前言:作为后端开发者,日常开发中离不开MySQL索引优化,而聚簇索引作为InnoDB存储引擎的核心设计,更是面试和实操中的高频重点。很多开发者只知道"主键就是聚簇索引",却不懂其底层逻辑和实操注意事项,导致项目中出现索引失效、性能瓶颈等问题。本文将结合我自己搭建的java-mm-showcase技术脚手架项目(技术栈:Spring Boot 3.2.5 + Gradle + JDK 17 + MySQL),从原理、实操、避坑三个维度,手把手拆解聚簇索引,新手也能快速上手,面试也能直接套用。
一、聚簇索引核心原理(通俗好懂,拒绝晦涩)
很多人容易混淆聚簇索引和非聚簇索引,其实用一句话就能区分:聚簇索引是"索引即数据,数据即索引",而非聚簇索引是"索引是导航,数据是单独存储的内容"。类比来说,聚簇索引就像一本按目录排序的书,目录的页码(索引键)和书页内容(数据)顺序完全一致,找到目录就能直接翻到对应内容;而非聚簇索引则是单独的目录,找到目录后还需要根据页码再翻到对应书页,这个过程就是"回表"。
从底层结构来看,聚簇索引基于B+树实现,其非叶子节点仅存储索引键和子节点指针,用于导航;叶子节点则直接存储完整的行数据,且叶子节点之间通过双向链表连接,这也是聚簇索引范围查询高效的核心原因。
核心结论:聚簇索引的本质是"索引结构与数据本身物理存储在一起",一张表只能有1个聚簇索引。在MySQL InnoDB中,主键会默认作为聚簇索引;若未定义主键,MySQL会自动选择第一个唯一非空列作为聚簇索引;若两者都没有,则会隐式创建一个6字节的自增rowid作为聚簇索引,这也是InnoDB存储引擎的强制规则之一。
二、结合java项目,实操聚簇索引
在前几篇mysql的实操项目中,核心业务表user用于存储用户信息,下面讲的所有实操依然围绕该表展开,SQL可直接复制到项目中执行,贴合真实开发场景。
1. 项目中聚簇索引的默认创建(最常用场景)
在项目初始化时,user表的创建SQL如下,其中主键id会自动成为聚簇索引,无需额外手动创建,这也是日常开发中最推荐的方式:
-- user表创建SQL
create table user (
id bigint primary key auto_increment, -- 聚簇索引(自增主键,推荐)
name varchar(50) not null comment '用户名',
age int comment '年龄',
phone varchar(20) comment '手机号',
create_time datetime default current_timestamp comment '创建时间',
index idx_age (age) -- 非聚簇索引(普通索引,用于age字段查询)
) comment '用户表';说明: id作为自增主键,是聚簇索引的最优选择。
因为自增主键能保证数据顺序插入,避免B+树频繁发生页分裂,提升插入性能;同时自增主键长度短小,能减少索引占用的磁盘空间,降低磁盘IO损耗。
2. 聚簇索引的查询实操(对比非聚簇索引)
在mysql实战讲解(一)中我们提到过回表的概念,下面通过两条SQL对比聚簇索引和非聚簇索引的查询差异,我们再强化一下"回表"的概念:
(1)聚簇索引查询(主键id查询):
-- 聚簇索引查询,无回表,效率最高
select * from user where id=100;查询流程:由于id是聚簇索引,MySQL会直接通过聚簇索引的B+树找到对应的叶子节点,叶子节点中存储着完整的用户数据,无需额外操作,全程仅需3-4次磁盘IO,这也是主键查询效率最高的原因。
(2)非聚簇索引查询(age字段查询):
-- 非聚簇索引查询,需回表
select * from user where age=25;查询流程:首先通过非聚簇索引idx_age找到对应的主键id,再通过主键id(聚簇索引)找到完整的用户数据,这个"通过主键找数据"的过程就是回表,比聚簇索引多了一步操作,效率稍低。
3. 聚簇索引的修改与验证(项目排错常用)
在项目开发中,有时会遇到"删除主键后,索引失效"的问题,其实核心是没理解聚簇索引的创建规则。下面通过SQL实操,模拟项目中可能遇到的场景,验证聚簇索引的自动切换逻辑:
-- 1. 先取消id的自增属性
alter table user modify column id bigint not null;
-- 2. 删除原有聚簇索引(主键id)
alter table user drop primary key;
-- 3. 创建唯一非空索引,MySQL会自动将其作为聚簇索引
