1.redis概述
redis是一款高性能的NOSQL系列的非关系型数据库
1.常见的NoSql数据库
概述:NOSQL(NoSQL= Not Only SQL),意即"不仅仅是SQL",是一项全新的数据库理念,泛指非关系型的数据库简单来说,就是传统的关系型数据库虽然也非常优秀,但是面对海量数据、高并发的时候,会无法应对(存在IO操作)。而NOSQL为了处理海量数据,高并发,将关系型数据库的关系去掉,仅存数据,且将所有数据存在内存中。
1.Redis
2.MongoDB
3.Memcache
4.HBase
2.redis概述
Redis(Remote Dictionary server) 由salvator sanfilippo在2009年开源的使用 ANSI C 语言编写、高性能、遵守 BSD 协议、支持网络可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API的非关系型数据库。与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存,每秒可处理超过 10 万次读写操作,是已知性能最快的
3.redis特点
1.单线程,Redis是单线程的,所以Redis的所有单个操作都是原子性的。多个操作也能由事务来保证原子性(通过MULT!和EXEC这两个指令),因此在redis层面无需考虑并发所带来的影响
2.性能极高,读110000/S,写81000/s
3.丰富的数据类型:String、List、Hash,set及Ordered set
4.支持持久化
5.支持横向扩展
6.丰富的特性,redis还支持publish/subscribe,通知,key过期等等特性7)redis的单个key和value的最大大小都是512M(避免大key操作)
4.IO多路复用
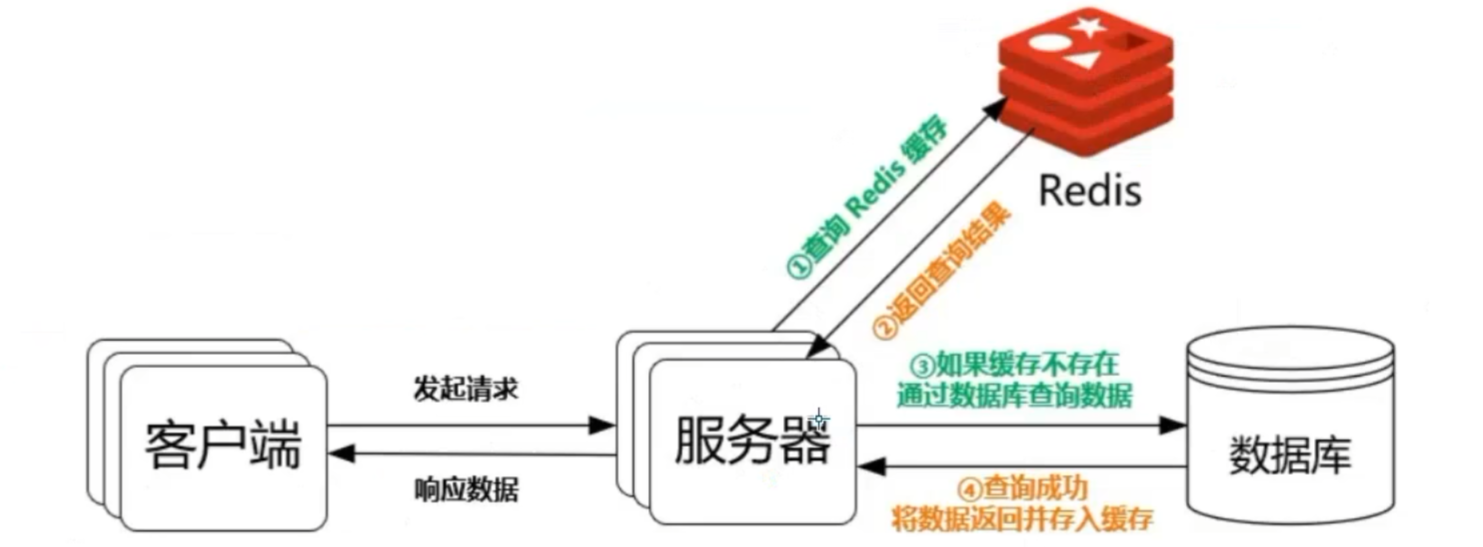
Redis的IO多路复用:
redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
2.Redis常用数据类型
1.redis启动安装
bash
wget http://download.redis.io/releases/redis-6.2.6.tar.gztar -zxvf redis-6.2.6.tar.gz -C /usr/local/
cd /usr/local/redis-6.2.6
yum -y install gcc
make && make install
vim redis.conf
# 搜索配置文件/bind,然后enter查找到按n查找下一个
# 允许远程访问
bind 0.0.0.0
# 禁用保护模式(无需密码)
protected-mode no
