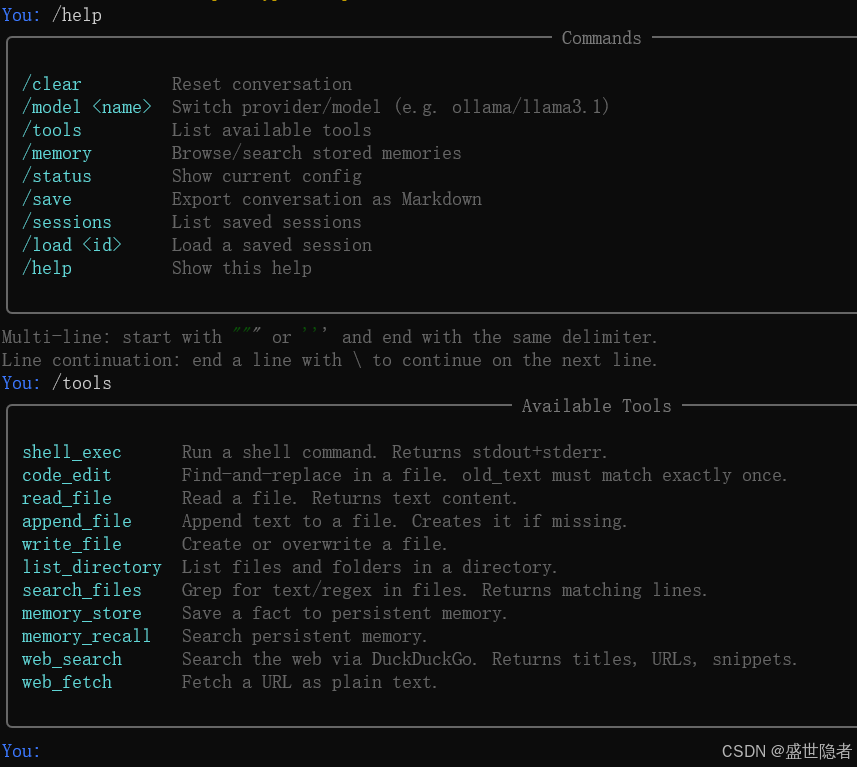
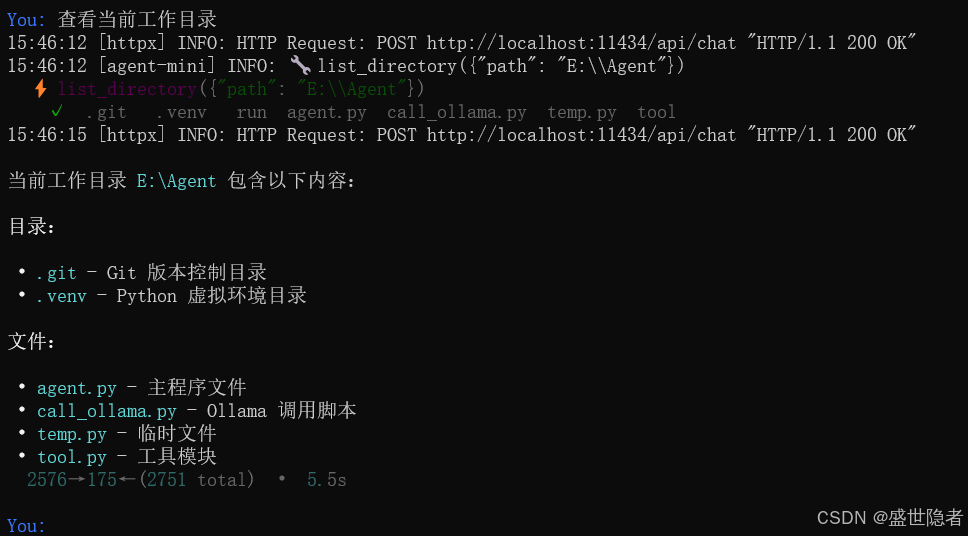
文章目录
- [1. 硬件配置与模型选择](#1. 硬件配置与模型选择)
- [2. 模型参数配置](#2. 模型参数配置)
-
- [🧠 参数详解:为何这样配置你的10核+8GB显存](#🧠 参数详解:为何这样配置你的10核+8GB显存)
- [3. 本地API调用](#3. 本地API调用)
-
- [3.1 模型驻留](#3.1 模型驻留)
-
- [⚙️ 工作原理](#⚙️ 工作原理)
- [🛠️ 配置方式](#🛠️ 配置方式)
- [💡 实用技巧](#💡 实用技巧)
- [💡 最佳实践与注意事项](#💡 最佳实践与注意事项)
- [3.2 流式输出](#3.2 流式输出)
-
- [🔌 原理:它是如何工作的?](#🔌 原理:它是如何工作的?)
