(一).CAS
1.概念
CAS(Compare And Swap),表示"比较和交换",是一条CPU的指令,这就导致了CAS指令是一个原子的。
java
boolean CAS(address, expectValue, swapValue) {
if (&address == expectedValue) {
&address = swapValue;
return true;
}
return false;
}上述的代码就是CAS的一个伪代码,实际上是一条指令。
第一个参数表示"内存地址",第二个参数表示"寄存器1"的值,第二个参数表示"寄存器2"的值
CAS就是进行判断,判断"内存地址"的值和"寄存器1"的值是否相等,如果相等则将"寄存器2"的值和"内存地址"进行交换,但是由于基本上只关心交换后"内存地址"中的值,而不关心"寄存器2"的值,所以此处就可以将这样的操作理解成"赋值",本质上是交换,基于交换实现了赋值
CAS本质上是CPU指令,操作系统就会把这个指令进行封装,提供一些api,就可以在C++中调用了,JVM又是基于C++实现的所以JVM也能够使用C++第哦啊用这样的CAS操作

2.用途
(1).实现原子类
Ⅰ.概念
java
public static int count=0;
public static void main(String[] args) throws InterruptedException {
Object locker=new Object();
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
}在上面的例子中,我们通过加锁来破坏原子性,从来保证了线程的安全。但是,现在又认为加锁的效率比较低,于是就可以通过CAS中的原子类来实现count++,以确保性能,同时保证线程安全
原子类在java.util.concurrent.atomic包底下
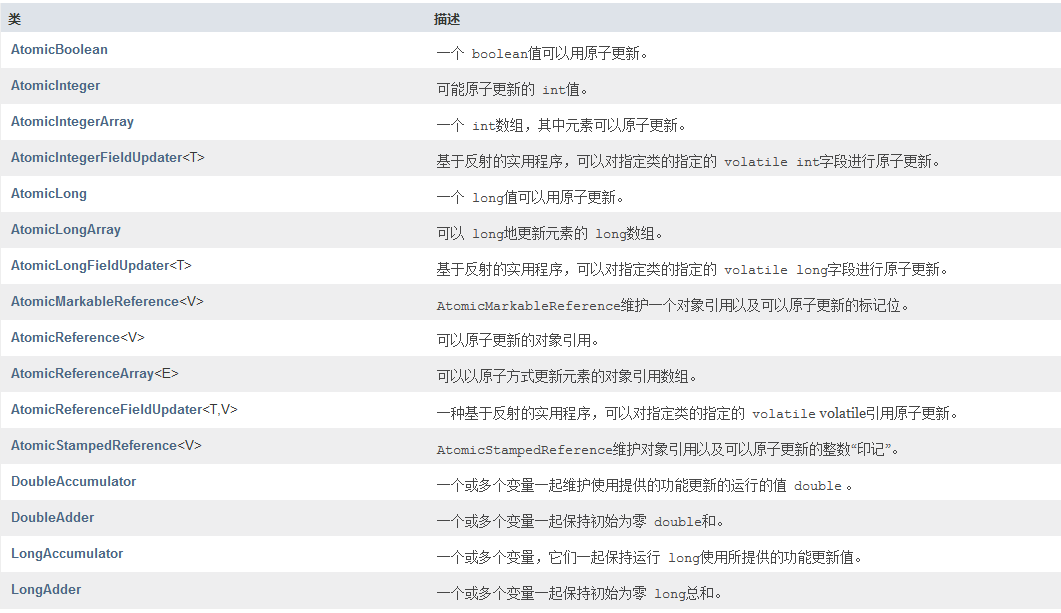
原子类主要是用于多个线程同时修改一个变量
java
//基于"CAS"实现"原子类",避免加锁
public static AtomicInteger count=new AtomicInteger(0); //初始值为0
public static void main(String[] args) throws InterruptedException {
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.getAndIncrement();//AtomicInterger是一个原子类,所以使用引用对象的时候要通过.的方式
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.getAndIncrement();
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
}getAndIncrement()等价于count++
incrementAndGet()等价于++count
addAndget(n)等价于count+=n
Ⅱ.AtomicInteger伪代码
java
class AtomicInteger {
private int value;
public int getAndIncrement() {
int oldValue = value;
while ( CAS(value, oldValue, oldValue+1) != true) {
oldValue = value;
}
return oldValue;
}
}oldValue就是"寄存器",Java没有寄存器的使用,所以这里由int代替
getAndIncrement()就相当于自增的操作,首先先使用CAS指令,判断value内存和oldValues寄存器1的值是否相同如果相同则将oldValues+1"寄存器2"的值赋值给values,然后返回true,然后进行判断true!=true,所以不成立,然后返回oldValue,即返回自增前的值,此时oldValue为0,value为1
下图是在多线程的视角

(2).实现自旋锁
java
public class SpinLock {
private Thread owner = null;
public void lock(){
// 通过 CAS 看当前锁是否被某个线程持有.
// 如果这个锁已经被别的线程持有, 那么就⾃旋等待.