# 允许后台访问
daemonize yes
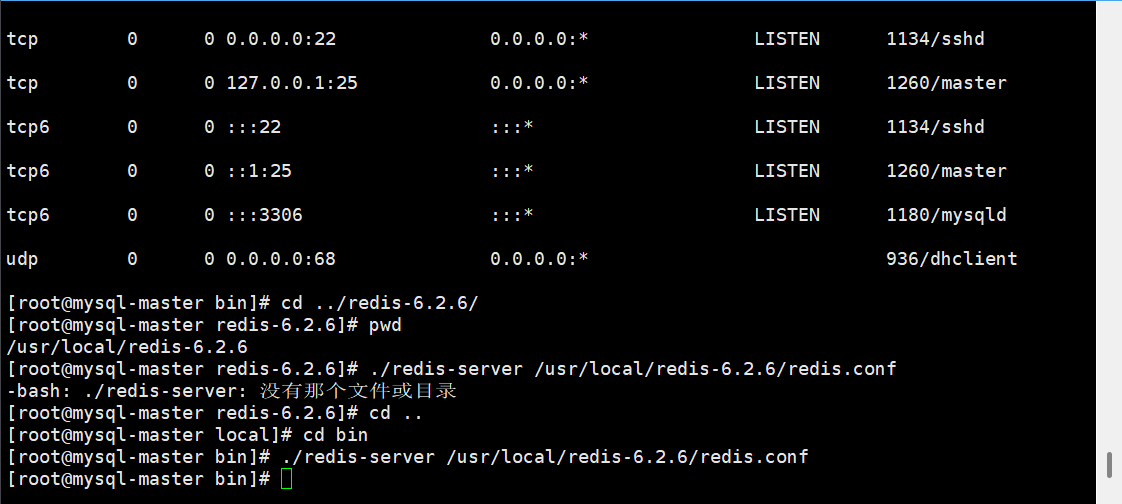
# 启动redis,进入到/usr/local/bin目录下启动redis
./redis-server #启动redis
# 以配置文件启动redis
./redis-server /usr/local/redis-6.2.6/redis.conf 启动redis
开启成功后,尝试连接
连接成功,停止redis
bash
ps aus | grep redis / kill redis进程ID2.通用命令
bash
# 先启动redis命令行
./redis-cliredis基础命令表
| 命令 | 描述 |
|---|---|
select index |
切换不同的库 (0-15) |
info |
返回当前 redis 服务器状态和一些统计信息 |
monitor |
实时监听并返回 redis 服务器接收到的所有请求信息 |
shutdown |
把数据同步保存到磁盘上,并关闭 redis 服务 |
redis操作键命令表
| 命令 | 描述 |
|---|---|
dbsize |
返回当前数据库的 key 的数量 |
keys * |
查看所有的 key |
exists key |
判断是否存在这个 key |
type key |
查看 key 的类型 |
set key value |
给指定的 key 设置值 |
get key |
获取指定 key 的值 |
expire key 5 |
为指定的 key 设置过期时间 |
ttl key |
查看指定的 key 还有多少时间过期(-1:表示永不过期;-2:表示已经过期) |
flushdb |
清空当前库 |
flushall |
清空所有库 |
3.数据类型
1.string
string是redis 最基本的数据类型。一个key对应一个value。redis的string可以表示任何数据,比如jpg图像或者序列化的对象,string的最大值能存储512MB
存储的数据:单个数据,最简单的数据存储类型
存储数据的格式:一个存储空间保存一个数据
存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用
bash
set name zhangsan
set age 21
get name2.list
redis的列表允许用户从系列的两端推入或者弹出元素列表由多个字符串值组成的有序可重复的系列,是链表结构
bash
lpush names zhangsan # 从列表左边推入元素
rpush names lisi # 从列表右边推入元素
lpush names zhangsan # 可存入相同的元素
