摘要(Summary) :本文讨论智能体在生产环境中的资源感知优化 :在单次请求生命周期内把预算、延迟、配额与任务难度 纳入显式 State ,通过 LangGraph 的节点、条件边与受控循环 实现在线选档、取证伸缩、有界升档与可观测降级。前半部分厘清概念边界与典型策略模式(分层路由、升档 cap、fallback、上下文塑形等);后半部分以 demo_codes 中 SRE 事件分诊 为例,对照 OpenAIResourceLLM (真实调用)下的 resource_aware_graph.py 拓扑、route_after_critic 路由及 verbose/audit 可观测性,并说明与 pytest 测试替身 的关系。
关键词(Keywords):LangGraph;资源感知优化;SRE 分诊;预算与 spend;模型档位(flash / balanced / heavy);条件边;升档上限;优雅降级;OpenAI 兼容 API;ChatOpenAI;可观测性;Policy as code
demo链接:LangGraph 25. 实战:Agent资源优化怎么做案例代码
1. 问题:为什么智能体需要"省着用算力"
想象医院的分诊台:同样是"不舒服",急诊要最快稳住生命体征,门诊可以慢慢排队做精细检查。资源不是无限的 ,关键不是"会不会治",而是"在单位资源内治到什么程度、何时该升级手段"。
智能体在生产环境里的处境类似:算力、第三方 API、响应时间、预算 都是硬约束。如果每个步骤都用最贵、最慢的模型,小实验里可能显得"更聪明",但规模化服务时既不经济也不可靠------账单会爆炸,尾延迟 和供应商限流还会把系统拖垮。
所以我们需要一种机制:让每个决策点都能回答两个问题------
- "这一步值得付出多少?"
- "扣掉这一步的消耗,剩下的预算还够不够走完后面必须的步骤?"
这就是资源感知优化要做的事。
实际例子 :同一条用户工单,低严重度 可能只需要一句话建议;P1 事故 则需要全量取证、发布关联与可审计的根因分析。两条路径在 token、工具 QPS、人工审核上的消耗可能差一个数量级,用同一张"全顶配"流水线硬跑是典型的浪费。
2. 什么是资源感知优化
2.1 一句话定义
资源感知优化 = 智能体在单次请求的生命周期内,持续读取两类信号:
- 资源存量:还剩多少预算、多少时间、多少配额
- 任务难度:严重度、所需工具深度、不确定性
然后在线选择 最合适的动作和实现路径(用哪个模型、检索多少上下文、要不要重试),在给定约束下让质量尽可能好,越界时能优雅降级,而不是默默失败。
核心理解 :这不是"写完 prompt 就算优化",而是闭环控制 ------每走一步都会改变剩余资源,下一步的策略必须基于更新后的状态。
2.2 资源有哪些维度?
实际做产品时要分开考虑这几类,它们不能简单互相换算:
| 维度 | 你在产品上"看见"什么 | 常见应对手段 |
|---|---|---|
| 经济成本 | 这次请求花了多少钱、调外部接口要不要钱 | 简单活给小模型、长文章先缩成摘要 再喂模型、同样问题别重复call模型 |
| 时间 / 用户等待 | 大多数人多快拿到结果、最慢的人要等多久、排队有多长 | 非关键步骤能砍就砍 、先返回短答案 再在后台补全、太慢的步骤异步处理 |
| 机器算力 | 显卡还有余量吗、显存快满了吗、同时能接多少并发 | 排队限流 、任务拆开跑、让模型少写点字 、上下文别一股脑全塞 |
| 外部接口稳定性 | 大模型或第三方 API 是不是总限流/报错、有没有备用线路 | 主线路挂了换备用 、失败太多就先停一会 、必要时换供应商或换模型 |
| 数据量与合规 | 一次要拉多长的日志、有没有敏感字段不能碰 | 先少拉一点看清轮廓 ,再决定要不要全量;取证像漏斗:摘要 → 抽样 → 全量 |
| 组织与人 | 人还能接多少活、哪些事必须有人点头 | 便宜路径自动跑 ;一碰高风险/高花费 就暂停等人确认 |
关键认知 :"省钱"和"省时间"经常打架 ------小模型单次更快,但有时要多轮改稿,总时间反而更长。资源感知优化谈的是好几件事同时卡着你时怎么取舍。
3. 概念边界:别和这些东西混为一谈
3.1 任务规划 vs 资源感知优化
任务规划 解决的是分解与排序:先做 A,再做 B,子任务之间的依赖关系是什么。输出是「离散控制流」。
资源感知优化 在此基础上进一步解决实现档位的选择 :在已确定的控制流上,每一步选用什么成本---能力档位的推理与工具配置。例如轻量模型完成起草、重量级模型仅在质检未通过时介入。
二者互补而非互斥 :仅有规划而无可量化的资源状态(预算、已消耗、剩余时延等),系统仍可能在某一节点把配额用光。
实例:旅行助手把「交通查询 / 住宿查询 / 行程编排」拆为子任务属于规划;针对「仅状态查询类问题走轻模型、冲突消解走强模型」属于资源感知优化。
3.2 静态路由 vs 动态资源感知
静态路由 在部署阶段就预先绑定策略(例如按租户 SKU 固定到某一模型族),运行期不随单次请求内部状态变化。
动态资源感知 则要求策略是状态依赖的 :在同一会话或单次请求内,随着累计消耗增加、截止时间临近、外部错误率上升等信号变化,后续节点应选择更保守或更经济的实现路径。
静态策略回答"默认走哪条路";动态策略回答"在当前剩余资源下 是否仍应走原路"。工程上常将粗粒度静态路由 与细粒度动态决策分层叠加。
3.3 缓存、RAG 与压缩
这些技术与「资源感知」是正交的,解决的是不同层面的问题:
- 缓存 :降低重复计算与重复检索的成本,并不自动约束"首次路径"上的模型与工具用量。
- RAG :提供可验证证据来源 ,但若缺少检索条数 / token 上限 / 相关性阈值 等约束,易出现context 膨胀,反而拉高延迟与计费。
- 压缩与摘要 :以信息损失 换取更低的上下文体积与推理成本 ;在高严重度场景下,需显式评估摘要层级的风险可接受边界。
资源感知层应在 State 中显式纳入 这些子系统的「预算与质量」假设,并在条件边中体现截断、降级、二次检索等分支。
3.4 水平扩展 vs 单请求内优化
水平扩展 (加副本、分片)缓解的是系统级吞吐与饱和 ;本文聚焦单请求内部的资源分配与策略 :在已分配到的算力份额内,如何分配模型档位、工具深度与重试预算。
两者关系是互补的 :容量不足会导致排队与超时;若单请求路径缺乏资源意识,则扩容往往线性放大无效消耗。
4. 典型策略模式(由简到繁)
工业界常见做法多为下列模式的组合,可在 LangGraph 中映射为节点、条件边与 State 字段。
4.1 分层路由(Tiered Routing)
核心思想 :先用较低成本完成路径判别 (规则引擎、轻量分类模型或小规模 LLM 调用),只在必要时升级到高能力模型。判别自身的延迟与 token 成本应显著低于下游的重推理步骤。
设计要点 :明确特征空间 (文本长度、意图、严重度标签、用户层级)、路由器的 SLA ,以及对误路由的纠错机制(例如二次判别或用户回退)。
LangGraph 示例:客服查询分层路由
场景:用户进入客服系统,先由轻量路由节点判断查询复杂度,再决定走向哪条处理链路。
输出层
处理链路
路由层(轻量判别)
输入层
简单查询
复杂查询
不确定(低置信)
用户查询
router_node
小模型 / 规则引擎
职责:判断查询复杂度
simple_handler
轻量模型
查物流/看订单/FAQ
complex_handler
旗舰模型
退款纠纷/技术排错/多轮推理
返回响应
伪代码示意:
python
# === State 定义 ===
class QueryState(TypedDict):
user_query: str
complexity_score: float # 路由节点输出:0~1,越接近1越复杂
route_to: Literal["simple", "complex"]
response: str
# === 路由节点:轻量判别 ===
def router_node(state: QueryState) -> QueryState:
"""
使用小模型(如 gemini-2.5-flash)或规则引擎,
快速判断查询复杂度,输出 complexity_score 和 route_to。
"""
query = state["user_query"]
# 方案 A:规则快速筛选明显简单的查询
if len(query) < 20 and any(k in query for k in ["物流", "订单号", "多少钱"]):
return {**state, "complexity_score": 0.1, "route_to": "simple"}
# 方案 B:小模型做语义判别(带结构化输出约束)
result = mini_llm.classify(
query,
prompt="判断查询复杂度:简单查询(查状态/FAQ)vs 复杂查询(纠纷/技术/多步推理)",
response_format={"complexity_score": "float 0~1", "reason": "str"}
)
# 阈值策略:>0.6 视为复杂,不确定时保守地走复杂链路
route = "complex" if result["complexity_score"] > 0.6 else "simple"
return {
**state,
"complexity_score": result["complexity_score"],
"route_to": route
}
# === 路由函数:根据 route_to 字段分流 ===
def route_decision(state: QueryState) -> Literal["simple_handler", "complex_handler"]:
return "simple_handler" if state["route_to"] == "simple" else "complex_handler"
# === 简单链路:轻量模型快速响应 ===
def simple_handler(state: QueryState) -> QueryState:
"""使用轻量模型(如 gpt-4o-mini),低成本快速响应。"""
resp = mini_model.chat(
system="你是客服助手,用简洁语言回答物流/订单类问题。",
user=state["user_query"]
)
return {**state, "response": resp}
# === 复杂链路:旗舰模型深度处理 ===
def complex_handler(state: QueryState) -> QueryState:
"""使用旗舰模型(如 gpt-4o/Claude),处理需要推理的复杂场景。"""
resp = flagship_model.chat(
system="你是高级客服专家,处理退款纠纷、技术排错等复杂问题...",
user=state["user_query"],
tools=[refund_policy_tool, tech_diagnose_tool] # 复杂链路挂载工具
)
return {**state, "response": resp}
# === 图构建 ===
graph = StateGraph(QueryState)
graph.add_node("router", router_node)
graph.add_node("simple_handler", simple_handler)
graph.add_node("complex_handler", complex_handler)
graph.add_edge(START, "router")
graph.add_conditional_edges("router", route_decision, {
"simple_handler": "simple_handler",
"complex_handler": "complex_handler"
})
graph.add_edge("simple_handler", END)
graph.add_edge("complex_handler", END)