// 如果这个锁没有被别的线程持有, 那么就把 owner 设为当前尝试加锁的线程.
while(!CAS(this.owner, null, Thread.currentThread())){}
}
public void unlock (){
this.owner = null;
}
}对于owner,如果null,那么锁就是空闲的,如果不为null,那么锁已经被某个线程给占有了
java
while(!CAS(this.owner, null, Thread.currentThread())){}对于这行代码,是实现自旋锁的核心逻辑代码。首先,先判断owner是否和null相等,如果相等,则就将当前线程的引用设置到owner中,如果owner和null不相等,那么就一直在while()循环中循环,即自旋效果。发现锁被占用,CAS不会执行交换,而是返回false。进入循环,再进行下一次的判定,由于循环体是空着的,所以整个循环速度非常快(忙等),但是一旦其他线程释放了锁,那么此线程就能第一时间拿到锁
3.CAS的缺陷
(1).缺陷原因
使用CAS确实能够保证线程安全,其核心就是先比较是否相等,即内存和寄存器是否相等。判断内存和寄存器是否相等,本质上就是在判定是否有其他线程插入进行做了一些修改。如果发现寄存器和内存的值一致,就可以任务是没有现成穿插过来修改的,因此接下来的修改操作就是安全的。但是这里有一个问题,就是改了又改回去 。本来判定内存中的值是否为A,发现是A,说明没有线程改过,但是可能会存在一种情况,另一个线程从A改成了B,然后又从B改成了A。我们称上述问题为ABA问题。(汤老师取钱)
(2).解决方案
我们可以使用"版本号"来进行解决。此时,约定这个"版本号"只能加不能减,那么就可以有效的避免ABA问题
(二).JUC组件
1.概念
JUC 组件,指的是java.util.concurrent包里面的一些和多线程相关的工具
2.相关组件
(1).Callable接口和FutureTask类
Callable接口和Runnable接口属于并列的关,同时Callable接口支持泛型。我们使用Runnable任务的时候,需要重写里面的run()方法;当我们使用Callable任务的时候,我们需要重写里面的call()方法,并且call()方法是有返回值的,返回值的类型就是我们所写的泛型类型
示例
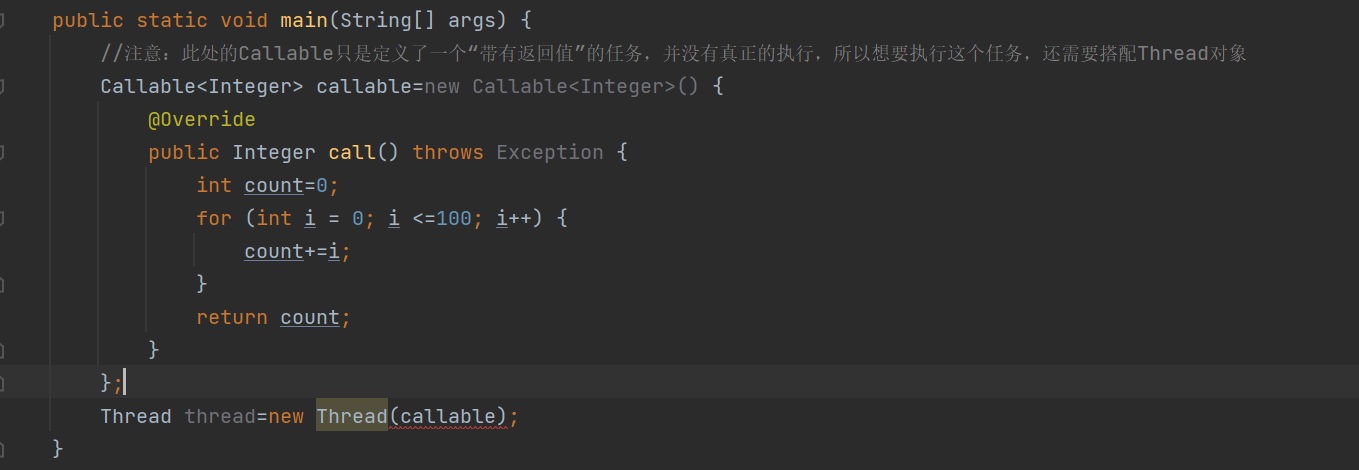
通过图片中代码,可以看到,报错了。
这是因为Thread的构造方法没有提供传入Callable的对象
所以这个时候,我们就需要借助FutrueTask类了
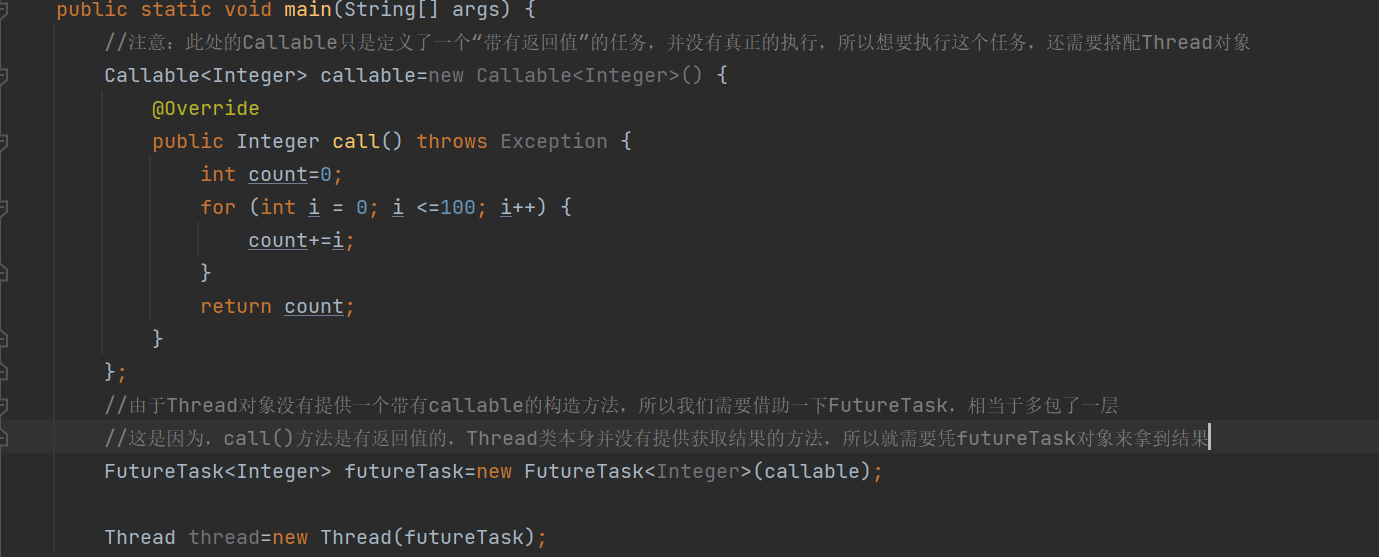
Thread本身不提供获取结果的方法,所以就需要凭借FutureTask对象来拿到结果集
这样做的目的是为了"解耦合",Thread类就是线程,希望和"任务"这个概念剥离开,更不希望关心任务是什么样的任务,也不希望关心是否有返回值
java
public static void main(String[] args) throws ExecutionException, InterruptedException {
//注意:此处的Callable只是定义了一个"带有返回值"的任务,并没有真正的执行,所以想要执行这个任务,还需要搭配Thread对象
Callable<Integer> callable=new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int count=0;
for (int i = 0; i <=100; i++) {
count+=i;
}
return count;
}
};
//由于Thread对象没有提供一个带有callable的构造方法,所以我们需要借助一下FutureTask,相当于多包了一层
