哈希
- 什么是哈希?
- 哈希冲突
-
- 冲突的概念
- 冲突的避免
-
- 哈希函数设计
- [负载因子调节 ⭐](#负载因子调节 ⭐)
- 冲突的解决
- 冲突严重时的解决办法
- 手搓哈希桶(泛型实现)
-
- MyHashBuck的成员变量
- [根据 key 获取对应的 value: getVal(K key)](#根据 key 获取对应的 value: getVal(K key))
- [插入键值对:push(K key, V val)](#插入键值对:push(K key, V val))
- [扩容并重哈希: resize()](#扩容并重哈希: resize())
- 完整测试
-
- [模拟场景:自定义 Student 类作为 Key](#模拟场景:自定义 Student 类作为 Key)
- [测试 MyHashBuck 是否生效](#测试 MyHashBuck 是否生效)
- 插入、删除、查找的时间复杂度对比⭐
-
- [为什么是 O ( 1 ) O(1) O(1) 而不是 O ( N ) O(N) O(N)?⭐](#为什么是 O ( 1 ) O(1) O(1) 而不是 O ( N ) O(N) O(N)?⭐)
- 极端情况:性能退化⭐
- 时间与空间的权衡⭐
- HashMap和TreeMap
什么是哈希?
哈希(Hash) ,是一种将任意长度的输入 通过特定算法转换成固定长度输出 的计算机技术。这个输出的结果被称为哈希值 或消息摘要。
一个优秀的哈希函数通常具备以下核心特性:
- 确定性:相同的输入,无论计算多少次,产生的哈希值必然相同。
- 高效性:计算速度快。
- 不可逆性:从哈希值几乎不可能反向推导出原始数据。
- 抗碰撞性:找到两个不同的输入却产生相同的哈希值,在计算上是极其困难的。
哈希冲突
冲突的概念
由于输入空间是无限的(任意长度的数据),而输出空间是有限的,根据鸽巢原理 ,哈希冲突必然会发生 ,即两个不同的输入 K1 ≠ K2,却计算出了相同的哈希值 H(K1) = H(K2)。
冲突的避免
既然冲突无法根除,就要想办法减少冲突的概率。
哈希函数设计
好的哈希函数能让数据均匀分布在哈希表中,降低聚集的概率。
设计原则:
- 计算简单高效
- 哈希值分布均匀
- 充分利用所有输入信息
常见设计方法:
| 方法 | 说明 | 示例 |
|---|---|---|
| 直接定址法 | H(key) = key 或 H(key) = a·key + b |
适用于关键字连续的情况 |
| 除留余数法 | H(key) = key % p(p为质数) |
最常用,p取小于表长的最大质数 |
| 平方取中法 | 取key平方后的中间几位 | 适合不知道key分布的情况 |
| 折叠法 | 将key分割后叠加 | 适合key位数较多的情况 |
Java中 HashMap 的哈希计算采用了扰动函数,让高位也参与索引计算:
java
// JDK 1.8 HashMap.hash() 简化
static final int hash(Object key) {
int h;
// key.hashCode() 异或 其高16位,增加随机性
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}负载因子调节 ⭐
负载因子(Load Factor) = 表中已有元素个数 / 哈希表长度
这是控制冲突概率的关键参数:
- 负载因子越小 → 空间越充裕 → 冲突概率低 → 查找快,但空间浪费大
- 负载因子越大 → 空间利用率高 → 冲突概率高 → 查找变慢
Java中 HashMap 的设计:
- 默认负载因子 = 0.75
- 当元素数量 > 容量 × 0.75 时触发扩容 ,容量翻倍,并重哈希(Rehash) 所有元素
java
// HashMap的扩容阈值判断
if (++size > threshold) // threshold = capacity * loadFactor
resize();冲突的解决
当冲突真的发生时,需要具体的解决策略。主要分为闭散列 和开散列两大类。
闭散列(开放寻址法)
核心思想:所有元素都存储在哈希表数组中,发生冲突时,按某种探测序列寻找下一个空槽。
| 探测方式 | 公式 | 特点 |
|---|---|---|
| 线性探测 | H(key, i) = (H(key) + i) % m |
简单,但会产生聚集问题 |
| 二次探测 | H(key, i) = (H(key) + i²) % m |
缓解聚集,但可能探测不全 |
| 双重哈希 | H(key, i) = (H1(key) + i·H2(key)) % m |
分布最均匀,计算稍复杂 |
Java中的应用:ThreadLocal 的内部类 ThreadLocalMap 就使用了线性探测法来解决冲突。
java
// ThreadLocalMap 线性探测示意
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}开散列/哈希桶⭐
核心思想 :哈希表的每个槽位不再存储单个元素,而是存储一个容器 (链表或树),所有哈希值映射到同一位置的元素都放入这个容器中。因为冲突的元素被拉成一条链,所以也叫拉链法 。
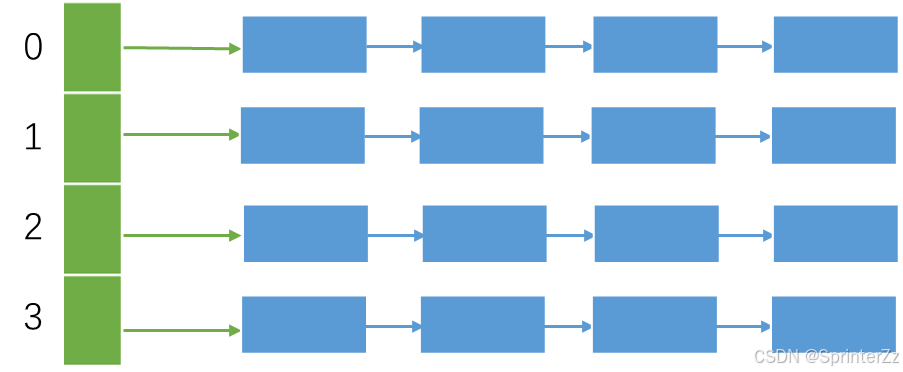
Java中的应用:HashMap 就是开散列的典型实现。JDK 1.8之后做了重大优化:
- 链表长度 < 8 时:使用单向链表
- 链表长度 ≥ 8 且数组长度 ≥ 64 时:链表树化为红黑树,将查找复杂度从 O(n) 降为 O(log n)
java
// HashMap 树化阈值
static final int TREEIFY_THRESHOLD = 8;
