Python 数据分析实战:NumPy+Pandas+Matplotlib 综合案例(电商销售数据分析)
在掌握了NumPy(数值计算)、Pandas(数据处理)、Matplotlib(可视化) 三大核心库的基础用法后,本文通过真实电商销售数据场景 ,带你完成一次完整的数据分析全流程:数据加载→数据清洗→数值计算→多维度分析→可视化展示,真正实现三剑客的融会贯通。
一、案例场景与目标
场景
模拟一份电商平台销售数据集,包含:订单日期、商品类别、销售额、销量、地区、利润等字段,数据存在缺失值、异常值等真实业务问题。
分析目标
-
清洗脏数据,得到规范数据集;
-
用 NumPy 做数值统计(利润均值、销售额分位数等);
-
用 Pandas 做维度分析(各品类销量 / 利润、地区销售排行、月度趋势);
-
用 Matplotlib 绘制可视化图表,直观呈现分析结果。
二、环境准备
确保已安装三大库,未安装则执行:
bash
pip install numpy pandas matplotlib三、完整实战代码(逐段解析)
1. 导入库并设置中文显示
Matplotlib 默认不支持中文,必须先配置,否则图表会出现乱码:
python
# 导入三大核心库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# PyCharm + Matplotlib 版本不兼容导致的经典报错
import matplotlib
matplotlib.use('TkAgg')
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False2. 生成模拟数据(贴近真实业务)
我们手动生成一份包含脏数据的数据集,还原真实数据分析场景:
python
# 生成日期数据(2024年1-6月)
dates = pd.date_range(start="2024-01-01", end="2024-06-30", freq="D")
# 商品类别
categories = ["电子产品", "服装", "食品", "家居用品", "美妆"]
# 销售地区
regions = ["华东", "华北", "华南", "西南", "西北", "东北"]
# 随机生成数据
np.random.seed(666) # 固定随机种子,结果可复现
data = {
"订单日期": np.random.choice(dates, size=1000),
"商品类别": np.random.choice(categories, size=1000),
"销量": np.random.randint(1, 50, size=1000),
"销售额": np.random.uniform(10, 5000, size=1000),
"地区": np.random.choice(regions, size=1000),
"利润": np.random.uniform(-200, 1500, size=1000) # 包含负利润(亏损)
}
# 构造DataFrame
df = pd.DataFrame(data)
# 手动制造脏数据(缺失值+异常值)
df.loc[np.random.choice(df.index, 50), "利润"] = np.nan # 50个利润缺失值
df.loc[df["销售额"] > 4500, "销售额"] = 0 # 异常销售额置0
df.loc[:30, "销量"] = np.nan # 前30行销量缺失
# 查看原始数据前5行
print("===== 原始数据前5行 =====")
print(df.head())
# 查看数据基本信息
print("\n===== 数据基本信息 =====")
print(df.info())3. 数据清洗(Pandas 核心)
清洗是数据分析的关键步骤,处理缺失值、异常值、重复数据:
python
# 1. 处理缺失值:用均值填充数值型缺失列(适配Pandas CoW模式,避免inplace链式赋值报错)
df["销量"] = df["销量"].fillna(df["销量"].mean())