- [⚖️ 场景与效果对比](#⚖️ 场景与效果对比)
- [⚙️ 默认行为与语言SDK差异](#⚙️ 默认行为与语言SDK差异)
- [🛠️ 实际应用示例](#🛠️ 实际应用示例)
-
- [1. 流式 (`stream: true`)](#1. 流式 (
stream: true)) - [2. 非流式 (`stream: false`)](#2. 非流式 (
stream: false))
- [1. 流式 (`stream: true`)](#1. 流式 (
- [✨ 高级特性:工具调用与思考过程](#✨ 高级特性:工具调用与思考过程)
- [💡 最佳实践](#💡 最佳实践)
- [3.3 思考模式](#3.3 思考模式)
-
- [🧠 哪些模型支持思考?](#🧠 哪些模型支持思考?)
- [🛠️ 如何设置`think`参数?](#🛠️ 如何设置
think参数?) -
- [1. CLI (命令行界面)](#1. CLI (命令行界面))
- [2. API 调用](#2. API 调用)
- [3. Modelfile 配置](#3. Modelfile 配置)
- [4. 流式处理思考内容](#4. 流式处理思考内容)
- [📊 何时用,何时不用?](#📊 何时用,何时不用?)
- [🔗 与`keep_alive`、`stream`的协同](#🔗 与
keep_alive、stream的协同) - [📊 核心参数与效果对比](#📊 核心参数与效果对比)
- [🛠️ 示例:使用 `hide_thinking` 参数](#🛠️ 示例:使用
hide_thinking参数) - [⚠️ 注意事项](#⚠️ 注意事项)
- [4. ollama+agent](#4. ollama+agent)
1. 硬件配置与模型选择
deepseek提供的模型参数量与推荐的硬件配置如下。
- 应该在满足运行条件的前提下,尽可能选择最大参数量的模型,因为模型参数量越大效果越好
- 如果模型参数量超过硬件配置的支持,可能导致运行缓慢,因为模型不能全在GPU跑,部分计算任务被调度到CPU
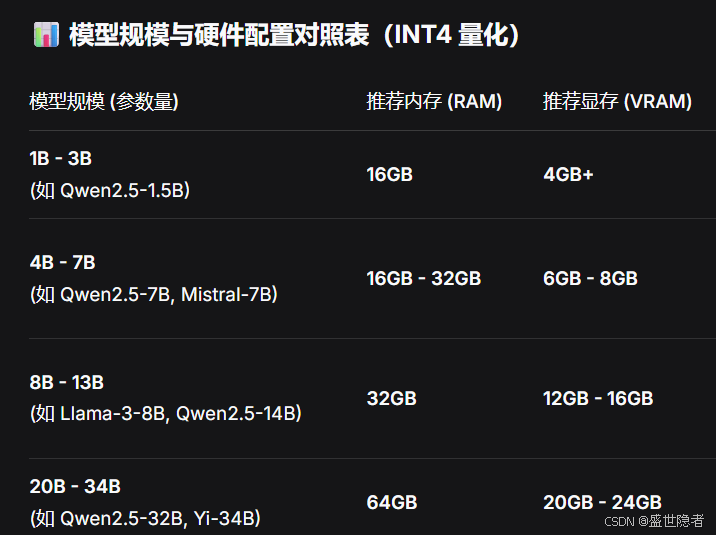
如果内存16GB,显存8GB,推荐模型参数量小于7b,如qwen3.5:4b
bash
ollama run qwen3.5:4b2. 模型参数配置
建议输入自己的硬件配置信息和模型信息,让AI来帮忙确定
16GB内存,8GB显存,10核CPU推荐的qwen3.5:4b模型参数配置(Modelfile.txt):
bash
ollama create qwen3.5:4b-mine -f .\Modelfile.txt
bash
FROM qwen3.5:4b
# ========== 硬件适配参数 ==========
PARAMETER num_ctx 5120
PARAMETER num_gpu 999
PARAMETER num_thread 10
# ========== 输出质量控制 ==========
PARAMETER temperature 0.7
PARAMETER top_k 40
PARAMETER top_p 0.95🧠 参数详解:为何这样配置你的10核+8GB显存
-
基础模型 (
FROM qwen3.5:4b) :默认采用Q4_K_M量化,模型文件仅 3.4 GB。对于你的8GB显存来说,这留下了充裕的 KV Cache 空间。 -
上下文长度 (
num_ctx 5120) :这是针对你8GB显存的 "极限甜点值"。- 估算显存占用 :模型权重 (3.4GB) + 5120 上下文的 KV Cache (~4.0GB) ≈ 7.4GB 。这个数值安全地卡在8GB显存上限以内,既利用了几乎全部显存资源,又留出了约 600MB 的缓冲地带,可以避免因显存波动导致的崩溃。
- 对比收益 :相比我之前建议的
4096,这个值能让你一次性处理更长的代码文件,或维持更多轮的复杂对话记忆。
-
GPU层数 (