//这是因为,call()方法是有返回值的,Thread类本身并没有提供获取结果的方法,所以就需要凭futureTask对象来拿到结果
FutureTask<Integer> futureTask=new FutureTask<Integer>(callable);
Thread thread=new Thread(futureTask);
thread.start();
//get()操作就是获取到futureTask的返回值,这个返回值来自于Callable的call()方法
//get()方法可能会发生阻塞,如果当前线程执行完毕,get()就会拿到返回结果
//如果当前线程没有执行完毕,get()就会一致阻塞
System.out.println(futureTask.get());
}总结
创建线程的方法
①.继承Thread类(定义单独的类/匿名内部类)
②.实现Runnable接口(定义单独的类/匿名内部类)
③.通过lambda表达式
④.实现Callable接口(定义单独的类/匿名内部类)
⑤.使用线程池 ThreadFactory
(2).ReentrantLock
可重入锁,和synchronized是并列的关系
synchronized和ReentrantLock的区别
①.synchronized是关键字(内部实现是JVM内部通过C++,实现的),ReentrantLock是标准库的类,由Java实现的
②.synchronized是通过代码块控制加锁解锁,Reentrantlock是通过lock()和unlock()方法来控制加锁和解锁
③.ReentrantLock除了提供lock()和unlock()方法之外,还提供了tryLock()方法,用来判断是否加锁成功,如果成功,则返回true,如果失败,返回false,不会发生阻塞。同时tryLock()还提供了设置超时时间的版本,等待时间达到超时时间之后再返回true或者false
④.ReentrantLock默认是非公平锁,但是ReentrantLock提供了公平锁的实现
⑤.ReentrantLock搭配的等待通知机制是Condition类,相比wait()和notify()来说,功能更强大一些
示例
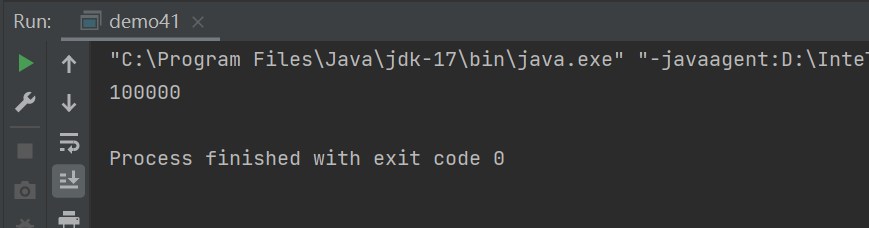
java
public static int count=0;
public static void main(String[] args) throws InterruptedException {
ReentrantLock reentrantLock=new ReentrantLock();
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
reentrantLock.lock(); //加锁
count++;
reentrantLock.unlock(); //解锁
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
reentrantLock.lock();
count++;
reentrantLock.unlock();
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
}
(3).信号量 Semaphore
Ⅰ.概念
信号量,类似于一个计数器,描述了某种可用资源的个数。信号量能够协调多个进程之间的资源费配,也能协调多个线程之间的资源分配
信号量在申请资源(P操作)的时候,计数器就会-1,释放资源(V操作)的时候就会+1,当计数器为0的时候,再申请就会阻塞等待,相当于"锁"的更广泛的推广
在java中,acquire()方法就相当于申请资源,release()方法就相当于释放资源
Ⅱ.示例
①.