app = graph.compile()关键设计细节:
| 设计点 | 说明 |
|---|---|
| 路由成本占比 | 小模型路由节点的 token 消耗应 < 总成本的 5%,否则出现"路由比业务还贵"的倒挂 |
| 阈值策略 | complexity_score 处于模糊区间(如 0.4~0.7)时,保守地走向复杂链路,避免误伤 |
| 误路由回退 | 简单链路发现无法处理时(如触发"未知意图"信号),可重新路由到复杂链路 |
| 观测埋点 | 记录每个请求的 complexity_score 和实际走的链路,用于后续校准阈值 |
4.2 有上界的升档(Escalation with Cap)
核心思想 :当质检(人工规则、小型评估模型或结构化 critic)判定输出不满足深度、证据或格式要求 时,允许在有限次数 内提升实现档位并重新生成,同时累计经济与时间成本。
设计要点 :必须为最大升档轮数 、单次/累计费用上限 与截止时间 同时设界,以保证终止性 与最坏情况可预期,避免在边界输入上出现无界重试。
本仓库示例中以 escalation_round 与 spend 相对 budget_cap 体现这一约束。
LangGraph 示例:带上限的文档质检升档
场景:AI 助手生成技术文档,质检不通过时可升级模型档位重试,但有明确的轮次上限 和预算上限。
出口
生成-质检循环(最多3轮)
初始化
verdict=accept
verdict=escalate
且 round<2
且 budget够
verdict=escalate
但 round≥2 或 budget不够
State
escalation_round=0
spend=0
budget_cap=100
draft_node
按当前档位生成文档
critic_node
质检评估
输出 verdict
route_after_critic
条件路由
escalate_node
round += 1
升级档位
finalize
输出最终文档
degrade_finalize
标注降级原因
需人工复核
伪代码示意:
python
# === State 定义 ===
class DocGenState(TypedDict):
user_request: str
draft: str
tier: Literal["fast", "standard", "premium"] # 三档模型
escalation_round: int # 当前升档轮次(0,1,2)
budget_cap: int # 预算上限(抽象算力单元)
spend: int # 已消耗
critic_verdict: dict # 质检结果
degraded: bool # 是否降级终态
# === 档位成本表 ===
COST_TIER = {"fast": 10, "standard": 25, "premium": 60}
MAX_ESCALATION = 2 # 最多升2次,共3轮
# === 生成节点:按当前档位生成,预算不足时强制降级 ===
def draft_node(state: DocGenState) -> DocGenState:
"""
根据 escalation_round 选择档位:
round=0 → fast, round=1 → standard, round=2 → premium
"""
tier_order = ["fast", "standard", "premium"]
tier = tier_order[min(state["escalation_round"], 2)]
# 预算检查:如果当前档位超预算,强制用最低档
if state["spend"] + COST_TIER[tier] > state["budget_cap"]:
tier = "fast"
log("[policy] 预算不足,强制降级到 fast")
# 调用对应模型生成文档
draft = llm_generate(
model=tier,
prompt=state["user_request"],
system="生成技术文档,要求包含:概述、步骤、注意事项"
)
return {
**state,
"draft": draft,
"tier": tier,
"spend": state["spend"] + COST_TIER[tier]
}
# === 质检节点:评估文档质量 ===
def critic_node(state: DocGenState) -> DocGenState:
"""
用小模型或规则检查文档是否达标。
返回 verdict: "accept" | "escalate"
"""
draft = state["draft"]
# 检查项:长度、结构完整性、关键要素
checks = {
"has_overview": "概述" in draft or "简介" in draft,
"has_steps": len([l for l in draft.split("\n") if l.strip().startswith(("1.", "2.", "-"))]) >= 3,
"long_enough": len(draft) > 500,
}
if all(checks.values()):
verdict = {"verdict": "accept", "reason": "结构完整"}
else:
missing = [k for k, v in checks.items() if not v]
verdict = {"verdict": "escalate", "reason": f"缺少: {missing}"}
return {**state, "critic_verdict": verdict}
# === 条件路由:决定下一步走向 ===
def route_after_critic(state: DocGenState) -> Literal["finalize", "escalate", "degrade_finalize"]:
verdict = state["critic_verdict"].get("verdict")
current_round = state["escalation_round"]
spend = state["spend"]
cap = state["budget_cap"]
# 情况1:质检通过 → 直接输出
if verdict == "accept":
return "finalize"
# 情况2:质检不通过,但还能升档(有预算、有轮次)
if verdict == "escalate":
# 检查轮次上限
if current_round >= MAX_ESCALATION:
log(f"[cap] 已达最大升档轮次 ({MAX_ESCALATION}),停止升档")
return "degrade_finalize"
# 检查预算是否够下一次升档
next_tier_cost = COST_TIER[["fast", "standard", "premium"][min(current_round + 1, 2)]]
if spend + next_tier_cost > cap:
log(f"[cap] 预算不足以支撑下一轮 (需{next_tier_cost}, 剩{cap-spend})")
return "degrade_finalize"
# 可以继续升档
return "escalate"
return "finalize"
# === 升档节点:仅增加轮次计数 ===
def escalate_node(state: DocGenState) -> DocGenState:
"""纯状态变更:轮次+1,下一跳回到 draft_node 用更高档位重试。"""
new_round = state["escalation_round"] + 1
log(f"[escalate] 升档至 round={new_round}")
return {**state, "escalation_round": new_round}
# === 降级收口:标注降级原因 ===
def degrade_finalize_node(state: DocGenState) -> DocGenState:
"""预算或轮次触顶,标注降级终态。"""
note = "\n\n[系统备注] 文档生成已达资源上限,当前输出为尽力结果,建议人工复核。"
return {
**state,
"draft": state["draft"] + note,
"degraded": True
}
# === 正常收口 ===
def finalize_node(state: DocGenState) -> DocGenState:
return state
# === 图构建 ===
graph = StateGraph(DocGenState)
graph.add_node("draft", draft_node)
graph.add_node("critic", critic_node)
graph.add_node("escalate", escalate_node)
graph.add_node("degrade_finalize", degrade_finalize_node)
graph.add_node("finalize", finalize_node)
# 边:包含一个受控循环
graph.add_edge(START, "draft")
graph.add_edge("draft", "critic")
graph.add_conditional_edges("critic", route_after_critic, {
"finalize": "finalize",
"escalate": "escalate",
"degrade_finalize": "degrade_finalize"
})
graph.add_edge("escalate", "draft") # 循环回生成节点
graph.add_edge("degrade_finalize", "finalize")
graph.add_edge("finalize", END)
app = graph.compile()关键控制逻辑:
| 约束类型 | 实现位置 | 触发条件 |
|---|---|---|
| 轮次上限 | route_after_critic |
escalation_round >= 2 时强制走向 degrade_finalize |
| 预算上限 | route_after_critic |
剩余预算不足以支付下一轮生成时走向降级 |
| 单次预算钳制 | draft_node |
即使路由决定用高档,若超预算也强制降档 |
| 可观测性 | degrade_finalize_node |
降级终态显式标注,便于后续人工介入 |
运行示例:
- 低成本成功路径:fast档生成 → critic通过 → finalize(总消耗10)
- 一次升档成功:fast档生成 → critic不通过 → escalate → standard档重试 → critic通过 → finalize(总消耗35)
- 预算触顶降级:前两轮消耗70,第三轮需premium(60)但只剩30 → degrade_finalize(总消耗70,标注降级)
4.3 降级链路与故障隔离(Fallback Chain)
核心思想 :当首选模型或依赖服务因限流、内容策略、区域性故障、超时 等不可用时,按预定顺序尝试次优但可用 的实现,并在审计日志中记录实际生效路径。
设计要点 :与「静默替换」相对,生产系统需要可观测的降级事件 以支持计费归因、告警与事后分析;在高错误率场景下应配合断路或退避 策略,防止对下游造成重试风暴。
LangGraph 示例:主备模型自动切换(带熔断)
场景:代码审查助手,首选 GPT-4 进行深度分析,当主模型限流/超时时自动降级到 Claude,并记录降级事件;如果连续失败则触发熔断,暂停调用一段时间。
结果处理
调用尝试层
输入
CLOSED/半开
OPEN
成功
429/超时
抛异常
成功
仍失败
