这篇文章不会堆砌枯燥的公式,而是用最直白的语言、生动的比喻和可运行的代码,带你彻底搞懂CNN。
前言:CNN 在做什么?
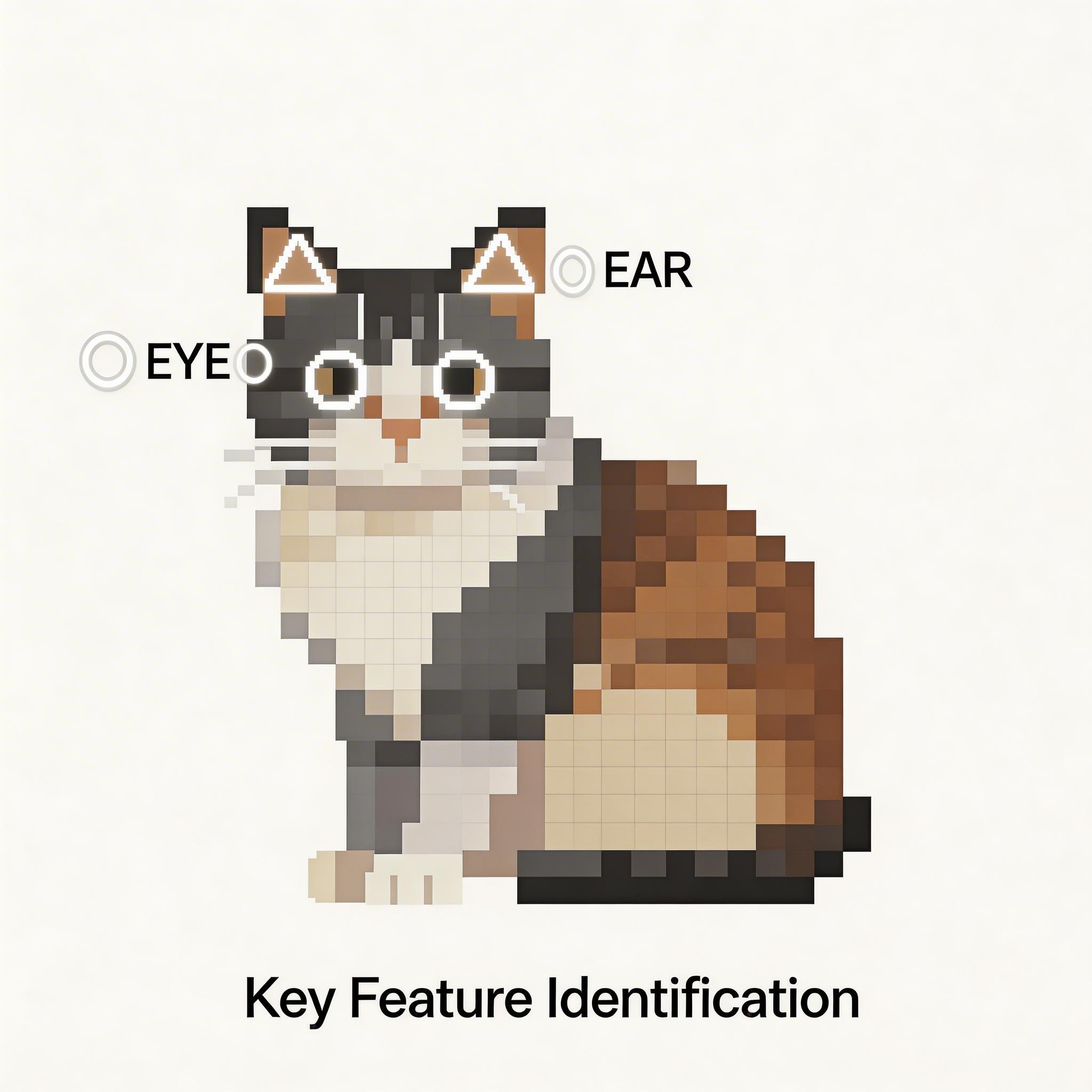
想象一下,你是一个侦探,需要从一张照片里认出"这是一只猫"。你不会一下子看完整张照片,而是会先看局部:耳朵的形状、胡须的纹理、眼睛的颜色......把这些局部线索组合起来,最终得出结论。
卷积神经网络(CNN) 干的正是同样的事:它通过一层层的"小侦探",逐步从局部到整体,从简单到复杂,最终认出图片里的东西。
CNN 如今已经无处不在:
-
你手机里的人脸解锁
-
自动驾驶汽车识别红绿灯和行人
-
医生用 AI 看 CT 片子
-
淘宝拍照搜同款
这一切的背后,都是 CNN 在默默工作。
一、为什么非要用 CNN?------全连接网络的"硬伤"
在 CNN 出现之前,人们用"全连接网络"处理图像。这种网络有个致命问题:它会把图片拉成一条直线。
比如一张 32×32 的彩色图片,本来是一个立方体(高、宽、RGB 三通道)。全连接网络会把它变成一长串数字(32×32×3 = 3072 个数字)。这样一来,原本挨着的像素可能被分到很远的位置,网络完全丢失了"左边、右边、上边、下边"这种空间关系。