static final int MIN_TREEIFY_CAPACITY = 64;冲突严重时的解决办法
当冲突极其严重(例如链表过长或探测次数过多),需要采取系统性措施:
| 解决办法 | 说明 | Java中的应用 |
|---|---|---|
| 扩容+重哈希 | 扩大表容量,将所有元素重新计算位置 | HashMap自动扩容(2倍) |
| 链表转红黑树 | 当链表过长时转为树结构 | HashMap树化机制 |
| 更换哈希函数 | 如果原函数分布不均,换更好的算法 | 扰动函数的优化 |
| 应用层限流/熔断 | 极端情况下拒绝服务 | 业务层自我保护 |
手搓哈希桶(泛型实现)
MyHashBuck的成员变量
java
// 静态内部类:定义桶中的节点节点
static class Node<K, V> {
public K key; // 存储的键
public V val; // 存储的值
public Node<K, V> next; // 下一个节点引用(链表结构)
public Node(K key, V val) {
this.key = key;
this.val = val;
}
}
// 哈希桶数组,初始容量默认为 10
public Node<K, V>[] array = (Node<K, V>[]) new Node[10];
// 记录当前哈希表中存储的有效键值对数量
public int usedSize;
// 负载因子阈值:当 (usedSize / array.length) >= 0.75 时触发扩容
public static final double DEFAULT_LOAD_FACTOR = 0.75;根据 key 获取对应的 value: getVal(K key)
java
/**
* 根据 key 获取对应的 value
* @param key 目标键
* @return 对应的 value,若不存在则返回 null
*/
public V getVal(K key) {
// 1. 计算哈希地址:
// key.hashCode() 得到原始哈希值
// & 0x7FFFFFFF 是为了将符号位置 0,确保结果为正数
// % array.length 映射到当前数组下标范围
int index = (key.hashCode() & 0x7FFFFFFF) % array.length;
// 2. 遍历该下标位置的链表
Node<K, V> cur = array[index];
while (cur != null) {
// 注意:引用类型必须使用 equals 比较内容是否相等
if (cur.key.equals(key)) {
return cur.val;
}
cur = cur.next;
}
return null; // 链表遍历完没找到
}插入键值对:push(K key, V val)
java
/**
* 向哈希表中插入键值对
* @param key 键
* @param val 值
*/
public void push(K key, V val) {
// 计算目标下标
int index = (key.hashCode() & 0x7FFFFFFF) % array.length;
// 1. 检查是否存在重复的 key
Node<K, V> cur = array[index];
while (cur != null) {
if (cur.key.equals(key)) {
// 如果 key 已存在,则更新对应的 val 并结束
cur.val = val;
return;
}
cur = cur.next;
}
// 2. 插入新节点(执行到这里说明 key 不重复)
// 采用【头插法】:新节点的 next 指向当前桶的头节点,然后新节点变成为新的头
Node<K, V> newNode = new Node<>(key, val);
newNode.next = array[index];
array[index] = newNode;
usedSize++;
// 3. 检查负载因子是否超标
// 使用 (double) 强转防止整数除法导致精度丢失
if ((double) usedSize / array.length >= DEFAULT_LOAD_FACTOR) {
resize(); // 触发扩容
}
}扩容并重哈希: resize()
java
/**
* 扩容并重哈希
* 核心逻辑:数组长度变化后,所有节点原来的下标可能都会失效,必须重新计算
*/
private void resize() {
// 1. 创建一个新的二倍容量的数组
Node<K, V>[] newArray = (Node<K, V>[]) new Node[array.length * 2];
// 2. 遍历旧数组中的每一个桶
for (int i = 0; i < array.length; i++) {
Node<K, V> cur = array[i];
// 3. 遍历旧桶中的每一个链表节点
while (cur != null) {
// 【关键点】在修改 cur.next 之前,先记录原链表的下一个节点
Node<K, V> nextNode = cur.next;
// 4. 根据新数组长度重新计算当前节点在新数组中的下标
int newIndex = (cur.key.hashCode() & 0x7FFFFFFF) % newArray.length;
// 5. 将当前节点移动到新数组(同样使用头插法)
cur.next = newArray[newIndex];
newArray[newIndex] = cur;