java
public static void main(String[] args) throws InterruptedException {
//信号量 可用资源是"4"个
Semaphore semaphore=new Semaphore(4);//计数器的初始值
semaphore.acquire();
System.out.println("申请第一个资源");
semaphore.acquire();
System.out.println("申请第二个资源");
semaphore.acquire();
System.out.println("申请第三个资源");
semaphore.acquire();
System.out.println("申请第四个资源");
}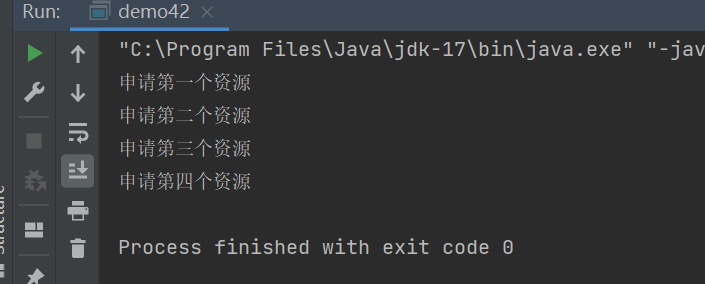
可以看到Semaphore中有四个资源,我们申请了四次,四次都申请下来了
②.
java
public static void main(String[] args) throws InterruptedException {
//信号量 可用资源是"3"个
Semaphore semaphore=new Semaphore(3);//计数器的初始值
semaphore.acquire();
System.out.println("申请第一个资源");
semaphore.acquire();
System.out.println("申请第二个资源");
semaphore.acquire();
System.out.println("申请第三个资源");
semaphore.acquire();
System.out.println("申请第四个资源");
}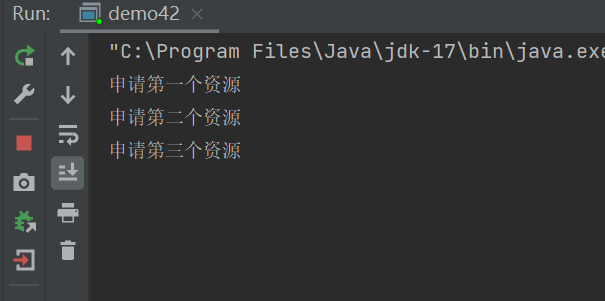
可以看到,Semaphore中的可用资源有3个,但是申请了4次,在申请第四次的时候,发生了阻塞等待