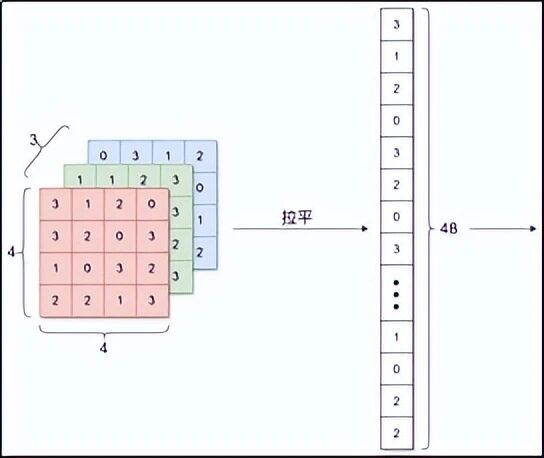
打个比方:这就像把一首歌的每个音符随机打乱顺序,然后让人猜原曲------不可能猜出来。
CNN 的聪明之处在于:它不拆散图片,而是用一个"小放大镜"在图片上滑动,每次只看一小块区域,保留图片的原始形状。这样,空间信息就完整地保留下来了。
二、CNN 的三块积木
一个 CNN 模型主要由三种层堆叠而成,就像搭积木一样:
|----------|----------------|--------|
| 积木名称 | 一句话作用 | 有无参数 |
| 卷积层 | 用"小筛子"在图片上找特征 | 有(可学习) |
| 池化层 | 把图片缩小,保留最显眼的部分 | 无 |
| 全连接层 | 汇总所有特征,拍板分类 | 有(可学习) |
下面我们一块一块拆开看。
三、卷积层:特征探测器
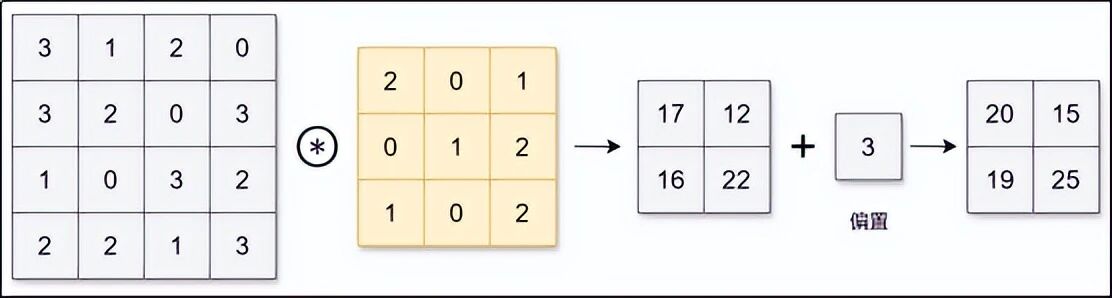
3.1 卷积核------那个"小筛子"
