2.3 必备易懂的 RL (强化学习) 基础
这里我们不系统讲解强化学习复杂的理论,而是通过讲个通俗的故事,带大家快速了解大模型训练中所涉及的核心强化学习知识 。
(如果你想系统深入地学习 RL,推荐参考西湖大学强化学习视频课程或"动手学强化学习"文字教程 )
大模型训练(特别是 RLHF 阶段)通常涉及四个主要模型,它们各司其职 :
Actor Model (演员模型):这就是我们想要训练的最终目标语言模型 。
Critic Model (评论家模型):它的作用是预估预期收益 。
Reward Model (奖励模型):它的作用是计算实际收益 。
Reference Model (参考模型):它的作用是给语言模型增加一些约束,防止语言模型"训歪",确保模型的回答分布最好与之前的 SFT (有监督微调) 模型相近 。
接下来,我们用一个班级考试的故事来带大家入门,对以上几个干瘪的名词建立生动的概念 。
2.3.1 Reward (奖励)
小明和小雅是同班同学,每次考试会得到一个分数 。老师按"考试分数"发奖励 (Reward):考多少分,就发多少颗星星,星星能换文具 。
小明基础好,总考 80 分;小雅起步慢,常考 30 分 。
如果只看绝对分数,问题很快来了 :
-
小雅发奋图强考到了 60 分,进步巨大,却只能拿到 60 颗星,比小明的 80 颗还要少得多,慢慢地她就没了干劲 。
-
小明这边也很纠结:为了冲刺 100 分拿满星,他一会儿熬夜刷题,一会儿瞎蒙答案,导致分数忽高忽低,星星数也时多时少 。
💡 概念对应 :
- Actor (执行者) 是小明和小雅,他们是"做动作"的主体,努力学习是为了提高分数 。
- Reward (奖励) 是星星,是对他们"动作结果"的直接反馈 。
只看 Reward 奖励进行学习的话,既不鼓励后进生的进步,又容易让人为了高分走极端 。这就是强化学习里常说的"单靠奖励优化会有高方差"的问题 。
2.3.2 Critic (评论家)
班主任王老师看出了问题,于是给两人各定了一条"预期分数线":小明的线是 80 分,小雅的线是 40 分 。
王老师宣布新规则:"超过自己的线,多 1 分多 1 颗星;没超过,就算考 60 分也没星。"
这下小雅眼睛亮了:从 30 分提高到 60 分,超了基准线 20 分,一口气拿到 20 颗星!而小明虽然考了 85 分,但只超了 5 分,反而拿得少 。
更妙的是,王老师会定期调线:小雅稳定在 60 分后,线就提高到 60 分;小明总考 85 分,线就微调成 83 分 。
💡 概念对应 :
- Critic (评估者) 就是王老师 。它的核心作用是给每个 Actor 定"基准线"(预期分数),用"实际分数减去基准线"来算出"真正的进步" 。
有了 Critic,奖励不再死板地只看绝对结果,而是看"超越自身预期的部分"。这种方式既公平又稳定,这就是强化学习里"Critic 能降低方差"的核心价值 。
2.3.3 Clip (截断):别让进步太冒进
平静了一阵后,新问题又冒出来了:有一次考试,小明超常发挥,答对了超难的附加题考了 95 分,超了基准线 15 分,拿到了 15 颗星 。他尝到了甜头,下次考试决定直接放弃稳妥的基础题,专攻最难的附加题。结果不幸考砸,只得了 60 分,星星瞬间归零 。
