c++从入门到跑路------string类

1.为什么学习string类?
1.1 C语言中的字符串
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列 的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户 自己管理,稍不留神可能还会越界访问。
1.2 两个面试题(暂不做讲解)
在OJ中,有关字符串的题目基本以string类的形式出现,而且在常规工作中,为了简单、方便、 快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数。讲白了,就是c语言那套面向过程的思想已经跟不上社会发展的变化了,而c++创新地采用了面向对象思想,利用封装,多态,继承,极大的提高了开发效率,以及开发潜力。
2.标准库中的string类
2.1 string类(了解)
cplusplus.com/reference/string/string/?kw=string
这个链接是关于c++里面string类的文档介绍
注意:在使用string类时,必须包含#include头文件以及using namespace std;
2.2 auto和范围for
auto关键字
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,后来这个 不重要了。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型 指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期 推导而得。
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际 只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
在这里补充2个C++11的小语法,方便我们后面的学习。
(1)auto不能作为函数的参数,可以做返回值,但是建议谨慎使用
(2) auto不能直接用来声明数组
#include<iostream>
using namespace std;
int func1()
{
return 10;
}
// 不能做参数
void func2(auto a)
{}
// 可以做返回值,但是建议谨慎使用
auto func3()
{
return 3;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = func1();
// 编译报错:rror C3531: "e": 类型包含"auto"的符号必须具有初始值设定项
auto e;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
int x = 10;
auto y = &x;
auto* z = &x;
auto& m = x;
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
cout << typeid(z).name() << endl;
auto aa = 1, bb = 2;
// 编译报错:error C3538: 在声明符列表中,"auto"必须始终推导为同一类型
auto cc = 3, dd = 4.0;
// 编译报错:error C3318: "auto []": 数组不能具有其中包含"auto"的元素类型
auto array[] = { 4, 5, 6 };
return 0;
}
#include<iostream>
#include <string>
#include <map>
using namespace std;
auto aa = 1, bb = 2;
// 编译报错:error C3538: 在声明符列表中,"auto"必须始终推导为同一类型
auto cc = 3, dd = 4.0;
// 编译报错:error C3318: "auto []": 数组不能具有其中包含"auto"的元素类型
auto array[] = { 4, 5, 6 };
int main()
{
std::map<std::string, std::string> dict = { { "apple", "苹果" },{ "orange",
"橙子" }, {"pear","梨"} };
// auto的用武之地
//std::map<std::string, std::string>::iterator it = dict.begin();
auto it = dict.begin();
while (it != dict.end())
{
cout << it->first << ":" << it->second << endl;
++it;
}
return 0;
}范围for
对于一个有范围的集合=而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此 C++11中引入了基于范围的for循环。for循环后的括号由冒号" :"分为两部分:第一部分是范围 内用于迭代的变量,第二部分则表示被迭代的范围,自动迭代,自动取数据,自动判断结束 范围for可以作用到数组和容器对象上进行遍历 范围for的底层很简单,容器遍历实际就是替换为迭代器,这个从汇编层也可以看到
#include<iostream>
#include <string>
#include <map>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
// C++98的遍历
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