卷积层有一个核心道具:卷积核 (也叫滤波器)。它是一个小矩阵,比如 3×3 大小。你可以把它想象成一个有偏好的小眼镜:有的眼镜喜欢看"横线条",有的喜欢看"竖线条",有的喜欢看"圆点"。
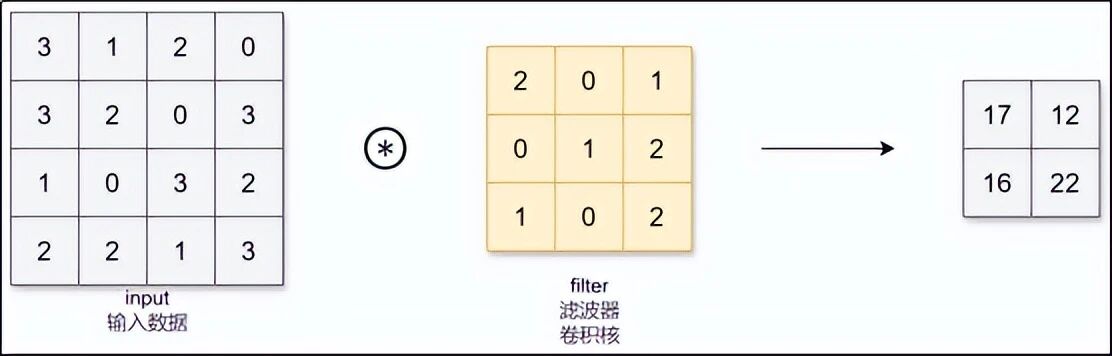
这个卷积核会在图片上从左到右、从上到下滑动。每到一个位置,它就把覆盖住的像素值和自己的数值做一次"亲密计算",得出一个数字。这个数字代表"这块区域和我偏好的特征有多像"。
计算过程(大致理解,不必记数字):
-
把卷积核盖在图片的一小块区域上
-
对应位置相乘,再全部加起来
-
得到一个数,填到输出特征图的对应位置
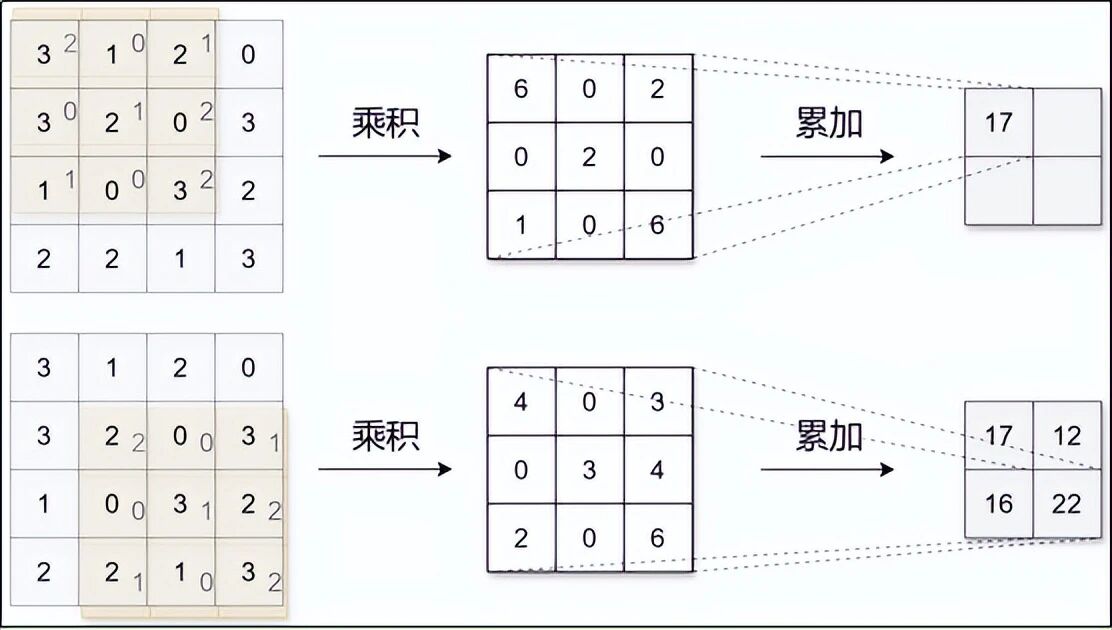
所有位置都算完后,就得到一张新的、更小的图片,叫做特征图。这张特征图上的每个点,都代表原图对应区域与卷积核的"相似度"。
3.2 填充------给图片加个"边框"
你会发现,每次卷积后,图片都会变小一点。比如 32×32 的图片,用 3×3 卷积核,步幅为 1,卷积后变成 30×30。如果连续做很多次卷积,图片会迅速缩水,甚至消失。
填充就是在原图周围加一圈"0",就像给照片加个白边。加一圈后,32×32 变成 34×34,再用 3×3 卷积核,输出就还是 32×32 ------尺寸不变了。