王老师见状,赶紧打补丁加了条规则:"超过基准线的部分,最多按 10 分算。"(即比如超了 15 分也只给 10 颗星,超 8 分就正常给 8 颗) 。
💡 概念对应:
这招在强化学习里叫 "Clip (截断)" 。它既不打击进步热情,又不让人瞎冒险,完美控制了 Actor 更新学习策略时的"步幅",防止模型彻底崩坏 。
2.3.4 Reference (参考模型)
日子久了,王老师又发现一个 bug:小明偶尔考了 90 分,基准线就会立刻跟着上调。这导致他下次即便考了很不错的 88 分,也会因为没达到新基准线而拿不到星,非常打击信心 。
于是老师又加了一个参考维度:"除了当前的基准线,还要和你上周的平均成绩比。" 比如小明上周平均 85 分,这次考了 88 分,就算当前基准线已经被调到了 86 分,只要比上周的平均水平高,也能多拿 2 颗星保底 。
💡 概念对应 :
- Reference (参考者) 就是"上周平均成绩" 。它记录着 Actor 过去的原始水平。用"现在的表现"对比"过去的自己",能避免基准线波动太频繁,让进步的标准更加平稳可控 。
2.3.5 总结:一场考试讲透 RL
在这场考试博弈里,每个角色都有自己明确的活儿 :
Actor (小明、小雅):负责"做事"(参加考试),通过不断调整自己的学习方法(策略)去争取更好的结果 。
Reward (星星):给结果打分,直接告诉 Actor"这样做对不对" 。
Critic (王老师的基准线):算清到底"进步了多少",给 Actor 划定一个合理的努力目标 。
Reference (上周平均成绩) :锚定历史水平,兜底保障,让进步的标准更稳定 。
强化学习的本质,其实就是让"做事的人 (Actor)"在外部的"反馈 (Reward)"中,跟着"评估者 (Critic)"的指引,同时时刻参考"过去的自己 (Reference)",慢慢找到最稳、最优的进步方式 。就像故事里的小明和小雅,最终都在最适合自己的节奏里,越学越好 。
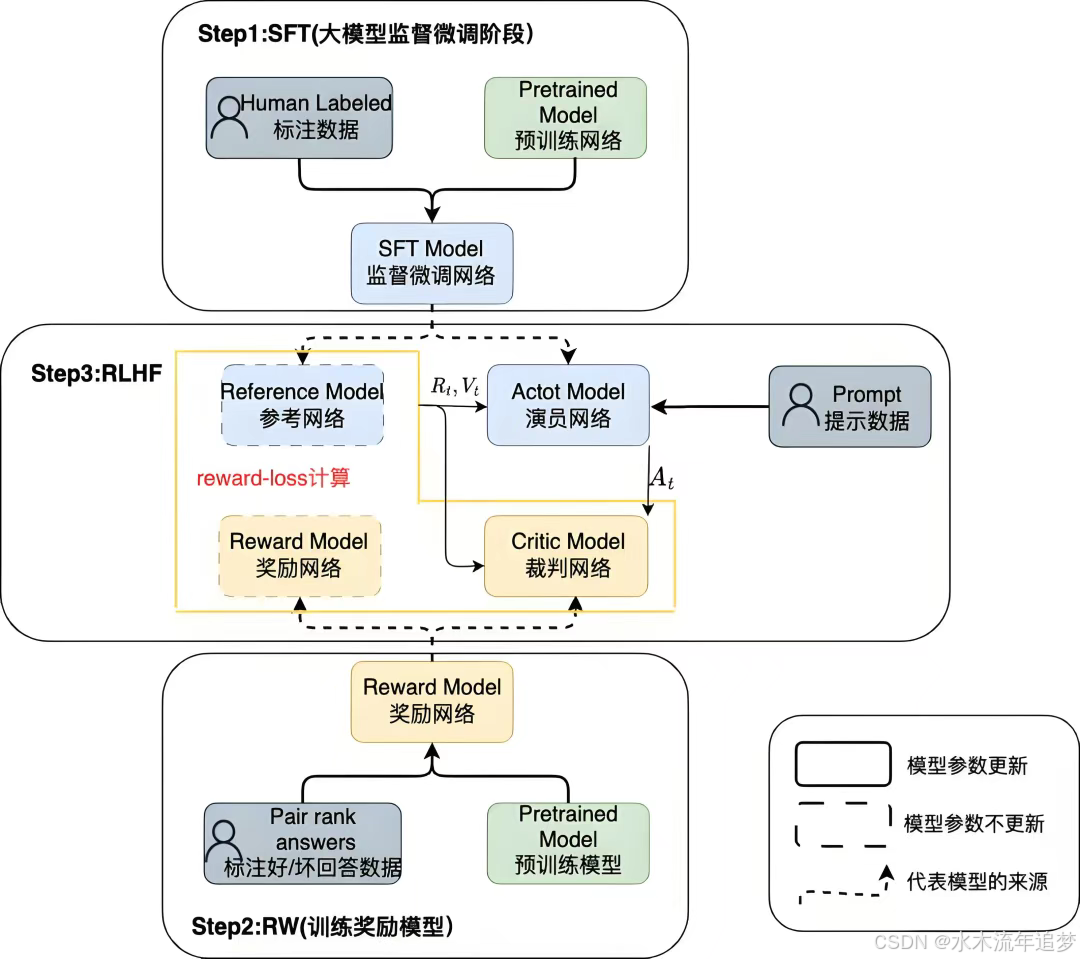
附:大模型 RLHF 训练三阶段逻辑关系图解
为了更好地将上述故事对应到实际的大模型工程中,以下是 RLHF 训练的三个标准步骤:
- Step 1: SFT (大模型监督微调阶段)
- 基于 Pretrained Model (预训练网络) 和 Human Labeled (人工标注数据),训练出 SFT Model (监督微调网络) 。
- Step 2: RW (训练奖励模型)
- 基于预训练模型,使用标注好的好/坏回答对比数据 (Pair rank answers),训练出能够打分的 Reward Model (奖励网络) 。
- Step 3: RLHF (强化学习对齐)
-
输入 Prompt (提示数据) 后,Actor Model (演员网络) 生成回答(动作 AtA_tAt)
-
Critic Model (裁判网络) 和 Reward Model (奖励网络) 协同计算出 reward-loss 来引导模型更新 。
-
同时,Reference Model (参考网络) 提供 Rt,VtR_t, V_tRt,Vt 约束,防止 Actor 模型为了追求高分而彻底偏离原有的正常说话方式 。

python
print('hello world')