仅用于个人学习进步,如侵权请联系删除!
一、存储引擎
1.mysql存储引擎(存储数据、建立索引、读写数据的实现方式)
在MySQL5.5版本之后,默认使用的是InnoDB存储引擎。在此之前默认使用的MyISAM存储引擎。
2.InnoDB存储引擎、InnoDB存储引擎、Memory存储引擎的区别?
InnoDB:支持事务、行级锁、外键
MyISAM:不支持事务、不支持外键、不支持行级锁,但支持表锁
Memory:表数据只能存储在内存当中,所以这种表只能用于临时表使用
3.InnoDB、InnoDB如何选择?
最主要的还是InnoDB支持事务,能够保证并发情况下的数据一致性。数据会有并发情况就要考虑InnoDB存储引擎
二、索引
1.索引实质是一种能够实现高效查询的数据结构
使用索引的优点:能够提高数据查询的速度
使用索引的缺点:维护索引是会占用空间的,能够提高查询速率,但是会降低更新表速度
2.索引类型(主要是B+Tree、Hash索引)
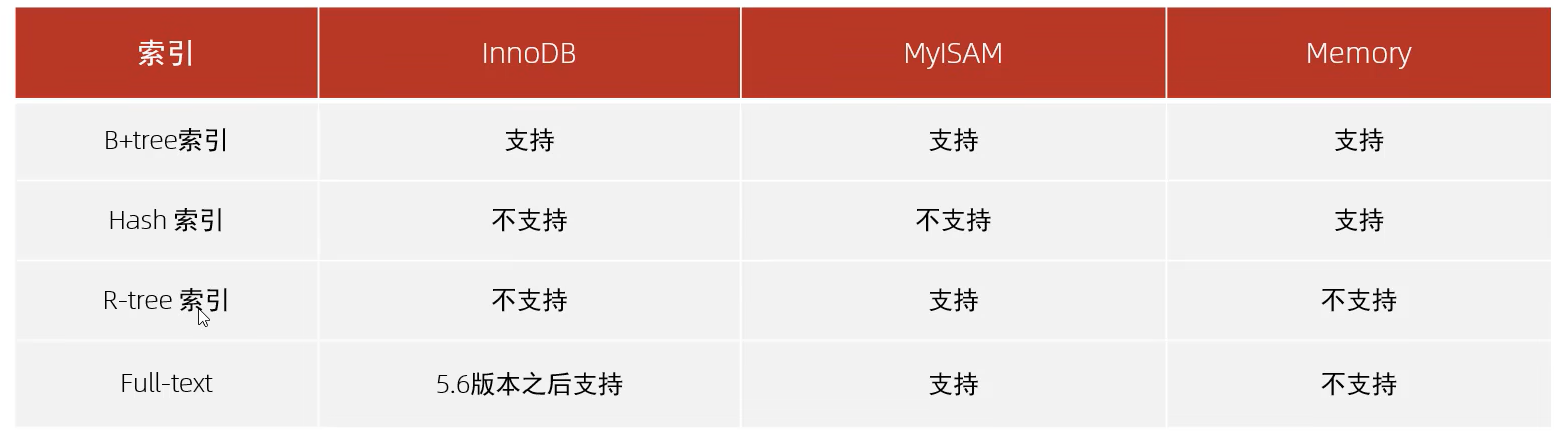
3.这部分可以学习下二叉树、红黑树(自平衡二叉树)、B-Tree(多路平衡查找树)、B+-Tree
(1)二叉树:每个节点下只会有两个子节点,单边插入会造成链表情况,