待审查代码片段
circuit_breaker
熔断器检查
try_primary
调用 GPT-4
try_fallback
调用 Claude
record_fallback
记录降级事件
返回审查结果
记录失败
抛出异常
伪代码示意:
python
# === State 定义 ===
class CodeReviewState(TypedDict):
code_snippet: str
language: str
review_result: str
used_fallback: bool # 是否走了备用链路
fallback_reason: str # 降级原因(429 / timeout / error)
circuit_status: Literal["CLOSED", "OPEN", "HALF_OPEN"] # 熔断状态
failure_count: int # 连续失败计数
last_failure_time: float # 上次失败时间戳
audit_log: list[str] # 审计日志
# === 熔断器配置 ===
CIRCUIT_THRESHOLD = 5 # 连续失败5次触发熔断
CIRCUIT_TIMEOUT = 60 # 熔断后60秒才允许试主链路
FALLBACK_MODEL = "claude-3-sonnet"
PRIMARY_MODEL = "gpt-4"
# === 熔断器检查节点 ===
def circuit_breaker_node(state: CodeReviewState) -> CodeReviewState:
"""
检查熔断器状态:
- CLOSED:正常,走主链路
- OPEN:熔断中,直接走备用链路
- HALF_OPEN:过了冷却期,允许试一次主链路
"""
now = time.time()
status = state.get("circuit_status", "CLOSED")
last_fail = state.get("last_failure_time", 0)
# 熔断冷却期检查
if status == "OPEN" and (now - last_fail) > CIRCUIT_TIMEOUT:
status = "HALF_OPEN"
log("[circuit] 熔断冷却结束,进入半开状态,允许试主链路")
return {**state, "circuit_status": status}
# === 路由:根据熔断状态决定走向 ===
def route_by_circuit(state: CodeReviewState) -> Literal["try_primary", "try_fallback"]:
if state["circuit_status"] == "OPEN":
return "try_fallback"
return "try_primary" # CLOSED 或 HALF_OPEN 都尝试主链路
# === 主链路节点:调用首选模型 ===
def try_primary_node(state: CodeReviewState) -> CodeReviewState:
"""调用 GPT-4,捕获限流/超时异常。"""
try:
result = call_llm(
model=PRIMARY_MODEL,
prompt=build_review_prompt(state["code_snippet"], state["language"]),
timeout=10
)
# 成功:重置失败计数
return {
**state,
"review_result": result,
"used_fallback": False,
"failure_count": 0,
"circuit_status": "CLOSED" # 半开状态下成功,关闭熔断
}
except RateLimitError as e:
log(f"[primary] 限流: {e}")
raise NodeInterrupt("fallback_needed") # 触发跳转到备用链路
except TimeoutError as e:
log(f"[primary] 超时: {e}")
raise NodeInterrupt("fallback_needed")
# === 备用链路节点:调用次选模型 ===
def try_fallback_node(state: CodeReviewState) -> CodeReviewState:
"""调用 Claude,同时更新熔断器计数。"""
try:
result = call_llm(
model=FALLBACK_MODEL,
prompt=build_review_prompt(state["code_snippet"], state["language"]),
timeout=15 # 备用链路给更长的超时
)
# 记录降级事件到审计日志
reason = "主链路限流/超时" if not state.get("used_fallback") else "未知"
audit_entry = f"{time.strftime('%H:%M:%S')} | FALLBACK | {reason} | {FALLBACK_MODEL}"
return {
**state,
"review_result": result,
"used_fallback": True,
"fallback_reason": reason,
"audit_log": [*state.get("audit_log", []), audit_entry]
}
except Exception as e:
# 备用也失败:更新熔断器状态
new_count = state.get("failure_count", 0) + 1
new_status = "OPEN" if new_count >= CIRCUIT_THRESHOLD else state.get("circuit_status", "CLOSED")
log(f"[fallback] 也失败 ({new_count}/{CIRCUIT_THRESHOLD}), 熔断状态: {new_status}")
return {
**state,
"failure_count": new_count,
"circuit_status": new_status,
"last_failure_time": time.time(),
"audit_log": [*state.get("audit_log", []), f"FAIL | {str(e)[:50]}"]
}
# === 主链路失败后的处理节点 ===
def handle_primary_failure(state: CodeReviewState) -> CodeReviewState:
"""主链路失败,更新失败计数,可能触发熔断。"""
new_count = state.get("failure_count", 0) + 1
new_status = "OPEN" if new_count >= CIRCUIT_THRESHOLD else state.get("circuit_status", "CLOSED")
log(f"[primary_fail] 连续失败 {new_count} 次,熔断状态: {new_status}")
return {
**state,
"failure_count": new_count,
"circuit_status": new_status,
"last_failure_time": time.time()
}
# === 结果收口节点 ===
def finalize_node(state: CodeReviewState) -> CodeReviewState:
"""统一输出,附带审计信息。"""
if state.get("used_fallback"):
log(f"[finalize] 结果来自备用模型 ({state.get('fallback_reason')})")
else:
log("[finalize] 结果来自主模型")
return state
# === 图构建 ===
graph = StateGraph(CodeReviewState)
graph.add_node("circuit_check", circuit_breaker_node)
graph.add_node("try_primary", try_primary_node)
graph.add_node("handle_primary_fail", handle_primary_failure)
graph.add_node("try_fallback", try_fallback_node)
graph.add_node("finalize", finalize_node)
# 主流程
graph.add_edge(START, "circuit_check")
graph.add_conditional_edges("circuit_check", route_by_circuit, {
"try_primary": "try_primary",
"try_fallback": "try_fallback"
})
# 主链路成功/失败处理
try PrimaryTryCatch(
node="try_primary",
on_success="finalize",
on_exception=[
(RateLimitError, "handle_primary_fail"),
(TimeoutError, "handle_primary_fail")
]
)
# 处理完失败后,再尝试备用链路
graph.add_edge("handle_primary_fail", "try_fallback")
# 备用链路结果都走向 finalize(成功或失败都在 audit_log 中)
graph.add_edge("try_fallback", "finalize")
graph.add_edge("finalize", END)
app = graph.compile()降级与熔断策略对照:
| 场景 | 系统行为 | 观测点 |
|---|---|---|
| 主模型偶发限流 | 单请求降级到 Claude,记录 used_fallback=True |
audit_log 中出现 FALLBACK 条目 |
| 主模型连续5次失败 | 熔断器 OPEN,后续请求直接走备用链路60秒 | failure_count 达阈值,circuit_status=OPEN |
| 熔断冷却后试主链路 | HALF_OPEN 状态下允许试一次,成功则关闭熔断 | circuit_status 状态流转日志 |
| 备用也失败 | 记录失败,更新计数,可能加速熔断 | audit_log 中连续出现 FAIL 条目 |
生产建议:
- 异步告警 :当
used_fallback率超过 10% 或circuit_status变为 OPEN 时,触发告警通知运维。 - 分级备用:可以设计多级备用(GPT-4 → Claude → 本地小模型 → 返回"服务暂不可用")。
- 成本对账 :
audit_log中的 FALLBACK 条目可作为成本归因依据(区分主/备用模型的账单)。
4.4 上下文塑形(Context Shaping)
核心思想 :在给定任务风险等级下,主动选择进入模型的证据粒度------从高层摘要、抽样片段到全量原文,而非默认「能拉尽拉」。
设计要点 :将信息预算 (token、带宽、合规审查成本)与错误代价 对齐;示例中的 context_light_mode 表示在预算紧张时收紧取证范围。
LangGraph 示例:日志分析取证漏斗
场景:SRE 助手处理线上故障查询,根据严重度 和预算动态选择日志取证粒度------摘要 → 抽样 → 全量,避免不分青红皂白拉取全部日志撑爆上下文。
分析层
取证执行层(三选一)
塑形决策层
输入层
severity=1
或 budget紧张
severity=2
且 budget充足