alter table user add unique key uk_phone (phone);
-- 4. 查看索引信息,验证聚簇索引(项目排错常用SQL)
show index from user;
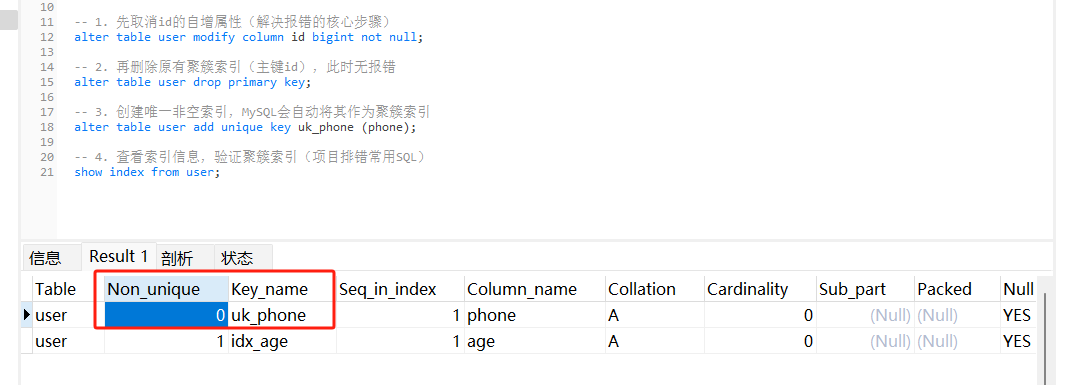
说明:图中1中 non_unique 0 为primary ,图2 变成了uk_phone。因为删除主键后,若存在唯一非空列(如这里的phone),MySQL会自动将其作为聚簇索引;若没有,则会隐式创建隐藏的rowid作为聚簇索引。
重点注意:上述sql中主键列是自增列(auto_increment),不能直接删除主键,必须先取消自增属性,否则会触发1075报错,这是项目实操中最容易踩的坑之一。
三、项目实操避坑指南
踩坑点1:用频繁更新的列作为聚簇索引(如phone)
-- 错误:用phone作为聚簇索引(phone频繁更新)
alter table user add primary key (phone);
-- 推荐:重新设置自增主键id作为聚簇索引
alter table user add primary key (id);问题分析:聚簇索引的排序就是数据的物理存储顺序,若phone频繁更新,会导致数据在磁盘上频繁"搬家",同时所有非聚簇索引的叶子节点(存储聚簇索引键)都要同步更新,严重影响项目性能。需要重新设置自增主键id作为聚簇索引。
踩坑点2:用UUID作为聚簇索引(主键无序)
-- 不推荐:用UUID作为主键(聚簇索引)
create table user (
id varchar(36) primary key comment 'UUID主键',
username varchar(50) not null
);问题分析:UUID是随机字符串,无法保证顺序插入,每次插入数据时,InnoDB需要调整B+树结构(发生页分裂)来插入数据,导致写入性能变慢,还会产生大量磁盘碎片,影响项目查询性能。
解决方案:优先选自增主键(bigint auto_increment),若必须用UUID,可采用"有序UUID"方案,减少页分裂。
踩坑点3:忽略聚簇索引的唯一性(导致索引失效)
问题分析:聚簇索引的列必须唯一(主键/唯一非空列),若设置非唯一列作为聚簇索引,MySQL会自动为其添加隐藏列,导致索引结构异常,最终出现索引失效、查询变慢的问题,这在项目中容易被忽略。
要像上面的2.3,创建聚簇索引时,确保列是主键或唯一非空列,避免使用普通非唯一列。
四、聚簇索引与非聚簇索引核心区别
| 对比维度 | 聚簇索引(Clustered Index) | 非聚簇索引(Non-Clustered Index) |
|---|---|---|
| 核心本质 | 索引与数据物理存储在一起,"索引即数据" | 索引与数据分离,索引仅存储数据指针(聚簇索引键) |
| 数量限制 | 一张表仅1个(InnoDB强制规则) | 一张表可创建多个(无明确上限,受性能影响) |
| 默认情况 | InnoDB中,主键默认作为聚簇索引(如user表id) | 手动创建,如user表的idx_age(age字段普通索引) |
| 查询效率 | 无需回表,查询效率高(如select * from user where id=100) | 需回表(除覆盖索引外),效率低于聚簇索引(如select * from user where age=25) |
| 存储结构 | B+树叶子节点存储完整行数据 | B+树叶子节点存储聚簇索引键(如user表id) |
| 插入/更新性能 | 稍慢,需维持数据物理顺序(避免页分裂) | 较快,仅需更新索引结构,不影响数据存储 |
| 项目实操示例 | user表id(自增主键),对应SQL:primary key (id) | user表idx_age,对应SQL:index idx_age (age) |
两者核心差异在于"索引与数据是否绑定",聚簇索引主打查询高效,非聚簇索引主打灵活扩展。项目中需合理搭配,以聚簇索引(自增主键)为核心,非聚簇索引辅助高频查询,避免过度创建非聚簇索引导致性能损耗。
总结:
-
核心原理:聚簇索引=索引+数据,一张表仅1个,InnoDB中主键默认是聚簇索引,无主键则自动适配或隐式创建;
-
项目实操中自增主键id是最优聚簇索引,查询高效、插入稳定,避免用不唯一的索引、无序的UUID等作为聚簇索引;
-
聚簇索引的性能直接决定MySQL查询效率,项目中优先选自增短小的主键作为聚簇索引,避免无序、频繁更新的列,这是索引优化的基础。