num_gpu 999) :强制将4B模型的全部层加载到你的8GB显存中运行,确保获得最高的推理速度。通过以下命令可以查看ollama模型计算任务调度情况:
bashollama ps

-
CPU线程数 (
num_thread 10) :与你10核CPU精确匹配。这能优化模型首次加载时的权重解析速度,并在极少数显存压力大、需要CPU参与计算时,发挥CPU的最大多核效能。 -
温度参数 (
temperature 0.7):维持代码生成和创意对话之间的最佳平衡点。 -
(
top_k=40):保留概率最高的 40 个词。这一步几乎保留了所有合理词汇(食物种类一般不超过40个),但绝对滤掉了"水泥"这类离谱词。 -
(
top_p=0.95):在上一步的40个词中,继续累加概率至 95%。这一步会动态剪掉那些概率极低、可有可无的候选词(比如"泡面"、"炒饭"等,如果它们排在末尾的话)。
3. 本地API调用
3.1 模型驻留
keep_alive 是 Ollama API 中用于精细控制模型内存占用的参数,它的核心作用是定义模型在完成一次请求后,会在显存中继续"待命"多久。
理解这个参数,对优化本地 AI 应用的响应速度和资源管理至关重要。它的取值非常灵活:
- 立即释放 (
"0"或0):响应生成后立即卸载模型。适合显存紧张、用完即走的场景。 - 限时驻留 (
"5m"/"2h"/"24h"/300) :Ollama 全局默认值为"5m"。可使用 "h", "m", "s" 为单位,或直接写秒数。 - 永久驻留 (
-1或"-1"等):让模型常驻显存。适合追求极速响应的开发或高频调用场景。
⚙️ 工作原理
keep_alive 的计时是 "滑动刷新" 的:
- 每一次请求完成,计时器都会重置,开始新一轮倒计时。
- 这意味着,只要你的请求间隔小于设定的
keep_alive值,模型就会一直保持在显存中,随时准备"热启动"响应。
🛠️ 配置方式
它有三种配置方式,优先级依次降低:
- API 调用时指定(最高优先级):在请求体中直接定义,拥有最高控制权。
- 启动时设置环境变量 :设置
OLLAMA_KEEP_ALIVE环境变量,为所有模型定义默认行为。 - 服务端默认配置(最低优先级) :默认值为 5分钟。
💡 实用技巧
- 预热模型 :服务启动后,可发送
keep_alive: -1的空请求让模型常驻,避免首个真实请求的加载延迟。 - 主动卸载 :发送
keep_alive: 0的空请求,立即释放资源。 - 监控状态 :使用
ollama ps命令查看当前已加载的模型及其驻留时间。
💡 最佳实践与注意事项
keep_alive 的设置需要结合实际场景来权衡:
- 根据场景选择策略
- 高并发/生产环境 :推荐设为
-1让模型常驻,以获得最低延迟和最高吞吐量。 - 间歇性使用/开发环境 :设为
"1h"或"24h",在工作时段内保持热启动,同时避免长期占用资源。 - 资源受限/短期任务 :设为
"5m"或更短,让系统自动管理,或主动用0释放显存。
- 高并发/生产环境 :推荐设为
- 注意事项
- 监控显存:常驻大模型会持续占用大量显存,运行多程序时需监控避免冲突。
- 谨慎多模型共存 :同时常驻多个模型会加剧显存压力,注意
OLLAMA_MAX_LOADED_MODELS的配置限制。 - 注意版本兼容 :部分旧版库可能将
keep_alive视为布尔值,使用时请查阅所用 SDK 的文档。
掌握了 keep_alive 参数,你就可以精细地控制 Ollama 模型的内存驻留行为。你可以按需在"即时响应"和"释放资源"之间自由切换,从而构建出既高效又稳定的 AI 应用。
3.2 流式输出
stream参数是控制Ollama API响应方式的开关。它决定了模型是像真人打字一样逐词输出 (stream: true),还是等待完整回答后一次性返回 (stream: false)。
和keep_alive控制模型"驻留多久"不同,stream只控制结果"如何呈现",并不影响模型在显存中的状态。
🔌 原理:它是如何工作的?