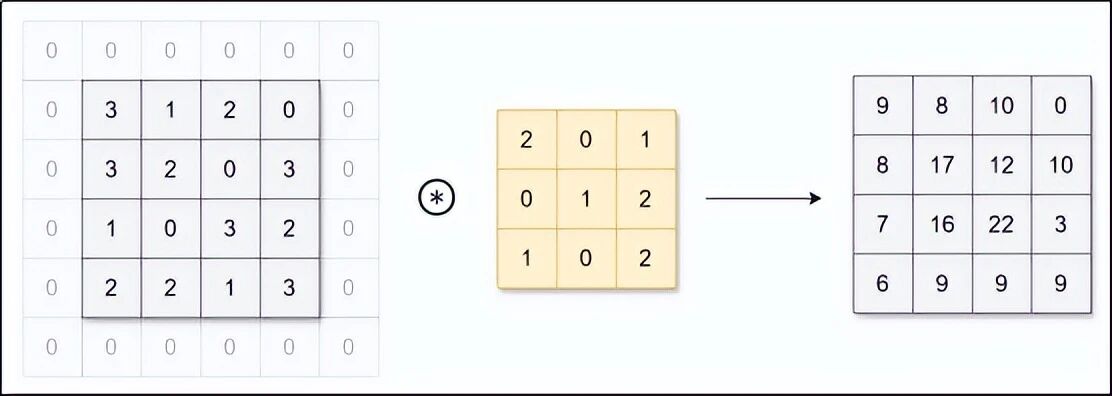
填充有两个好处:
-
控制输出尺寸
:让你可以自由决定输出是变大、变小还是不变。
-
保护边缘信息
:边缘的像素原来只被计算一次,填充后会被多次计算,信息得到更好利用。
3.3 步幅------大步走还是小步走
卷积核每次滑动的距离叫做步幅。
-
步幅 = 1
:慢慢滑,输出精细,计算量大。
-
步幅 = 3
:跳着滑,输出粗糙,计算量小。
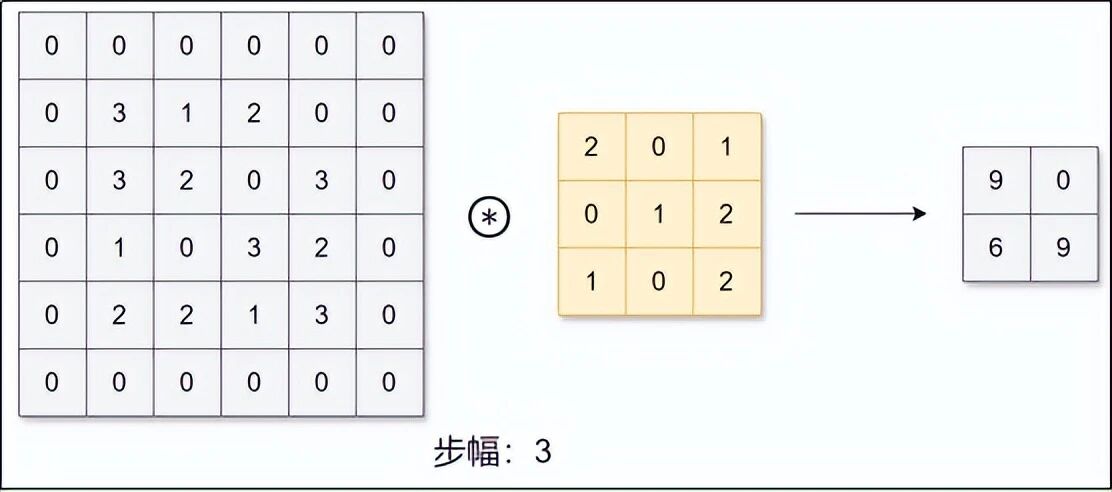
通常前几层用步幅 1,后几层或者想快速降采样时用步幅 3。
3.4 彩色图片怎么办?------多通道卷积
彩色图片有红、绿、蓝三个通道。每个通道都是一张独立的灰度图。处理彩色图片时,我们的卷积核也要"长胖"------变成三层叠在一起的立体结构。
计算时:每个通道单独做卷积,然后把三个通道的结果加起来,得到一个数字。这样就兼顾了颜色信息。
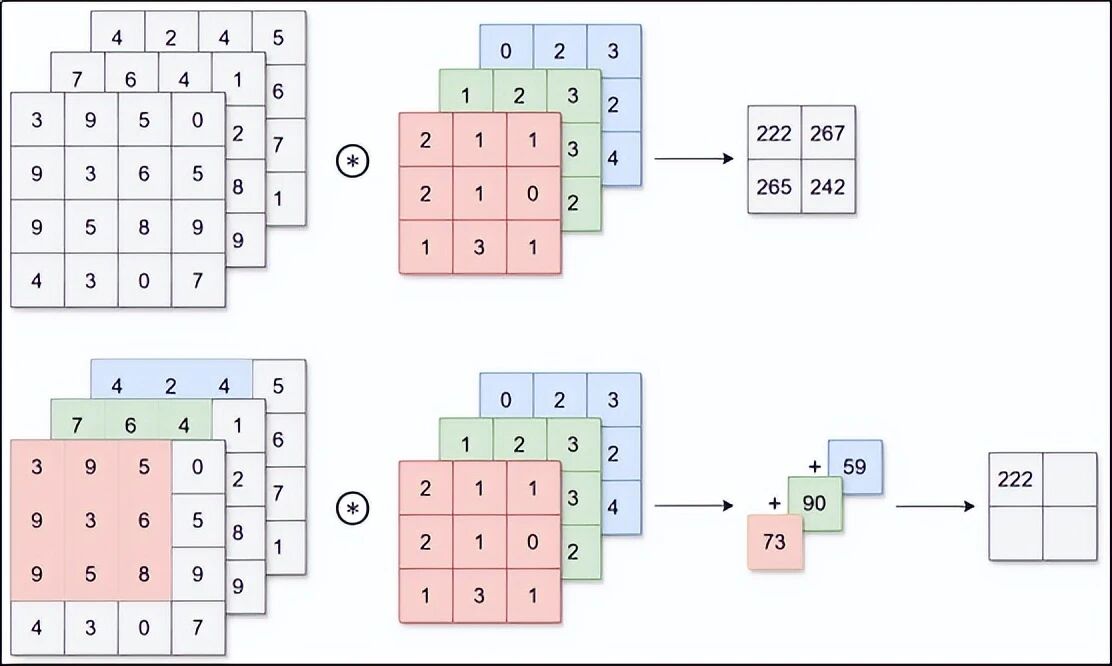
3.5 多个卷积核------同时找多种特征