{
array[i] *= 2;
}
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
{
cout << array[i] << endl;
}
// C++11的遍历
for (auto& e : array)
e *= 2;
for (auto e : array)
cout << e << " " << endl;
string str("hello world");
for (auto ch : str)
{
cout << ch << " ";
}
cout << endl;
return 0;
}2.3 string类的常用接口说明(注意下面我只讲解最常用的接口)
1.string类对象的常见构造
构造函数链接:
http://www.cplusplus.com/reference/string/string/string/

一、string () 无参构造函数(重点)
1. 形参类型解释
无输入形参,为无参构造函数。
2. 函数的功能与代码实现
核心功能 :构造一个空的std::string对象,字符串长度为 0,无有效字符,仅初始化底层基础内存结构,无字符数据存储。
#include <iostream>
#include <string>
using namespace std;
int main() {
// 基础用法:构造空字符串
string empty_str;
cout << "空字符串长度:" << empty_str.size() << endl; // 输出 0
cout << "是否为空:" << empty_str.empty() << endl; // 输出 1(true)
// 典型场景:先构造空串,后续赋值
string str;
str = "hello world";
cout << "赋值后内容:" << str << endl; // 输出 hello world
return 0;
}3. 开发中的注意事项
- 空 string 对象是合法、可安全操作 的对象,不是空指针,调用
empty()、size()、赋值等成员函数不会触发崩溃; - 空串的底层内存会在后续赋值 / 追加内容时自动扩容分配,无需手动管理。
二、string (const char* s) 构造函数(重点)
1. 形参类型解释
形参为const char* s:指向以\0结尾的 C 风格字符串的只读指针。
*为什么必须用 const char(一针见血)**:
- 兼容字符串字面量 :双引号包裹的
"xxx"本质是const char[N],只能绑定到const char*,非 const 的char*无法接收,会直接编译报错; - 保证入参安全:const 承诺函数内部不会修改原字符串内容,避免误改只读内存导致程序崩溃;
- 通用性最强 :可同时接收
const char*、char*、字符数组、字符串字面量,覆盖所有 C 风格字符串场景。
2. 函数的功能与代码实现
核心功能 :读取入参s指向的 C 风格字符串(从起始地址到\0为止),将内容全量拷贝到新构造的std::string对象中,生成与原 C 字符串内容完全一致的 C++ 字符串。
#include <iostream>
#include <string>
using namespace std;
int main() {
// 最常用:用字符串字面量直接构造
string str1("hello C++");
cout << "str1: " << str1 << endl; // 输出 hello C++
// 用char数组(C风格字符串)构造
char c_arr[] = "C style string";
string str2(c_arr);
cout << "str2: " << str2 << endl; // 输出 C style string
// 用const char*指针构造
const char* c_ptr = "const char string";
string str3(c_ptr);
cout << "str3: " << str3 << endl; // 输出 const char string
return 0;
}3. 开发中的注意事项
- 入参
s必须以 **\0空字符结尾 **,否则会触发内存越界读取,导致程序崩溃或乱码; - 禁止传入
nullptr、野指针、未初始化的指针,会触发未定义行为,直接导致程序崩溃; - 空串
""是合法入参,会构造一个空的 string 对象,与无参构造效果一致。
三、string (size_t n, char c) 构造函数
1. 形参类型解释
size_t n:无符号整数类型,指定最终生成字符串的固定长度(字符个数);char c:基础字符类型,用于填充字符串的单个字符。
2. 函数的功能与代码实现
核心功能 :构造一个长度为n的 string 对象,字符串的每一个字符都统一为入参的字符c。
#include <iostream>
#include <string>
using namespace std;
int main() {
// 基础用法:生成5个'a'组成的字符串
string str1(5, 'a');
cout << "str1: " << str1 << endl; // 输出 aaaaa
// 实用场景:生成分隔线
string split_line(20, '-');
cout << split_line << endl; // 输出 --------------------
// 给已有字符串赋值
string str2;
str2 = string(4, '9');
cout << "str2: " << str2 << endl; // 输出 9999
