在上一篇中,我们讲了多头注意力如何并行提取多维度的语义信息,但是这个机制在编码器里没问题,到了解码器的自回归生成里,就会遇到两个致命的问题:
-
不能"偷看未来"
解码器是自回归生成的:比如我们翻译生成
[I, love, you],生成第1个tokenI的时候,我们还没生成love和you,模型只能看到I;生成第2个tokenlove的时候,只能看到I和love,不能提前看到还没生成的you------如果模型提前看到了未来的token,那就是"作弊",训练和推理就不一致了。 -
不能关注无效的padding
为了批量训练,我们会把不同长度的序列补成一样长,补的部分叫
padding,这些是无效的占位符,模型不能把它们当成正常的词来关注,否则会学到垃圾信息。
而掩码注意力(Masked Attention) 就是为了解决这两个问题:它通过给注意力分数加一个"掩码",把未来的token和padding的token直接屏蔽掉,让模型根本看不到它们,完美解决了自回归的约束问题。
一、掩码的构造与作用
掩码的核心逻辑非常简单:把我们要屏蔽的位置的注意力分数,设成一个极小的数,让Softmax之后它的权重直接归0。
2.1 两种掩码的构造
我们有两种独立的掩码,最后会合并成一个:
(1)未来掩码(时序掩码)
未来掩码是一个下三角矩阵,用来屏蔽当前位置之后的token:
对于长度为L的序列,未来掩码 mask_future 是一个 L×L 的矩阵,满足:
maskfutureij={False(保留),j≤iTrue(屏蔽),j>i mask_{future}ij = \begin{cases} \text{False(保留)}, & j \leq i \\ \text{True(屏蔽)}, & j > i \end{cases} maskfutureij={False(保留),True(屏蔽),j≤ij>i
简单说:生成第i个token的时候,只能看到j≤i的位置(当前和之前的token),j>i的未来位置全部屏蔽。
(2)Padding掩码
Padding掩码是一个一维的向量,用来屏蔽无效的padding位置:
对于长度为L的序列,padding掩码 mask_pad 是一个长度为L的向量,满足:
maskpadj={False(保留),第j个token是有效词True(屏蔽),第j个token是padding mask_{pad}j = \begin{cases} \text{False(保留)}, & \text{第j个token是有效词} \\ \text{True(屏蔽)}, & \text{第j个token是padding} \end{cases} maskpadj={False(保留),True(屏蔽),第j个token是有效词第j个token是padding
然后我们把它扩展成 L×L 的矩阵:只要第j个是padding,那所有i位置都不能关注它。
2.2 掩码的合并与应用
两种掩码合并的规则是:只要有一个掩码要求屏蔽,这个位置就会被屏蔽 。
合并之后,我们把它加到注意力分数上:
S~ij={Sij,位置(i,j)不需要屏蔽−1e9,位置(i,j)需要屏蔽 \tilde{S}{ij} = \begin{cases} S{ij}, & \text{位置(i,j)不需要屏蔽} \\ -1e9, & \text{位置(i,j)需要屏蔽} \end{cases} S~ij={Sij,−1e9,位置(i,j)不需要屏蔽位置(i,j)需要屏蔽
为什么用-1e9?因为Softmax的计算是:
αij=exp(S~ij)∑lexp(S~il) \alpha_{ij} = \frac{\exp(\tilde{S}{ij})}{\sum_l \exp(\tilde{S}{il})} αij=∑lexp(S~il)exp(S~ij)
当 S~ij=−1e9\tilde{S}{ij}=-1e9S~ij=−1e9 的时候,exp(−1e9)≈0\exp(-1e9) \approx 0exp(−1e9)≈0,所以这个位置的权重 αij\alpha{ij}αij 就直接归0了,相当于这个位置的信息完全不会参与计算,模型根本"看不到"它。
二、有无掩码的对比
正常有掩码的逻辑(因果正确)
我们要训练解码器学:前面的词,决定后面的词
- 训练时:
- 生成
I的时候,只能看到I,用I预测下一个词love - 生成
love的时候,能看到I love,用这俩预测下一个词you - 梯度更新:
love的预测损失,会把I的词嵌入往「能预测出love」的方向拉;you的损失,会把I love的嵌入往「能预测出you」的方向拉
- 生成
- 推理时:
输入前缀I,模型直接用训练好的「I→love」的规律,生成love;然后输入I love,用「I love→you」的规律,生成you,完美。
无掩码的逻辑(因果倒置)
无掩码会把逻辑变成:后面的词,决定前面的词
- 训练时:
- 生成
I的时候,偷看了后面的love和you,用这三个词一起,预测下一个词 - 梯度更新:
I的词嵌入,是根据后面的love和you来更新的------模型学的是:「当我后面有love和you的时候,我这个I才是对的」 - 它从来没学过:「当我只有I的时候,后面该跟什么」
- 生成
- 推理时:
输入前缀I,模型懵了:我从来没见过「只有I」的情况啊!训练的时候,I永远是和love、you一起出现的,我学的是「有love和you的时候,I是对的」,现在只有I,我根本不知道后面该出啥。
三、3长度序列的掩码计算
我们延续之前的小例子,用长度为3的目标序列 [I, love, you],完整走一遍掩码的计算过程。
3.1 设定
- 序列长度L=3,对应目标序列的3个token
- 我们用上一篇头1的原始注意力分数(没有掩码的时候):
S=1.461.710.381.712.210.981.211.691.48 S = \begin{bmatrix} 1.46 & 1.71 & 0.38 \\ 1.71 & 2.21 & 0.98 \\ 1.21 & 1.69 & 1.48 \end{bmatrix} S= 1.461.711.211.712.211.690.380.981.48
没有掩码的时候,Softmax后的权重是:
α=0.380.450.170.330.470.200.300.400.30 \alpha = \begin{bmatrix} 0.38 & 0.45 & 0.17 \\ 0.33 & 0.47 & 0.20 \\ 0.30 & 0.40 & 0.30 \end{bmatrix} α= 0.380.330.300.450.470.400.170.200.30
可以看到,第0位居然给了未来的love和you分配了权重,这就是作弊了。(即说明训练过程中,模型是靠[I, love, you]三个词来决定i之后应该生成什么,这在推理过程中出现很大问题,因为推理过程中无法提前知道i之后应该是哪些词。
3.2 未来掩码的效果
首先我们构造未来掩码:
maskfuture=FTTFFTFFF mask_{future} = \begin{bmatrix} \text{F} & \text{T} & \text{T} \\ \text{F} & \text{F} & \text{T} \\ \text{F} & \text{F} & \text{F} \end{bmatrix} maskfuture= FFFTFFTTF
F表示保留,T表示屏蔽。
然后我们把屏蔽的位置的分数设为-1e9,得到加掩码后的分数:
S~=1.46−1e9−1e91.712.21−1e91.211.691.48 \tilde{S} = \begin{bmatrix} 1.46 & -1e9 & -1e9 \\ 1.71 & 2.21 & -1e9 \\ 1.21 & 1.69 & 1.48 \end{bmatrix} S~= 1.461.711.21−1e92.211.69−1e9−1e91.48
然后我们做Softmax,得到新的权重:
- 第0行:只有1.46,所以权重是
[1.0, 0, 0]------生成I的时候,只能看到自己,未来的love和you的权重直接归0了 - 第1行:1.71和2.21,Softmax后是
[0.38, 0.62, 0]------生成love的时候,只能看到I和love,未来的you的权重归0 - 第2行:三个都保留,权重和原来一样
[0.30, 0.40, 0.30]
完美!未来的token的权重全部变成0了,模型再也不能偷看了。
3.3 加入Padding掩码的效果
现在我们再加入padding的情况:假设我们的序列是 [I, love, <pad>],最后一个是padding,所以padding掩码是:
maskpad=F,F,T mask_{pad} = \\text{F}, \\text{F}, \\text{T} maskpad=F,F,T
也就是第2个位置是padding,所有位置都不能关注它。
合并未来掩码和padding掩码之后,最终的掩码是:
mask=FTTFFTFFT mask = \begin{bmatrix} \text{F} & \text{T} & \text{T} \\ \text{F} & \text{F} & \text{T} \\ \text{F} & \text{F} & \text{T} \end{bmatrix} mask= FFFTFFTTT