// 继续处理原链表的下一个节点
cur = nextNode;
}
}
// 6. 将成员变量指向新数组
array = newArray;
}完整测试
模拟场景:自定义 Student 类作为 Key
假设要把 Student 对象存入 MyHashBuck。
java
import java.util.Objects;
public class Student {
public String id; // 学号
public String name; // 姓名
public Student(String id, String name) {
this.id = id;
this.name = name;
}
/**
* 重写 hashCode
* 目标:让 id 相同的学生产生相同的哈希值,从而进入同一个桶
*/
@Override
public int hashCode() {
// 使用 Objects 工具类,根据 id 和 name 生成哈希值
return Objects.hash(id, name);
}
/**
* 重写 equals
* 目标:当哈希冲突时,通过这个方法判断是不是同一个学生
*/
@Override
public boolean equals(Object o) {
// 1. 如果地址相同,肯定是同一个对象
if (this == o) return true;
// 2. 如果对比的对象为空,或者类不一致,肯定不是同一个
if (o == null || getClass() != o.getClass()) return false;
// 3. 强转为 Student
Student student = (Student) o;
// 4. 比较核心字段的内容(注意:String 的比较也要用 equals)
return Objects.equals(id, student.id) &&
Objects.equals(name, student.name);
}
}测试 MyHashBuck 是否生效
java
public class Test {
public static void main(String[] args) {
MyHashBuck<Student, String> map = new MyHashBuck<>();
Student s1 = new Student("101", "张三");
map.push(s1, "大二");
// new 一个内容完全一样的 s2
Student s2 = new Student("101", "张三");
// 如果重写了 hashCode 和 equals,这里能拿到 "大二"
// 如果没重写,这里会拿到 null
System.out.println("查询结果: " + map.getVal(s2));
}
}小技巧 :在 IntelliJ IDEA 中,按住
Alt + Insert,选择equals() and hashCode(),IDE 会自动生成代码。
插入、删除、查找的时间复杂度对比⭐
| 操作 | 平均复杂度 | 最坏复杂度 | 说明 |
|---|---|---|---|
| 查找 (Search) | O ( 1 ) O(1) O(1) | O ( N ) O(N) O(N) / O ( log N ) O(\log N) O(logN) | 取决于哈希分布和是否转红黑树 |
| 插入 (Insert) | O ( 1 ) O(1) O(1) | O ( N ) O(N) O(N) | 主要是因为扩容时的重哈希开销 |
| 删除 (Delete) | O ( 1 ) O(1) O(1) | O ( N ) O(N) O(N) | 先查找再修改指针,查找是关键 |
为什么是 O ( 1 ) O(1) O(1) 而不是 O ( N ) O(N) O(N)?⭐
虽然在拉链法中,查找操作实际上是在链表上进行的(这看起来像是 O ( N ) O(N) O(N)),但哈希表通过两个机制将其限制在常数时间:
- 哈希函数的均匀性 :一个好的
hashCode算法能将数据均匀地分散在各个桶中,避免大量数据堆积在同一个桶里。 - 负载因子(Load Factor)控制 :正如在代码中设置的
0.75。一旦数据量变大,导致平均每个桶里的节点变多时,哈希表会执行resize()扩容。 - 结论 :扩容保证了桶的数量随数据量同步增长,使得平均每个桶的链表长度 L L L 始终保持在一个很小的常数 (通常小于 8)。查找时间 = 计算哈希 + 遍历长度为 L L L 的链表,依然是 O ( 1 ) O(1) O(1)。
极端情况:性能退化⭐
虽然平均是 O ( 1 ) O(1) O(1),但作为开发者必须警惕最坏情况:
- 哈希冲突严重 :如果
hashCode方法写得极差(比如让所有对象都返回同一个整数),所有数据都会挤在同一个桶里,此时哈希表会退化成一个普通的链表 ,复杂度变成 O ( N ) O(N) O(N)。 - JDK 8 的优化 :为了防止这种极端退化,Java 的
HashMap引入了红黑树 。当链表长度超过 8 且数组长度超过 64 时,链表会转为红黑树。此时即使冲突严重,查找复杂度也能控制在 O ( log N ) O(\log N) O(logN)。
时间与空间的权衡⭐
哈希表的 O ( 1 ) O(1) O(1) 并不是免费的,它是用空间换时间:
- 空间浪费:为了保持低冲突率,数组中总会有大约 25% 以上的空位(负载因子 0.75)。
- 扩容开销 :当触发
resize()时,需要申请新数组并重新计算所有数据的哈希位置。虽然单次push可能因为触发扩容而变慢,但在多次操作中摊还(Amortized)下来,它依然属于常数级别。