核心主张:V4 不只是"更便宜的 GPT-4o"------它重新定义了"百万上下文"从奢侈品变为基础设施的临界点。读懂这篇文章,你能在正确的场景用正确的配置,成本节省 80% 以上。
一、先建立认知:为什么"百万上下文"这次是真命题?
过去两年,"支持长上下文"是各家模型的营销词汇。但现实情况是:支持 128K 上下文并不意味着你能负担得起用它。上下文越长,KV Cache 越大,推理成本呈近似平方级增长。真正的长上下文能力,必须同时满足三个条件:支持、性能不下降、成本可接受。
DeepSeek-V4 的核心突破,正是第三点。
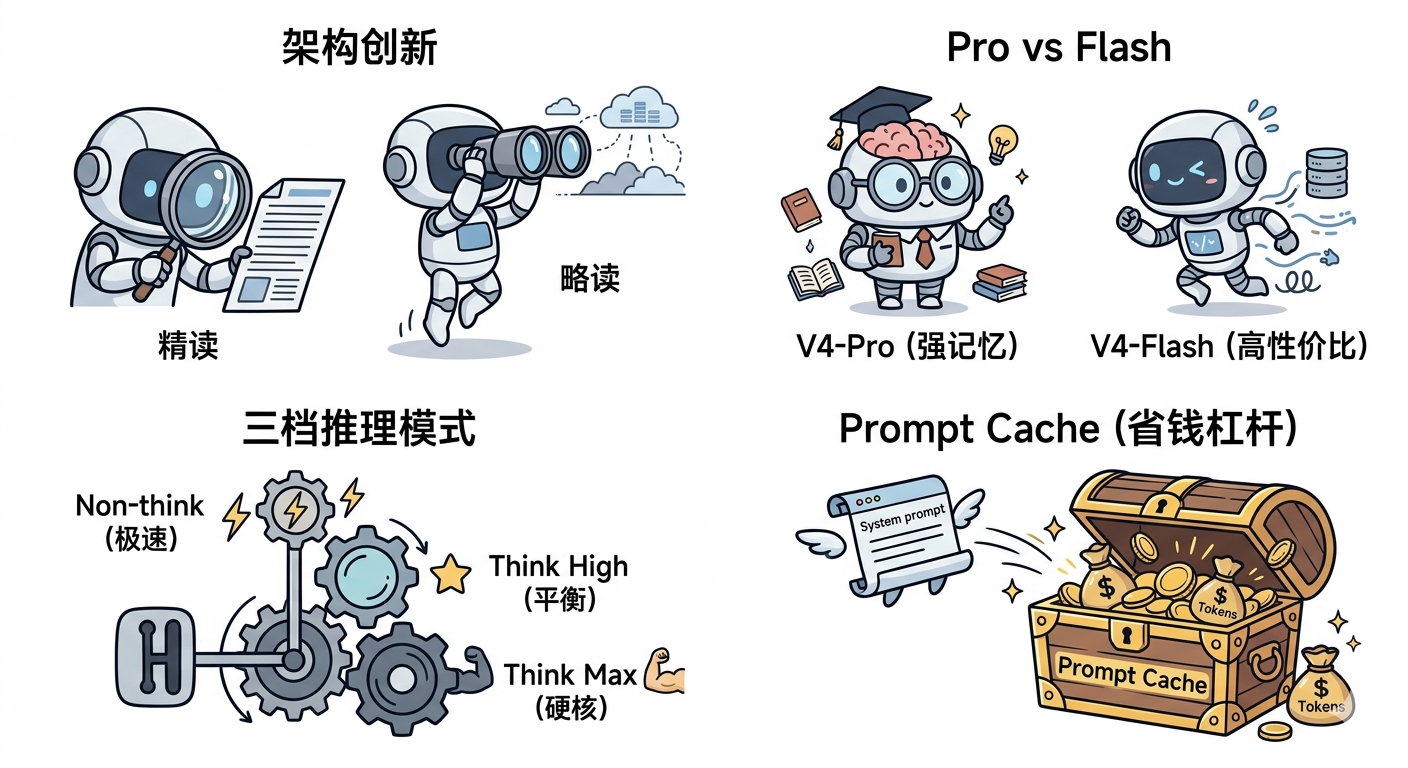
架构创新:从计算瓶颈到效率飞跃
根据 DeepSeek-V4 技术报告,V4-Pro 在百万 Token 上下文下,单 token 推理计算量仅为上一代 V3.2 的 27% ,KV Cache 占用压缩至 10% 。V4-Flash 更激进:计算量降至约 10% ,KV Cache 降至 7%。
这意味着什么?
