使用唯一标识码替换员工ID
产品销售分析 I
进店却未进行过交易的顾客
上升的温度
每台机器的进程平均运行
员工奖金
学生们参加各科测试的次数
至少有5名直接下属的经理
确认率
1378. 使用唯一标识码替换员工ID
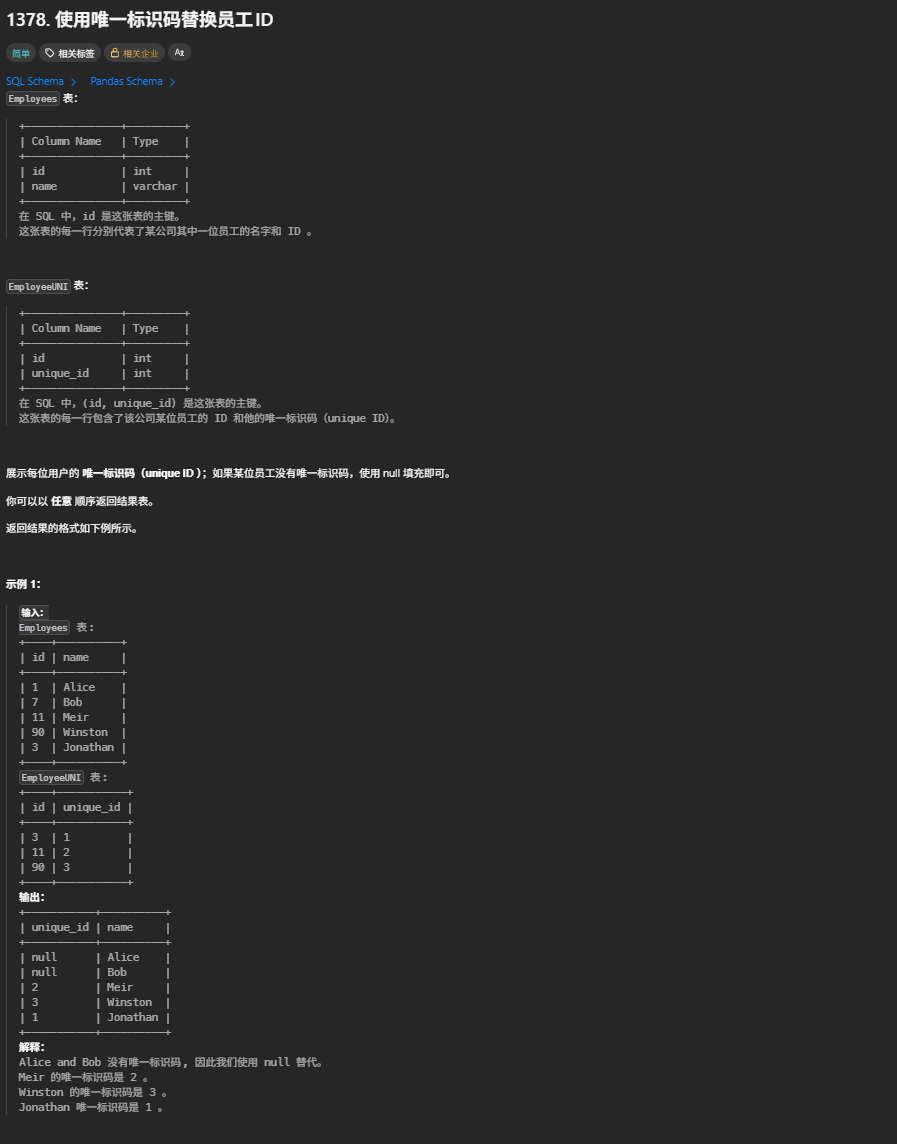
写法
select unique_id , name from Employees left join EmployeeUNI on Employees.id =EmployeeUNI.id;1068. 产品销售分析 I
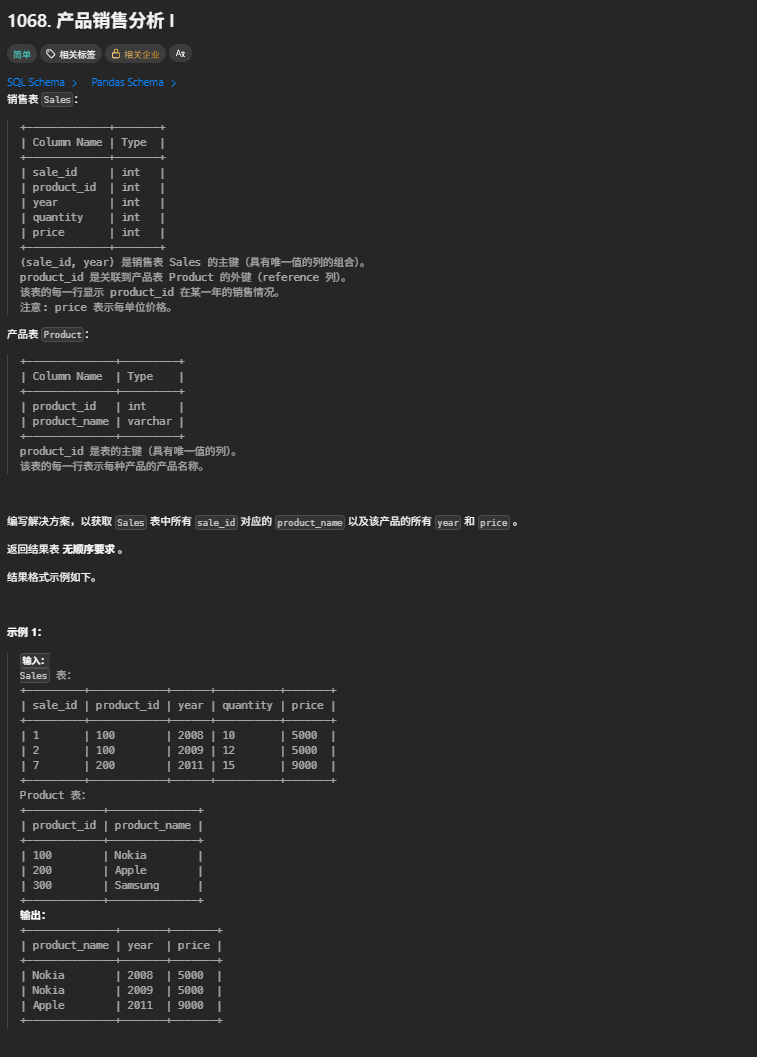
我的写法
select product_name , year , price from Sales natural join Product ;参考写法
SELECT Product.product_name, Sales.year, Sales.price
FROM Product INNER Join Sales
On Product.product_id = Sales.product_id;1581. 进店却未进行过交易的顾客
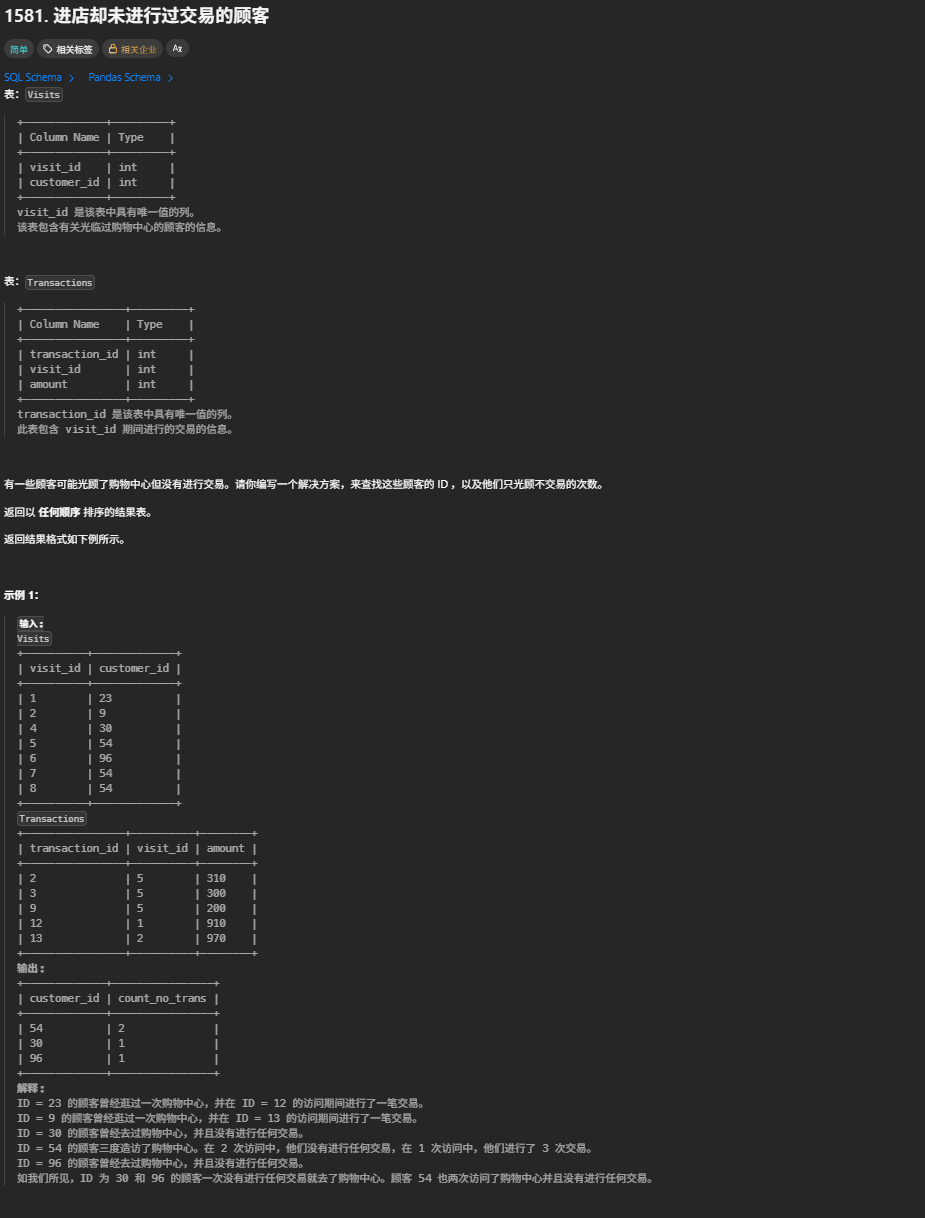
步骤一:使用 LEFT JOIN 关联两表(Visits 左表,Transactions 右表)
步骤二:关联后得到中间表
|----------|-------------|----------------|----------|--------|