return 0;
}3. 开发中的注意事项
size_t是无符号类型,禁止传入负数,负数会被隐式转换为极大的无符号数,导致内存分配失败、程序崩溃;- 字符
c必须用单引号' '包裹,双引号包裹的是字符串,会编译报错; - 当
n=0时,会构造一个空的 string 对象。
四、string (const string& s) 拷贝构造函数(重点)
1. 形参类型解释
形参为const string& s:std::string类型的只读左值引用。
为什么用 const string&:
- 提升效率:传引用避免拷贝整个字符串的全量数据,仅传递地址,极大降低性能开销;
- 保证原对象安全:const 承诺函数不会修改原字符串对象,同时可接收 const / 非 const 的 string 对象、临时 string 对象;
- 符合 C++ 语法规范:拷贝构造函数的标准签名要求,是实现值语义的核心,保证拷贝的合法性。
2. 函数的功能与代码实现
核心功能 :用一个已存在的 string 对象s,深拷贝构造出一个内容、长度完全一致的新 string 对象;新对象拥有独立的内存空间,与原对象互不影响,修改其中一个不会改变另一个。
#include <iostream>
#include <string>
using namespace std;
int main() {
// 基础用法:拷贝构造
string origin("origin string");
string copy_str(origin); // 调用拷贝构造
cout << "原字符串:" << origin << endl; // 输出 origin string
cout << "拷贝字符串:" << copy_str << endl; // 输出 origin string
// 验证深拷贝:修改拷贝对象,原对象不受影响
copy_str = "modified string";
cout << "修改后拷贝字符串:" << copy_str << endl; // 输出 modified string
cout << "原字符串:" << origin << endl; // 仍输出 origin string
return 0;
}3. 开发中的注意事项
- 该函数是深拷贝,新对象有独立的内存空间,与原对象生命周期完全解耦;
- 当 string 对象以值传递的方式传入函数、或以值的方式返回时,编译器会自动调用该拷贝构造函数;
- 标准库已处理自赋值场景,无需额外判断,但开发中应避免
string s(s);这类无意义的自拷贝写法。
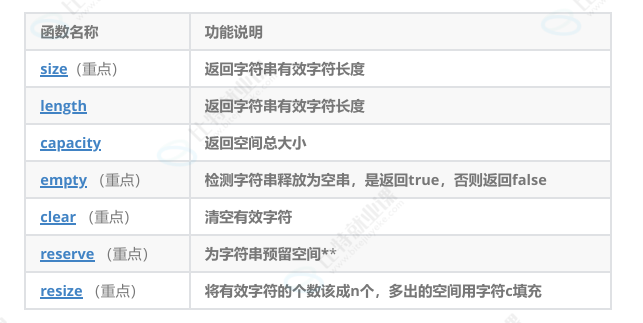
2.string类对象的容量操作
链接如下:
cplusplus.com/reference/string/string/?kw=string
注意:
1.size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接 口保持一致,一般情况下基本都是用size()。
2.clear()只是将string中有效字符清空,不改变底层空间大小。
3.resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不 同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数 增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
4.reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参 数小于string的底层空间总大小时,reserver不会改变容量大小
一、size () 函数(重点)
1. 函数应用场景
日常开发中获取字符串有效字符个数的核心函数,用于循环遍历字符串的边界控制、用户输入长度合规校验、字符串截取的边界判断等所有需要获取字符串实际有效长度的场景,是 string 类最高频使用的函数之一。
2. 函数的功能与代码实现
核心功能 :返回 string 对象中有效字符的个数 ,不包含底层自动添加的\0结束符,返回值类型为无符号整数size_t。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello C++";
// 核心用法:获取有效长度
size_t valid_len = str.size();
cout << "有效字符长度:" << valid_len << endl; // 输出9
// 典型场景:长度合规校验
if (str.size() > 5) {
cout << "字符串长度符合要求" << endl;
}
return 0;
}3. 开发中的注意事项
- 返回值是
size_t无符号整数,禁止与负数做比较(无符号数会将负数转为极大值,导致判断逻辑永久失效); - 仅统计有效字符,不含底层自动添加的
\0结束符; - 空字符串调用
size()返回 0,是安全操作,不会触发崩溃。
二、length () 函数
1. 函数应用场景
与size()功能完全等价,是 C++ string 类的历史兼容设计,仅用于老项目代码维护,新开发代码不推荐优先使用。
2. 函数的功能与代码实现
核心功能 :和size()完全一致,返回 string 对象的有效字符个数,返回值类型为size_t,底层共用同一套实现逻辑。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "test string";
cout << "length()结果:" << str.length() << endl; // 输出11
cout << "size()结果:" << str.size() << endl; // 输出11,结果完全一致