这不是简单的工程优化,而是架构层的根本性重新设计。V4 采用混合注意力架构,交替部署两类注意力层:
CSA(压缩稀疏注意力) 负责"精读"------它维护一批"摘要词条"作为索引,配合快速检索机制(Lightning Indexer),处理需要精确定位的中程信息。类比一个熟练的文献综述者,能在 500 页报告里快速找到关键段落。
HCA(重度压缩注意力) 负责"略读"------极高压缩率的全局状态摘要,捕捉超长序列的宏观依赖关系。类比一个战略分析师,不需要记住每一个数字,但能把握整体趋势与因果。
两者交替工作,构成"精读 + 略读"的双层处理机制,使得模型在面对百万级 Token 时既不丢失细节,也不失去全局视野------同时大幅压缩计算成本。
这个架构创新的实际意义:百万上下文从"技术上可以"变成了"业务上值得"。整个代码库、一年的财报、完整的法律合同集,现在可以一次性塞进上下文,而不是担心账单。
二、家族谱系:V4-Pro 与 V4-Flash 的本质差异
先看核心参数对比:
| 维度 | V4-Pro(旗舰) | V4-Flash(性价比) |
|---|---|---|
| 总参数 / 激活参数 | 1.6T / 49B | 284B / 13B |
| 架构层数 / 隐维度 | 61 层 / 7168 | 43 层 / 4096 |
| 上下文 / 最大输出 | 1M / 384K | 1M / 384K |
| API 定价(输入/输出) | 1.74 / 3.48(每百万 Token) | 0.14 / 0.28(每百万 Token) |
关键发现:Flash 不是 Pro 的"低配版"
最反直觉的一个事实:Flash 不是 Pro 的蒸馏版,而是独立训练的模型。
根据技术报告,在编程和数学任务上,两者差距极小:
- SWE-bench Verified:Pro 80.6%,Flash 接近(差距约 1-2%)
- Terminal-Bench:Pro 67.9%,Flash 表现相近
这意味着"高难度推理"并不是 Pro 的专有优势。Pro 真正碾压 Flash 的场景,是知识密集型任务------即答案依赖模型记忆而非上下文推理的场景。
选型的第一原则由此产生:你的任务是"考记忆"还是"考推理"?
- 考记忆(常识性知识、百科事实、行业专识)→ Pro 有显著优势
- 考推理(代码、数学、逻辑分析、RAG 类任务)→ Flash 以约 8% 的成本实现接近 Pro 的效果
三、三档变速:推理模式的本质与边界
V4 全系支持通过 reasoning_effort 参数控制推理深度,本质上是在计算预算与输出质量之间做权衡。
none
high
max
用户请求
reasoning_effort
Non-think
直接输出
Think High
中等深度思维链
Think Max
穷尽推理潜力
速度最快
成本最低
质量与成本平衡
质量上限
成本最高
Non-think:被低估的生产力工具
很多人把 Non-think 当作"低配模式",这是误解。对于结果高度确定的任务------分类、提取、摘要、格式转换------思维链本身是噪音,不是信号。禁用它反而更快、更准、更便宜。
适用场景:实时聊天、日志打标、文本分类、关键词提取、结构化数据抽取。
关键优势:
- 响应速度最快
- 成本最低
- 适合高并发场景
Think High:日常复杂任务的最优解
Think High 是 V4 推理能力的"甜点区"。模型会生成中等深度的思考过程,这个过程不仅提升答案质量,还为开发者提供了极有价值的调试线索------你可以通过读模型的"内心独白"判断它是否走在正确的推理路径上,从而提前拦截错误。
适用场景:复杂代码编写、多步骤 Agent 任务、文档深度分析、逻辑推理题。
平衡点:在质量与 Token 消耗间取得最佳平衡。
Think Max:极端任务的保险丝