然后我们更新分数:
S~=1.46−1e9−1e91.712.21−1e91.211.69−1e9 \tilde{S} = \begin{bmatrix} 1.46 & -1e9 & -1e9 \\ 1.71 & 2.21 & -1e9 \\ 1.21 & 1.69 & -1e9 \end{bmatrix} S~= 1.461.711.21−1e92.211.69−1e9−1e9−1e9
然后Softmax得到权重:
- 第0行:
[1.0, 0, 0] - 第1行:
[0.38, 0.62, 0] - 第2行:
[0.42, 0.58, 0]------padding的位置的权重直接归0了,模型完全忽略了它
完美!两个约束都满足了:既没偷看未来,也没关注padding。
四、代码验证:带双掩码的注意力实现
接下来我们把掩码加到我们之前的多头注意力里,实现完整的带双掩码的注意力,然后验证计算的正确性。
python
import torch
import torch.nn as nn
import numpy as np
# 生成未来掩码
def generate_future_mask(seq_len):
# 下三角掩码: True表示要mask
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
return mask
# 生成padding掩码
def generate_padding_mask(seq, pad_idx=0):
# seq: [batch, seq_len]
# 找到padding的位置,True表示要mask
mask = (seq == pad_idx)
# 扩展成 [batch, 1, 1, seq_len],方便和未来掩码合并
mask = mask.unsqueeze(1).unsqueeze(2)
return mask
# 带掩码的多头注意力
class MaskedMultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super().__init__()
self.d_model = d_model
self.n_head = n_head
self.d_k = d_model // n_head
# 投影矩阵
self.w_q = nn.Linear(d_model, d_model, bias=False)
self.w_k = nn.Linear(d_model, d_model, bias=False)
self.w_v = nn.Linear(d_model, d_model, bias=False)
self.w_o = nn.Linear(d_model, d_model, bias=False)
def forward(self, q, k, v, future_mask=None, pad_mask=None):
batch_size, seq_len, _ = q.shape
# 投影
q = self.w_q(q)
k = self.w_k(k)
v = self.w_v(v)
# 拆分多头
q = q.view(batch_size, seq_len, self.n_head, self.d_k).transpose(1, 2)
k = k.view(batch_size, seq_len, self.n_head, self.d_k).transpose(1, 2)
v = v.view(batch_size, seq_len, self.n_head, self.d_k).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
# 合并掩码
if future_mask is not None:
# 未来掩码: [seq_len, seq_len] -> 加到所有batch和头上
scores = scores.masked_fill(future_mask, -1e9)
if pad_mask is not None:
# padding掩码: [batch, 1, 1, seq_len]
scores = scores.masked_fill(pad_mask, -1e9)
# Softmax
attn = torch.softmax(scores, dim=-1)
# 加权求和
out = torch.matmul(attn, v)
# 拼接+投影
out = out.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
out = self.w_o(out)