(2)红黑树(自平衡二叉树):能够解决二叉树形成链表情况,但是如果层级太多,速度也会有点慢
(3)B-Tree(多路平衡查找树):至多有5个子节点,根节点有4个key,5个指针。当节点有5个key时,中位数会向上分裂,最终实现一个节点只会有4个key
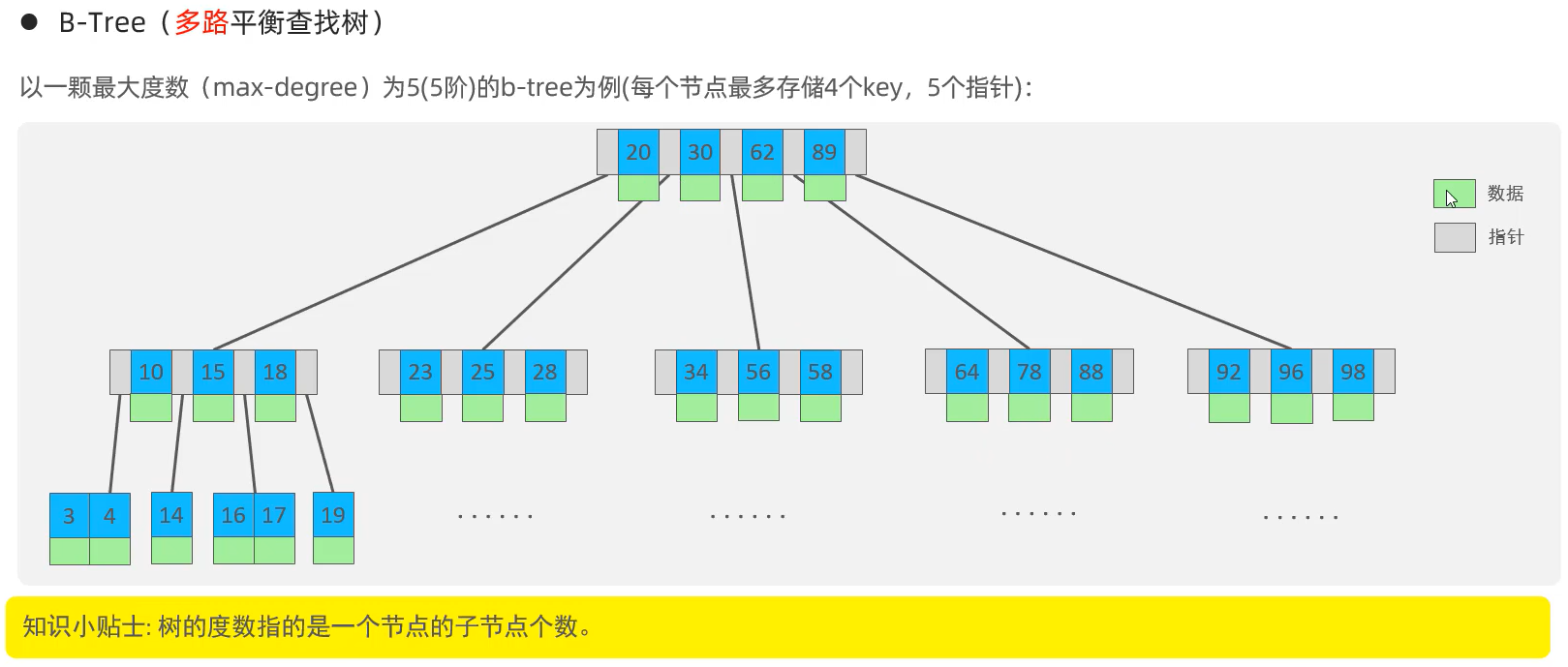
熟悉B-Tree数据结构:在https://www.cs.usfca.edu/\~galles/visualization/BTree.html这个地址操作一下,熟悉一下,感受一些魅力(太妙了)