| visit_id | customer_id | transaction_id | visit_id | amount |
| 1 | 23 | 12 | 1 | 910 |
| 2 | 9 | 13 | 2 | 970 |
| 4 | 30 | null | 4 | null |
| 5 | 54 | 2 | 5 | 310 |
| 5 | 54 | 3 | 5 | 300 |
| 5 | 54 | 9 | 5 | 200 |
| 6 | 96 | null | 6 | null |
| 7 | 54 | null | 7 | null |
| 8 | 54 | null | 8 | null |
步骤三:最终需要 customer_id、count_no_trans 两个字段
步骤四:用过滤条件 WHERE transaction_id IS NULL(或 amount IS NULL)筛选
过滤后得到的表:
|----------|-------------|----------------|----------|--------|
| visit_id | customer_id | transaction_id | visit_id | amount |
| 4 | 30 | null | 4 | null |
| 6 | 96 | null | 6 | null |
| 7 | 54 | null | 7 | null |
| 8 | 54 | null | 8 | null |
步骤五:按 customer_id 分组聚合,统计无交易的访问次数
最终结果表:
|-------------|----------------|
| customer_id | count_no_trans |
| 54 | 2 |
| 30 | 1 |
| 96 | 1 |
SELECT
v.customer_id,
COUNT(v.visit_id) AS count_no_trans
FROM
Visits v
LEFT JOIN
Transactions t
ON
v.visit_id = t.visit_id
WHERE
t.transaction_id IS NULL
GROUP BY
v.customer_id;197. 上升的温度
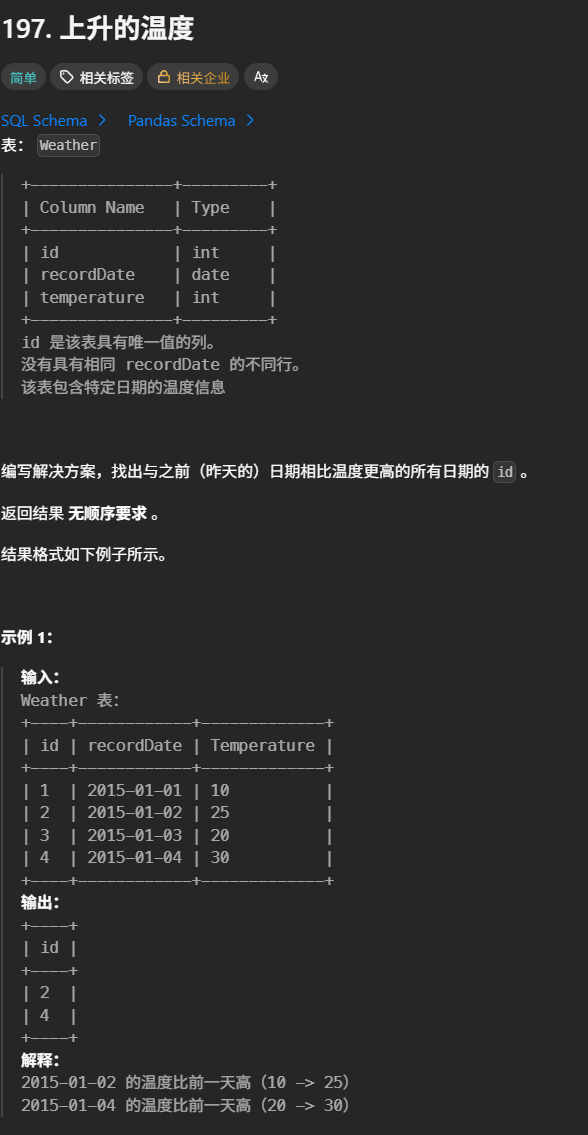
SELECT w1.id
FROM Weather w1
JOIN Weather w2
ON DATEDIFF(w1.recordDate, w2.recordDate) = 1
AND w1.temperature > w2.temperature;FROM Weather w1 JOIN Weather w2 对 Weather 表做自连接,把表拆成两个副本:
-
w1:代表「今天」的温度记录 -
w2:代表「昨天」的温度记录
ON DATEDIFF(w1.recordDate, w2.recordDate) = 1 用 DATEDIFF 函数计算两个日期的天数差,筛选出 ** 相差 1 天(即昨天和今天)** 的记录对
-