③.信号量的特殊情况,将信号量的可用资源数设置为1,即取值要么是1,要么是0,此时就等价于"锁"
java
public static int count=0;
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore=new Semaphore(1);
Thread thread1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
try {
semaphore.acquire();//申请资源
count++;
semaphore.release();//释放资源
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread thread2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
try {
semaphore.acquire();//申请资源
count++;
semaphore.release();//释放资源
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(count);
}(4).CountDownLatch
Ⅰ.概念
在进行多线程编程的时候,经常会把一个大的任务拆分成多个子任务,然后通过多线程执行这些子任务,从而提高程序的效率。
我们可以通过CountDounLatch类来衡量这多个子任务是否都完成了,从而判断整个任务是否都完成了
Ⅱ.思路
①.通过构造方法指定参数,描述拆成了多少个任务,例如拆成10个子任务
②.每个任务执行完毕之后都调用一次countDown方法,当调用了10次countDown()方法之后,表示所有的子任务都执行完毕了
③.主线程中调用await()方法,等待所有任务执行完毕之后await()就会返回,否则就会阻塞等待
Ⅲ.示例
java
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch=new CountDownLatch(10); //表示任务的个数
ExecutorService threadPool = Executors.newFixedThreadPool(4);//创建四个线程
for (int i = 0; i < 10; i++) {
int id=i;
threadPool.submit(()->{
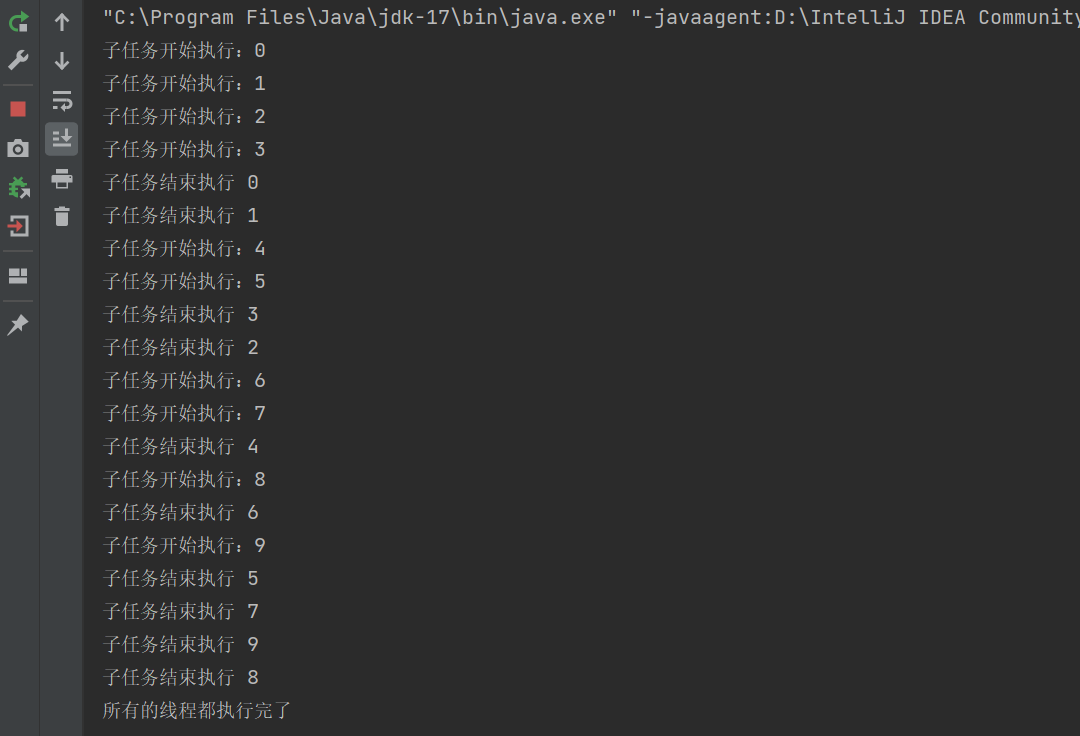
System.out.println("子任务开始执行:"+id);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("子任务结束执行 "+id );
countDownLatch.countDown();
});
}
//等待所有的任务都结束
countDownLatch.await();
System.out.println("所有的线程都执行完了");
}
(三).线程安全的集合类
1.多线程下使用ArrayList
(1).自行加锁推荐
只需要分析清楚加锁的情况,要把哪些代码打包在一起,成为一个"原子"操作
(2).Collections.synchronizedList(new ArrayList)
这个相当于给ArrayList套了层壳,返回的List的所有的关键方法都带有synchronized
(3).使用CopyOnWriteArrayList
Ⅰ.概念
写时拷贝,不需要加锁,当我们要进行写操作时,不是在原来的ArrayLsit上进行修改,而是先拷贝一份,在拷贝的那一份上进行修改,当修改结束之后,再将原数组的引用指向拷贝的这份数组上
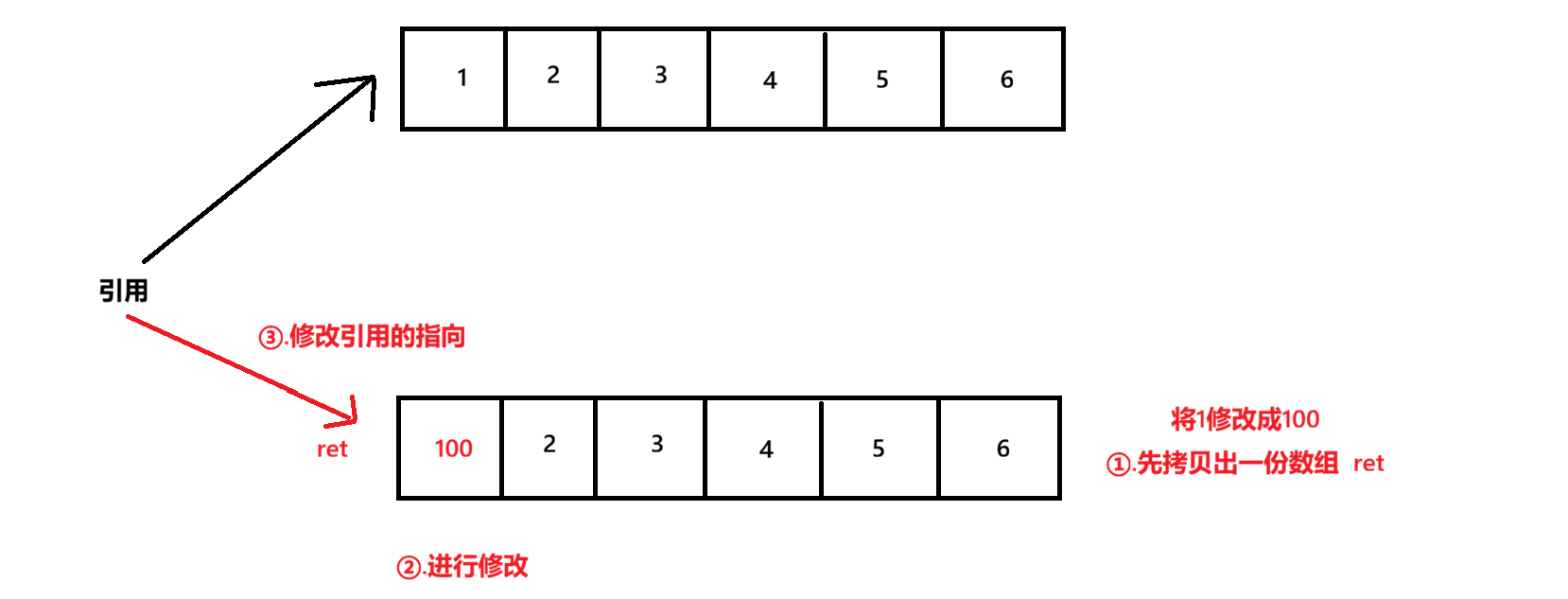
再拷贝数组的过程中,如果有其他线程在读,就直接读取旧版本的数据