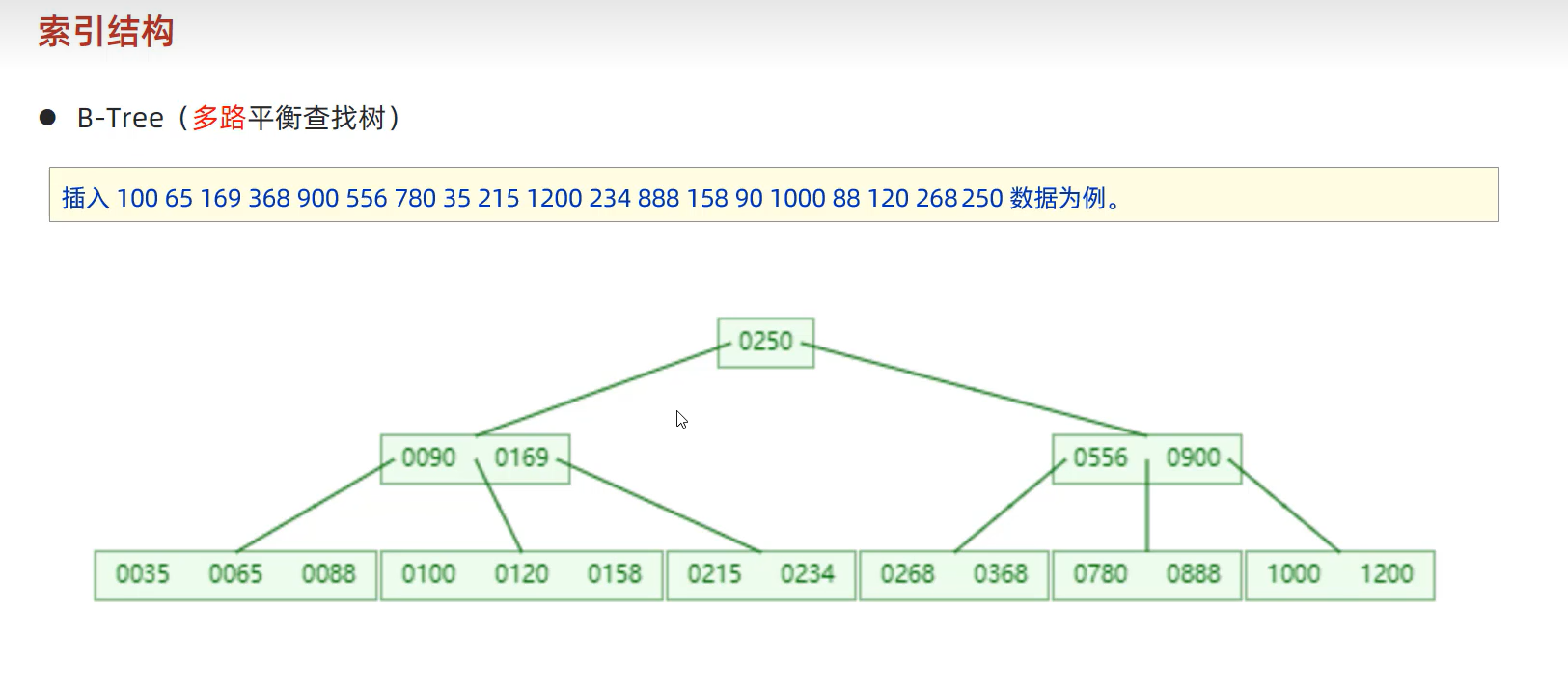
(4)B+-Tree
与B-Tree的区别:如下图,所有的根节点和中间节点的数据都会出现在叶子节点中(其实就是所有数据都会出现在叶子节点,注意所有的叶子节点并不是都会出现在根节点或中间节点当中,因为除了叶子节点的其他节点),并且叶子节点中的数据形成了单向链表。
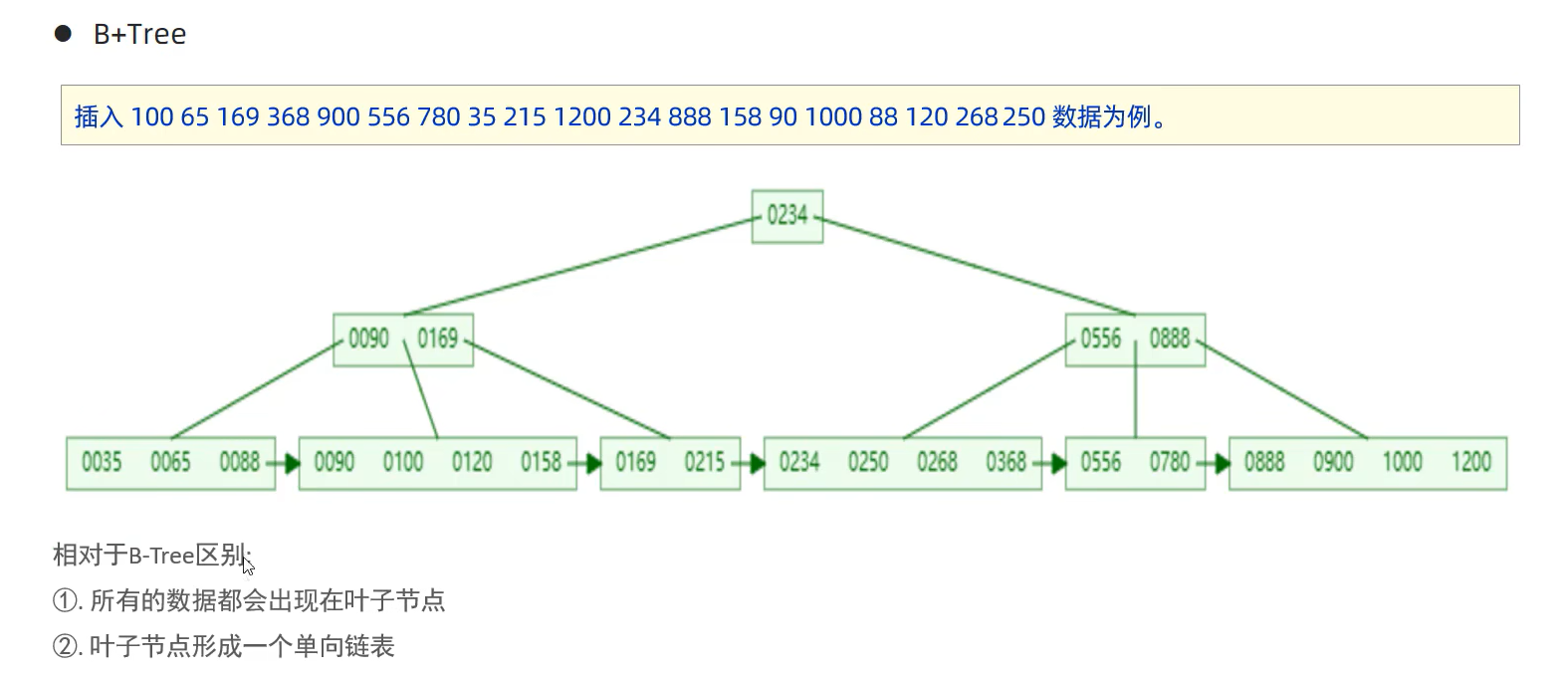
(5)MySQL对B+Tree的优化
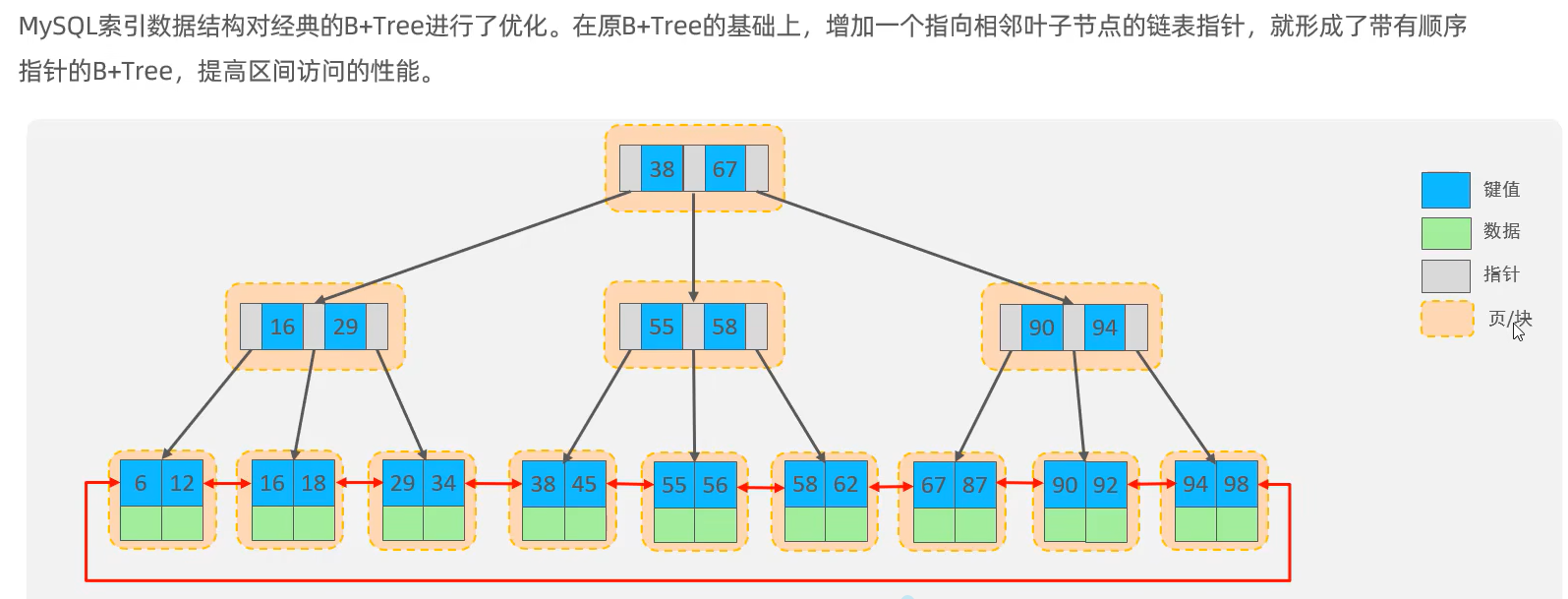