stream的两种模式对应着截然不同的数据传输方式。
| 参数值 | 响应格式 (Content-Type) | 数据传输方式 |
|---|---|---|
true (流式) |
application/x-ndjson |
服务器将生成的每个词或短语,作为一个独立的JSON对象,通过换行分隔的JSON (NDJSON) 流式发送。 |
false (非流式) |
application/json |
服务器在模型生成完所有内容后,将完整结果打包成一个标准的JSON对象一次性返回。 |
⚖️ 场景与效果对比
选择哪种模式,主要取决于你的应用场景。
| 特性 | 流式 (stream: true) | 非流式 (stream: false) |
|---|---|---|
| 响应速度 | 极低的感知延迟,可即时看到首个生成片段。 | 高感知延迟,用户需等待完整内容生成完毕。 |
| 适用场景 | 聊天机器人、实时文本生成、代码补全等注重交互体验的场景。 | 结构化数据提取、文本分类、单元测试等需要完整、可预测结果的场景。 |
| 开发复杂度 | 较高。需处理数据流、解析不完整JSON、累积片段并维护状态。 | 较低。一次请求即可获得完整、稳定的JSON,易于解析。 |
| 功能支持 | 完整支持常规对话、思考过程 (thinking) 和工具调用 (tool calling) 的流式输出。 | 不支持流式工具调用。如需使用tools参数,必须设置stream: false。 |
⚙️ 默认行为与语言SDK差异
了解不同环境下的默认设置,可以避免很多困惑。
| 调用方式 | stream 默认值 |
行为说明 |
|---|---|---|
| REST API | true |
直接调用 /api/generate 或 /api/chat 时,默认即为流式响应。 |
| Ollama 命令行 (CLI) | true |
在终端中运行 ollama run ... 时,默认就是打字机效果。 |
| 官方 Python SDK | false |
使用 ollama 库的 chat 或 generate 函数时,默认为非流式。 |
| 官方 JavaScript SDK | false |
与Python库一样,默认关闭流式传输,需手动开启。 |
🛠️ 实际应用示例
1. 流式 (stream: true)
-
REST API (cURL)
bash# 注意:无需显式设置stream: true,因为它是默认值 curl http://localhost:11434/api/generate -d '{ "model": "qwen3.5:4b", "prompt": "解释一下什么是API。" }' -
Python SDK
pythonfrom ollama import chat stream = chat( model='qwen3.5:4b-mine', messages=[{'role': 'user', 'content': '解释一下什么是API。'}], stream=True, # 必须显式开启 ) for chunk in stream: print(chunk['message']['content'], end='', flush=True)
2. 非流式 (stream: false)
-
REST API (cURL)
bashcurl http://localhost:11434/api/generate -d '{ "model": "qwen3.5:4b", "prompt": "将下面的句子翻译成中文:Hello World.", "stream": false }' -
Python SDK
pythonfrom ollama import chat response = chat( model='qwen3.5:4b-mine', messages=[{'role': 'user', 'content': '将下面的句子翻译成中文:Hello World.'}], # stream默认为False,可不写 ) print(response['message']['content'])
✨ 高级特性:工具调用与思考过程
对于支持高级功能的模型(如 qwen3),stream 参数能与工具调用和思考过程(thinking)无缝结合。
- 工具调用 :在流式模式下,
tool_calls信息会分散在多个数据块中,需要在客户端进行累积和重组。 - 思考过程 :支持思考的模型会在每个数据块中额外携带一个
thinking字段,用于展示模型的内部推理步骤。
💡 最佳实践
- 完整对话历史:在流式模式下,记得将分散的数据块累积起来,才能作为下一次请求的对话历史。
- 性能指标 :流式响应的最后一个数据块(
done: true)会包含详细的性能指标,如total_duration(总耗时)、eval_count(生成的token数)等,是分析性能的重要依据。 - 结构化输出 :当需要模型输出符合特定JSON格式的结果时,应将
stream设置为false,以便获取一个完整、合法的JSON对象。 - 超时设置:对于非流式请求,特别是可能生成大量文本的场景,务必设置一个足够长的客户端读取超时(如60秒),防止请求意外中断。
3.3 思考模式
think参数是Ollama为"推理模型"提供的"透明模式"开关,让你能窥见AI得出最终答案前的内部思考过程。
简单来说,think参数控制着推理模型在给出最终答案前,是否输出其内部思考过程。
think: true(慢思考) :让模型先输出thinking字段内容,再输出content最终答案。这就像展示了AI的"思考草稿"或"解题步骤",方便你debug或审计。think: false(快回答):强制模型跳过思考步骤,直接给出答案。这会显著加快响应速度,适合简单问答场景。
🧠 哪些模型支持思考?