lpop names # 从左边弹出元素
lrange name 0 -1 # 查看列表里面所有的元素3.set
Redis的Set是String类型的无序集合,集合成员是唯一的,这意味着集合中不能出现重复的数据
bash
sadd language java
sadd language php
smembers languge| 命令 | 作用 | 例子 |
|---|---|---|
SREM 键名 元素1 元素2... |
删除指定的元素 | SREM tags 篮球 足球 → 删掉集合里的 "篮球" 和 "足球" |
SPOP 键名 |
随机弹出(删除)1 个元素 | SPOP tags → 随机删掉集合里的一个元素(适合抽奖) |
4.Hash
Redis hash是一个String类型的field()字段)和value(值)的映射表,hash特别适合用于存储对象
bash
hset order-11 product matex
hset order-11 price 999
hget order-11 price| 命令 | 作用 | 例子 |
|---|---|---|
HDEL 键名 字段1 字段2... |
删除指定的字段 | HDEL student age sex → 删掉 student 对象里的 "age" 和 "sex" 字段,保留 id、name |
5.ZSet
redis 有序集合和集合一样也是 string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序
bash
zadd readlist 100 hehe
zadd readlist 101 haha
Zrange readlist 0 -1 withscores| 命令 | 作用 | 例子 |
|---|---|---|
zrem 键名 元素1 元素2... |
删除指定的元素 | ZREM game:rank zhangsan lisi → 删掉排行榜里的 "zhangsan" 和 "lisi" |
zremrangebyscore 键名 最小分数 最大分数 |
按分数范围删除 | ZREMRANGEBYSCORE game:rank 0 900 → 删掉分数在 0-900 之间的所有元素 |
zremrangebyrank 键名 起始排名 结束排名 |
按排名范围删除(从 0 开始) | ZREMRANGEBYRANK game:rank 0 2 → 删掉排名倒数前 3 的元素 |
查询键值的数据类型
bash
type 键值4.redis持久化
1.概述