如下图,额外增加指针,使叶子节点本身形成的单项链表 形成了双向链表。
- 标准 B+ 树原始设计
所有叶子节点本身就带指针,构成单向链表:只存 后继指针,从左往右串起来,只能从头往后遍历。
- MySQL InnoDB 做的优化
InnoDB 在叶子节点上额外加了前驱指针:
-
原有:下个叶子节点指针(向后)
-
新增:上个叶子节点指针(向前)
直接把叶子节点从 单向链表 → 双向循环链表。
(6)、总结:(注意:前面学习时,B-Tree和B+Tree都可以设置成5个节点,4个key,凭什么说B-Tree一页存储的key会减少。那是因为在B-Tree结构中,每个节点都会保存数据。理论上能够放入4个key,但是实际上会根据数据大小,有可能会小于4个key。B+Tree非叶子节点不放入数据,几乎都能装满理论数量的key)

Hash索引只支持精准查询
三、索引分类


 就是说
就是说
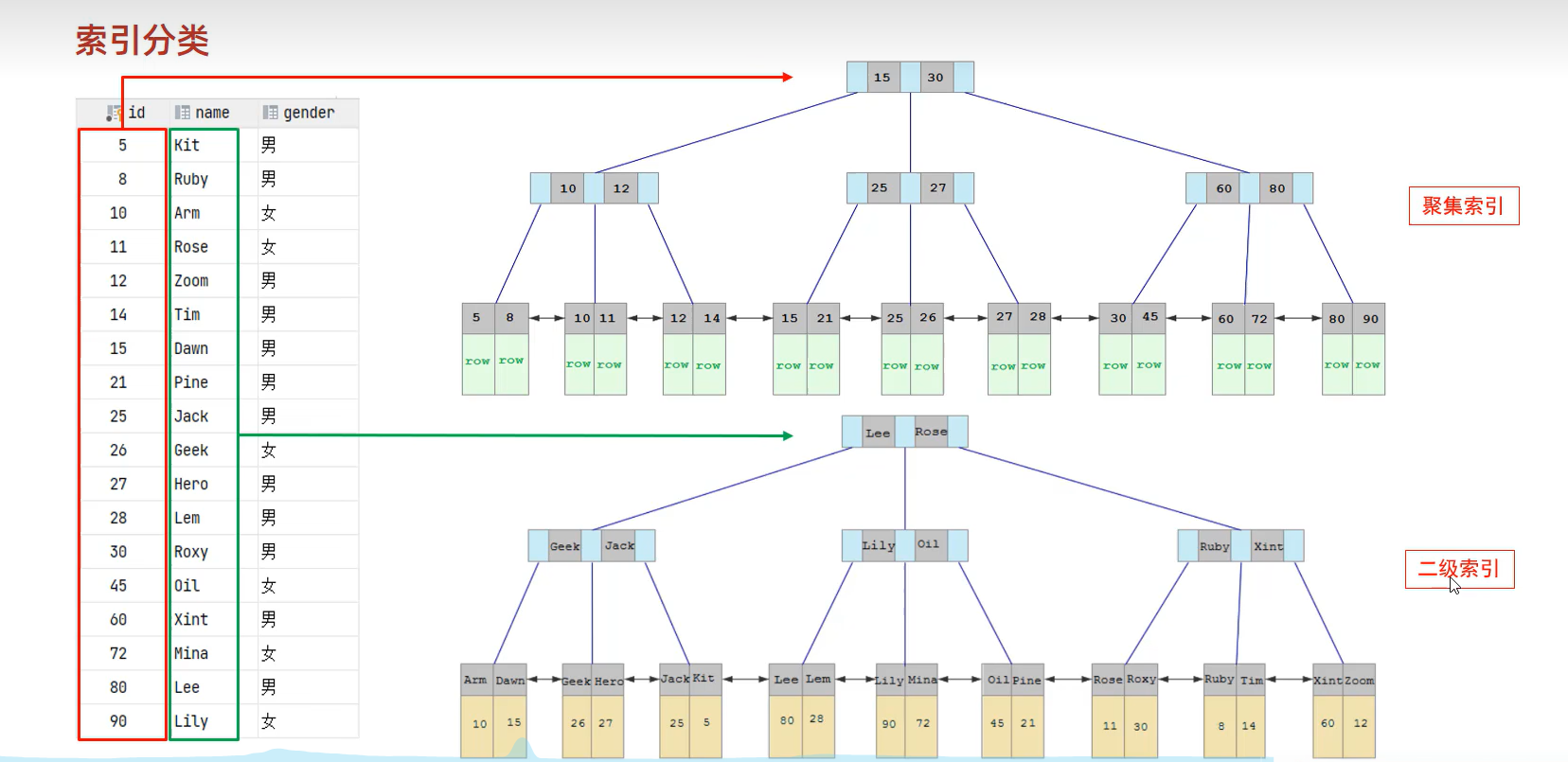
聚集索引一定得有,依次是主键索引、第一个唯一索引、最后是InnoDB自动生成的一个rowId隐藏的聚集索引。聚集索引特别之处是,叶子节点会放入该行的所有数据