severity=3
且 budget充足
故障查询
如:'服务延迟高' / '订单接口报错'
严重度信号
severity: 1/2/3
预算余量
budget_left
context_shape_node
证据粒度决策
fetch_summary
仅拉取统计聚合
~500 tokens
fetch_sample
抽样日志
~2000 tokens
fetch_full
全量原始日志
~10000+ tokens
analyze_node
用选定的证据分析
输出分析结果
伪代码示意:
python
# === State 定义 ===
class LogAnalysisState(TypedDict):
query: str # 用户查询
severity: int # 严重度 1=低 2=中 3=高
time_range: str # 查询时间范围,如 "1h" / "24h"
# 资源与塑形相关
budget_cap: int # 总预算上限
budget_used: int # 已用预算
context_mode: Literal["summary", "sample", "full"] # 当前取证模式
context_tokens: int # 实际拉取的上下文token数
logs_fetched: list[str] # 拉取的日志内容
# 分析结果
analysis_result: str
confidence: float # 分析置信度(受证据完整性影响)
# === 塑形决策节点:选择证据粒度 ===
def context_shape_node(state: LogAnalysisState) -> LogAnalysisState:
"""
根据严重度和预算余量,决定取证粒度。
核心逻辑:高风险/高预算 → 全量;低风险/紧预算 → 摘要。
"""
severity = state["severity"]
budget_left = state["budget_cap"] - state["budget_used"]
# 决策矩阵:严重度 × 预算
if severity >= 3 and budget_left >= 80:
mode = "full"
estimated_tokens = 10000
log("[shape] P1事故,预算充足 → 全量取证")
elif severity >= 2 and budget_left >= 40:
mode = "sample"
estimated_tokens = 2000
log("[shape] P2告警 → 抽样取证(10%采样)")
else:
# severity=1 或预算紧张,用摘要模式
mode = "summary"
estimated_tokens = 500
log(f"[shape] 严重度={severity} 或预算紧张({budget_left} left) → 摘要取证")
return {
**state,
"context_mode": mode,
"estimated_tokens": estimated_tokens
}
# === 条件路由:根据 context_mode 走向不同取证节点 ===
def route_by_shape(state: LogAnalysisState) -> Literal["fetch_summary", "fetch_sample", "fetch_full"]:
return f"fetch_{state['context_mode']}"
# === 取证节点 1:摘要级(轻量)===
def fetch_summary_node(state: LogAnalysisState) -> LogAnalysisState:
"""仅拉取预聚合的统计信息:错误率、QPS、延迟分位数。"""
logs = query_log_aggregation(
query=state["query"],
time_range=state["time_range"],
metrics=["error_rate", "p99_latency", "qps"]
)
# 构造结构化摘要(控制token)
summary_text = format_summary(logs) # 约500 tokens
return {
**state,
"logs_fetched": [summary_text],
"context_tokens": len(summary_text.split()),
"budget_used": state["budget_used"] + 10 # 摘要成本低
}
# === 取证节点 2:抽样级(中等)===
def fetch_sample_node(state: LogAnalysisState) -> LogAnalysisState:
"""拉取抽样日志 + 典型错误样例。"""
# 10% 随机抽样 + 错误日志全取( capped 数量)
logs = query_log_sample(
query=state["query"],
time_range=state["time_range"],
sample_rate=0.1,
max_error_logs=100
)
sample_text = format_logs(logs) # 约2000 tokens
return {
**state,
"logs_fetched": logs,
"context_tokens": len(sample_text.split()),
"budget_used": state["budget_used"] + 40 # 中等成本
}
# === 取证节点 3:全量级(完整)===
def fetch_full_node(state: LogAnalysisState) -> LogAnalysisState:
"""拉取全量日志,用于深度根因分析。"""
logs = query_log_full(
query=state["query"],
time_range=state["time_range"],
include_trace=True, # 包含分布式追踪
include_request_body=True
)
full_text = format_logs(logs) # 可能10000+ tokens
return {
**state,
"logs_fetched": logs,
"context_tokens": len(full_text.split()),
"budget_used": state["budget_used"] + 100 # 高成本
}
# === 汇聚节点:统一处理证据 ===
def analyze_node(state: LogAnalysisState) -> LogAnalysisState:
"""根据取证结果进行分析,标记置信度。"""
mode = state["context_mode"]
evidence = "\n".join(state["logs_fetched"])
# 根据证据完整度调整prompt策略
if mode == "summary":
system = "基于统计摘要进行初步分析。注意:缺少原始日志细节,结论可能存在盲区。"
max_confidence = 0.7 # 摘要模式置信度上限
elif mode == "sample":
system = "基于抽样日志分析。包含典型错误样例,但非全量。"
max_confidence = 0.85
else:
system = "基于全量日志进行深度根因分析。证据完整。"
max_confidence = 0.95
result = llm_analyze(
system=system,
evidence=evidence,
query=state["query"]
)
# 置信度取模型输出与模式上限的较小值
confidence = min(result.get("confidence", 0.8), max_confidence)
return {
**state,
"analysis_result": result["analysis"],
"confidence": confidence
}
# === 图构建 ===
graph = StateGraph(LogAnalysisState)
graph.add_node("shape", context_shape_node)
graph.add_node("fetch_summary", fetch_summary_node)
graph.add_node("fetch_sample", fetch_sample_node)
graph.add_node("fetch_full", fetch_full_node)
graph.add_node("analyze", analyze_node)
# 塑形决策 → 三选一取证
graph.add_edge(START, "shape")
graph.add_conditional_edges("shape", route_by_shape, {
"fetch_summary": "fetch_summary",
"fetch_sample": "fetch_sample",
"fetch_full": "fetch_full"
})
# 三选一汇聚到分析
graph.add_edge("fetch_summary", "analyze")
graph.add_edge("fetch_sample", "analyze")
graph.add_edge("fetch_full", "analyze")
graph.add_edge("analyze", END)
app = graph.compile()塑形策略与风险对位:
| 查询场景 | 严重度 | 取证模式 | 典型token消耗 | 置信度上限 | 适用情况 |
|---|---|---|---|---|---|
| "查看服务状态" | 1 | summary | ~500 | 70% | 快速健康检查 |
| "排查偶发报错" | 2 | sample | ~2000 | 85% | 需要样例但非紧急 |
| "P1事故根因" | 3 | full | ~10000+ | 95% | 必须深度分析 |
| 预算告急时的P2 | 2 | summary | ~500 | 70% | 降级为轻量先止血 |
关键设计细节:
- 风险对冲 :摘要模式的结果自带置信度上限,避免用户把"初步估计"当"确凿结论"。
- 动态降级 :即使严重度高,若预算不足以支撑全量取证,仍退回到抽样或摘要(在
context_shape_node中调整逻辑)。 - 可复现取证 :
fetch_*节点记录查询参数(时间范围、采样率、过滤条件),便于事后审计和重跑。 - 增量展开:可以先走 summary → 若结论不明确(confidence低)→ 用户确认后再触发 sample/full 二次取证(在图中表现为条件循环)。
4.5 多智能体场景下的负载与能力可见性
多个工作智能体并行存在时,编排器若缺乏各节点的当前负载与能力边界 信息,易出现低效分配 (高难度子任务落入高负载节点)。近期研究强调自描述资源与编排器协同分配 对整体效用的改善。参考:Self-Resource Allocation in Multi-Agent LLM Systems, arXiv:2504.02051
5. 为什么 LangGraph 适合承载资源感知策略
LangGraph 把应用建模为基于显式 State 的有向状态机:
- 节点(node):承载 IO、LLM 调用、工具执行等副作用
- 边(edge):规定默认执行顺序
- 条件边(conditional edges):根据 State 当前快照选择下一跳
- State :在节点之间传递,并可对部分字段配置归约器(reducer)
好处 :在同一框架内可同时表达数据面 (累积上下文、审计轨迹)与控制面(预算、分支、重试)。
资源感知策略通常要求「扣费---决策---再扣费」的闭环;LangGraph 的多项工程属性与此结构同构。