一个卷积核只能找一种特征(比如"竖线")。但一张图片里有无数种特征。怎么办?多用几个卷积核。
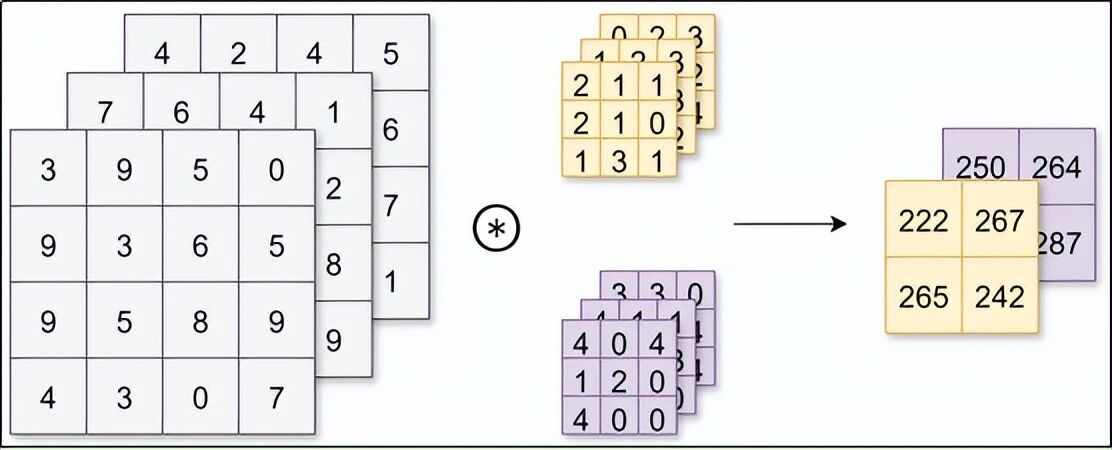
假设我们用 32 个卷积核,每个都会输出一张特征图。这 32 张特征图堆叠在一起,就形成了一个新的三维数据。下一层卷积就可以在这个三维数据上继续提取更复杂的特征。
四、池化层:压缩大师
卷积层找到了很多特征,但特征图还是太大,计算起来很慢。池化层的任务就是缩小特征图 ,同时保留最重要的信息。
4.1 最大池化------只留最亮的
最常用的是最大池化。它把特征图分成一个个小方块(比如 2×2),每个方块只保留最大的那个数,其余三个扔掉。
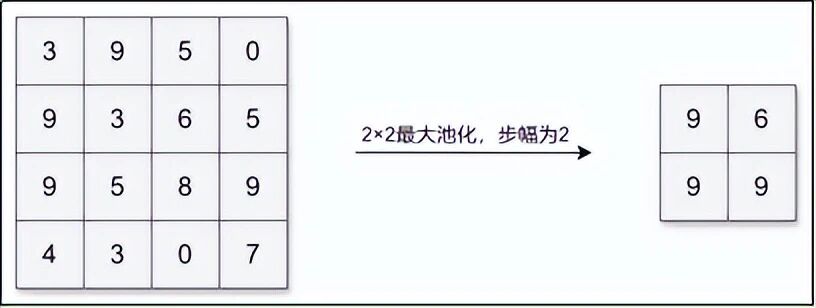
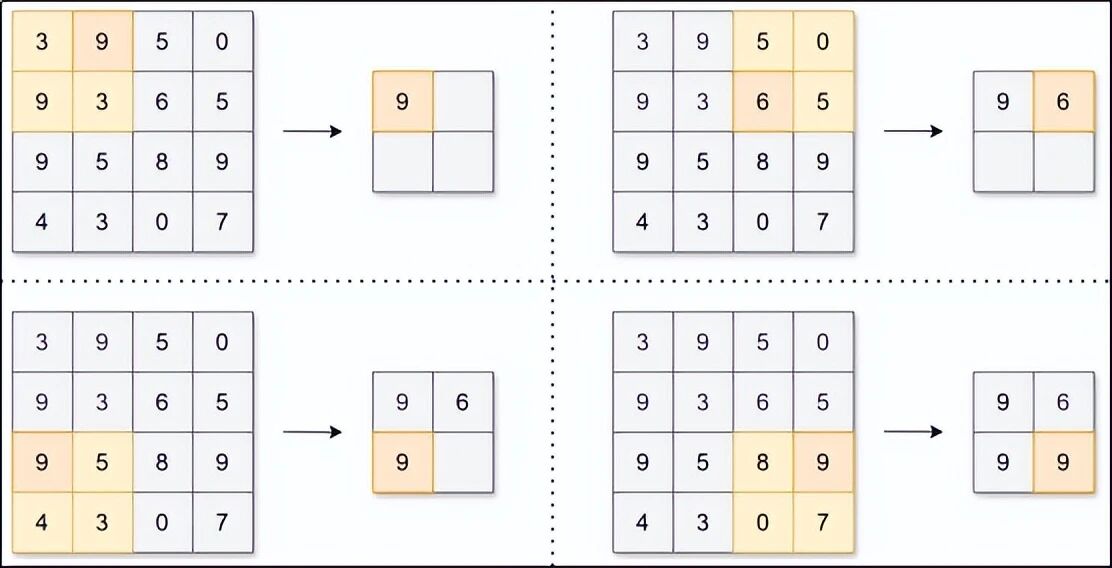
效果:图片长宽各减半,但最明显的特征(比如猫耳朵的尖角)被保留下来。
4.2 平均池化------取平均值
还有一种平均池化,它不取最大值,而是取方块里所有数的平均值。效果更平滑,但会削弱突出特征。分类任务通常用最大池化。
4.3 池化层的三个优点
-
没有参数
