文章目录
- [一. 梯度下降法](#一. 梯度下降法)
-
- [1.1 一维梯度下降法](#1.1 一维梯度下降法)
- [1.2 多维梯度下降算法](#1.2 多维梯度下降算法)
- [1.3 二次多项式回归:MSE损失函数与梯度下降完整推导](#1.3 二次多项式回归:MSE损失函数与梯度下降完整推导)
-
-
- 一、模型定义
- 二、MSE损失函数定义
- 三、损失函数的梯度(偏导数)计算
-
- [1. 对参数 w 1 w_1 w1 求偏导](#1. 对参数 w 1 w_1 w1 求偏导)
- [2. 对参数 w 2 w_2 w2 求偏导](#2. 对参数 w 2 w_2 w2 求偏导)
- 四、梯度下降参数更新公式
-
- [1. 参数 w 1 w_1 w1 的更新公式](#1. 参数 w 1 w_1 w1 的更新公式)
- [2. 参数 w 2 w_2 w2 的更新公式](#2. 参数 w 2 w_2 w2 的更新公式)
- 五、补充说明
-
一. 梯度下降法
传统权重更新算法为最常见、最简单的一种参数更新策略。
(1)基本思想:设定学习率 η \eta η,参数沿梯度反方向进行移动。设待更新参数为 w w w,梯度为 g g g,则更新公式为:
w ← w − η ⋅ g w \leftarrow w - \eta \cdot g w←w−η⋅g
(2)梯度下降三种不同形式
- BGD(Batch Gradient Descent): 批量梯度下降,每次参数更新使用所有样本
- SGD(Stochastic Gradient Descent): 随机梯度下降,每次参数更新只使用一个样本
- MBGD(Mini-Batch Gradient Descent): 小批量梯度下降,每次参数更新使用小部分样本数据(mini-batch)
这三个优化算法在训练时虽然所采用的数据量不同,但是在进行参数优化时,采用的方法是相同的:
- step1 :求梯度 g = ∂ l o s s ∂ w = f ( l o s s ) g = \frac{\partial loss}{\partial w}=f(loss) g=∂w∂loss=f(loss)
- step2 :求梯度的平均值(单个样本的SGD不需要求平均值)
- step3 :更新权重 w ← w − η ⋅ g w \leftarrow w - \eta \cdot g w←w−η⋅g
(3)优缺点
优点:
- 算法简单,当学习率取值恰当时候,可以收敛到全局最优点(凸函数)或局部最优点(非凸函数)
缺点:
- 对学习率非常敏感,过小收敛极慢,过大又越过极值点
- 学习率除了敏感,有时候还会因为在迭代过程中保持不变,很容易造成算法被卡在鞍点(梯度为0,但不是最小值也不是最大值的点)
- 在比较平坦的区域,由于梯度接近于0,优化算法会因误判,在还未到达极值点时,就提前结束迭代,陷入局部最小值
1.1 一维梯度下降法
我们以目标函数(损失函数) f ( x ) = x 2 f(x)=x^2 f(x)=x2 为例来看一看梯度下降是如何工作的(这里 x x x为参数)
迭代方法为:
x ← x − η ∗ g = x − η ∗ ∂ l o s s ∂ x x \leftarrow x - \eta * g = x - \eta * \frac{\partial loss}{\partial x} x←x−η∗g=x−η∗∂x∂loss
虽然我们知道最小化 f ( x ) f(x) f(x) 的解为 x = 0 x=0 x=0,这里依然使用如下代码来观察是如何迭代的
这里 x x x 为模型参数,使用 x = 10 x=10 x=10 作为初始值,并设学习率 η = 0.2 \eta=0.2 η=0.2,使用梯度下降法对 x x x 迭代10次
代码实现:
python
import numpy as np
import matplotlib.pyplot as plt
x = 10
lr = 0.2
result = [x]
for i in range(10):
x -= lr*2*x
result.append(x)
f_line = np.arange(-10, 10, 0.1)
plt.plot(f_line, [x*x for x in f_line])
plt.plot(result, [x*x for x in result], '-o')
plt.title('learning rate = {}'.format(lr))
plt.xlabel('x')
plt.ylabel('f(x)')
plt.show()使用不同的学习率进行训练,会有以下结果:
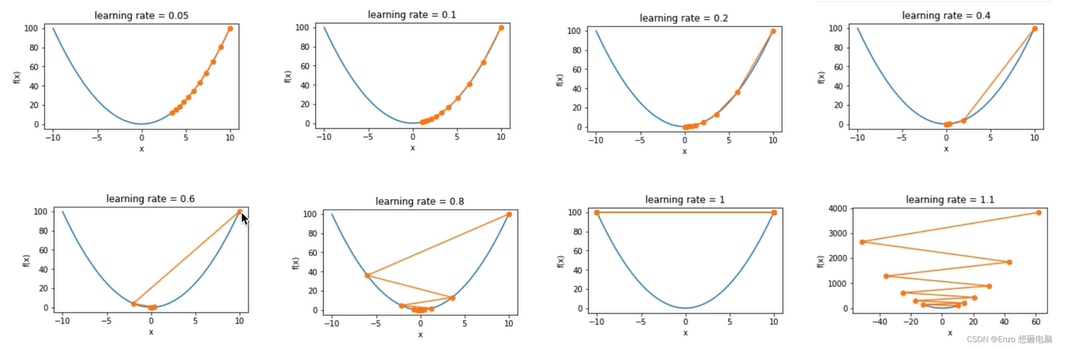
- 如果学习率过小,将导致 x x x 的更新非常缓慢,需要更多的迭代
- 相反,当使用过大的学习率, x x x 的迭代不能保证降低 f ( x ) f(x) f(x) 的值,例如,当学习率 η = 1.1 \eta=1.1 η=1.1 时, x x x 超出了最优解 x = 0 x = 0 x=0,并逐渐发散
1.2 多维梯度下降算法
在对一元梯度下降有了了解之后,下面看看多元梯度下降,即考虑 X = x 1 , x 2 , ⋯ x d T X = x_1, x_2, \\cdots x_d^T X=x1,x2,⋯xdT 的情况。