不同数据库的日期函数差异:
-
MySQL:
DATEDIFF(w1.recordDate, w2.recordDate) = 1 -
PostgreSQL:
w1.recordDate - w2.recordDate = INTERVAL '1 day' -
SQL Server:
DATEDIFF(day, w2.recordDate, w1.recordDate) = 1
-
AND w1.temperature > w2.temperature 筛选出「今天温度 > 昨天温度」的记录,最终取出今天的 id 作为结果
1661. 每台机器的进程平均运行时间
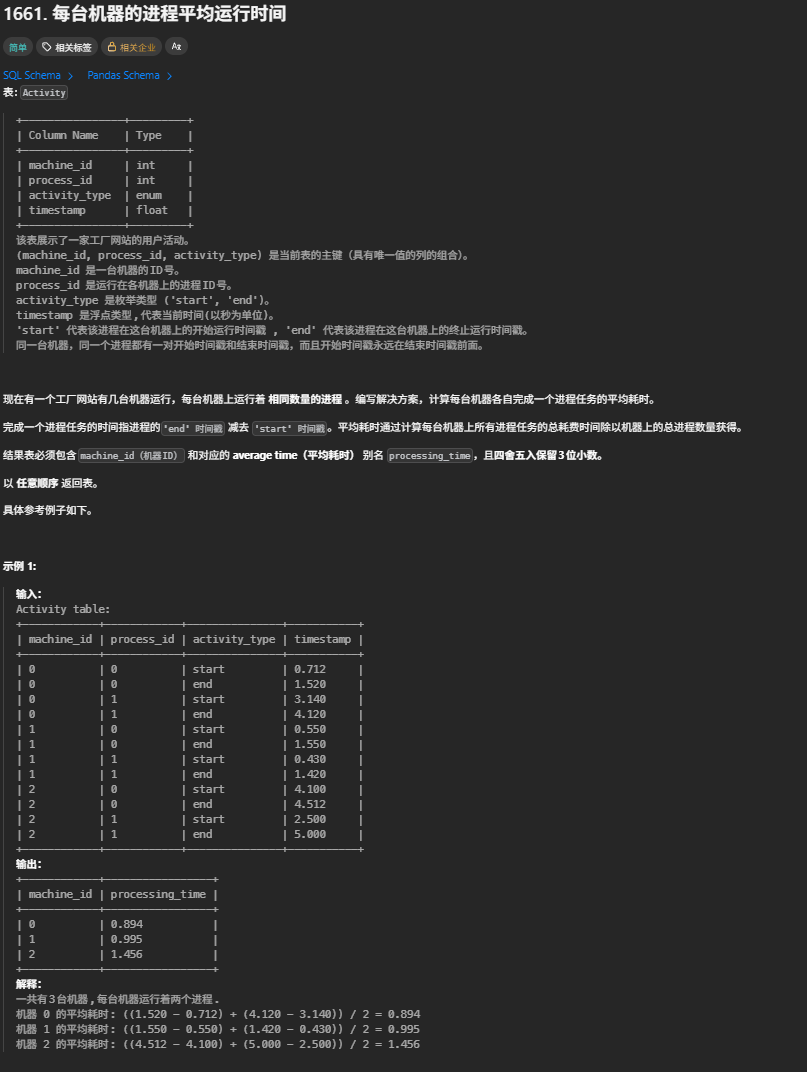
SELECT
a1.machine_id,
ROUND(AVG(a2.timestamp - a1.timestamp), 3) AS processing_time
FROM
Activity a1
JOIN
Activity a2
ON
a1.machine_id = a2.machine_id
AND a1.process_id = a2.process_id
AND a1.activity_type = 'start'
AND a2.activity_type = 'end'
GROUP BY
a1.machine_id;FROM Activity a1 JOIN Activity a2 对 Activity 表做自连接 ,将同一进程的 start 和 end 记录关联到同一行:
-