并非所有模型都具备思考能力,目前主要支持以下几类(更多正在加入):
- Qwen 3 / 3.5 :支持
true/false。若运行时思考过程过长,可通过启动参数--think=false或交互命令/set nothink关闭以提速。 - GPT-OSS :仅支持
"low"、"medium"、"high"三个等级控制思考深度,传入true/false无效。 - DeepSeek R1 :支持
true/false。 - DeepSeek-v3.1 :支持
true/false。
🛠️ 如何设置think参数?
Ollama提供了多种方式来控制思考模式,从命令行到API调用,一应俱全。
1. CLI (命令行界面)
-
单次运行 :
bash# 启用思考(默认为true) ollama run qwen3.5 --think "你的问题" # 禁用思考,快速回答 ollama run qwen3.5 --think=false "你的问题" # 为GPT-OSS指定思考等级 ollama run gpt-oss --think=high "你的问题" -
交互模式 :
bash# 在交互对话中动态切换 /set think # 启用思考 /set nothink # 禁用思考 -
隐藏思考内容 :若想使用思考模型但不想看到其内部过程,可使用
--hidethinking标志,它会在后台运行思考逻辑,最终只展示答案。
2. API 调用
/api/chat和/api/generate端点均支持think参数。
-
Chat API 示例 (cURL):
bashcurl http://localhost:11434/api/chat -d '{ "model": "qwen3.5", "messages": [{"role": "user", "content": "如何实现一个单例模式?"}], "think": true, "stream": false }'成功响应中,
message对象将包含thinking和content两个字段,分别对应推理轨迹和最终答案。 -
Python 示例:
pythonfrom ollama import chat response = chat( model='qwen3.5', messages=[{'role': 'user', 'content': '解释一下"多态"的概念。'}], think=True, # 启用思考 stream=False ) print("思考过程:", response['message']['thinking']) print("最终答案:", response['message']['content'])
3. Modelfile 配置
可以在Modelfile中预定义think行为,但实际测试发现部分模型可能不生效,最稳妥的方式还是在API调用时动态指定。
dockerfile
FROM qwen3.5:4b
PARAMETER think false # 尝试默认禁用思考4. 流式处理思考内容
当启用流式响应(stream: true)时,思考过程会以数据块的形式先于答案到达。你需要根据message.thinking或message.content字段来区分它们。
📊 何时用,何时不用?