二级索引:叶子节点放入只会设置索引的数据和该行的id
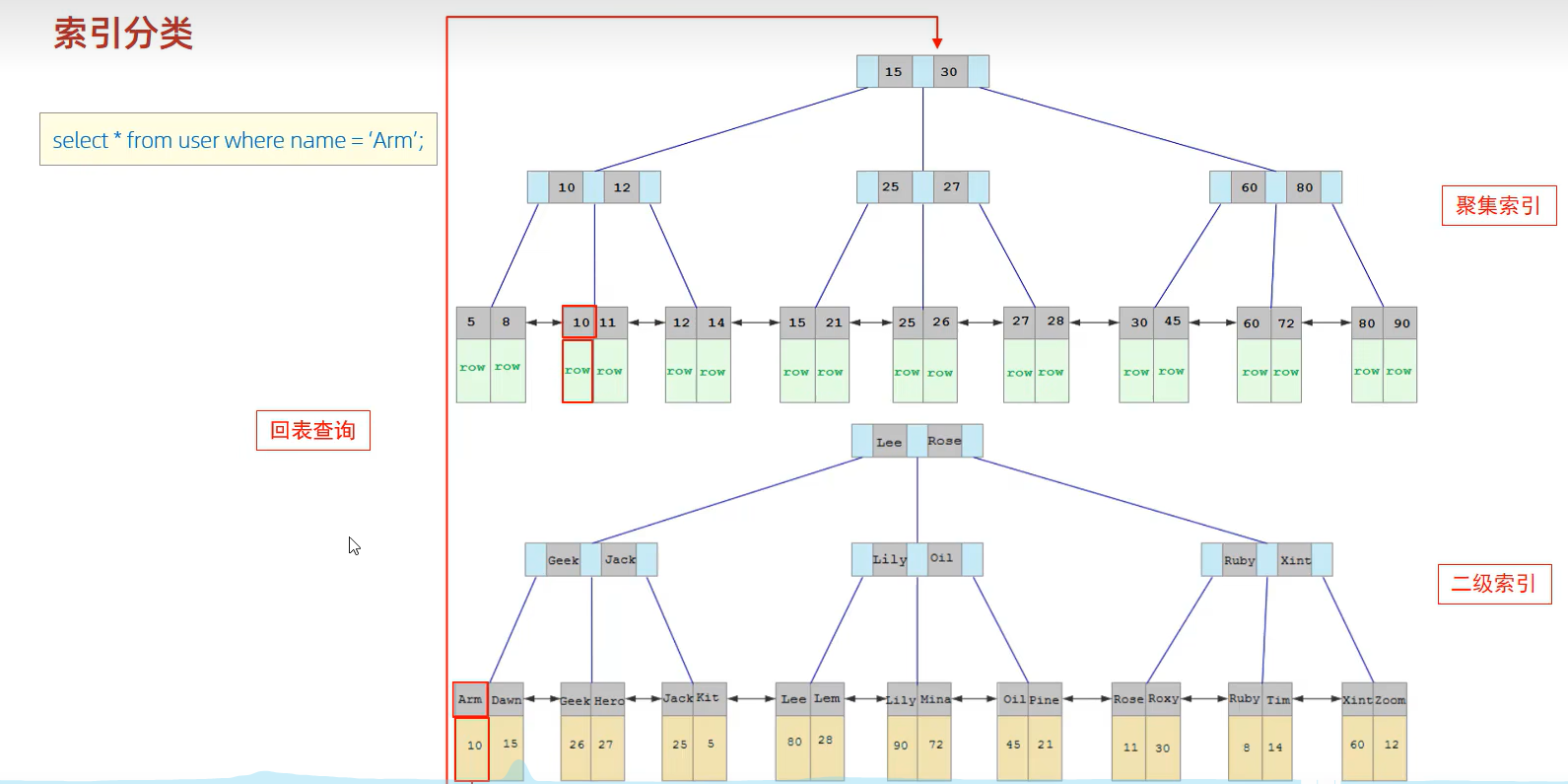
当执行查询sql语句时,流程是什么样的?如下图select * from user where name ='Arm'
会先去二级索引根据name='Arm'找到id,拿到id再去聚集索引找到这一行的所有数据,这一操作叫做回表查询。
如果select * from user where id =10 (意思是直接走聚集索引),应该就是可以直接拿到数据,不需要回表查询了
MySQL B+Tree结构不同高度能够存储多少数据量?
