。对于 ARM 边缘设备,尽量在边缘侧完成算法推理和 RTMP 推流,中心节点仅负责存储和展示,以降低中心服务器的解码压力,确保大规模部署时的系统稳定性。