了解think参数的配置和用法后,核心在于如何选择。
| 场景 | 建议设置 | 原因 |
|---|---|---|
| 代码生成、复杂逻辑推理 | think: true |
模型会先规划、设计,生成的代码结构更清晰、健壮。 |
| 数学问题、数据分析 | think: true |
模型的思考轨迹包含了计算步骤,答案更可靠。 |
| 简单问答、闲聊、翻译 | think: false |
无需复杂推理,禁用思考可换取最快响应速度。 |
| 游戏NPC对话、实时交互 | think: false |
延迟是最重要的体验指标,快速响应比深度思考更重要。 |
| 模型调试、审计、教学 | think: true |
需要查看模型内部工作流程,以评估其决策路径。 |
🔗 与keep_alive、stream的协同
- 与
keep_alive:keep_alive管理模型在显存中的驻留,而think决定模型如何回答。两者互不干扰,可以自由组合。 - 与
stream:二者常结合使用。think: true开启思考,stream: true则能实时打印思考过程,极大提升交互感。
在Ollama的API调用中,让模型进行内部思考但不输出内容,有两种方式:
- 过滤响应数据 :在客户端收到模型返回的完整数据后,选择只使用或显示
content字段,主动忽略thinking字段。 - 使用API参数组合(
"think": true+"hide_thinking": true) :由服务端直接处理,API响应中只包含content字段,thinking字段完全不存在。这是更直接、更高效的方式。
📊 核心参数与效果对比
下表展示了在非流式 ("stream": false) 场景下,不同 think 和 hide_thinking 参数组合对响应内容的影响:
think |
hide_thinking |
响应内容 | 说明 |
|---|---|---|---|
false |
(不生效) | 只有 content 字段 |
模型不进行推理,响应最快。 |
true |
false (或不设置) |
包含 thinking 和 content 字段 |
可以查看推理轨迹,适合调试。 |
true |
true |
只有 content 字段 |
隐藏思考内容,模型内部推理,客户端仅显示最终答案。 |
🛠️ 示例:使用 hide_thinking 参数
该功能在Ollama的REST API、Python SDK和CLI中均可使用。
-
REST API (cURL) 示例
bashcurl http://localhost:11434/api/chat -d '{ "model": "qwen3.5:4b-mine", "messages": [{"role": "user", "content": "什么是闭包?"}], "stream": false, "think": true, "hide_thinking": true }'在此响应中,
message对象将只包含content字段。 -
Python SDK 示例
pythonfrom ollama import chat response = chat( model='qwen3.5:4b-mine', messages=[{'role': 'user', 'content': '什么是闭包?'}], stream=False, options={'think': True, 'hide_thinking': True} ) print(response['message']['content']) # 只打印最终答案 -
命令行 (CLI) 示例
bashollama run qwen3.5:4b-mine --think --hidethinking "什么是闭包?"
⚠️ 注意事项
- Modelfile 限制 :
think参数可在 Modelfile 中预设,但无法预设hide_thinking。它必须在每次API调用时动态设置。 - 与
stream: true配合 :在流式模式下,此组合依然生效。模型不会发送thinking字段的数据块,客户端可直接处理content的流式数据,逻辑更简单。 - 模型支持 :此功能适用于支持思考功能的模型,如 Qwen 3 系列 、DeepSeek R1 和 DeepSeek-v3.1。
4. ollama+agent
- 执行以下命令安装agent-mini,建议安装到全局python环境,这样可以方便启动agent-min,自动完成一些任务
bash
pip install agent-mini- 安装完成后,执行以下命令初始化配置信息
bash
agent-mini init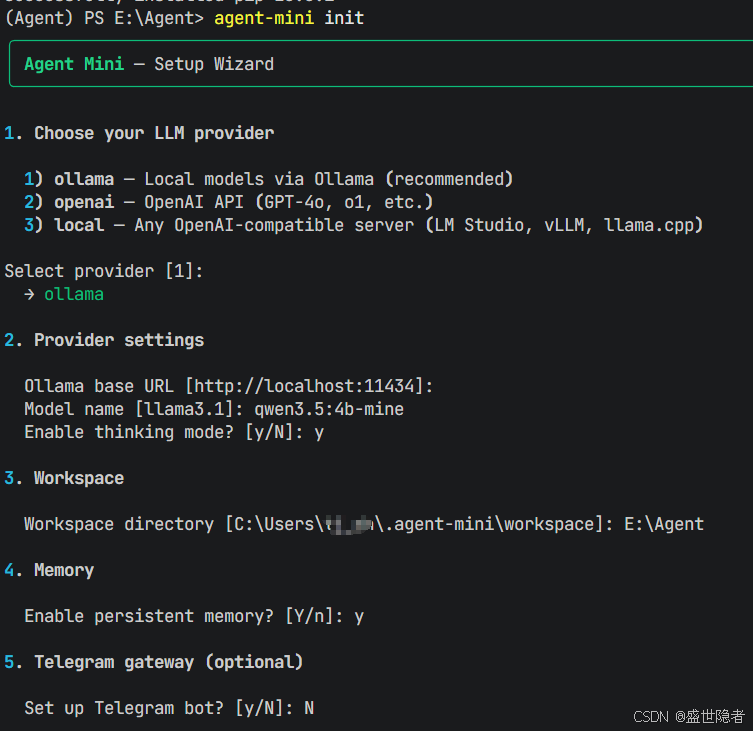
- 执行以下命令启动agent-mini,通过对话可以让ollama模型调用工具自动执行一些任务,比如文件与目录操作、网络搜索(无法使用,duckduckgo国内不支持)
bash
agent-mini chat