5.1 会计一致性(Accounting)
含义 :任意一次执行的资源消耗 必须能挂接到具体节点与路径 ,并与事前预算可对账。
LangGraph 的便利 :将与费用同类的量纲(token、内部算力单元、工具配额等)放入 State,使每个节点的返回可被视为一条会计分录 ;配合顺序追加的 audit 或自定义事件,可在单元测试中断言「从 triage 经 context 至首次 draft 的累计消耗不超过 budget_cap」,在生产侧按节点 ID 做成本分解。
实践注意 :若扣费逻辑散落在闭包、全局变量或未持久化上下文之外,图结构无法自动保证 可审计性;应将估算、实测回写、封顶校验 与节点出口显式绑定。
5.2 策略可执行性(Policy as Code)
含义 :预算、升档上限、超时 fallback、禁止自动改生产等约束必须由代码路径强制执行,不能仅依赖模型在对话中的自我声明。
LangGraph 的便利 :route_after_critic 一类纯函数路由 可将「剩余预算不足以支付下一档 draft」等规则落实为确定性分支 ;LLM 仍可参与软性建议 (例如偏好某条工具链),但与硬壳策略 分离:硬壳负责终止、降级、熔断 ,软壳负责内容生成与措辞。
实践注意 :凡关键约束仅写在 prompt 中而无对应分支测试,应视为不可发布风险。
5.3 控制流可验证性(Reviewability)
含义 :评审者应能通过读图与读路由函数 判断:是否存在无出口循环 、最坏情况下的步数上界、以及退化/收口是否覆盖。
LangGraph 的便利 :draft → critic → escalate → draft 等回路在拓扑上显式可见 ;finalize、degrade_finalize 等收口节点 提供可证明的终止形态 。相较在单体式循环或深层递归中隐式重试,变更审查与蓝绿演练更易定位「是哪条边引入了新规」。
实践注意 :当单条 route_* 函数过长时,应抽取子图 、表驱动阈值或策略对象,避免条件边逻辑退化为不可维护的「第二业务层」。
5.4 业界实践参照与框架边界
将单体巨型 agent 拆为多节点流水线 、为不同节点配置差异化模型与提示 、并叠加分流与缓存 ,在多个公开案例中报告了可观的成本改善;参见 Musaib Altaf, 2026、Gabriel Mendes, Medium。对默认实现中 token 使用存在结构性浪费 的评论见 Gary Botlington, dev.to。
边界声明 :LangGraph不实现 全局最优调度、不内置供应商价目表、也不替代容量规划;它提供的是表达与控制流的首要承载物 。最终是否经济、是否满足 SLA,仍依赖:State 量纲是否完备 、分支是否覆盖预算耗尽/超时/429 等边角 、以及评估是否采用成本---质量联合指标。
6. 常见反模式(设计评审检查项)
以下条目建议在架构评审与上线前 checklist中逐项核对。
6.1 全局共用超重 system prompt
- 表现:所有流量共用同一份极大的 system 指令与安全规约,简单与复杂请求无差别前置。
- 后果 :固定输入成本抬高全体请求的基线;轻量意图无法摊销 prompt 开销。
- 改进 :按入口 SKU / 意图档 拆分 system 片段;公共合规与领域专规 分层注入;低风险路径采用短规约 + 后置抽检。
6.2 高成本模型承担路由判别
- 表现 :意图分类、严重度、是否检索等「一步定型」与最终生成共用旗舰模型。
- 后果 :路由步的延迟与单价 与主推理同阶,出现成本结构倒置。
- 改进 :路由优先规则 / 轻量分类器 / 小模型 ;为路由调用设严格 max_tokens 与超时 ;监控路由成本占总成本比例。
6.3 缺少显式 cap 的自修正回路
- 表现 :质检不通过即再次调用 LLM,无最大轮次、费用上限、deadline的硬止条件。
- 后果 :边界输入上可能出现无界重试 ;费用与尾延迟无上界可陈述。
- 改进 :在 State 中维护
escalation_round、spend与budget_cap(及时间戳);超限走degrade_finalize、排队或人工工单。
6.4 不可观测的降级
- 表现 :运行时更换模型、压缩检索、
top_k等参数,但未写入结构化审计或 trace。 - 后果 :成本尖刺与质量回退无法归因;对账与客户沟通缺乏证据链。
- 改进 :每次实现档变化写入
audit或 span attribute;对fallback 率、降级终态率设告警阈值。
6.5 策略只存在于文档
- 表现 :设计文档描述完备预算策略,但运行期 State 无字段、代码无分支。
- 后果 :策略不可测试、不可回归;后续 refactor 易静默破坏约定。
- 改进 :策略参数化 进配置或 State;关键分支配套单元测试 / 合约测试。
6.6 并行与重复计费失配
- 表现 :并行子图重复触发同一昂贵取证,或对共享副作用重复扣费/漏扣费。
- 后果 :账本与真实资源不一致;高并发下放大无效调用。
- 改进 :为昂贵步骤设幂等键与去重 ;在汇聚节点统一汇总 spend。
评审探针(建议配套使用):
- 若用户级预算减半 ,工作流应在哪一个节点 首次出现与基线不同的分支或输出契约?
- 若主模型连续 429 / 超时 ,是否在有限步内 进入 fallback 或退化终态,且路径可被自动化测试固定?
- 离线评估是否同时汇报质量与成本(或延迟),而非仅汇报准确率类单一指标?
若以上问题无确定答案 ,通常表明资源与策略尚未作为一等设计要素纳入实现。
7. 示例工作流拓扑与节点详解
本节通过一个SRE(站点可靠性工程)事件分诊助手的完整示例,演示如何把前面讲的资源感知策略落地为可运行的LangGraph代码。
7.0 场景与问题:为什么需要这个工作流
业务背景 :
想象你是值班SRE,凌晨3点收到一条告警:"订单服务延迟飙升"。你需要快速判断:
- 这是P1生产事故,需要立即全量取证、发布关联、根因分析?
- 还是普通告警,只需几句话建议指向runbook即可?
资源矛盾:
- 如果把所有工单都扔给最强模型做"深度分析"------账单爆炸,且高延迟会让P1事故错过黄金止损时间。
- 如果一律用轻量模型"快速过"------P1事故的浅层分析可能漏掉关键线索,引发更大故障。
工作流要解决的问题:
- 动态分档:根据工单描述自动判断严重度(P1/P2/P3)。
- 取证伸缩:低严重度只拉摘要日志,高严重度才拉全量上下文。
- 模型分层:简单工单用flash档快速出稿,复杂工单逐步升级到balanced/heavy档。
- 有界升档 :质检不通过时可以重试,但有轮次上限 和预算上限硬性约束。
- 可观测降级:预算或轮次触顶时,进入"尽力而为"终态并标注人工复核。
关键流程节点(对应下方拓扑图):
triage:读取原始告警,输出结构化分诊(严重度1-3)。context:根据严重度和预算选择取证粒度(轻/标/重)。draft:按当前档位生成答复,预算不足时强制降级,主模型失败时fallback。critic:质检评估,输出accept或escalate。escalate:升档轮次+1,回到draft用更高档位重试(形成受控循环)。degrade_finalize:预算/轮次触顶时的降级收口。finalize:正常收口。
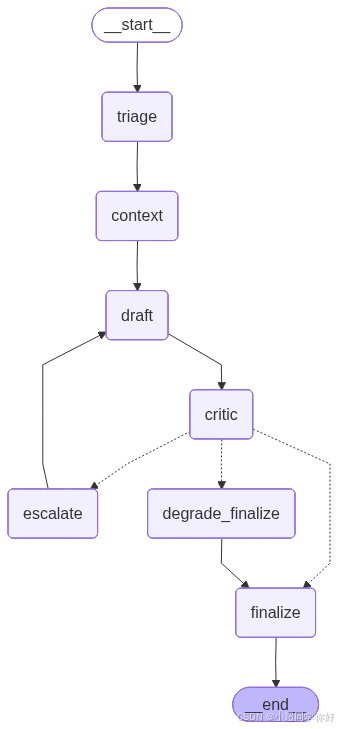
一句话描述这张图 :
从入口开始,先分诊 、再取证 、然后生成-质检 ;质检不通过且资源允许时,走escalate升级档位循环重试 ;质检不通过但资源触顶时,走degrade_finalize降级收口 ;质检通过则直接finalize正常收口。
实现说明 :demo_codes 默认路径 (build_resource_aware_app() 无参、main.py、Notebook 在检测到 API Key 时)均使用 OpenAIResourceLLM ------通过 ChatOpenAI 调用真实模型,环境变量与 20_skills_5_MetaSkills/demo_codes 的 .env 一致。下文 §7.2 起对 triage_incident / critique 等 的摘录,对应 llm_resource.py 中 OpenAIResourceLLM 的实现语义(JSON 输出 + _extract_json_object 解析)。MockResourceLLM 仍保留在仓库中,仅 供 tests/test_resource_aware_graph.py 做无网络的确定性回归,不是 CLI/Notebook 的主路径。
7.1 状态模式、计费常数与辅助函数(含 verbose)
ResourceAwareState (TypedDict)把领域字段 (工单、分诊、上下文、草案、质检结果)与资源字段 (budget_cap、spend、escalation_round、audit 等)放在同一快照中,便于节点返回增量更新并在测试中断言路径与消耗。
verbose=True (initial_state(..., verbose=True) 或 main.py --verbose)时:
_log:除写入audit外,将同一行print到控制台(便于与外部日志系统对照)。_verbose_payload:在每个业务节点及route_after_critic返回前,打印[verbose][节点名]块,列出本步写入 state 的要点;draft、context_bundle等长字段会截断,避免刷屏。
py
import json
import time
from typing import Any, Literal, TypedDict
class ResourceAwareState(TypedDict, total=False):
"""运行时状态:预算与审计字段与业务字段分离,便于观测。"""
incident_raw: str
triage: dict[str, Any]
context_bundle: str
context_light_mode: bool
draft: str
tier_used: Tier
escalation_round: int
used_fallback: bool
critic: dict[str, Any]
budget_cap: int
spend: int
audit: list[str]
simulate_primary_failure: bool
done_reason: str
degraded: bool
verbose: bool
COST_TRIAGE = 8
COST_CONTEXT = {0: 12, 1: 28, 2: 55}
COST_DRAFT: dict[Tier, int] = {"flash": 18, "balanced": 48, "heavy": 110}
def _tier_for_round(escalation_round: int, severity: int) -> Tier:
base = 0 if severity == 1 else 1 if severity == 2 else 1
idx = min(base + escalation_round, 2)
return ("flash", "balanced", "heavy")[idx] # type: ignore[return-value]
def _log(state: ResourceAwareState, line: str) -> None:
audit = list(state.get("audit") or [])
audit.append(f"{time.monotonic():.3f}s | {line}")
state["audit"] = audit
if state.get("verbose"):
print(line)
def _truncate_text(s: str, limit: int = 1600) -> str:
s = str(s) if s is not None else ""
return s if len(s) <= limit else s[: limit - 1] + "..."