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。redis提供两种方式进行持久化,一种是RDB持久化(原理是将Redis在内存中的数据库记录定时 dump到磁盘上的RDB持久化),另外一种是AOF(append only file)持久化(原理是将Redis的操作日志以追加的方式写入文件
RDB:在指定的时间间隔能对你的数据进行快照存储。(默认开启)
AOF:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据。(默认关闭)
2.rdb快照
1.概述
bin目录下有一个rdb文件里面就是redis数据备份文件,也叫redis数据快照,就是将所有数据都记录到磁盘中,当redis示例故障重启后,从磁盘中读取快照命令,恢复数据
2.执行命令时机
执行save命令-立即执行一次快照,redis使用过程中禁用
bash
save # save命令会导致主进程阻塞,只有数据迁移时候可能用到执行bgsave命令
异步执行RDB:bgsave,后台单开一个进程执行,保证业务不会中断
bash
bgsave # 这个命令执行会开启地理进程完成RDB,主线程可以持续处理用户请求,不收影响执行shutdown命令
bash
./shutdown # 关闭redis进程正常关闭redis,会自动缓存一次Redi数据,但是杀死进程kill则不会保存数据
redis内部有触发RDB的机制可以在redis.cong文件中
# 900秒内,如果至少有1个key被修改,则执行bgsave,如果是save""则表示禁用RDB
save 900 1
save 3000 10
save 60 10000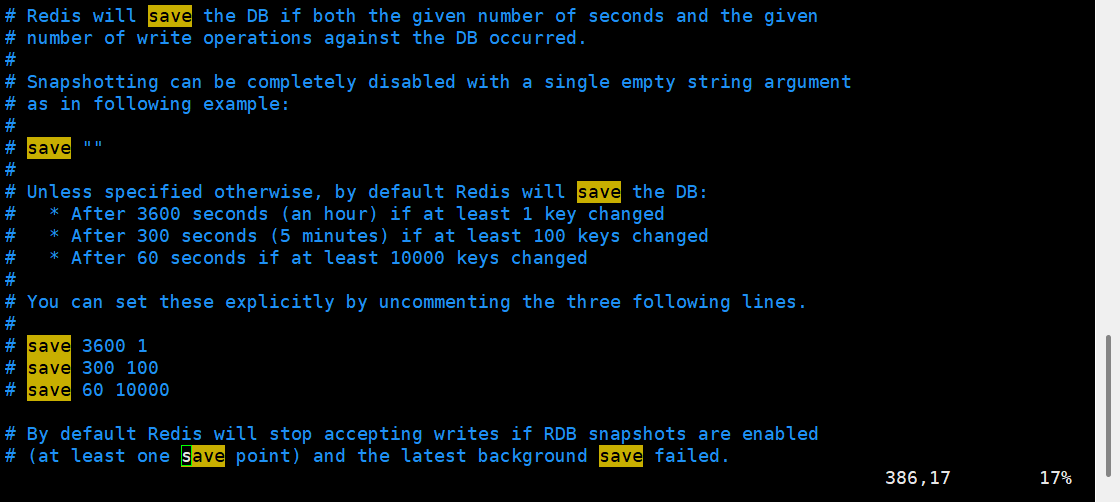
3.机制原理
fork主进程得到一个子进程,共享内存空间(fork采用的是copy-on-write技术(写时复制))
子进程读取复制出来的内存数据并写入新的RDB文件
用新RDB文件替换旧的RDB文件
4.优点与缺点
优点
方便备份与恢复:整个Redis数据库将只包含一个文件,默认是dump.rdb,这对于文件备份和恢复而言是非常完美的。因为我们可以非常轻松的将-个单独的文件压缩后再转移到其它存储介质上。一旦系统出现灾难性故障,我们可以非常容易的进行恢复
性能最大化:对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是分叉出子进程,由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了
启动效率更高:相比于AOF机制,如果数据集很大,RDB的启动效率会更高
缺点
不能完全避免数据丢失:因为RDB是每隔一段时间写入数据,所以系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失