虽然在拷贝的过程中,不是原子的,但是由于提供了就把呢不能的数据,不影响其他线程的读取,新版本数据拷贝完毕后,直接进行引用的修改
注意:整个过程中都没有加锁,所以不会涉及到阻塞
Ⅱ.优点
适用于特定的场景,例如,服务器进行重新加载配置
服务器正在运行,当需要进行修改的时候,正常来说,修改配置文件之后,不能够立即生效,需要重启一下服务器。很多服务器也会提供配置重加载(reload)。配置就是被读取到服务器的内存中,以数组/哈希来存储,服务器代码中的其他逻辑就会读取这些数组/哈希中的值,此时程序员手动修改配置文件之后,手动触发reload功能,服务器就会创建新的数组/哈希,加载新的配置,加载完毕之后,使用新配置代替旧配置
Ⅲ.缺点
①.当数组特别大的时候,非常低效
②.如果多个线程同时修改,也会出现问题
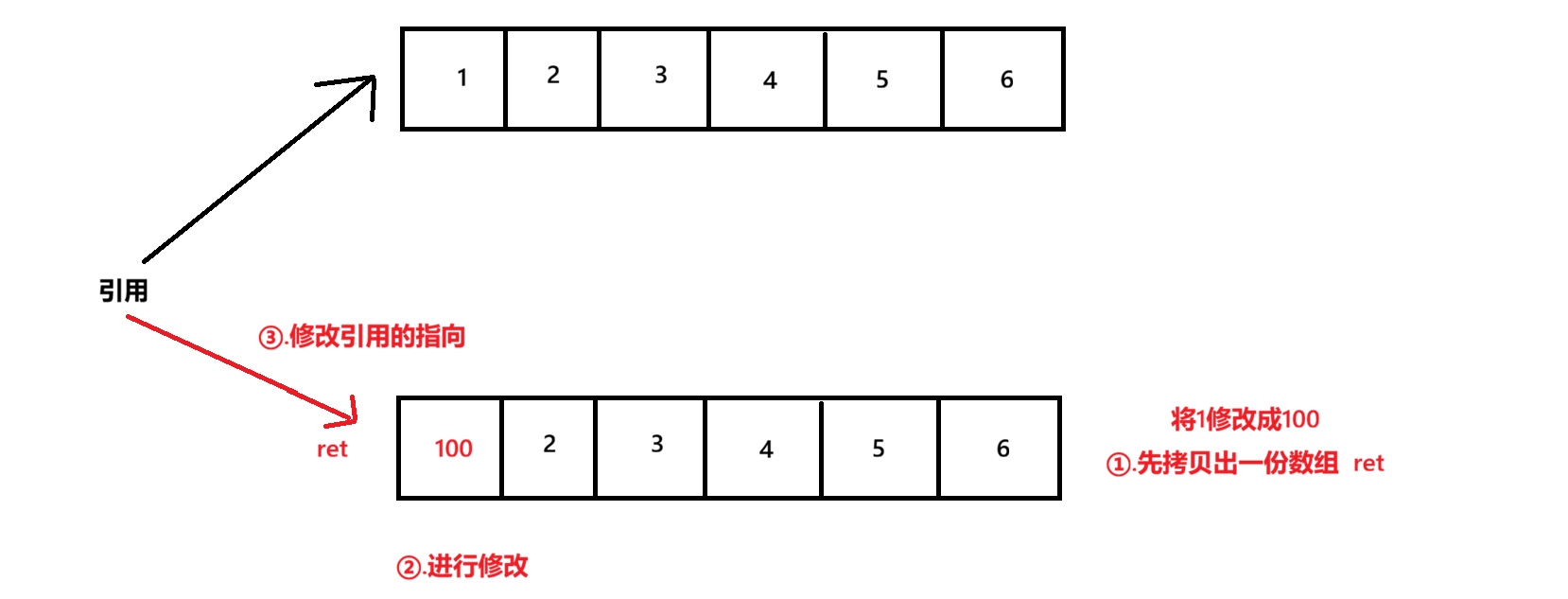
例如,如果第一个线程修改前三个数据,第二个线程修改后三个数据,那么此时就会出错,可能最后引用指向了第二个线程修改后的数组,那么就不一定确保前三个数据被完整的修改
2.多线程下使用阻塞队列
这个在前面介绍过
①.ArrayBlockingQueue 基于数组实现的阻塞队列
②.LinkedBlockingQueue 基于链表实现的阻塞队列
③.PriorityBlockingQueue 基于堆实现的带有优先级的阻塞队列
④.TransferQueue 最多只包含一个元素的阻塞队列
3.多线程下使用哈希表
(1).HashMap
线程不安全
(2).HashTable
虽然是线程安全的,但是不建议使用,因为HashTable是给所有public修饰的方法都加入了synchronized,这样会导致效率低
(3).ConCurrentHashMap
Ⅰ.介绍
效率更高,按照桶级别进行加锁
要介绍清除ConCurrentHashMap,还是要先通过HashTable进行入手
