前言
什么是 Vibe Coding?
2025 年初,随着大模型能力的跃迁和本地执行能力的增强,一种几乎"零门槛"的开发方式迅速走红------ Vibe Coding。
Vibe Coding 的本质是"通过对话迭代,将模糊的需求逐步变成实际产品",在这种模式下,开发者不再像传统工程那样先设计架构、拆解需求、定义接口,而是:
- 通过自然语言向 AI 描述一个"模糊目标"
- 依赖 AI(如大模型)快速生成代码
- 根据运行效果不断"微调感觉"(vibe)
- 通过多轮对话逐步逼近结果
一个典型的例子如下:
- 帮我写一个文件上传组件,要支持拖拽和进度条。
- 再加个失败重试功能
- 顺便支持下图片预览能力
- 这个 UI 不太对,直接使用 antd 的组件。
可以看到,这种模式有几个显著特征:
- 弱约束:没有严格的输入输出定义
- 高交互:依赖多轮 prompt 迭代
- 即时反馈:强调快速看到结果
- 上下文驱动:高度依赖当前对话语境
为什么 Vibe Coding 爆火?
Vibe Coding 的流行并不是偶然,它解决了传统开发中的几个核心痛点:
-
极低的启动成本
不需要设计文档、不需要接口定义,甚至不需要完整需求,直接开写。
-
极高的开发速度
借助 AI,很多"样板代码 + 通用逻辑"可以瞬间生成。
-
更贴近人类思维
人类本来就是模糊表达需求,而不是写接口文档。Vibe Coding 更符合直觉。
-
探索性开发非常高效
在做 demo、原型、工具脚本时,效率极高。
Vibe Coding 的核心问题
vibe coding 的核心问题可用一句话表示:在简单问题上表现惊艳,但在复杂系统中会迅速失控。
失控点一:起点偏差
在 Vibe Coding 中,任务通常从一句模糊描述开始,但真实系统往往会非常复杂,包含大量隐含信息:
- 既有架构约束
- 数据模型限制
- 业务规则
- 历史实现逻辑
- ...
这些信息并不会出现在 prompt 中,于是 AI 开始自由发挥。
- 基于经验进行合理补全
- 生成一个看起来没问题的方案
这种行为的问题在于一旦初始理解出现偏差,后续所有生成都会在错误轨道上不断强化,最终与真实需求越来越偏离。
失控点二:上下文坍塌
随着开发深入,对话轮次增加,AI就开始出现「失忆」,具体表现为:
- 已经确认的接口被重新设计
- 明确过的约束被忽略
- 关键细节在后续对话中消失
出现这些问题的本质原因是:
- 上下文窗口有限(信息被压缩或截断)
- 自然语言缺乏结构化表达
- 没有稳定的长期记忆机制
结果就是:前面花大量时间达成的共识,在后续过程中不断被覆盖。
失控点三:过程失控
当任务进入中后期,问题会进一步升级:
- 决策和核心逻辑散落在不同对话中
- 没有阶段性产物沉淀,无法追溯设计意图
此时开发的状态变成:**没有工程状态,只有聊天记录,**这会带来严重后果:
- 对话一旦中断,难以继续。
- 一旦切换任务,需要重新解释上下文。
- 没有中间过程记录,团队协作困难。
这就是典型的迷路状态:AI 不知道自己在做什么,开发者也无法控制方向
总结
在 Vibe Coding 模式下每开启一个新对话,AI 就会刷新为职场小白,当任务跨多个模块、多文件,并且要跨阶段推进时,不提前规划、对齐需求,AI就会跑偏,生成过程不可控,生成结果不可用。
什么是Spec Coding?