def _verbose_payload(state: ResourceAwareState, node: str, payload: dict[str, Any]) -> None:
"""verbose=True 时打印本节点写入 state 的关键字段(长文本截断)。"""
if not state.get("verbose"):
return
sep = "─" * 60
print(f"\n{sep}\n[verbose][{node}] 本节点产出(写入 state 的要点)\n{sep}")
for key, val in payload.items():
if val is None:
print(f" {key}: null")
continue
if isinstance(val, str):
print(f" {key}:\n{_truncate_text(val, 2000)}")
elif isinstance(val, (dict, list)):
try:
dumped = json.dumps(val, ensure_ascii=False, indent=2)
print(f" {key}:\n{_truncate_text(dumped, 2400)}")
except (TypeError, ValueError):
print(f" {key}: {repr(val)[:1200]}")
else:
print(f" {key}: {val}")
def _charge(state: ResourceAwareState, cost: int, memo: str) -> ResourceAwareState:
spend = state.get("spend", 0) + cost
_log(state, f"charge +{cost} ({memo}) → spend={spend}/{state.get('budget_cap')}")
return {**state, "spend": spend}7.2 triage_node 节点 (分诊)
职责 :读取原始 incident_raw,调用 llm.triage_incident() 得到结构化分诊(severity、compliance_touch、summary)。
资源 :扣减 COST_TRIAGE。分诊结果决定后续取证档位 与起草档位基线 ,是整张图的难度信号源。
py
def triage_node(state: ResourceAwareState) -> ResourceAwareState:
s = {**state}
_log(s, "[node] triage")
triage = llm.triage_incident(s["incident_raw"])
out = _charge({**s, "triage": triage}, COST_TRIAGE, "triage")
_verbose_payload(out, "triage", {"triage": out.get("triage"), "spend": out.get("spend")})
return out推理后端(OpenAIResourceLLM) :分诊由 小模型 (resource_aware_config.model_flash)按 system 指令输出单个 JSON ,再解析为 severity / compliance_touch / summary(严重度钳制在 1--3)。完整实现见 demo_codes/llm_resource.py。
py
def triage_incident(self, incident_raw: str) -> dict[str, Any]:
sys = (
"你是 SRE 分诊助手。只输出一个 JSON 对象,不要 Markdown,不要解释文字。\n"
"字段:severity(整数 1=低 2=中 3=高/P1)、compliance_touch(布尔...)、summary(...≤120 字)。\n"
"严重度参考:宕机/全线不可用/生产事故/P1 → 3;延迟/超时/大量告警/P2 → 2;一般咨询 → 1。"
)
user = f"工单原文:\n{incident_raw.strip()}"
model = resource_aware_config.model_flash
raw = self._chat(model, system=sys, user=user, temperature=0.0, max_tokens=256)
data = _extract_json_object(raw)
sev = max(1, min(3, int(data.get("severity", 1))))
return {
"severity": sev,
"compliance_touch": bool(data.get("compliance_touch", False)),
"summary": str(data.get("summary", ""))[:200],
}对于用户输入 P2:checkout-api 延迟飙升,payment-gw 错误率升高。,triage_node 节点输出:
model_flash
charge +8 (triage) → spend=8/260
{
"severity": 2,
"compliance_touch": false,
"summary": "checkout-api延迟飙升,payment-gw错误率升高"
}
spend: 87.3 context_node 节点 (取证 / 上下文采集)
职责 :依据 triage.severity 选择标称取证成本 (COST_CONTEXT 档次);若当前 spend 加上该成本将超过 budget_cap,则置 context_light_mode=True,改为轻取证 ,并仅扣减较低费用 5。
资源 :体现**「预算不足则收缩信息面」的策略,对应生产中的分层拉取日志 / trace**。
py
def context_node(state: ResourceAwareState) -> ResourceAwareState:
"""取证:按严重度选标称成本;预算不足时轻取证并扣减较低费用。"""
s = {**state}
_log(s, "[node] context_gather")
tri = s.get("triage") or {}
severity = int(tri.get("severity", 1))
cap = s.get("budget_cap", 0)
current = s.get("spend", 0)
key = min(max(severity - 1, 0), 2)
need = COST_CONTEXT[key]
light = current + need > cap
bundle = llm.build_context(s["incident_raw"], severity, light_mode=light)
cost = 5 if light else need
ctx_state = {
**s,
"context_bundle": bundle,
"context_light_mode": light,
}
if light:
_log(ctx_state, "[policy] 预算不足,降级为轻取证")
out = _charge(ctx_state, cost, "context")
_verbose_payload(
out,
"context",
{
"context_light_mode": out.get("context_light_mode"),
"context_bundle": out.get("context_bundle"),
"spend": out.get("spend"),
},
)
return out
py
def build_context(self, incident_raw: str, severity: int, light_mode: bool) -> str:
if light_mode or severity == 1:
depth = "轻取证:仅输出索引级摘要(聚合指标、服务名推断),不要编造具体 trace id。"
elif severity == 2:
depth = "标准取证:给出若干条代表性指标与假设关联服务,可含虚构但合理的 trace 样例。"
else:
depth = "深度取证:给出发布窗口、DB/锁等待、全链路线索等较完整(可虚构)的取证摘录。"
sys = (
"你是取证编排助手。演示环境中无真实日志,请根据工单**合理虚构**一段「上下文包」文本,"
"用于后续起草答复;内容要像内部运维备注,不要输出 JSON。\n"
f"{depth}"
)
user = f"severity={severity} light_mode={light_mode}\n工单:\n{incident_raw.strip()}"
model = resource_aware_config.model_flash
return self._chat(model, system=sys, user=user, temperature=0.25, max_tokens=600)对于用户输入 P2:checkout-api 延迟飙升,payment-gw 错误率升高。,context_node 节点输出:
charge +28 (context) → spend=36/260
context_light_mode: False
context_bundle:
【上下文包】
- 问题时间窗:2024-04-05 14:23 - 14:47(UTC+8)
- 涉及服务:checkout-api(v2.3.1)、payment-gw(v1.8.4)、user-profile-service(v3.2.0)
- 关键指标异常:
- checkout-api 平均延迟从 120ms 突增至 980ms(P95 达 2.1s),持续 24 分钟
- payment-gw 错误率从 <0.5% 升至 18.3%(主要为 5xx 服务端错误)
- 伴随请求量小幅上升(+12%),但无明显流量突增或用户行为异常
- 调用链关联分析(虚构 trace 样例,用于定位):
`trace_id=7a2b8f3c-d9e1-4a6f-bc7d-3e5f9a1c2b4d`
└── checkout-api (14:25:11.32) → [duration: 1.8s, status: 500]
├── user-profile-service (14:25:11.34) → [duration: 1.2s, status: 200]
└── payment-gw (14:25:11.36) → [duration: 1.6s, status: 502, error: "Gateway timeout"]
`trace_id=9f4e1a2b-5c6d-4e7f-8g9h-0i1j2k3l4m5n`
└── checkout-api (14:26:03.11) → [duration: 2.3s, status: 500]
├── payment-gw (14:26:03.13) → [duration: 2.1s, status: 504, error: "Connection refused"]
└── redis-cache (14:26:03.15) → [duration: 0.08s, status: 200]
- 假设根因初步指向:
- payment-gw 在 14:23 左右触发了数据库连接池耗尽(日志中出现 `max pool size reached`)
- checkout-api 在调用 payment-gw 时未启用超时熔断(默认超时 1.5s,实际响应常 >2s)
- user-profile-service 返回的用户权限数据在某版本更新后增加字段校验逻辑,导致下游依赖延迟放大
- 附加线索:
- 14:22:45 有一次灰度发布(checkout-api v2.3.1 部署),但未涉及 payment-gw
- 14:24:10 收到告警:`payment-gw-pool-utilization > 95%`
- 14:25:00 开始出现大量 `java.net.SocketTimeoutException` 日志
> 注:当前环境为演示,日志与 trace 为合理虚构,用于编排取证流程。真实排查需结合 APM、日志聚合与监控系统联动。
spend: 367.4 draft_node 节点(按档位生成答复)
职责:
- 用
_tier_for_round(escalation_round, severity)选本次推理档位 - 若
spend + COST_DRAFT[tier] > budget_cap,强制降为 flash,避免单次调用越界 - 调用
llm.draft_answer(...) - 若抛出
LLMPrimaryUnavailable(真实部署中可映射为限流/超时;演示时在simulate_primary_failure且首次heavy下由OpenAIResourceLLM主动抛出),则降为balanced重试 ,并置used_fallback=True - 按实际使用的 tier 扣减
COST_DRAFT
资源 :本节点集中体现模型分档 + 预算钳制 + 可观测 fallback。
py
def draft_node(state: ResourceAwareState) -> ResourceAwareState:
"""起草:按轮次选 tier,预算钳制与可选 primary 失败 fallback;合并 `used_fallback` 标志。"""
s = {**state}
tri = s.get("triage") or {}
severity = int(tri.get("severity", 1))
rnd = s.get("escalation_round", 0)
tier = _tier_for_round(rnd, severity)
cap = s.get("budget_cap", 0)
projected = s.get("spend", 0) + COST_DRAFT[tier]
if projected > cap:
tier = "flash"
_log(s, "[policy] 剩余预算不足以目标档位 → 强制 flash")