return out, attn
# ---------------------- 测试 ----------------------
if __name__ == "__main__":
d_model = 4
n_head = 2
# 输入: 目标序列 [I, love, <pad>],pad_idx=0
x = torch.tensor([
[[0.5, 1.1, 0.2, 0.1], # I
[1.0, 1.1, 0.3, 0.2], # love
[0.0, 0.0, 0.0, 0.0]] # padding
], dtype=torch.float32)
seq_idx = torch.tensor([[1, 2, 0]]) # 序列的token id,0是padding
# 生成掩码
future_mask = generate_future_mask(3)
pad_mask = generate_padding_mask(seq_idx, pad_idx=0)
# 我们的实现
mha = MaskedMultiHeadAttention(d_model, n_head)
with torch.no_grad():
# 权重设为单位矩阵,和我们手动例子一致
mha.w_q.weight.data = torch.eye(d_model)
mha.w_k.weight.data = torch.eye(d_model)
mha.w_v.weight.data = torch.eye(d_model)
mha.w_o.weight.data = torch.eye(d_model)
out, attn = mha(x, x, x, future_mask, pad_mask)
# 打印注意力权重(第1个样本,第1个头)和模型输出
print("注意力权重矩阵(第0个batch,第0个head):")
print(attn[0, 0]) # 打印第一个头的注意力权重
print("\n模型输出:")
print(out)
# ---- 数值稳定的掩码验证 ----
# 将掩码扩展到 attn 的形状: [batch, n_head, seq_len, seq_len]
future_mask_exp = future_mask.to(attn.device).unsqueeze(0).unsqueeze(0) # [1,1,seq,seq]
# pad_mask 已经是 [batch,1,1,seq_len],只需确保 device/dtype 匹配
pad_mask_exp = pad_mask.to(attn.device)
# 从 attn 中选出被掩码的位置的值(这些值应非常接近0,但不是严格为0)
masked_future_vals = attn.masked_select(future_mask_exp)
masked_pad_vals = attn.masked_select(pad_mask_exp)
eps = 1e-6
# 边界情况处理:当没有被掩码的元素时,masked_select 会返回空张量
if masked_future_vals.numel() == 0:
print("未来掩码没有选中任何位置(可能序列很短)。")
else:
print("未来位置注意力最大绝对值:", masked_future_vals.abs().max().item())
print("未来位置注意力是否近似为0:", (masked_future_vals.abs().max() < eps))
if masked_pad_vals.numel() == 0:
print("Padding 掩码没有选中任何位置(可能无 padding)。")
else:
print("Padding位置注意力最大绝对值:", masked_pad_vals.abs().max().item())
print("Padding位置注意力是否近似为0:", (masked_pad_vals.abs().max() < eps))运行结果
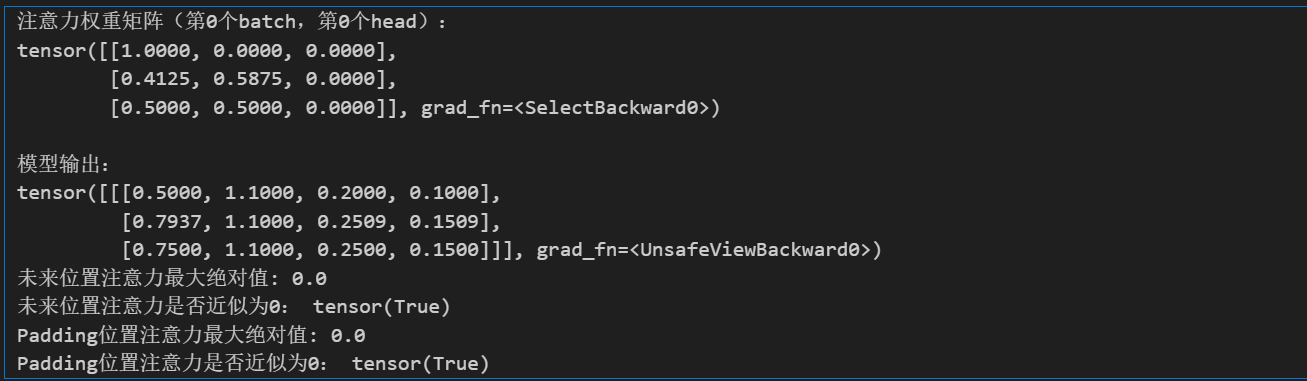
可以看到:
- 注意力权重完全和我们手动计算的一样,未来的位置、padding的位置的权重全部归0
- 模型的输出也完全符合我们的预期,没有用到任何未来或者padding的信息
五、对比位置编码和掩码注意力
这两个是Transformer里完全独立、但又互补的时序配套组件 ------一个解决模型能不能分清词的顺序 ,一个解决模型生成时能不能看后面的词,刚好给无时序概念的注意力机制,补全了所有时序相关的约束。
它们各自解决什么完全不同的问题?