Think Max 没有推理 Token 上限,适合那些"答对了节省巨大成本、答错了带来严重后果"的场景。竞赛级算法题、形式化数学证明、高风险的自动化决策链------在这些场景下,多花几倍的推理 Token 是合理的投资。
注意:日常开发中不需要它。遇到 Think High 无法解决的问题,先检查 Prompt 质量,再考虑升级到 Think Max。
四、实战场景深度拆解
场景 A:企业级 RAG / 知识库问答
业务痛点:知识库动辄数十万字,每次查询都要把大量上下文塞进请求,成本和延迟都是问题。
V4 的解法:Flash 的百万上下文 + Prompt Cache 的组合,是目前市场上 RAG 场景的最优解。
Prompt Cache 的工作原理
Prompt Cache 的原理很简单:系统提示和知识库内容结构固定,DeepSeek 会自动缓存这部分内容。下次请求时,命中缓存的 Token 输入成本大幅降低。
KV Cache DeepSeek API 应用层 用户 KV Cache DeepSeek API 应用层 用户 提问 系统提示 + 知识库 + 问题 检查系统提示+知识库是否缓存 命中缓存 仅处理新增问题部分 返回答案 展示结果
关键操作要点:将系统提示和知识库置于消息列表最前,保持结构不变,只在末尾追加用户问题,缓存命中率可达较高水平。
成本对比(百万 Token):
| 方案 | 输入成本 | 输出成本 | 总体评价 |
|---|---|---|---|
| V4-Flash(缓存命中) | 显著降低 | $0.28/M | 极低成本 |
| GPT-4o | $2.50/M | $10.00/M | 参考基准 |
推荐配置:V4-Flash + Non-think(答案确定性强的检索)或 Think High(需要综合分析的复杂问答)。
场景 B:自主编程 Agent
业务痛点:多步骤编程任务要求模型在文件读写、代码分析、错误定位、重构执行之间连续决策,任何一步出错都可能导致整个任务失败。
为什么 Pro 在这里是必选:根据技术报告,V4-Pro 在 SWE-bench Verified 上达到 80.6%,在 Terminal-Bench 上达到 67.9%,表现优异。
更重要的是,在内部 R&D 编程基准测试中,V4-Pro-Max 的通过率达到 67%,接近 Claude Opus 4.5 的 70%,显著优于 Claude Sonnet 4.5 的 47%。
是
否
是
否
否
是
接收编程任务
Think High 规划任务分解
是否需要读取文件?
调用 read_file 工具
直接生成代码
分析代码结构
生成修改方案
是否需要验证?
调用 run_tests 工具
写入文件
测试通过?
调试推理循环
任务完成
推荐配置:V4-Pro + Think High(常规编程任务);极难任务考虑 Think Max。
场景 C:海量数据批处理(打标 / 摘要 / 分类)
业务痛点:千万级日志、评论、工单需要自动化处理,速度和成本是核心指标,质量要求相对宽松(准确率 90%+ 即可)。
V4-Flash 为什么是理想选择:
根据技术报告,V4-Flash 在设计时就考虑了高吞吐场景,其架构优化使得在处理大规模数据时具有显著的效率优势。
实际工程建议:用异步并发批量发送请求,对于结果确定性要求高的任务,可以设置低 temperature 减少随机性。
推荐配置:V4-Flash + Non-think。
场景 D:长文档分析与跨文档推理
业务痛点:法律合同审查、财报横向对比、学术文献综合------文本量大、需要跨文档建立联系、推理链条长。
这类场景最容易被误判为"必须用 Pro"。实际上,判断依据应该更细:
检索定位
找到某段话/数字
综合分析
跨文档推理
逻辑关系梳理
论点归纳
复杂因果推断
形式化论证
长文档分析任务
任务类型?
Flash + Non-think
速度快、成本低
推理深度?