高度为2时,能够存储1万8千条数据量
高度为3时,能够存储2200万条数据量。就能够满足千万级数据量需要了。
再往上就该考虑分库分表了。
四、索引语法
创建普通索引:create index idx_user_name(给索引起个名字) on table(表名)(name)
创建联合索引:create index idx_user_name_age_sex(给索引起个名字) on table(表名)(name,age,sex)
创建唯一索引:create unique index idx_user_name(给索引起个名字) on table(表名)(name) 如果不加unique,默认的就是普通索引
查看表的索引 show index from table
删除索引 drop idx_user_name(索引名) on table
五、SQL性能分析
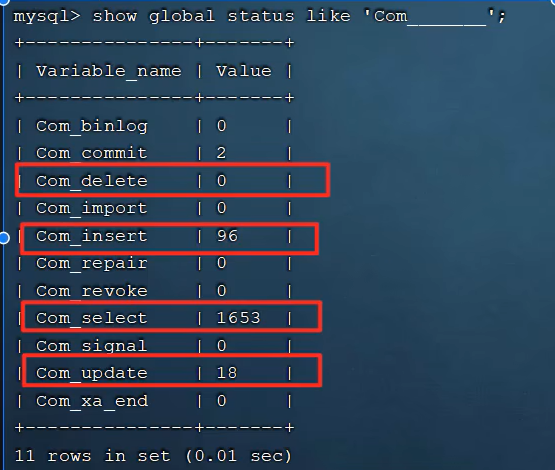
1.通过show global status like 'Com_______' ,能够看到查询、增、删、改执行操作的次数
2.慢查询日志(找到耗时过长的sql)
通过在配置文件开启,默认时间10秒,会生成一个slow_query_log慢查询日志,该日志会记录耗时过长的sql
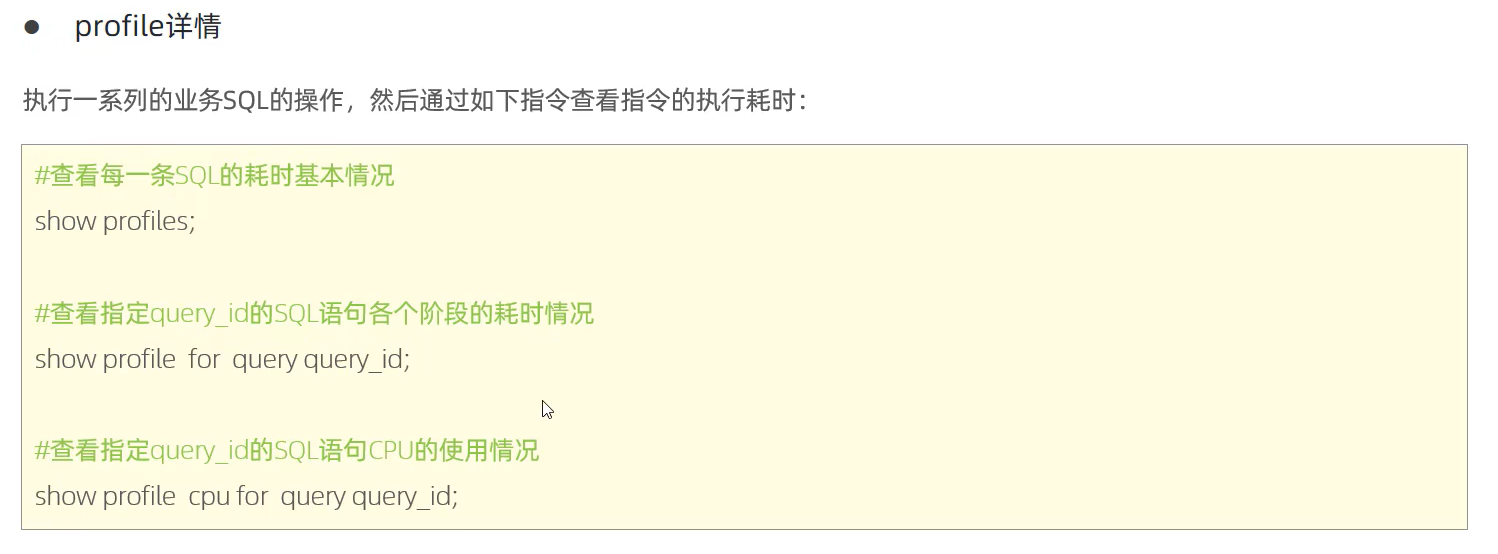
3.profile(即使没达到慢查询阈值的 SQL,也能精准定位它慢在哪里)