a1:代表start类型的记录 -
a2:代表end类型的记录
ON 关联条件
-
a1.machine_id = a2.machine_id:同一机器 -
a1.process_id = a2.process_id:同一进程 -
a1.activity_type = 'start' AND a2.activity_type = 'end':匹配开始和结束记录
**a2.timestamp - a1.timestamp**计算单个进程的运行耗时
**AVG(...)**对同一机器的所有进程耗时求平均值
**ROUND(..., 3)**四舍五入保留 3 位小数,符合题目要求
**GROUP BY a1.machine_id**按机器 ID 分组,分别计算每台机器的平均耗时
577. 员工奖金
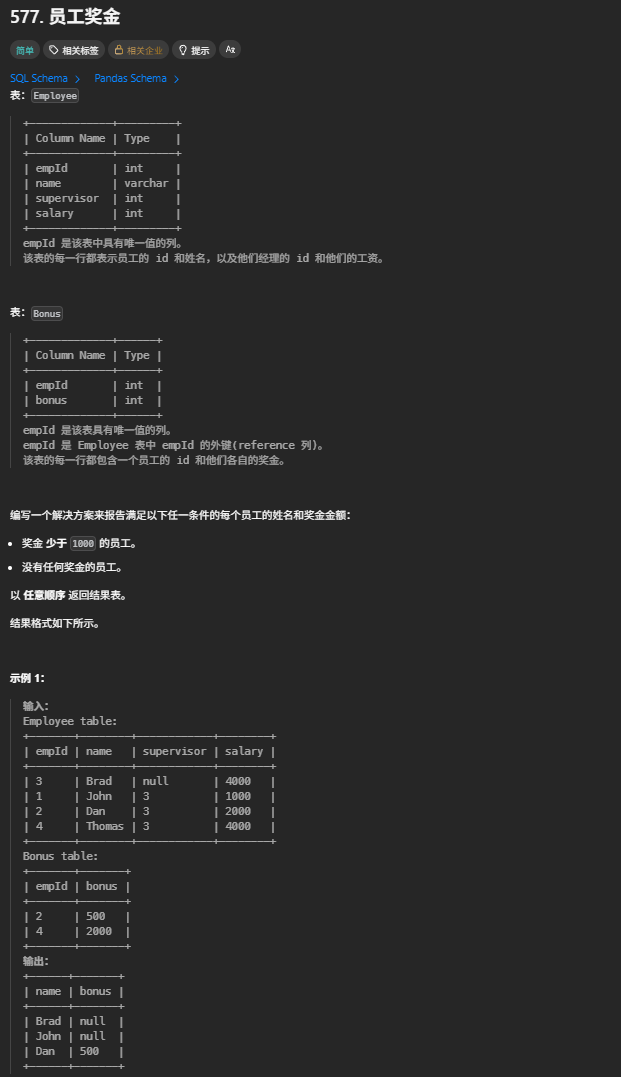
SELECT
e.name,
b.bonus
FROM
Employee e
LEFT JOIN
Bonus b
ON
e.empId = b.empId
WHERE
b.bonus < 1000 OR b.bonus IS NULL;FROM Employee e LEFT JOIN Bonus b ON e.empId = b.empId 以 Employee 为左表做左连接,保留所有员工记录:
-
有奖金的员工:
bonus列显示对应金额 -
无奖金的员工:
bonus列自动填充null
**WHERE b.bonus < 1000 OR b.bonus IS NULL**同时满足两个筛选条件:
-