多元损失函数,它的梯度也是多元的,是一个由d个偏导数组成的向量:
∇ f ( X ) = ∂ f x ∂ x 1 , ∂ f x ∂ x 2 , ⋯ , ∂ f x ∂ x d T \nabla f(X) = \\frac{\\partial f_x}{\\partial x_1}, \\frac{\\partial f_x}{\\partial x_2}, \\cdots, \\frac{\\partial f_x}{\\partial x_d}^T ∇f(X)=∂x1∂fx,∂x2∂fx,⋯,∂xd∂fxT
然后选择合适的学率进行梯度下降:
X ← X − η ∗ ∇ f ( X ) X \leftarrow X - \eta * \nabla f(X) X←X−η∗∇f(X)
下面通过代码可视化它的参数更新过程。构造一个目标函数 f ( X ) = x 1 2 + 2 x 2 2 f(X) = x_1^2 + 2x_2^2 f(X)=x12+2x22,并有二维向量 X = x 1 , x 2 X = x_1, x_2 X=x1,x2 作为输入,标量作为输出。
损失函数的梯度为 ∇ f ( x ) = 2 x 1 , 4 x 2 T \nabla f(x) = 2x_1, 4x_2^T ∇f(x)=2x1,4x2T。使用梯度下降法,观察 x 1 , x 2 x_1, x_2 x1,x2从初始位置-5, -2 的更新轨迹。
python
import numpy as np
import matplotlib.pyplot as plt
def loss_func(x1, x2): # 定义目标函数
return x1 ** 2 + 2 * x2 ** 2
x1, x2 = -5, -2
eta = 0.4
num_epochs = 20
result = [(x1, x2)]
for epoch in range(num_epochs):
gd1 = 2 * x1
gd2 = 4 * x2
x1 -= eta * gd1
x2 -= eta * gd2
result.append((x1, x2))
# print('x1:', result1)
# print('\n x2:', result2)
plt.figure(figsize=(8, 4))
plt.plot(*zip(*result), '-o', color='#ff7f0e')
x1, x2 = np.meshgrid(np.arange(-5.5, 1.0, 0.1), np.arange(-3.0, 1.0, 0.1))
plt.contour(x1, x2, loss_func(x1, x2), colors='#1f77b4')
plt.title('learning rate = {}'.format(eta))
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()1.3 二次多项式回归:MSE损失函数与梯度下降完整推导
一、模型定义
我们以二次多项式回归模型为例,推导其均方误差(MSE)损失函数的梯度与参数更新公式。
模型表达式:
f ( x ) = w 1 x + w 2 x 2 f(x) = w_1 x + w_2 x^2 f(x)=w1x+w2x2
其中:
- w 1 , w 2 w_1, w_2 w1,w2 为模型待学习的参数(权重)
- x x x 为输入特征
- f ( x ) f(x) f(x) 为模型的预测输出
二、MSE损失函数定义
采用 均方误差(MSE) 作为损失函数,用于衡量模型预测值与真实值的误差。对于单个样本,损失函数定义为:
L MSE = ( y true − f ( x ) ) 2 = ( y true − w 1 x − w 2 x 2 ) 2 L_{\text{MSE}} = \left(y_{\text{true}} - f(x)\right)^2 = \left(y_{\text{true}} - w_1 x - w_2 x^2\right)^2 LMSE=(ytrue−f(x))2=(ytrue−w1x−w2x2)2
其中 y true y_{\text{true}} ytrue 为样本的真实标签。
三、损失函数的梯度(偏导数)计算
梯度下降的核心是计算损失函数对参数的偏导数(梯度),用于指导参数更新。
1. 对参数 w 1 w_1 w1 求偏导
根据链式求导法则:
∂ L MSE ∂ w 1 = 2 ⋅ ( y true − w 1 x − w 2 x 2 ) ⋅ ∂ ∂ w 1 ( y true − w 1 x − w 2 x 2 ) = 2 ⋅ ( y true − w 1 x − w 2 x 2 ) ⋅ ( − x ) = − 2 x ⋅ ( y true − w 1 x − w 2 x 2 ) \begin{align*} \frac{\partial L_{\text{MSE}}}{\partial w_1} &= 2 \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \cdot \frac{\partial}{\partial w_1}\left(y_{\text{true}} - w_1 x - w_2 x^2\right) \\ &= 2 \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \cdot (-x) \\ &= -2x \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \end{align*} ∂w1∂LMSE=2⋅(ytrue−w1x−w2x2)⋅∂w1∂(ytrue−w1x−w2x2)=2⋅(ytrue−w1x−w2x2)⋅(−x)=−2x⋅(ytrue−w1x−w2x2)