Flash + Think High
性价比最优
Pro + Think High
知识深度优势
推荐配置:根据上图决策树选择,避免因为文档长就默认选 Pro。
场景 E:实时对话 / 语音助手后端
业务痛点:用户感知延迟极其敏感,首字延迟超过 2 秒就会影响体验。
Flash + Non-think 的组合是 V4 体系中响应最快的配置,对于语音助手场景,这是合理的选择。
推荐配置:V4-Flash + Non-think(严格实时);V4-Flash + Think High(允许一定延迟的复杂对话)。
五、选型决策树
五个问题,快速定位你的场景:
是
否
是
否
是
否
是
否
是
否
❓ 任务是否涉及\n10步以上工具链调用?
✅ V4-Pro\nThink High / Max
❓ 是否需要实时响应\n首字延迟要求高?
✅ V4-Flash\nNon-think
❓ 答案是否依赖\n模型的常识记忆?
✅ V4-Pro\nThink High
❓ 上下文是否\n超过 50 万 Token?
✅ V4-Flash\nNon-think / Think High
❓ 当前是否在\n优惠期内?\n2026/05/31 前
✅ V4-Pro 优惠期\n性价比极高
✅ V4-Flash\n默认首选
六、成本优化:三个杠杆
杠杆一:Prompt Cache
对于结构固定的请求(系统提示 + 知识库 + 用户问题),DeepSeek 自动缓存前两部分。命中后,输入成本显著降低。
操作要点:系统提示和知识库必须在消息列表最前,且结构保持一致。每次请求只在末尾追加用户消息。
杠杆二:模型选择
Flash 的百万 Token 总成本远低于 Pro。对于推理密集型任务(编程、数学、分析),Flash 以极低成本实现接近 Pro 的效果。
杠杆三:推理模式
同一模型下,Non-think → Think High → Think Max,推理 Token 占比逐步上升,对应成本增加。对于绝大多数任务,Think High 是上限,Think Max 是保险。
优惠期红利(2026/05/31 前):V4-Pro 享受大幅折扣。优惠期内,Pro 的成本与 Flash 正常价格接近,是窗口期。
七、开发者注意事项
多轮对话中的推理内容处理
这是容易踩坑的细节。当模型调用了工具时,推理内容需要正确处理以保持思维连贯性。
建议:查阅官方 API 文档,了解推理内容的正确处理方式。
旧模型名称废弃时间表
deepseek-chat 和 deepseek-reasoner 将于 2026/07/24 彻底废弃。
迁移映射:
deepseek-chat→deepseek-v4-flash(速度优先场景)或deepseek-v4-pro(质量优先场景)deepseek-reasoner→deepseek-v4-pro(搭配reasoning_effort="high"或"max")
建议在废弃日期前完成代码更新和回归测试。
八、常见误区澄清
误区一:Flash 是 Pro 的"低配版"
错。两者独立训练,定位不同。Flash 的编程和数学能力与 Pro 接近,成本远低于 Pro。对于推理密集型任务,Flash 是更理性的选择。
误区二:百万上下文 = 把所有信息都塞进去
错。长上下文是工具,不是策略。对于有明确检索目标的任务,RAG + 精确检索仍然比"全量塞入"更高效。只有当信息之间存在复杂交叉依赖时,全量上下文才有不可替代的价值。
误区三:Think Max 是"更好的 Think High"
错。Think Max 是"在极端任务上的保险",不是升级路径。对于日常复杂任务,Think Max 产生的额外推理 Token 大多是重复验证,边际收益递减。先用 Think High,真的解决不了再考虑 Think Max。
误区四:优惠期过了 Pro 就不值得用
需要具体计算。优惠期后,Pro 价格会恢复。对于工具调用准确率差异在你的场景下是否值得更高的成本,要做具体的业务测算,而不是直觉判断。
九、核心结论
一句话选型原则:记忆依赖 → Pro;推理密集 → Flash;实时场景 → Flash + Non-think;复杂 Agent → Pro + Think High;极端任务 → Pro + Think Max。
DeepSeek-V4 真正的价值不在于某个单点指标,而在于它把"百万上下文"从少数高价场景的专属能力,变成了任何具备合理架构的应用都能负担的基础设施。这个临界点的跨越,会改变接下来 AI 应用的设计思路。
参考资料
迁移提醒 :
deepseek-chat和deepseek-reasoner将于 2026/07/24 废弃。请尽快将代码中的模型名称更新为deepseek-v4-pro或deepseek-v4-flash。