:不需要学习,直接按规则算,省心。
-
通道不变
:每个通道独立池化,不会混在一起。
-
对位置不敏感
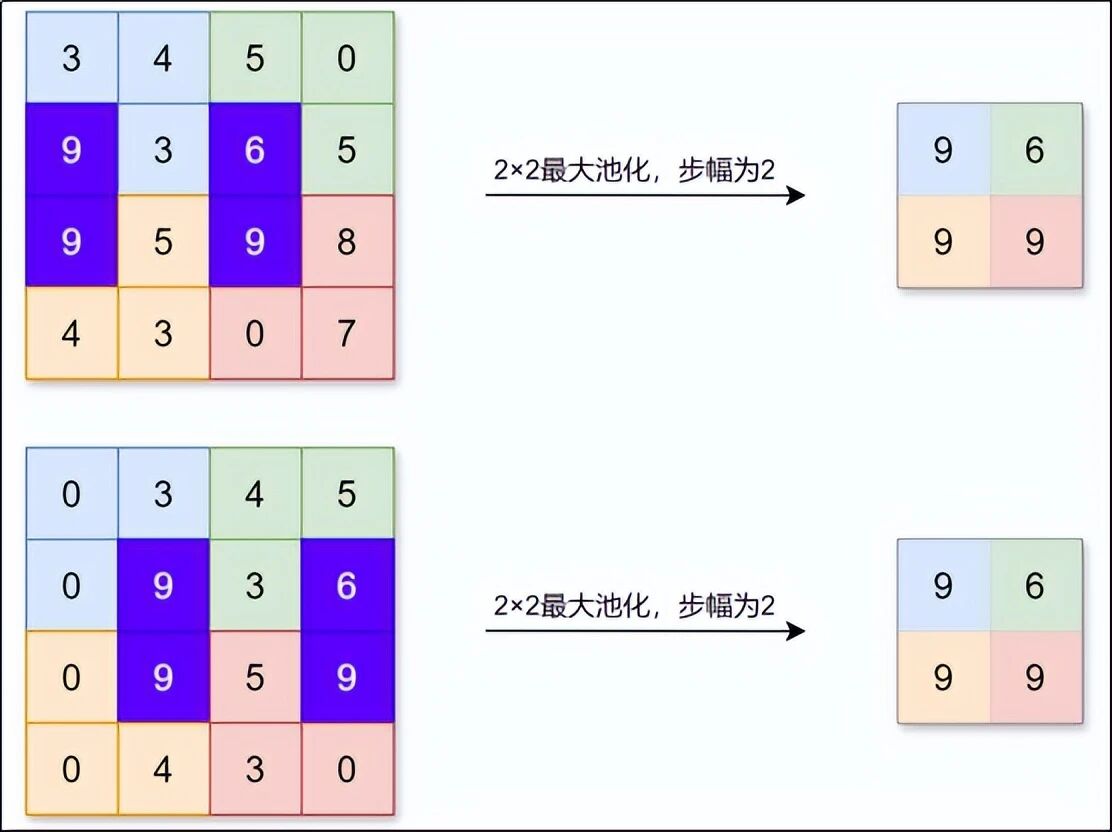
:如果猫的耳朵稍微往左偏了一点,只要还在窗口内,最大值可能不变,所以模型不会因为微小移动就认不出来。
五、激活函数------给网络注入"非线性"
卷积层输出后,通常会紧跟一个激活函数 。最常用的是 ReLU(Rectified Linear Unit)。
ReLU 超级简单:负数一律变 0,正数保持不变。
为什么需要它? 如果没有 ReLU,无论堆叠多少层卷积,最终结果还是输入的线性组合,表达能力很有限。ReLU 引入的"非线性"让网络能够学习真正复杂的模式。
另外,ReLU 计算快(只比较大小),还能让部分神经元输出 0,带来稀疏性,有助于泛化。
六、全连接层------最后拍板的"老板"
经过多轮"卷积+池化"后,图片已经被压缩成一张很小的特征图(比如 7×7×64)。全连接层的任务就是:
-
把这堆特征全部拉平成一维向量
-
通过几层普通的神经网络计算
-
最终输出一个概率分布,比如"猫:95%,狗:4%,兔子:1%"
七、完整 CNN 结构长什么样?