_log(s, f"[node] draft tier={tier} round={rnd}")
used_fb = False
try:
draft, fb = llm.draft_answer(
incident_raw=s["incident_raw"],
context_bundle=s.get("context_bundle", ""),
severity=severity,
tier=tier,
simulate_primary_failure=bool(s.get("simulate_primary_failure")),
)
used_fb = fb
except LLMPrimaryUnavailable as exc:
_log(s, f"[fallback] {exc} → retry balanced")
tier = "balanced"
draft, used_fb = llm.draft_answer(
incident_raw=s["incident_raw"],
context_bundle=s.get("context_bundle", ""),
severity=severity,
tier=tier,
simulate_primary_failure=False,
)
used_fb = True
merged_fb = used_fb or bool(s.get("used_fallback"))
after = _charge(
{**s, "draft": draft, "tier_used": tier, "used_fallback": merged_fb},
COST_DRAFT[tier],
f"draft({tier})",
)
_verbose_payload(
after,
"draft",
{
"tier_used": after.get("tier_used"),
"used_fallback": after.get("used_fallback"),
"draft": after.get("draft"),
"spend": after.get("spend"),
},
)
return after说明 :merged_fb 保证同一请求内只要发生过一次 fallback ,used_fallback 保持为 True ,避免后续某轮 heavy 成功又把标志写回 False (与测试 test_primary_failure_uses_fallback 一致)。
py
def draft_answer(
self,
*,
incident_raw: str,
context_bundle: str,
severity: int,
tier: Tier,
simulate_primary_failure: bool,
) -> tuple[str, bool]:
if (
simulate_primary_failure
and tier == "heavy"
and not self._heavy_failed_once
):
self._heavy_failed_once = True
raise LLMPrimaryUnavailable("simulated: heavy tier primary unavailable")
model = _model_for_tier(tier)
max_tokens = _max_tokens_for_tier(tier)
tier_hint = {
"flash": "用简短段落给出初步判断与下一步(可指向 runbook),不必长篇根因。",
"balanced": "给出较完整的根因假设、验证步骤与沟通要点。",
"heavy": "必须包含标题「根因分析(深度)」小节,给出分级处置建议(回滚/限流/扩容等)与风险说明。",
}[tier]
sys = (
"你是值班 SRE,根据工单与取证上下文起草对内回复(中文)。\n"
f"{tier_hint}\n"
"不要输出 JSON;可使用 Markdown 小标题。"
)
user = (
f"严重度(1-3): {severity}\n"
f"档位: {tier}\n\n"
f"取证上下文:\n{context_bundle}\n\n"
f"工单:\n{incident_raw.strip()}"
)
text = self._chat(
model,
system=sys,
user=user,
temperature=0.2,
max_tokens=max_tokens,
)
return text, False对于用户输入 P2:checkout-api 延迟飙升,payment-gw 错误率升高。,draft_node 节点输出:
charge +48 (draft(balanced)) → spend=84/260
tier_used:
balanced
used_fallback: False
draft:
# 🚨 P2 工单响应(对内 SRE 同步稿)
## 一、根因假设(高置信度)
综合调用链追踪、指标时序、日志线索与发布历史,当前**最可能的根因链**如下:
> **payment-gw 数据库连接池耗尽 → 触发级联超时与熔断缺失 → checkout-api 延迟雪崩 + 错误放大**
具体逻辑链:
1. **直接诱因**:`payment-gw v1.8.4` 在 14:22--14:24 间因某笔慢查询/事务未及时释放连接(或连接泄漏),导致 HikariCP 连接池利用率在 14:24:10 突破 95%,并在 14:25 达到 `max pool size reached`(日志可查);
2. **下游传导**:
- payment-gw 对 DB 超时后返回 `502 Gateway Timeout` 或 `504 Connection refused`(体现为 socket 层异常),而非优雅降级;
- checkout-api 调用 payment-gw **未配置显式超时与熔断**(当前依赖默认 HTTP 客户端 1.5s 超时,但实际响应常 >2s),导致线程阻塞、请求堆积、P95 延迟被严重拉高;
3. **上游放大**:
- user-profile-service v3.2.0 中新增的权限字段校验逻辑(如 JSON Schema 验证 + 外部鉴权调用)虽自身成功(200),但平均耗时增加 300--400ms,叠加 payment-gw 延迟后,checkout-api 整体链路突破 2s,触发更多超时与重试;
- 少量请求量上升(+12%)成为"压垮骆驼的最后一根稻草",暴露了连接池与超时配置的脆弱性。
> ✅ 排除项:
> - 非流量洪峰(无用户行为突变、无 CDN/入口层告警);
> - 非基础设施故障(CPU/Mem/网络监控均平稳,redis-cache 响应正常);
> - 非灰度发布直连影响(checkout-api v2.3.1 变更不含 payment-gw 调用逻辑调整,且问题在部署后 2min 才显现)。
---
## 二、关键验证步骤(已执行 / 待闭环)
| 步骤 | 操作 | 当前状态 | 责任人 |
|------|------|----------|--------|
| ✅ 1. 复现连接池瓶颈 | 在 staging 环境模拟相同 DB 负载(注入慢查询 + 并发调用),确认 `HikariPool-1 - Connection is not available, request timed out after 30000ms.` 日志复现 | 已复现 | @SRE-DBA |
| ✅ 2. 核查 checkout-api 超时配置 | 检查 `feign.client.config.default.readTimeout` 与 `connectTimeout`(当前为 1500ms),对比实际 payment-gw 响应 P95(2.1s)→ **存在 700ms 缺口** | 已确认 | @SRE-Backend |
| ⏳ 3. 分析 user-profile-service 新增校验开销 | 抽样比对 v3.1.9 与 v3.2.0 的 `/user/permissions` trace,统计 JSON Schema 验证耗时及外部调用次数 | 进行中(APM 查询中) | @SRE-Platform |
| ⏳ 4. 检查 payment-gw 是否启用连接泄漏检测 | 查阅 `leakDetectionThreshold=60000` 是否开启,确认近期是否有 `Connection leak detected` 日志 | 待查(日志平台关键词搜索) | @SRE-Backend |
---
## 三、沟通要点(对内同步口径)
- **对研发团队(checkout-api / payment-gw / user-profile-service)**:
> "本次延迟事件本质是**防御性配置缺失 + 依赖服务资源瓶颈**的组合问题。非代码功能缺陷,但暴露了关键链路的可观测性与韧性短板。请优先协同落地以下改进:
> - ✅ checkout-api:**本周内完成 Feign 超时升级至 2.5s + 集成 Resilience4j 熔断(failureRateThreshold=50%, timeout=2s)**;
> - ✅ payment-gw:**明日提供连接池监控增强方案(含泄漏检测开关、活跃连接数/等待队列长度告警)及慢 SQL 治理排期**;
> ...
spend: 847.5 critic_node节点(质检)
职责 :调用 llm.critique(...),输入事件、上下文、草案、严重度与实际使用的 tier ,得到结构化结果(至少含 verdict)。扣减 critic 固定成本 (常量 6)。该节点为条件边 提供策略输入。
py
def critic_node(state: ResourceAwareState) -> ResourceAwareState:
"""质检:调用 LLM 得到 `critic`(含 verdict),扣固定 critic 成本。"""
s = {**state}
tri = s.get("triage") or {}
severity = int(tri.get("severity", 1))
tier = s.get("tier_used", "flash")
_log(s, "[node] critic")
verdict = llm.critique(
incident_raw=s["incident_raw"],
context_bundle=s.get("context_bundle", ""),
draft=s.get("draft", ""),
severity=severity,
tier=tier,
)
after = _charge({**s, "critic": verdict}, 6, "critic")
_verbose_payload(
after,
"critic",
{"critic": after.get("critic"), "spend": after.get("spend")},
)
return after推理后端(OpenAIResourceLLM) :质检同样走 model_flash ,在 system 中写明与图策略对齐的规则(P1 缺深度根因且非 heavy → escalate、过短 → escalate、中高危 + flash 且无「根因」→ escalate 等),模型输出 JSON 后做 verdict 白名单 归一。完整代码见 llm_resource.py。
py
def critique(
self,
*,
incident_raw: str,
context_bundle: str,
draft: str,
severity: int,
tier: Tier,
) -> dict[str, Any]:
sys = (
"你是质检员。只输出一个 JSON 对象,不要 Markdown。\n"
"字段:verdict(\"accept\" 或 \"escalate\")、reason(字符串)。\n"
"规则:\n"
"- severity>=3 且草稿中无「根因分析(深度)」且 tier 不是 heavy → escalate。\n"
"- 草稿过短(明显少于约 80 字有效内容)→ escalate。\n"
"- severity>=2 且 tier 为 flash 且正文不含「根因」二字 → escalate。\n"
"- 其余 accept。\n"
f"当前 severity={severity}, tier={tier}。"
)
user = f"工单摘要:\n{incident_raw[:500]}\n\n取证摘录:\n{context_bundle[:1500]}\n\n草稿:\n{draft}"
model = resource_aware_config.model_flash
raw = self._chat(model, system=sys, user=user, temperature=0.0, max_tokens=256)
data = _extract_json_object(raw)
verdict = str(data.get("verdict", "accept")).lower()
if verdict not in ("accept", "escalate"):
verdict = "accept"
return {"verdict": verdict, "reason": str(data.get("reason", ""))}对于用户输入 P2:checkout-api 延迟飙升,payment-gw 错误率升高。,critic_node 节点输出:
charge +6 (critic) → spend=90/260
critic:
{
"verdict": "accept",
"reason": "severity=2 且 tier=balanced,不满足 escalate 触发条件;草稿内容完整,包含根因分析、验证步骤、沟通口径及后续动作,有效内容远超 80 字,符合要求。"
}
spend: 907.6 route_after_critic(条件路由)
职责 :根据 critic.verdict 与剩余预算 、**当前 escalation_round**决定下一跳:
accept/ 缺省 →finalizeescalate且escalation_round >= 2→degrade_finalize(升档次数 cap)escalate且剩余额度不足以支付下一轮 对应的 draft →degrade_finalize- 否则 →