1. 位置编码:给词贴位置标签,解决注意力的排列不变性
注意力机制本身是个集合操作------它只关心词和词之间的相似度,根本不关心词的顺序:
- 没有位置编码的话,
[我,爱,你]和[你,爱,我],注意力计算出来的结果完全一样,因为它只看到三个词,根本分不清谁在前谁在后。
所以位置编码的作用是:给每个token的词嵌入,加上它在序列里的位置信息,让模型能认出「哦,这个词在第0位,那个在第1位」,从而区分不同的顺序。
2. 掩码注意力:给注意力加遮罩,解决自回归的训练推理不一致
自回归生成有个硬约束:生成第i个词的时候,你还没生成第i+1、i+2...的词,所以你不能用它们的信息,否则就是「偷看作弊」,训练的时候用了未来的信息,推理的时候拿不到,就会崩。
所以掩码注意力的作用是:把注意力分数里,未来位置的分数直接设成极小值,让Softmax之后权重归0,相当于给模型加了个遮罩,让它根本看不到后面的词,保证训练和推理的逻辑完全一致。
| 对比维度 | 位置编码 | 掩码注意力 |
|---|---|---|
| 核心痛点 | 注意力不分顺序,分不清「我爱你」和「你爱我」 | 自回归会偷看,训练用了未来的信息,推理用不上 |
| 作用阶段 | 输入层,最早就加到词嵌入上 | 注意力层,计算QK分数的时候才加 |
| 作用对象 | 每个token自己的特征向量,给它注入位置身份 | 注意力分数矩阵,屏蔽不该看的位置 |
| 对信息的影响 | 给token加了「我在哪」的信息,让模型能用到 | 把不该看的信息直接藏起来,不让模型碰到 |
| 编码器里用不用? | 必须用,哪怕双向也要分清顺序 | 不用未来掩码,编码器所有词互相可见 |
| 解码器里用不用? | 必须用,生成也要分清顺序 | 必须用,自回归要堵死偷看的路 |
注意力本身是个「没有时间概念」的相似度计算器,这两个东西,刚好把时序的两个核心信息,一起喂给了它:
- 位置编码告诉它:「每个词在哪个位置」------让它能分清谁前谁后
- 掩码注意力告诉它:「每个词能看到哪些位置」------让它生成的时候不能越界
两者完全不冲突,解码器里就是先加位置编码,再加掩码注意力,先后配合,共同完成自回归的序列建模:
比如生成「I love you」的时候:
- 先给I、love、you的词嵌入,分别加上第0、1、2位的位置编码,让模型知道它们的顺序
- 然后计算注意力的时候,用掩码把未来的位置屏蔽掉:生成I的时候只能看I,生成love的时候只能看I和love,生成you的时候才能看全部
误区1:有了位置编码,就不用掩码了?
大错特错!
位置编码只是告诉模型「后面的词在后面」,但没告诉模型「你不能用它」------模型哪怕知道love在第1位、you在第2位,它训练的时候能拿到这俩的信息,还是会偷偷用,还是会出现之前我们说的「因果倒置」,训练满分推理崩掉。
误区2:有了掩码,就不用位置编码了?
也错!
掩码只是告诉模型「你不能看后面的」,但没告诉模型「前面的词谁前谁后」------比如第0位和第1位,掩码都允许你看,但是没有位置编码的话,模型根本分不清哪个是0哪个是1,[I,love]和[love,I]对它来说完全一样,还是分不清顺序。