会导致服务器暂停的现象:由于RDB是通过子进程来协助完成数据持久化工作的,因此当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。一般在夜深人静的时候持久化会比较好
3.aof持久化
1.概述
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
在重写的过程中,由于redis还会有新的写入,为了避免数据丢失,会开辟一块内存用于存放重写期间产生的写入操作,等到重写完会将这块内存中的操作再追加到aof文件中
2.执行的时机
aof默认是关闭的,需要修改redis.conf文件来开启aof
#是否开启AOF功能,默认是no
# 1251 行
appendon1y yes
# AOF文件的名称
appendfilename "appendonly.aof"aof命令记录的频率也可以通过redis.conf文件来配置,appendfsync everysec 它其实有三种模式
#表示每执行一次写命令,立即记录到AOF文件
appendfsync always
#写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到A0F文件,是默认方案
appendfsync everysec
#写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no3.机制原理
因为是记录命令,AOF文件会比RDB文件大的多。而且AOE会记录对同一个kev的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb上述AOF重写都是自动触发,通过bgrewriteaof 手动触发aof重写操作。注意:从 Redis 2.4开始, AOF 重写由 Redis 自行触发BGREWRITEAOF 仅仅用于手动触发重写操作
127.0.0.1:6379> bgrewriteaof4.RDB和AOF的区别
1.优点
更加安全,最多损失1秒的数据
2.缺点
AOF 文件比 RDB 更大:对于相同数量的数据集而言,AOF 文件通常要大于 RDB 文件
AOF 运行效率比 RDB 更慢:根据同步策略的不同,AOF 在运行效率上往往会慢于 RDB
3.两者之间的区别
| 对比 | RDB | AOF |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 两次备份之前会可能有数据丢失,不完整 | 相对完整,取决于刷盘策略 |
| 文件大小 | 备份文件会进行压缩,二进制存储,体积小 | 日志文件,记录执行命令,文件大 |