b.bonus < 1000:奖金小于 1000 -
b.bonus IS NULL:无任何奖金(左连接产生的空值)
**SELECT e.name, b.bonus**最终返回员工姓名和对应奖金,符合题目要求
1280. 学生们参加各科测试的次数
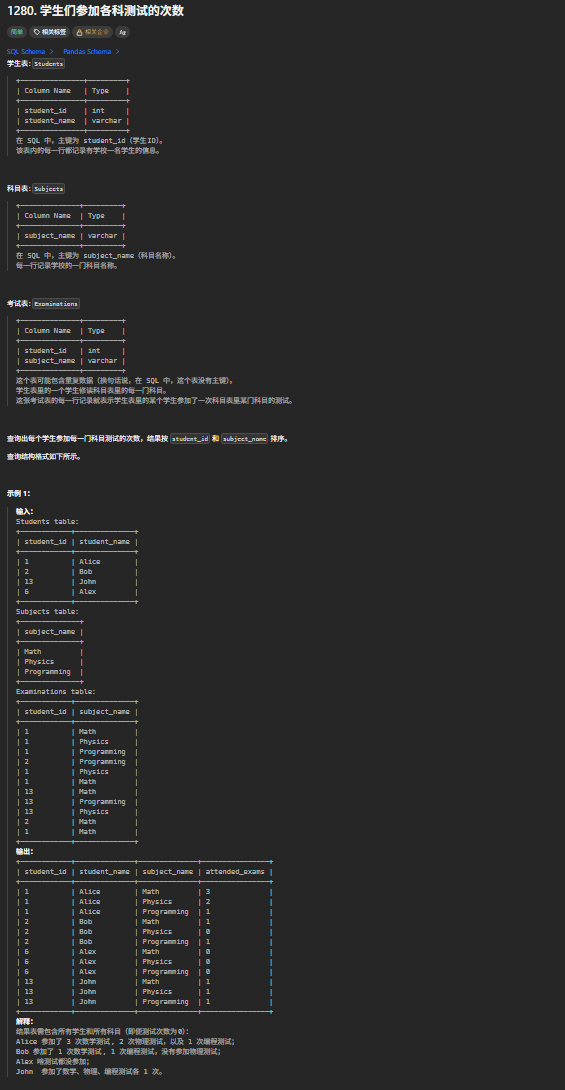
SELECT
s.student_id,
s.student_name,
sub.subject_name,
COUNT(e.subject_name) AS attended_exams
FROM
Students s
CROSS JOIN
Subjects sub
LEFT JOIN
Examinations e
ON
s.student_id = e.student_id
AND sub.subject_name = e.subject_name
GROUP BY
s.student_id, s.student_name, sub.subject_name
ORDER BY
s.student_id, sub.subject_name;CROSS JOIN Students s, Subjects sub(笛卡尔积)
-
作用:生成所有学生 × 所有科目 的完整组合(即每个学生对应每一门科目,共
学生数 × 科目数行) -
这是实现「0 次考试也显示」的核心步骤,确保不会遗漏任何学生 - 科目组合
LEFT JOIN Examinations e ON ...(左连接考试记录)
-
