Prompt进阶:9个月总结的核心工作流
让AI进入工程流程,而不是让它裸奔。
问题:你在帮AI还是在添乱?
大多数人用AI写代码的姿势:
- 输入需求
- 让它生成
- 报错了修一修
- 再生成
- 循环往复
结果:看似高效,实际埋坑。
一个忽略现有缓存层的函数,一个没考虑ORM规范的数据迁移,一个跟别处重复的API接口。这类错误安静、隐蔽,三个月后让整个系统雪崩。
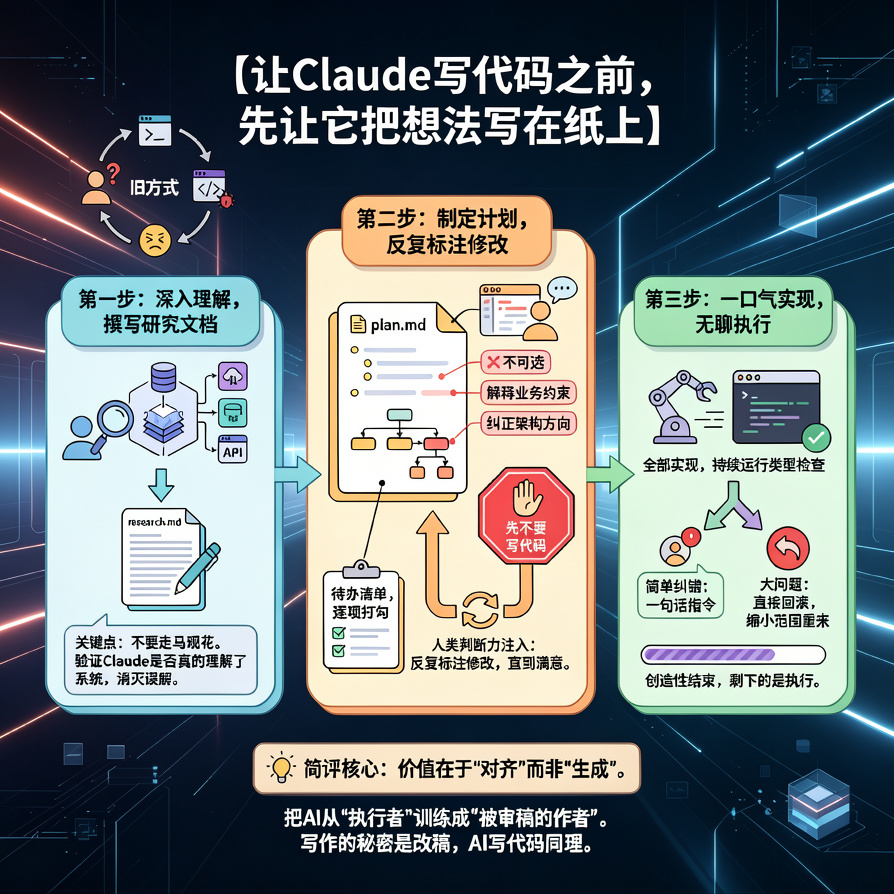
核心心法:需求先工件化,执行先加护栏
一句话总结:让需求先变成工件,让代码只在护栏里改。
❌ 帮我写个用户认证模块
✅ 先出方案,我审核通过后再写代码三步工作流(经过9个月验证)
第一步:让AI先读懂
帮我理解这个系统:
- 深入阅读src/目录下的代码
- 理解架构和数据流
- 复杂度、依赖关系、最容易出错的地方
把分析写进research.md,我确认后再下一步关键:用"深入"、"细节"、"复杂度"这类词,告诉AI别走马观花。
第二步:写计划,反复标注修改
基于对系统的理解,帮我出开发计划:
1. 要做什么
2. 改动哪些文件
3. 风险点在哪
4. 待实现的功能清单
写成plan.md然后:在编辑器里直接往plan.md加注释:
- 两个字的也有:"不可选"
- 一段话的也有:解释某个业务约束,或者纠正架构方向
最后把文档扔回给AI:
我加了一些注释,按注释更新plan.md,先不要写代码。第三步:一口气实现完
全部实现。
完成一项就在plan.md里标记。
不到所有任务完成不要停。
持续运行类型检查。进阶:OpenSpec工作流(来自真实项目验证)
对于真实生产项目,推荐用OpenSpec管理变更生命周期:
/opsx:propose → 需求拆解,产出proposal/design/tasks
↓
/opsx:apply → 执行代码改动
↓
/opsx:verify → 核对实现是否和change工件对齐
↓
/opsx:archive → 归档,保持上下文干净为什么这套流程重要?
| 阶段 | 问题 | 解决 |
|---|---|---|
| propose | 边界定义不清 | 先拆成工件,人审 |
| apply | AI自己扩需求 | 只做tasks.md范围内的事 |
| verify | 不知道改了什么 | 检查是否和工件对齐 |
| archive | 上下文越来越乱 | 归档保持干净 |
最佳实践:把"实现、评审、验证"彻底拆开
最危险的的不是AI写不出来,而是:
- 它在没有边界的情况下乱改
- 它不知道项目里的历史隐性约定
- 它把实现、评审、验证混在一起
- 它改完了代码,却没有把风险说清楚
- 它碰到了SQL、配置、脚本这类高风险区域,却没有硬护栏
应该拆成不同职责:
| 职责 | 做什么 |
|---|---|
| /opsx:verify | 检查实现是否和OpenSpec对齐 |
| prepare-review | 整理这次改了什么,方便人review |
| spring-architecture-review | 检查Spring分层有没有乱 |
| sql-risk-review | 检查SQL、批量更新的风险 |
| reviewer | 只读视角的代码审查 |
硬护栏:permissions + hooks
规则写进文档只是软约束,真正能拦住危险动作的,是权限和hook。
高风险目录(默认禁止修改):
- src/main/resources/application*.yml
- src/main/resources/db/
- sql/
- deploy/
- secrets/
权限配置示例(~/.claude/settings.json):
json
{
"permissions": {
"deny": [
"sql/*",
"deploy/*",
"src/main/resources/application-prod.yml"
]
}
}Hook自动检查:
json
{
"hooks": {
"BeforeWrite": [
{
"matcher": "*.sql",
"command": "echo 'SQL变更需要人工审核'"
}
]
}
}隐性约定要单独文档化
对真实业务项目来说,最危险的通常不是显式规则,而是那些"大家都知道,但没人写下来"的东西。
最佳实践:把所有容易导致"改完能跑、联调出错"的口头约定,单独沉淀到docs/implicit-contracts.md。
例如:
- 单元详情接口里,前端依赖contentResponse做回显
- status = null 和 status = 0 在历史语义上并不等价