| 宕机恢复 | 快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如 AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量 CPU 和内存消耗 | 低;主要是磁盘 io 操作,但 aof 重写会占用大量 cpu 与内存资源 |
| 应用场景 | 能容忍部分数据丢失,主球更快启动速度 | 数据安全性高的场景使用 |
5.redis主从复制
1.概述
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点
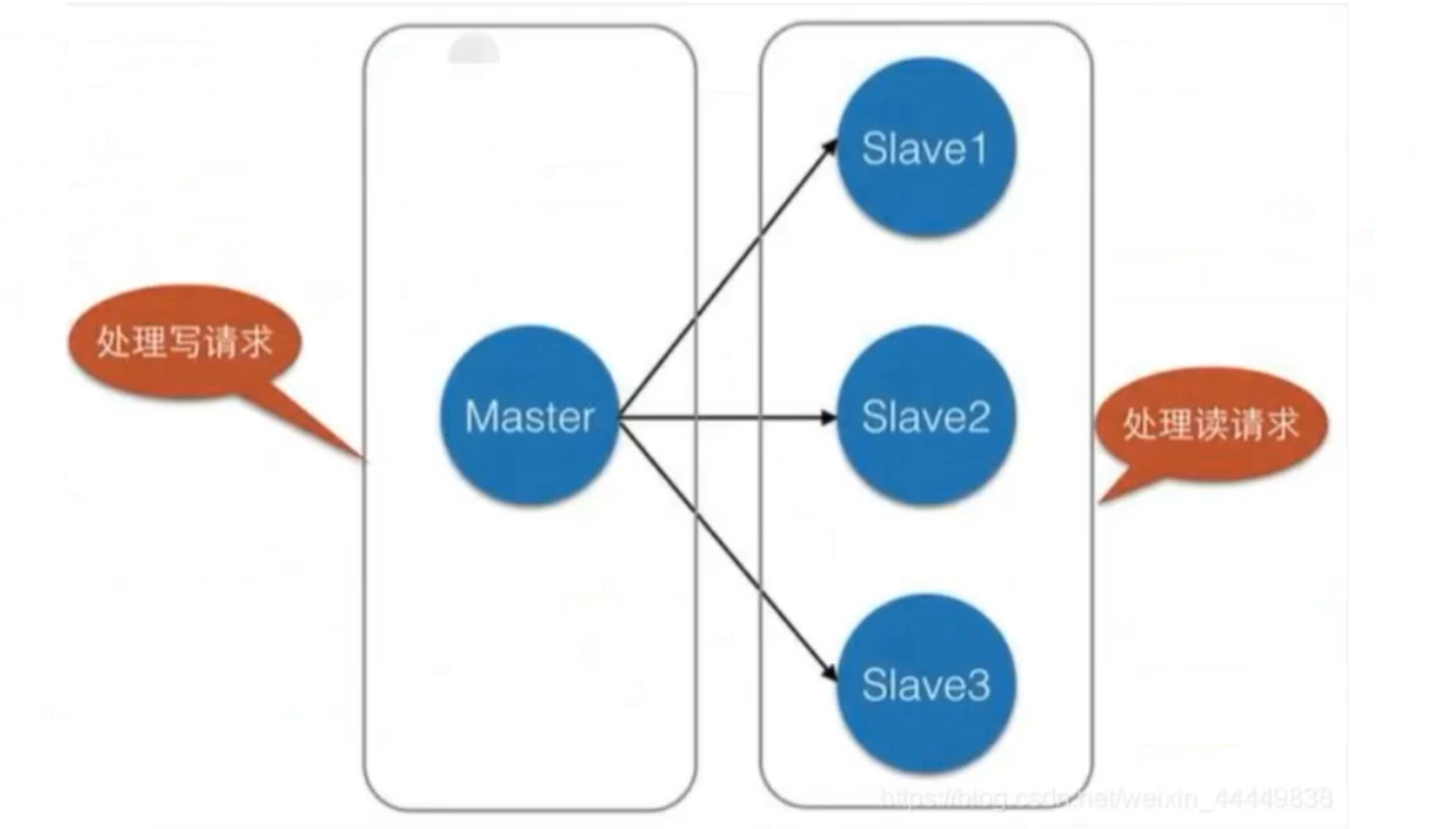
2.主从复制的作用
数据冗余主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
故障恢复当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余负载均衡 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载:尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量
读写分离 可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量
高可用基石 除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础
3.准备示例和配置文件
同一台虚拟机开启三个示例,准备不同的配置文件,在一台主机里面开启三个redis,在同一台虚拟机里面开启redis主从复制需要关闭aof
将appendonly修改为no
1.复制配置文件
mkdir 6379 6380 6381
cp redis.conf 6379/redis-6379.conf
cp redis.conf 6380/redis-6380.conf
cp redis.conf 6381/redis-6381.conf2.修改配置文件
6379.conf
#进程文件
pidfile /var/run/redis_6379.pid
#rdb方式备份的数据文件
dbfilename dump-6379.rdb
#一个主机如果有多个ip,指定Redis绑定哪个IP
replica-announce-ip 192.168.217.1516380.conf
port 6380
#进程文件
pidfile /var/run/redis_6380.pid
#rdb方式备份的数据文件
dbfilename dump-6380.rdb
#一个主机如果有多个ip,指定Redis绑定哪个IP