一个典型的 CNN 通常遵循这个模式:
输入图片
↓
[卷积 → ReLU → 池化] ← 重复 2~4 次
↓
[全连接层 → ReLU] ← 可选,1~2 次
↓
[全连接层 → Softmax] ← 输出分类结果比如识别手写数字(MNIST)的一个经典小网络:
输入 28×28 灰度图
↓
卷积层1(6 个 5×5 卷积核) → 输出 24×24×6
ReLU
池化层1(2×2,步幅 2) → 输出 12×12×6
↓
卷积层2(16 个 5×5 卷积核) → 输出 8×8×16
ReLU
池化层2(2×2,步幅 2) → 输出 4×4×16
↓
拉平 → 256 个神经元
全连接层 → 120 → ReLU
全连接层 → 84 → ReLU
全连接层 → 10(对应 0~9 十个数字)
Softmax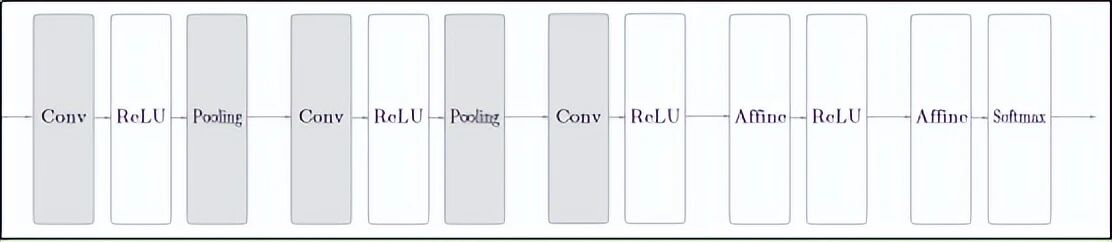
八、PyTorch 实战:从零搭建 CNN 识别手写数字
光说不练假把式。下面我们用 PyTorch 搭建一个简单的 CNN,在 MNIST 手写数字数据集上训练,实现 99% 以上的识别准确率。
8.1 安装依赖
pip install torch torchvision matplotlib8.2 完整代码(每一行都有注释)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# ---------- 1. 准备设备(有 GPU 就用 GPU) ----------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# ---------- 2. 数据预处理 ----------
# 将图片转为张量,并归一化到 [-1, 1] 范围(加速训练)
transform = transforms.Compose([
transforms.ToTensor(), # 转为 [0,1] 的张量
transforms.Normalize((0.5,), (0.5,)) # 归一化到 [-1,1]
])
# 下载训练集和测试集(第一次会自动下载)
train_dataset = torchvision.datasets.MNIST(
root='./data', train=True, download=True, transform=transform
)
test_dataset = torchvision.datasets.MNIST(
root='./data', train=False, download=True, transform=transform
)
# 数据加载器(分批、打乱)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# ---------- 3. 定义 CNN 模型 ----------
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一个卷积块:输入 1 通道(灰度),输出 16 通道,卷积核 3x3,填充 1(保持尺寸)
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.relu1 = nn.ReLU(inplace=True)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 尺寸减半
# 第二个卷积块:输入 16 通道,输出 32 通道
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.relu2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(2, 2) # 再次减半
# 第三个卷积块:输入 32 通道,输出 64 通道
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.relu3 = nn.ReLU(inplace=True)
self.pool3 = nn.MaxPool2d(2, 2) # 再次减半
# 经过三次 2x2 池化后,28x28 -> 14x14 -> 7x7 -> 3x3(因为 7/2 向下取整得 3)
# 所以特征图尺寸为 64 通道 * 3 * 3 = 576
self.fc1 = nn.Linear(64 * 3 * 3, 128) # 全连接层
self.relu_fc = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(128, 10) # 输出 10 类(0~9)
def forward(self, x):
# x 形状: [batch, 1, 28, 28]
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x) # [batch, 16, 14, 14]
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x) # [batch, 32, 7, 7]
x = self.conv3(x)
x = self.relu3(x)
x = self.pool3(x) # [batch, 64, 3, 3]
# 拉平
x = x.view(x.size(0), -1) # [batch, 576]
x = self.fc1(x)
x = self.relu_fc(x)
x = self.fc2(x) # 输出 logits(未归一化)
return x
# 实例化模型,移到设备
model = SimpleCNN().to(device)
print(model)
# ---------- 4. 定义损失函数和优化器 ----------
criterion = nn.CrossEntropyLoss() # 交叉熵损失(内部自带 Softmax)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# ---------- 5. 训练一个 epoch 的函数 ----------
def train_one_epoch(epoch_index):
model.train() # 设置为训练模式
running_loss = 0.0
correct = 0