2. 对参数 w 2 w_2 w2 求偏导
同理,对 w 2 w_2 w2 求偏导:
∂ L MSE ∂ w 2 = 2 ⋅ ( y true − w 1 x − w 2 x 2 ) ⋅ ∂ ∂ w 2 ( y true − w 1 x − w 2 x 2 ) = 2 ⋅ ( y true − w 1 x − w 2 x 2 ) ⋅ ( − x 2 ) = − 2 x 2 ⋅ ( y true − w 1 x − w 2 x 2 ) \begin{align*} \frac{\partial L_{\text{MSE}}}{\partial w_2} &= 2 \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \cdot \frac{\partial}{\partial w_2}\left(y_{\text{true}} - w_1 x - w_2 x^2\right) \\ &= 2 \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \cdot (-x^2) \\ &= -2x^2 \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \end{align*} ∂w2∂LMSE=2⋅(ytrue−w1x−w2x2)⋅∂w2∂(ytrue−w1x−w2x2)=2⋅(ytrue−w1x−w2x2)⋅(−x2)=−2x2⋅(ytrue−w1x−w2x2)
四、梯度下降参数更新公式
梯度下降的核心思想是:沿着损失函数梯度的反方向更新参数,逐步最小化损失函数。
参数更新的通用公式为:
w = w − η ⋅ ∂ L ∂ w w = w - \eta \cdot \frac{\partial L}{\partial w} w=w−η⋅∂w∂L
其中 η \eta η 为学习率(步长),用于控制参数更新的幅度。
1. 参数 w 1 w_1 w1 的更新公式
将 w 1 w_1 w1 的偏导数代入通用公式:
w 1 = w 1 − η ⋅ ∂ L MSE ∂ w 1 = w 1 − η ⋅ − 2 x ⋅ ( y true − w 1 x − w 2 x 2 ) = w 1 + 2 η x ⋅ ( y true − w 1 x − w 2 x 2 ) \begin{align*} w_1 &= w_1 - \eta \cdot \frac{\partial L_{\text{MSE}}}{\partial w_1} \\ &= w_1 - \eta \cdot \left-2x \\cdot \\left(y_{\\text{true}} - w_1 x - w_2 x\^2\\right)\\right \\ &= w_1 + 2\eta x \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \end{align*} w1=w1−η⋅∂w1∂LMSE=w1−η⋅−2x⋅(ytrue−w1x−w2x2)=w1+2ηx⋅(ytrue−w1x−w2x2)
2. 参数 w 2 w_2 w2 的更新公式
将 w 2 w_2 w2 的偏导数代入通用公式:
w 2 = w 2 − η ⋅ ∂ L MSE ∂ w 2 = w 2 − η ⋅ − 2 x 2 ⋅ ( y true − w 1 x − w 2 x 2 ) = w 2 + 2 η x 2 ⋅ ( y true − w 1 x − w 2 x 2 ) \begin{align*} w_2 &= w_2 - \eta \cdot \frac{\partial L_{\text{MSE}}}{\partial w_2} \\ &= w_2 - \eta \cdot \left-2x\^2 \\cdot \\left(y_{\\text{true}} - w_1 x - w_2 x\^2\\right)\\right \\ &= w_2 + 2\eta x^2 \cdot \left(y_{\text{true}} - w_1 x - w_2 x^2\right) \end{align*} w2=w2−η⋅∂w2∂LMSE=w2−η⋅−2x2⋅(ytrue−w1x−w2x2)=w2+2ηx2⋅(ytrue−w1x−w2x2)
五、补充说明
- 多样本扩展:上述推导针对单个样本,若为批量样本,需对所有样本的梯度求和后取平均,再进行参数更新。
- 学习率选择 :学习率 η \eta η 是超参数,过大易导致参数震荡不收敛,过小则收敛速度过慢,需根据实际场景调优。
- 损失函数简化 :部分场景会在MSE损失前添加 1 2 \frac{1}{2} 21 系数,目的是抵消求导后的系数 2 2 2,简化计算,不影响优化方向。