Spec Coding(规范驱动开发,Spec-Driven Development,简称 SDD )是一种面向复杂系统的 AI 开发模式,它以明确的功能规范(Specification)为核心,让 AI 在清晰的结构化文档指导下生成代码。
在引入 Spec 作为中间层之后,整个开发流程不再是"对话 → 代码",而是一个**分阶段、可验证、可回溯的工程链路。**Spec Cooding 整个流程一般可分为以下几点:
-
需求描述
用户需要先描述需求,包括做什么、为什么要做这个改动、做了哪些决策和权衡、以及明确哪些东西在范围之内。需求描述越清晰,AI 最终生成的效果就越符合预期。
-
AI 澄清需求
在生成实现方案之前,AI 会通过几轮对话与用户确认需求细节,例如:
- 功能范围
- 技术选型
- 数据结构
- 系统边界
这一阶段可以帮助用户进一步明确需求,避免模糊需求直接生成代码导致方向偏差。
-
生成方案
在需求确认后,AI 会生成完整的实现方案文档(Doc),文档通常包含:
- 项目目标
- 功能模块设计
- 技术实现思路
- 系统结构说明
用户可以直接在生成的文档中修改或补充细节。
-
拆分任务
有了实现方案之后,Spec 会将复杂需求拆解为多个步骤,使开发过程更加清晰。
-
分步执行任务
执行任务时可分步骤推进。
-
总结清单
任务完成后生成最终的总结清单。
在上述的每个阶段开始之前,都支持用户确认和修改。通过 Spec Coding 能够很好的解决 Vibe Coding 在复杂项目中的缺陷:
-
起点偏差
写代码之前先规划、对齐功能,保证方向正确。
-
上下文坍塌
将目标、约束等信息写下来并保存,不强依赖上下文。
-
过程失控
将决策、核心逻辑以及中间产物保存下来,便于 AI 追溯,解决 AI 迷失方向的问题,
如何使用Spec Coding?
虽然 Spec Coding 还是一个相对新的范式,但目前已经可以通过多种渠道落地,整体可以分为两类:IDE 和开源工具。
IDE内置
这一类工具已经把 Spec Coding 的流程做成了产品能力,用户可以直接使用,这类 IDE 有 comate、trae 等。以 comate 为例,用户进入 comate 后可直接切换为 Spec Mode 开启 Spec Coding。
开源工具
除了 IDE 之外社区也涌现出一批更加灵活的开源工具链。其中较有代表性的包括 spec-kit 与 OpenSpec。这类工具可以无缝集成到 Cursor、Claude Code 等 AI 编程工具中。
以 spec-kit 为例,spec-kit 是 GitHub 官方开源的规范驱动开发工具包,帮助开发者从需求到实现的全流程开发。
通过 specify init 命令初始化项目之后,就能在 AI 编程工具中通过命令行执行相应的功能,以 Cursor 为例:
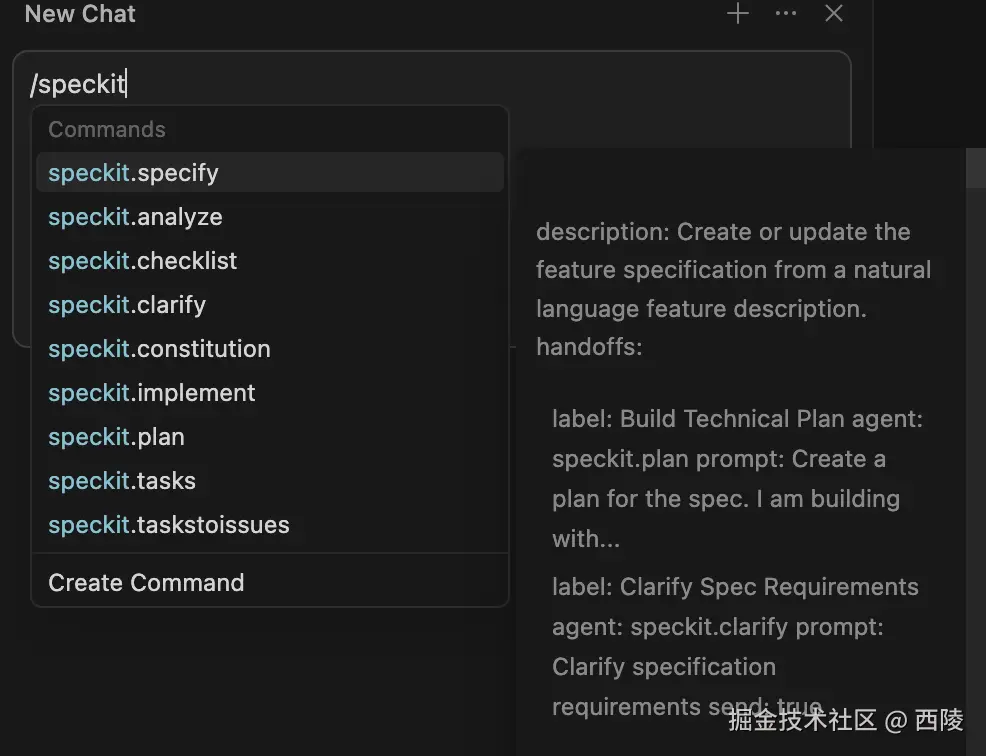
这里包含了所有的命令,其中有四个核心开发阶段:
-
/speckit.specify将功能需求转化为清晰的规范文档
-
/speckit.plan制定功能的技术实现方案
-
/speckit.tasks将技术方案分解为可执行的任务清单
-
/speckit.implement按任务清单逐步实现功能代码
如何用好Spec Coding?