total = 0
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 清零梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每 100 个 batch 打印一次
if i % 100 == 99:
print(f"Epoch {epoch_index+1}, Batch {i+1}: loss = {running_loss/100:.4f}")
running_loss = 0.0
epoch_acc = 100 * correct / total
return epoch_acc
# ---------- 6. 评估函数 ----------
def evaluate():
model.eval() # 设置为评估模式
correct = 0
total = 0
with torch.no_grad(): # 不计算梯度,节省内存
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return 100 * correct / total
# ---------- 7. 训练循环 ----------
num_epochs = 5
train_accs = []
test_accs = []
for epoch in range(num_epochs):
train_acc = train_one_epoch(epoch)
test_acc = evaluate()
train_accs.append(train_acc)
test_accs.append(test_acc)
print(f"Epoch {epoch+1} 结束:训练准确率 = {train_acc:.2f}%, 测试准确率 = {test_acc:.2f}%")
print("-" * 50)
print("训练完成!")
# ---------- 8. 画出训练曲线 ----------
plt.figure(figsize=(10, 5))
plt.plot(range(1, num_epochs+1), train_accs, label='训练准确率', marker='o')
plt.plot(range(1, num_epochs+1), test_accs, label='测试准确率', marker='s')
plt.xlabel('训练轮数')
plt.ylabel('准确率 (%)')
plt.title('CNN 在 MNIST 上的学习曲线')
plt.legend()
plt.grid(True)
plt.show()
# ---------- 9. 随机看几个预测结果 ----------
model.eval()
images, labels = next(iter(test_loader))
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
# 显示前 10 张
fig, axes = plt.subplots(2, 5, figsize=(12, 6))
axes = axes.ravel()
for i in range(10):
img = images[i].cpu().squeeze().numpy() # 转为 28x28 数组
axes[i].imshow(img, cmap='gray')
axes[i].set_title(f'真:{labels[i].item()} 预:{preds[i].item()}')
axes[i].axis('off')
plt.tight_layout()
plt.show()8.3 运行结果
训练 5 个 epoch 后,测试准确率通常能达到 99% 以上。你可以试着修改卷积核数量、添加 Dropout、调整学习率,观察准确率的变化。
九、CNN 训练小技巧
9.1 数据增强
如果数据量不够,可以把图片随机旋转、翻转、裁剪、调亮度,凭空变出更多训练样本。
from torchvision import transforms
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转 ±10 度
transforms.ColorJitter(0.2, 0.2), # 随机改变亮度和对比度
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])9.2 迁移学习
如果你没有几万张图片,又想用很深的网络,可以下载别人在大数据集上训练好的模型(如 ResNet),只微调最后几层。
import torchvision.models as models
model = models.resnet18(pretrained=True) # 加载预训练权重
# 冻结所有层
for param in model.parameters():
param.requires_grad = False
# 替换最后一层,适配自己的分类任务
model.fc = nn.Linear(512, 10)9.3 学习率调度
训练过程中动态降低学习率,有助于收敛到更好的位置。
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# 每个 epoch 后调用 scheduler.step()十、总结
|------------|------------|------------|
| 模块 | 作用 | 比喻 |
| 卷积层 | 提取局部特征 | 用小筛子扫描图片 |
| 激活函数(ReLU) | 引入非线性 | 把负的"过滤掉" |
| 池化层 | 缩小尺寸,增强鲁棒性 | 保留最亮的,扔掉暗的 |
| 全连接层 | 汇总特征,分类 | 拍板决策 |
CNN 之所以强大,是因为它模仿了生物视觉系统的三个特性:
-
局部感受野
(只看一小块)
-
层次化特征
(从边缘到形状到物体)
-
平移不变性
(稍微移动也能认出来)
掌握了这些核心思想,你就能看懂几乎所有 CNN 变种(ResNet、Inception、MobileNet 等)。它们无非是在这三块积木的基础上,加了跳跃连接、分组卷积、注意力机制等"高级玩法"。
最后送你一句话:理解 CNN 最好的方式不是死记公式,而是动手跑代码、改参数、观察结果。快去试试吧!