关联条件:
student_id和subject_name同时匹配 -
作用:将完整组合与实际考试记录关联,无考试记录的组合会被填充为
null
COUNT(e.subject_name) AS attended_exams(统计次数)
-
注意:必须用
COUNT(e.subject_name)而非COUNT(*)-
COUNT(*)会统计所有行(包括 null),导致 0 次考试被计为 1 -
COUNT(列名)会自动忽略 null 值,精准统计实际考试次数
-
GROUP BY s.student_id, s.student_name, sub.subject_name(分组)
-
按学生 ID、学生姓名、科目名分组,确保每个学生 - 科目组合单独统计
-
符合 SQL 语法规范(非聚合列必须出现在 GROUP BY 中)
ORDER BY s.student_id, sub.subject_name(排序)
- 按要求对结果升序排序
570. 至少有5名直接下属的经理
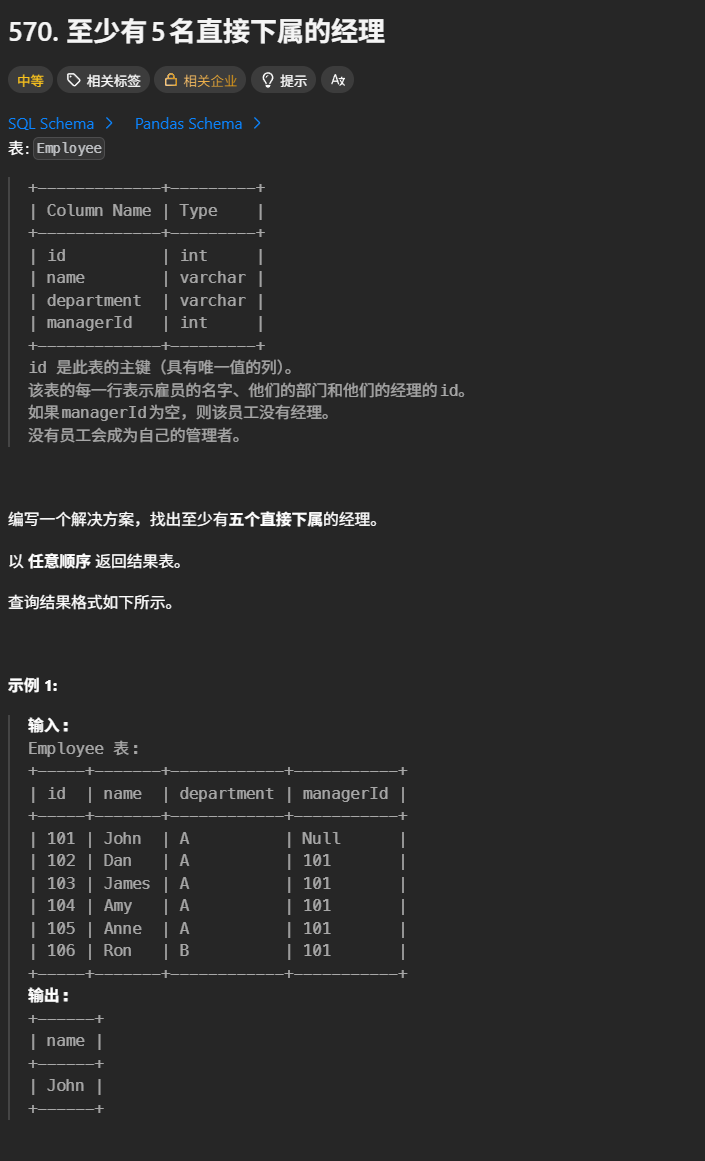
写法 1:子查询分组(推荐,兼容性最好)
SELECT name
FROM Employee
WHERE id IN (
SELECT managerId
FROM Employee
WHERE managerId IS NOT NULL
GROUP BY managerId
HAVING COUNT(*) >= 5
);写法 2:自连接 + 分组
SELECT e1.name