escalate节点
py
def route_after_critic(
state: ResourceAwareState,
) -> Literal["finalize", "escalate", "degrade_finalize"]:
verdict = (state.get("critic") or {}).get("verdict")
spend = state.get("spend", 0)
cap = state.get("budget_cap", 0)
rnd = state.get("escalation_round", 0)
tri = state.get("triage") or {}
severity = int(tri.get("severity", 1))
headroom = cap - spend
next_tier = _tier_for_round(rnd + 1, severity)
next_draft_floor = COST_DRAFT[next_tier]
if verdict == "accept" or verdict is None:
if state.get("verbose"):
_verbose_payload(
state,
"route_after_critic",
{
"next_node": "finalize",
"verdict": verdict,
"escalation_round": rnd,
"headroom": headroom,
"severity": severity,
},
)
return "finalize"
if verdict == "escalate":
if rnd >= 2:
target = "degrade_finalize"
elif headroom < next_draft_floor:
target = "degrade_finalize"
else:
target = "escalate"
if state.get("verbose"):
_verbose_payload(
state,
"route_after_critic",
{
"next_node": target,
"verdict": verdict,
"escalation_round": rnd,
"headroom": headroom,
"next_tier_if_escalate": next_tier,
"next_draft_floor": next_draft_floor,
"severity": severity,
},
)
return target # type: ignore[return-value]
if state.get("verbose"):
_verbose_payload(
state,
"route_after_critic",
{
"next_node": "finalize",
"verdict": verdict,
"note": "未知 verdict,默认收口",
},
)
return "finalize"verbose :条件边不是图上的「节点」,但在 verbose=True 时同样打印 [verbose][route_after_critic],便于对照「为何走向 finalize / escalate / degrade_finalize」。
7.7 节点 escalate(升档轮次 +1)
职责 :在允许继续升档时,仅将 escalation_round 自增 ,下一跳固定回 draft ;由 _tier_for_round 在下一轮选择更重一档(在 cap 内)。
设计动机 :把**「轮次变更」与「生成」**分离,审计上更清晰。
py
def escalate_node(state: ResourceAwareState) -> ResourceAwareState:
s = {**state}
nxt = s.get("escalation_round", 0) + 1
_log(s, f"[node] escalate → round={nxt}")
out = {**s, "escalation_round": nxt}
_verbose_payload(out, "escalate", {"escalation_round": nxt})
return out7.8 节点 degrade_finalize(退化定稿)
职责 :在预算或升档 cap 阻断进一步升档时,向 draft 追加系统备注 ,置 degraded=True,done_reason="degraded_budget_or_cap",进入可解释的降级终态 ;随后进入 finalize。
注意 :此处不另扣费(已在路由处判定无力继续),与业务上「尽最大努力交付 + 要求人工复核」一致。
py
def degrade_finalize_node(state: ResourceAwareState) -> ResourceAwareState:
s = {**state}
_log(s, "[node] degrade_finalize")
note = (
"\n\n[系统备注] 预算或升档次数已触顶,输出为尽力而为草案,"
"需人工复核后再执行变更。"
)
out = {
**s,
"draft": (s.get("draft") or "") + note,
"degraded": True,
"done_reason": "degraded_budget_or_cap",
}
_verbose_payload(
out,
"degrade_finalize",
{
"degraded": out.get("degraded"),
"done_reason": out.get("done_reason"),
"draft": out.get("draft"),
},
)
return out7.9 节点 finalize(收口)
职责 :统一收口 :若尚无 done_reason(正常 accept 路径),则记为 accepted ;保持 draft / audit / spend 等供调用方读取。随后图执行 END。
py
def finalize_node(state: ResourceAwareState) -> ResourceAwareState:
s = {**state}
_log(s, "[node] finalize")
reason = s.get("done_reason") or "accepted"
out = {**s, "done_reason": reason}
_verbose_payload(
out,
"finalize",
{
"done_reason": out.get("done_reason"),
"degraded": out.get("degraded"),
"spend": out.get("spend"),
"tier_used": out.get("tier_used"),
},
)
return out7.10 图编译、边与初始状态
build_resource_aware_app :注册全部节点;START → triage → context → draft → critic;critic 上条件边 绑定 route_after_critic;escalate → draft 形成受控环路 ;degrade_finalize 与正常 finalize 均汇入 END。
py
def build_resource_aware_app(llm: ResourceLLM | None = None):
"""编译无 checkpointer 的同步应用。默认使用真实 LLM(OpenAI 兼容);测试可显式传入 Mock。"""
if llm is not None:
backend = llm
else:
if not resource_aware_config.api_key:
raise ValueError(
"未配置 API Key:请在 demo_codes/.env 中设置 OPENAI_API_KEY 或 DASHSCOPE_API_KEY;"
"测试可 `from llm_resource import mock_llm_factory` 后传入 "
"`build_resource_aware_app(mock_llm_factory())`。",
)
backend = live_llm_factory()
h = make_node_handlers(backend)
g = StateGraph(ResourceAwareState)
g.add_node("triage", h["triage"])
g.add_node("context", h["context"])
g.add_node("draft", h["draft"])
g.add_node("critic", h["critic"])
g.add_node("escalate", h["escalate"])
g.add_node("degrade_finalize", h["degrade_finalize"])
g.add_node("finalize", h["finalize"])
g.add_edge(START, "triage")
g.add_edge("triage", "context")
g.add_edge("context", "draft")
g.add_edge("draft", "critic")
g.add_conditional_edges(
"critic",
route_after_critic,
{
"finalize": "finalize",
"escalate": "escalate",
"degrade_finalize": "degrade_finalize",
},
)
g.add_edge("escalate", "draft")
g.add_edge("degrade_finalize", "finalize")
g.add_edge("finalize", END)
return g.compile()
def initial_state(
incident_raw: str,
*,
budget_cap: int = 260,
simulate_primary_failure: bool = False,
verbose: bool = False,
) -> ResourceAwareState:
"""预算默认 260:足够 P2 走通;P1 + 多次升档可能触顶或触发降级。"""
return {
"incident_raw": incident_raw,
"escalation_round": 0,
"budget_cap": budget_cap,
"spend": 0,
"audit": [],
"simulate_primary_failure": simulate_primary_failure,
"done_reason": "",
"degraded": False,
"used_fallback": False,
"verbose": verbose,
}8. 代码组织与运行方式
| 模块 | 职责 |
|---|---|
config_parser.py |
从 .env 读取 OPENAI_API_KEY / DASHSCOPE_API_KEY、BASE_URL、MODEL 与可选 MODEL_FLASH / MODEL_BALANCED / MODEL_HEAVY(与 20_skills_5_MetaSkills/demo_codes 一致) |
resource_aware_graph.py |
StateGraph 构建、全部节点、route_after_critic、计费与 audit;verbose=True 时 _verbose_payload 打印各节点写入 state 的要点;draft 节点合并 used_fallback |
llm_resource.py |
ResourceLLM 协议、OpenAIResourceLLM (ChatOpenAI)、MockResourceLLM (仅 pytest)、LLMPrimaryUnavailable |
main.py |
CLI:--budget、--primary-down、--json、--verbose 等;无 Key 时提示配置 .env |
readme.md / README_运行与架构.md / README_完整方案.md |
Demo 索引、运行与拓扑、方案说明(对齐第 8 篇 tool granularity 文档结构) |
main.ipynb |
Jupyter 交互:拓扑图 + invoke(VERBOSE 与 CLI 行为一致) |
.env.example |
API Key、BASE_URL、分档模型名等示例 |
requirements.txt |
langgraph、langchain-openai、langchain-core、python-dotenv、pytest 等 |
tests/test_resource_aware_graph.py |
回归升档、低预算、simulate_primary_failure、低严重度路径(Mock,不消耗 API) |
环境与命令见 demo_codes/README_运行与架构.md 与上级目录 README.md 。使用 python main.py ... --verbose 时,入口会先打印一行说明,随后各节点按上表 _log + _verbose_payload 输出。自定义后端时实现 ResourceLLM 并传入 build_resource_aware_app(your_llm) 即可,图与路由逻辑可保持不变。
9. 小结
- 资源感知优化 把预算、时延、可靠性 等形式化约束纳入运行态状态 ,使策略成为可验证的控制流,而非事后报表中的统计现象。
- 优化对象本质上是多维约束下的折中 :经济成本、尾延迟、错误风险与组织流程不能压缩为单一标量。
- LangGraph 通过显式 State 与条件边 将策略图谱化 ,利于代码审查、回归测试与运维观测的闭环。
- 本仓库以SRE 事件分诊 为叙事载体,串联严重度驱动的取证伸缩、模型分层、有上界升档与 fallback ;读者可将同一状态与路由骨架迁移至其他高成本编排场景。