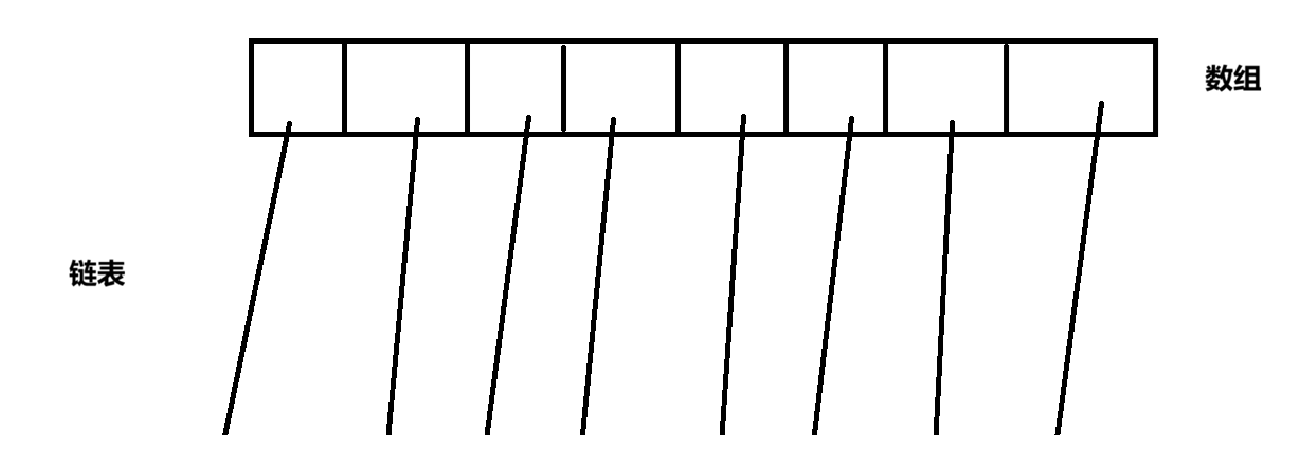
这是HashTable的构造
此时任意两个线程访问任意的两个不同元素,都会产生"锁竞争"
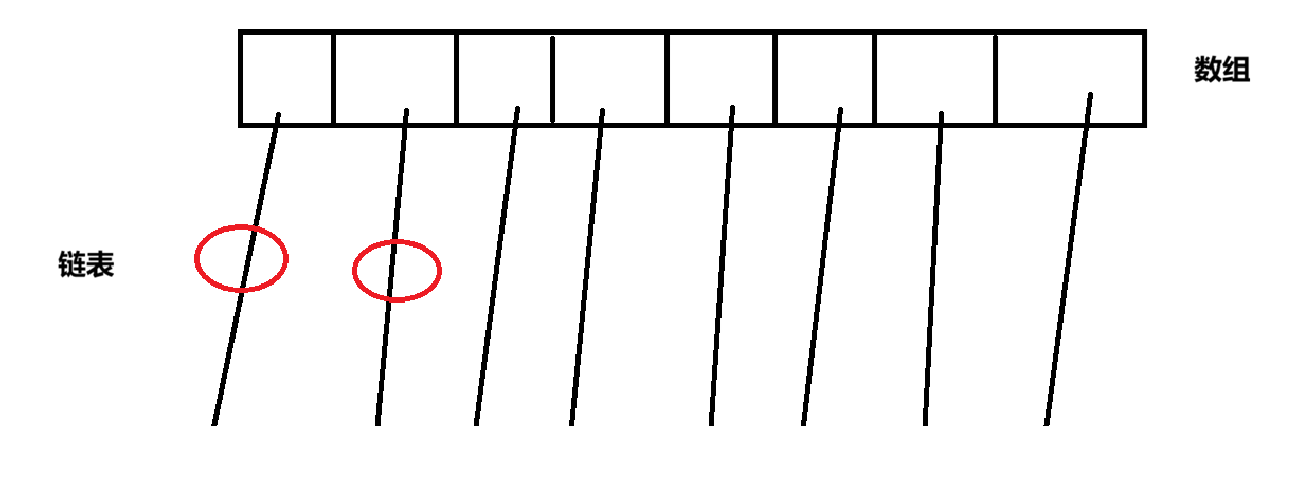
如上图所示,此时就会出现"锁竞争",但是如果修改的两个元素在不同的链表上,那么本身就不会涉及到线程安全问题
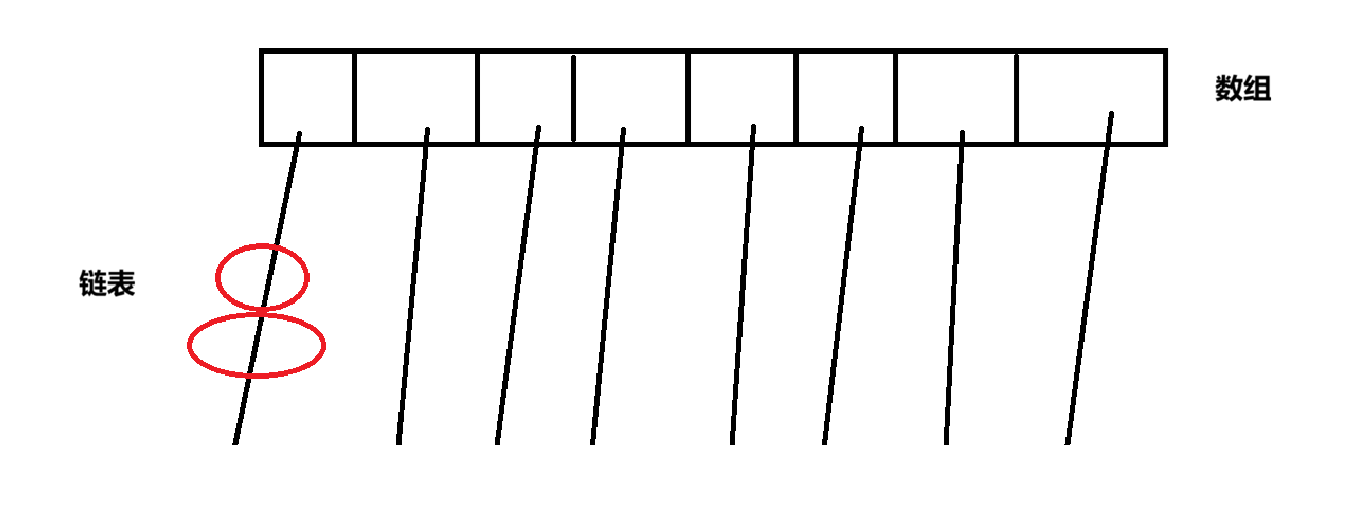
如果修改的是同一个链表上的两个元素,可能会出现线程安全问题,例如两个元素查到同一个元素的后面就可能出现锁竞争
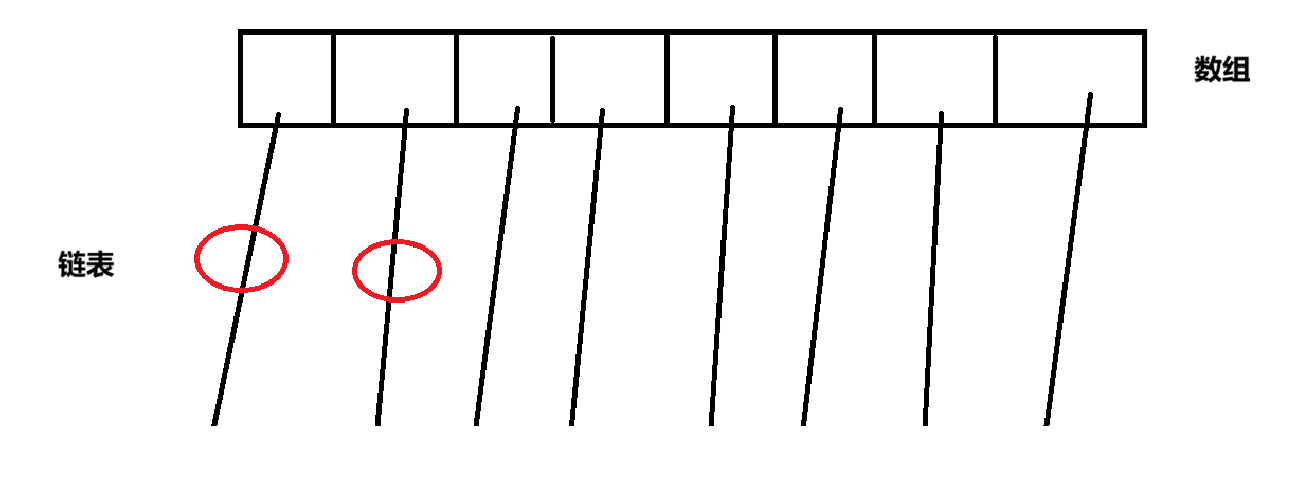
但是,这种情况下是不涉及到线程安全的,所有此时就可以进行优化,使用ConCurrentHashMap
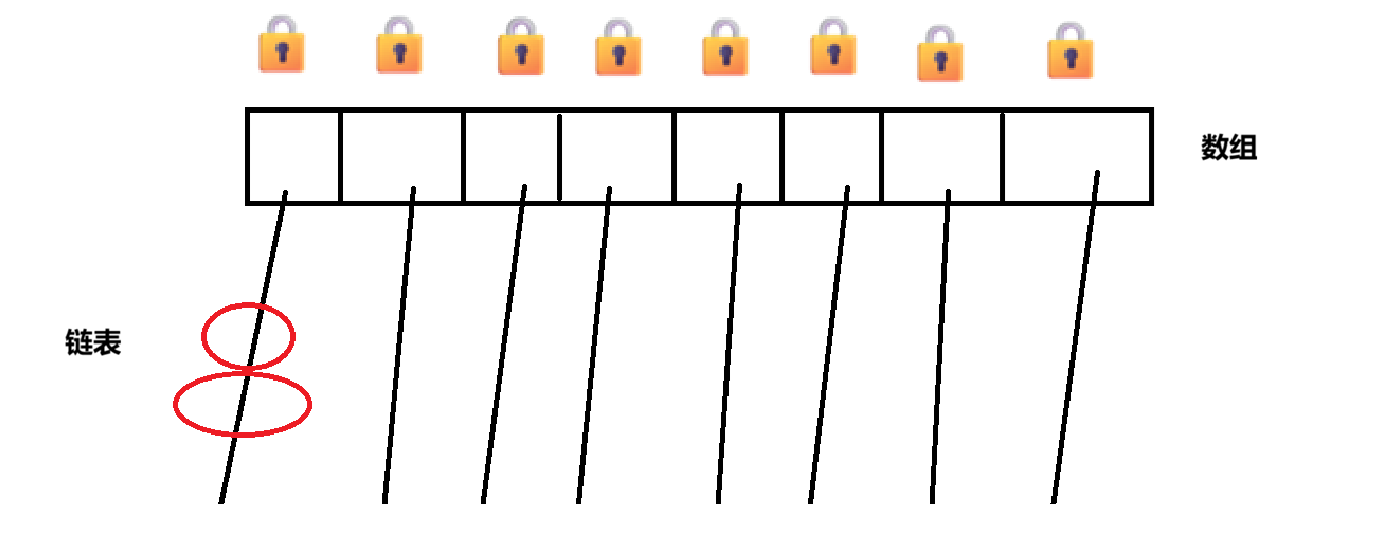
ConCurrentHashMap是针对不同的对象进行加锁,此时就不会产生锁竞争的问题了
ConCurrentHashMap的时间开销相对于HashTable来说肯定是低,但是再怎么低也不可能比HashMap低,因为HashMap是线程不安全的,不需要锁。对于空间开销,其实还好。直接使用每个链表的头节点作为synchronized的锁对象即可
Ⅱ.问题
①.size问题
当一个链表插入元素,另一个链表也插入元素的时候此时这个size()就不好计算了,那么这个时候就可以引入我们上面介绍过的原子类来解决问题
②.扩容问题
扩容操作,采用了"化整为零"的方式来解决。一下子全部扩容会很耗时,所以把整个扩容的过程拆分成多次来完成,一旦触发扩容,不是通过一次put来完成,而是通过多次的put/get等操作来完成的
Ⅲ.ConCurrentHashMap的核心优化点
①.把锁整个表优化成了锁桶
②.使用"原子类"针对size进行维护
③.正对哈希扩容的场景,化整为零,确保每个操作的加锁时间不要太长