FROM Employee e1
JOIN Employee e2
ON e1.id = e2.managerId
GROUP BY e1.id, e1.name
HAVING COUNT(e2.id) >= 5;1934. 确认率
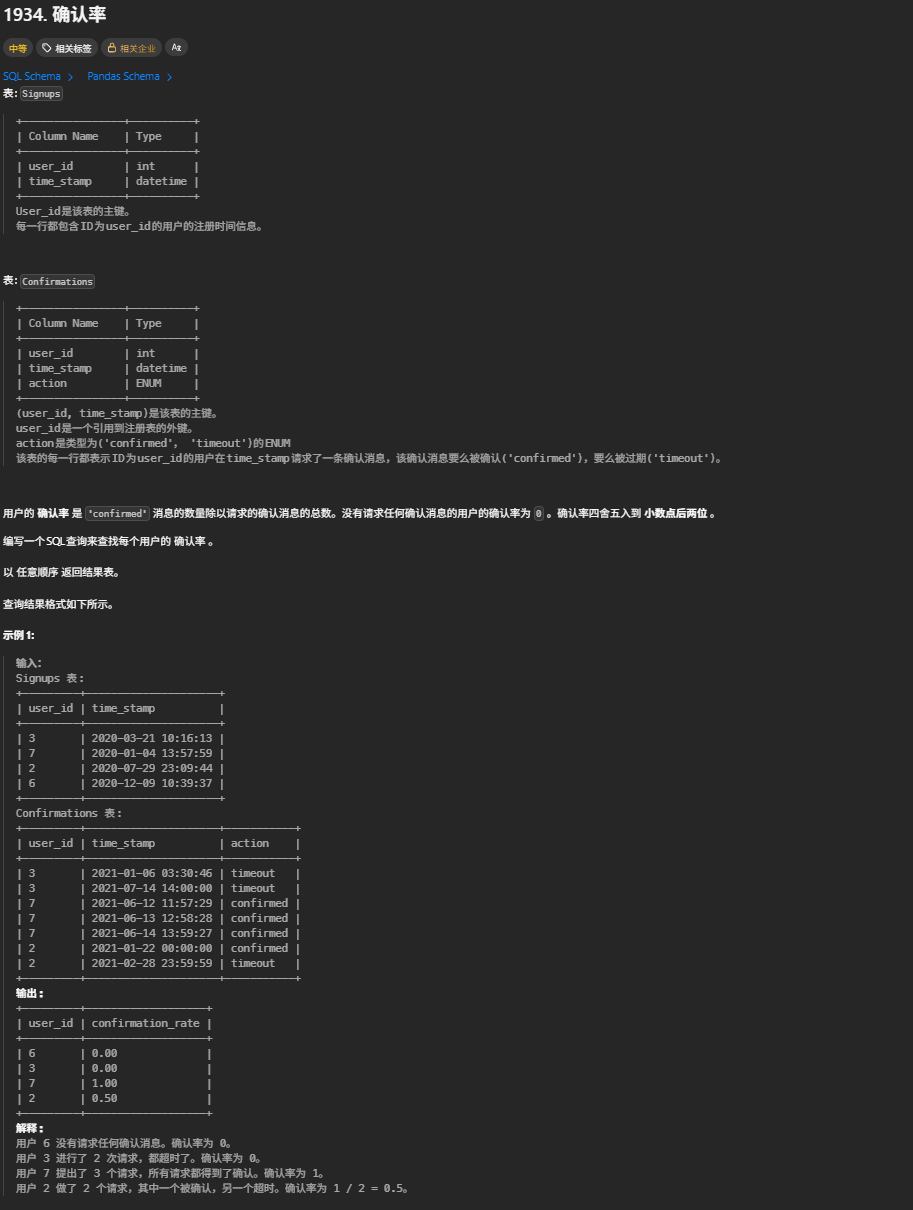
-- 等价手动计算写法
SELECT
s.user_id,
ROUND(
IFNULL(SUM(IF(c.action = 'confirmed', 1, 0)) / COUNT(c.action), 0),
2
) AS confirmation_rate
FROM Signups s
LEFT JOIN Confirmations c ON s.user_id = c.user_id
GROUP BY s.user_id;
SUM(IF(c.action = 'confirmed', 1, 0))
-
如果
action = confirmed→ 记 1 -
否则(timeout / NULL)→ 记 0
-
SUM把所有 1 加起来 → 成功确认次数
总结
这篇内容整理了多道经典 SQL 联表练习题,涵盖左连接、自连接、内连接、笛卡尔积、分组统计、条件过滤等核心用法,从员工 ID 关联、销售数据分析,到无交易顾客统计、温度对比、进程耗时计算、奖金筛选、考试次数统计、经理下属人数及用户确认率计算,通过清晰步骤和对应 SQL 写法,系统练习了多表联合查询与聚合函数的实际应用,能快速巩固 JOIN 与 GROUP BY 的解题思路。