df["利润"] = df["利润"].fillna(df["利润"].mean())
# 2. 处理异常值:删除销售额为0的异常数据
df = df[df["销售额"] > 0]
# 3. 删除重复数据(drop_duplicates无链式赋值问题,可正常使用inplace)
df.drop_duplicates(inplace=True)
# 4. 数据类型优化:订单日期转为日期格式,方便时间分析
df["订单日期"] = pd.to_datetime(df["订单日期"])
# 新增月份列,用于时间维度分析
df["月份"] = df["订单日期"].dt.month
# 查看清洗后数据
print("===== 清洗后数据信息 =====")
print(df.info())
print("\n===== 清洗后数据描述性统计 =====")
print(df.describe())4. NumPy 数值计算(高阶统计分析)
用 NumPy 对清洗后的核心指标做精准数值统计,弥补 Pandas 描述统计的不足:
python
# 提取核心数值列转为NumPy数组
sales_arr = df["销售额"].values # 销售额数组
profit_arr = df["利润"].values # 利润数组
quantity_arr = df["销量"].values # 销量数组
# 1. 基础统计(NumPy原生方法)
print("===== NumPy数值统计结果 =====")
print(f"总销售额:{np.sum(sales_arr):.2f} 元")
print(f"平均利润:{np.mean(profit_arr):.2f} 元")
print(f"销量中位数:{np.median(quantity_arr):.2f} 件")
print(f"利润标准差:{np.std(profit_arr):.2f}") # 利润波动程度
print(f"销售额95分位数:{np.percentile(sales_arr, 95):.2f}") # 高销售额阈值
# 2. 条件统计:亏损订单数量(利润<0)
loss_orders = np.sum(profit_arr < 0)
print(f"亏损订单数:{loss_orders} 单")5. Pandas 多维度数据分析
按商品类别、地区、月份三个核心维度做业务分析:
python
print("\n===== 1. 各商品类别销售分析 =====")
# 按品类分组:统计总销量、总销售额、总利润
category_analysis = df.groupby("商品类别").agg({
"销量": "sum",
"销售额": "sum",
"利润": "sum"
}).sort_values(by="销售额", ascending=False)
print(category_analysis)
print("\n===== 2. 各地区销售排行 =====")
# 按地区分组统计销售额
region_analysis = df.groupby("地区")["销售额"].sum().sort_values(ascending=False)
print(region_analysis)
print("\n===== 3. 月度销售趋势 =====")
# 按月份分组统计销售额
month_analysis = df.groupby("月份")["销售额"].sum()
print(month_analysis)6. Matplotlib 数据可视化(4 张核心图表)
将分析结果转化为直观图表,输出业务洞察:
python
# 创建画布(2行2列子图,适配4张图表)
plt.figure(figsize=(16, 12))
# 子图1:各品类销售额柱状图
plt.subplot(2, 2, 1)
plt.bar(category_analysis.index, category_analysis["销售额"], color="#4CAF50")
plt.title("各商品类别销售额对比", fontsize=12, pad=15) # 增加标题内边距,避免与其他图表标签重叠