一份可用的 spec 至少包含四类信息:
- 目标:要解决什么业务问题,成功标准是什么。
- 边界:In/Out 范围,异常路径,依赖和前提条件。
- 验收:可执行、可测量、可回归的验收条目。
- 约束:性能、安全、审计、兼容、成本、时效
这四类信息并不是写作模板,它们对应软件工程产物。目标对应需求项,边界对应设计决策,验收对应测试计划,约束对应质量门禁。规格越完整,后续分歧越少,返工越可控。
实际案例
案例介绍
用户在与 Agent 进行对话的过程中,前端通常做了如下操作:
- 携带query调用agent
- 接受agent响应(使用sse通信)
- 数据清理&聚合
- 将一次对话(query&response)封装为问答对
- UI组件渲染
- ...
但是 Agent 的使用形态是多样的, 针对不同的用户场景会有对应的垂类 Agent,用于专门解决某一场景下问题,例如 deepResearch、deepSearch、dataAnalysisAgent 等,不同类型的 Agent 虽然在功能层、数据层、UI 层都会存在一定的差异,但是底层协议解析内容聚合的逻辑是一致的。因此从SDK设计角度讲,Agent使用应该与具体的使用形态解藕,核心SDK的功能应该纯粹且单一,即负责Agent的一次调用执行。
spec设计
jsx
# 目标
## SDK定义
设计一个面向 AI Agent 的对话 SDK,用于统一处理 Agent 的调用执行与流式响应消费,向上提供稳定、可扩展的数据接口,支持多种对话及非对话交互形态。
SDK 的核心目标是:
- 屏蔽底层通信与协议细节(如 SSE / 多阶段输出)
- 提供统一的流式数据消费模型
- 支持不同 Agent 执行形态(单轮、多轮、工具调用等)
- 提供可扩展机制以适配不同业务需求
## SDK 能力
### 统一调用能力
- 支持一次 Agent 执行的完整生命周期管理
- 提供标准调用入口(Executor)
### 流式数据处理能力
- 支持流式返回(Streaming)
- 支持多阶段输出(思考 / 工具调用 / 结果)
### 结构化数据抽象
将原始流式数据抽象为统一结构
- Message(原始数据)
- Event(执行节点)
- Content(输出内容)
- Response(最终结果)
### 扩展能力
支持插件机制扩展
- 通信方式(xhr/fetch)
- Event 处理
- Content 数据聚合
- 数据视图
### 成功标准
- 接入方仅需关注"消费结果",无需处理协议细节
- SDK 可支持多种 Agent 形态(对话 / 工具 / workflow)
- 新增扩展能力无需修改核心 SDK
- 可在不同 JavaScript runtime 中一致运行
# 边界
## SDK职责
SDK 仅负责以下职责
### Agent 执行管理
- 发起请求
- 管理执行生命周期
- 接收流式数据
### 协议解析
将原始流式数据解析为结构化数据:Message → Event → Content
### 数据聚合
- 聚合分段消息为完整内容
- 处理多阶段输出
- 构建执行结果(Response)
### 插件调度
提供统一扩展机制
- Transport(通信)
- Event(事件处理)
- AggregateRule(聚合规则)
- View(数据视图)
## 非 SDK 职责
- 不维护 Conversation,不管理多轮上下文。
- 不提供 UI 组件,不参与视图渲染逻辑。
- 不定义业务场景,不绑定具体产品形态。
- 不存储执行结果,不管理历史记录。
## 异常路径
### 流式中断
- 返回已聚合数据
- 标记 Response 为 incomplete
### 未知数据类型
- 使用默认解析策略
- 保留原始数据
### 插件冲突
按优先级执行
- 精确匹配(id)
- 类型匹配(category)
- 默认处理
### 聚合异常
- 当前内容标记异常
- 不影响整体执行
## 实体设计
补充实体详细设计。
# 验收
列举需要验证的能力,并为其生成测试用例。
## 执行能力
验证如下能力:
- 返回 Response 对象
- 包含执行状态
- 包含结构化数据(Event / Content)
## 流式处理能力
输入:分段流式数据(chunk)
验证:
- 数据按顺序处理
- 内容逐步可消费
- 最终结果完整
## 插件扩展能力
### Event 插件
输入:注册自定义事件处理逻辑
验证:
- 新事件类型可被识别与处理
- 不影响已有逻辑