replica-announce-ip 192.168.217.1516381.conf
port 6381
#进程文件
pidfile /var/run/redis_6381.pid
#rdb方式备份的数据文件
dbfilename dump-6381.rdb
#一个主机如果有多个ip,指定Redis绑定哪个IP
replica-announce-ip 192.168.217.1513.启动服务
以配置文件启动服务
redis-server /usr/local/redis-6.2.6/6379/redis-6379.conf
进入客户端
cd /usr/local/bin
redis-cli -p 6379
redis-cli -p 6380
redis-cli -p 63814.开启主从复制
现在三个实例还没有任何关系,要配置主从可以使用replicaof或者slaveof(5.0以前)命令
有临时和永久两种模式:
修改配置文件(永久生效)
在redis.conf中添加一行配置:slaveof <masterip><masterport>
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>
在没有创建主从关系的情况下所有redis都是主机机
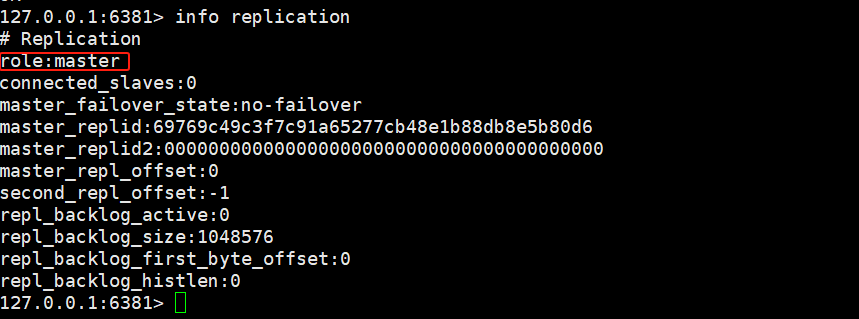
临时生效主从复制
slaveof 192.168.22.145 6379将6379端口的redis当做主机,其余两台机当做从机,其余两台机执行上述命令之后再次查看信息
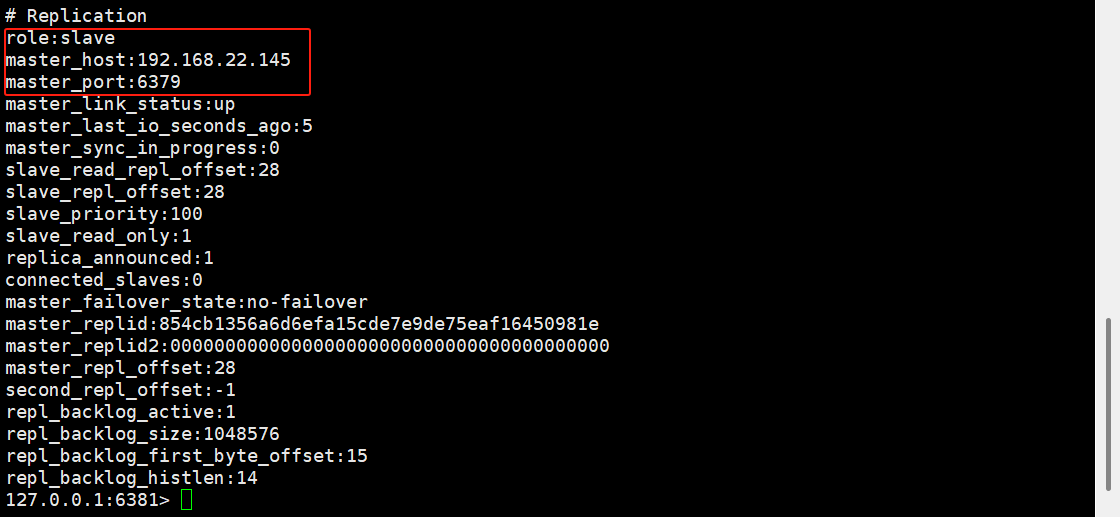
此时两台6380和6381的主机变成了从机,此时主机执行操作会同步到从机,且从机的数据会同步为主机的数据
5.原理
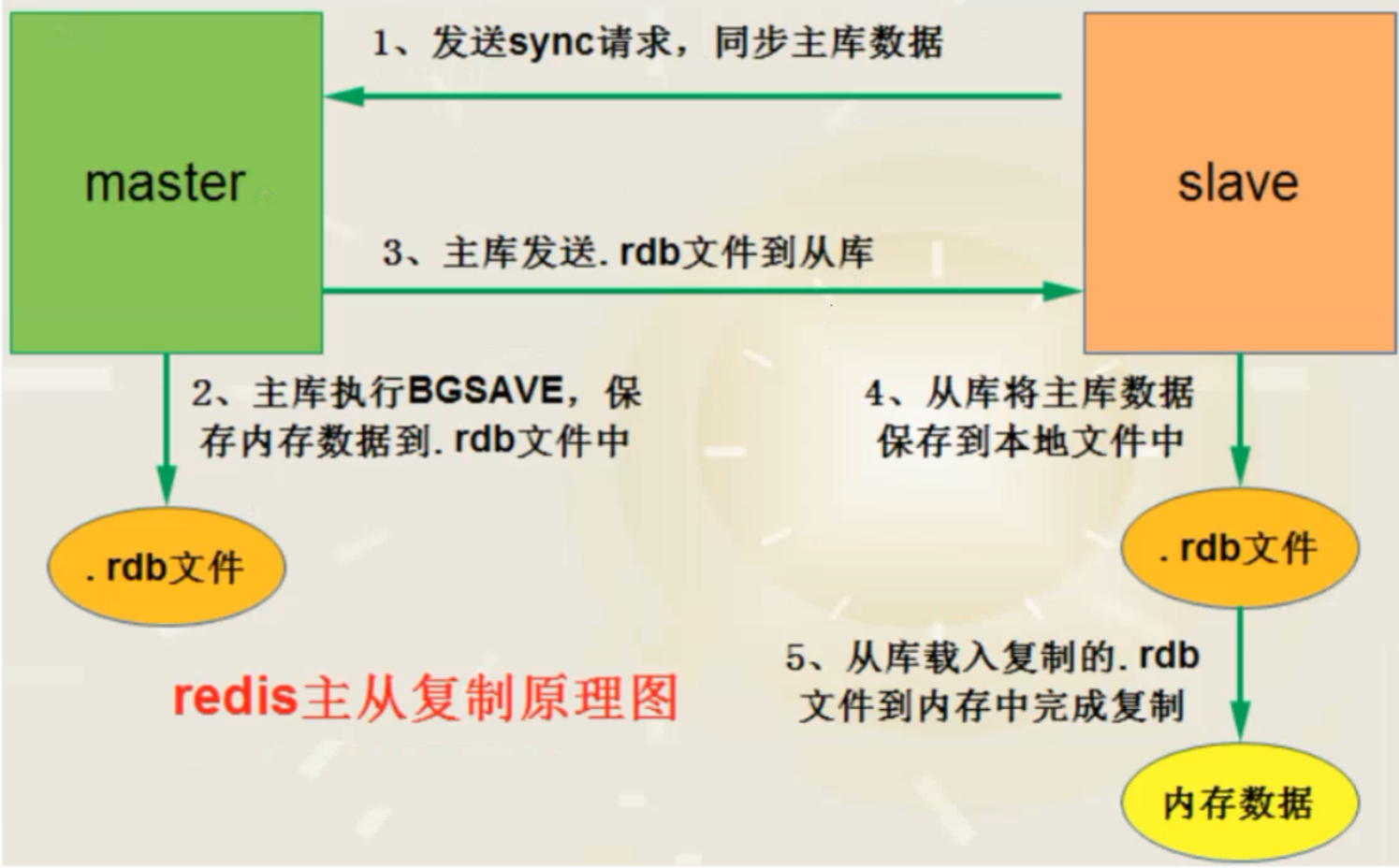
这里有一个问题,master如何得知salve是第一次来连接呢??
有几个概念,可以作为判断依据:
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的ofset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。因此slave做数据同步、必须向master声明自己的replicationid和ofset、master才可以判断到底需要同步哪些数据,因为slave原本出是一个master,有自己的replid和ofset,当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset.
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。