plt.xticks(rotation=15)
plt.ylabel("销售额(元)")
# 子图2:各地区销售额饼图
plt.subplot(2, 2, 2)
plt.pie(region_analysis.values, labels=region_analysis.index, autopct="%.1f%%", colors=plt.cm.Pastel1.colors)
plt.title("各地区销售额占比", fontsize=12, pad=15)
# 子图3:月度销售额趋势折线图(调整布局,避免标签重合)
plt.subplot(2, 2, 3)
plt.plot(month_analysis.index, month_analysis.values, marker="o", color="#FF5722", linewidth=2)
plt.title("2024年1-6月销售额趋势", fontsize=12, pad=15)
plt.xlabel("月份", labelpad=8) # 增加x轴标签内边距
plt.ylabel("销售额(元)", labelpad=8) # 增加y轴标签内边距
plt.grid(alpha=0.3)
plt.xticks(month_analysis.index) # 固定x轴刻度,避免标签错乱
# 子图4:销量与利润散点图
plt.subplot(2, 2, 4)
plt.scatter(df["销量"], df["利润"], alpha=0.6, color="#2196F3")
plt.title("销量与利润相关性", fontsize=12, pad=15)
plt.xlabel("销量(件)", labelpad=8)
plt.ylabel("利润(元)", labelpad=8)
# 调整子图间距,彻底避免标签重合
plt.tight_layout(pad=3.0) # 增加子图间整体间距
# 保存图片
plt.savefig("电商销售数据分析图表.png", dpi=300, bbox_inches="tight") # 适配标签,避免保存时裁剪
# 显示图表
plt.show()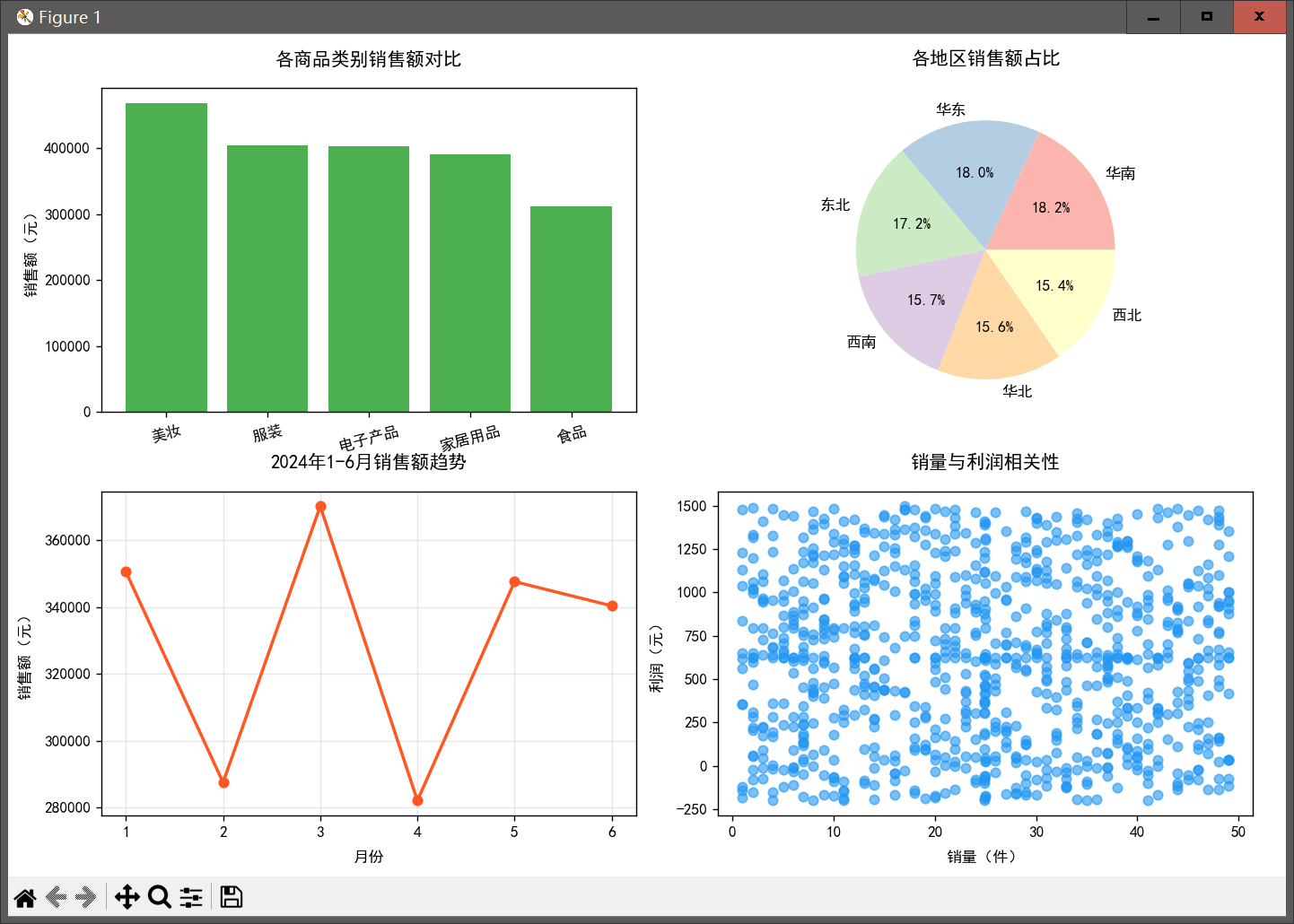
四、核心代码解析(三剑客分工)
1. NumPy:底层数值计算
-
作用:处理数组运算、精准统计、条件筛选,是 Pandas 和 Matplotlib 的底层支撑;
-
关键用法:
np.sum()/np.mean()/np.percentile()做统计,np.nan处理缺失值。
2. Pandas:数据处理核心
-
作用:数据加载、清洗、分组、聚合,是数据分析的主力工具;
-
关键用法:
-
fillna()/drop_duplicates()清洗数据; -
groupby()分组聚合; -
dt.month时间维度提取。
-
3. Matplotlib:可视化呈现
-
作用:将数据转化为柱状图、饼图、折线图、散点图,直观展示业务规律;
-
关键用法:多子图布局、中文配置、图表样式优化。
五、实战业务洞察(从图表得出结论)
-
品类洞察:电子产品销售额最高,是核心盈利品类;食品销量大但利润偏低;
-
地区洞察:华东地区销售额占比最高,为核心市场;西北、东北地区销售额偏低;
-
时间洞察:6 月销售额达到峰值,推测为电商大促活动带动;
-
相关性洞察:销量与利润无强线性关系,部分高销量订单存在亏损(需优化定价)。
六、总结
本文通过电商销售数据分析完整案例,实现了:
-
NumPy 负责数值计算,提供精准统计结果;
-
Pandas 负责数据清洗与维度分析,挖掘业务规律;
-
Matplotlib 负责可视化,让数据结果直观易懂;
这是 Python 数据分析最标准、最实用的工作流,掌握这套逻辑,可直接迁移到金融、医疗、运营等任意行业的数据分析场景中。
总结
-
数据分析标准流程:数据生成 / 加载→数据清洗→数值统计→维度分析→可视化;
-
三剑客分工:NumPy 管计算、Pandas 管处理、Matplotlib 管展示;
-
实战核心:先清洗脏数据,再做分析,最后用图表输出业务结论,贴合真实工作需求。