### AggregateRule 插件
输入:扩展新的内容聚合规则
验证:新类型内容可正确聚合
## 异常处理能力
输入:非法数据
验证:
- SDK 不崩溃
- 返回可用结果
- 状态可感知
# 约束
## 安全
- 不持久化用户输入与输出数据
- 不记录认证信息(token / header)
## 兼容
### 支持多 runtime
- Browser
- Node.js
- 其他 JS 环境
### 支持多通信方式
- fetch
- xhr
- 可扩展其他协议
## 时效
- 支持实时交互(流式输出)
- SDK 初始化与调用开销低
- 扩展能力可在短周期内实现(插件级扩展)
## 技术栈
- mobx
## 项目结构
//...spec 文档不一定要一次性写的很完美,这也很难,可以先给 Agent 输入一个大致的设计方案,通过多轮对话逐步优化 spec 文档。
Spec模式下的功能迭代
在持续演进的系统中,功能迭代的问题主要来源于以下几个方面:
-
设计文档逐渐失效
初始阶段会先产出技术设计文档用于对齐,但后续变更直接作用于代码,文档不再同步更新。
-
变更影响范围难以控制,强依赖个人经验
在没有明确链路时,如何修改、影响哪些地方,很大程度依赖开发经验,结果是不同人实现方式不一致,系统行为不可预测。
Spec 模式通过引入一条以规格为中心的变更链路:
Spec → Plan → Tasks → Test → Implementation将"变更"从实现层前移到设计层,从而在工程上带来一系列稳定性与可控性提升。
功能迭代流程
当系统已具备部分能力并发生需求变更时,Spec 模式要求变更沿以下路径推进:
更新 Spec
在 Spec 层定义变更:
- 明确规则变化(What changed)
- 标注影响范围(Scope)
- 更新验收条目(Acceptance)
更新 Plan
在 Plan 层约束实现路径:
- 仅调整受影响模块
- 明确不改动范围
- 避免设计扩散
这一层的核心作用将变更限制在可控范围内,而不是在实现过程中逐步扩大。
更新 Tasks
在执行层拆解变更:
- 删除失效任务
- 新增任务
- 建立任务与验收条目的映射
更新测试
补充新测试用例并修改已有测试用例。
实现代码
最后进入代码层:
- 按 Tasks 实现
- 通过 Test 验证
Spec 使用场景
下面列举了一些使用场景供参考。
| 场景 | 场景特征 | 为什么用sepc |
|---|---|---|
| 新系统 | 从零开始搭建一个完整系统,需要定义业务规则、模块边界以及整体架构 | 在系统初期阶段,业务规则、模块划分和接口边界尚未稳定。通过 Spec 先定义目标、边界和验收标准,可以在编码前完成系统级对齐,避免实现过程中反复调整架构和规则 |
| 大规模重构 | 对现有系统进行大规模重构或技术栈迁移,涉及多个模块和复杂依赖关系 | 重构过程中需要同时处理旧逻辑、新结构和模块依赖关系。Spec 可以明确当前有效规则、目标结构以及迁移范围,并通过 Tasks 和验收条目拆解重构步骤,降低跨模块改动带来的风险 |
| 多人协作的项目 | 多名开发者并行开发,可能结合 AI 工具进行协作,开发节奏快且变更频繁 | 在多人协作场景中,不同开发者对业务规则和系统行为的理解容易产生偏差。Spec 作为单一事实来源(Single Source of Truth),统一定义系统行为,并通过验收条目确保实现与预期一致 |
| 高质量/高稳定性要求 | 核心业务模块(如交易、计费、权限等),对正确性和稳定性要求高 | 核心模块需要严格定义行为边界和异常路径。Spec 中的验收条目可以转化为测试用例,确保每个规则都有明确验证,从而避免因局部修改导致系统行为偏差 |
| 长期迭代维护的项目 | 需要长期持续迭代的系统,存在历史逻辑沉淀和多轮需求变更 | 随着迭代进行,业务规则容易分散在代码中,导致系统行为难以理解。通过持续更新 Spec,可以将规则集中表达,并在每次变更时同步更新,从而降低后续维护成本 |
总结
Spec Coding 并非要取代我们已经习惯的 Vibe Coding,它更像是在我们的 AI 工具箱里增加了一项是用于解决复杂项目开的大工具。
在面对简单的 bug 修复、功能的微调、快速验证想法或者搭原型的场景时,Vibe Coding 依然是最高效的。在面对简单功能开发、部分代码重构的场景时,Plan 模式是最合适的。但当我们需要构建一个长期维护的复杂项目、大规模的重构时,Spec Coding 这种"先想清楚再动手"的模式,能有效的确保产出质量。