return 0;
}3. 开发中的注意事项
- 功能、性能、返回值与
size()完全无差异; - 新开发代码优先使用
size(),符合 STL 容器的统一命名规范(vector、list 等容器均用size()获取长度),提升代码可读性; - 同样需注意返回值是无符号类型,避免与有符号数错误比较。
三、capacity () 函数
1. 函数应用场景
用于查看 string 底层已分配的内存容量 ,分析字符串自动扩容的性能损耗,配合reserve()做内存预分配优化,高频用于循环拼接字符串、大数据量字符串处理等需要性能调优的场景。
2. 函数的功能与代码实现
核心功能 :返回 string 对象底层已分配的内存空间可容纳的最大字符个数 ,不含\0结束符的占用空间,capacity的值始终大于等于size。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello";
cout << "有效长度size:" << str.size() << endl;
cout << "已分配容量capacity:" << str.capacity() << endl;
// 追加字符,观察自动扩容
str += "12345678901234567890";
cout << "追加后size:" << str.size() << endl;
cout << "追加后capacity:" << str.capacity() << endl; // 容量自动扩容,常见1.5/2倍增长
return 0;
}3. 开发中的注意事项
capacity是已分配的内存上限 ,不是有效字符长度,有效长度始终以size为准;- 不同编译器的 string 扩容策略不同,
capacity的值不具备跨编译器一致性; capacity不会自动缩小,即使clear()清空字符串,已分配的内存通常也不会释放。
四、empty () 函数(重点)
1. 函数应用场景
高频用于字符串判空 ,比如用户输入合法性校验、接口入参空值判断、循环终止条件判断,是比if(str.size() == 0)更高效、可读性更强的写法。
2. 函数的功能与代码实现
核心功能 :检测 string 是否为空串(有效字符长度为 0),空则返回true,非空返回false,返回值类型为bool。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str1 = "";
string str2 = "hello";
// 核心用法:判空
cout << "str1是否为空:" << str1.empty() << endl; // 输出1(true)
cout << "str2是否为空:" << str2.empty() << endl; // 输出0(false)
// 典型场景:输入校验
string user_input;
if (user_input.empty()) {
cout << "输入不能为空,请重新输入" << endl;
}
return 0;
}3. 开发中的注意事项
empty()是O (1) 时间复杂度 ,部分编译器底层直接判断标志位,比size() == 0性能更优,判空优先使用empty();- 仅判断有效字符是否为 0,与
capacity无关,即使capacity不为 0,size为 0 时empty()也返回true; - 空 string 对象调用
empty()是安全操作,无崩溃风险。
五、clear () 函数(重点)
1. 函数应用场景
清空字符串的有效内容,重置为空串,用于循环复用 string 对象、处理完字符串后重置状态、清空无效内容,是重置字符串最常用的方法。
2. 函数的功能与代码实现
核心功能 :清空 string 对象的所有有效字符,将size置为 0,不会释放底层已分配的capacity内存,后续复用无需重新分配内存,执行效率更高。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello world";
cout << "清空前size:" << str.size() << endl;
cout << "清空前capacity:" << str.capacity() << endl;
// 核心用法:清空字符串
str.clear();
cout << "清空后size:" << str.size() << endl; // 输出0
cout << "清空后capacity:" << str.capacity() << endl; // 容量保持不变
return 0;
}3. 开发中的注意事项
clear()仅清空有效字符,不释放底层内存,适合后续复用该 string 对象的场景;- 如需清空同时释放内存,需在
clear()后调用shrink_to_fit(); - 空字符串调用
clear()是安全操作,无副作用。
六、reserve () 函数(重点)
1. 函数应用场景
预分配内存,避免字符串频繁自动扩容导致的性能损耗,是高频字符串拼接、大数据量字符串处理的核心优化手段,比如循环拼接大量字符、日志内容拼接、文件内容读取到 string 中,提前知道最终长度时使用。
2. 函数的功能与代码实现
核心功能 :为 string 对象预分配至少能容纳 n 个字符的内存空间 ,仅修改capacity的值,不会改变size(有效字符长度),也不会修改字符串的实际内容。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str;
cout << "初始capacity:" << str.capacity() << endl;
// 核心用法:预分配1000个字符的容量
str.reserve(1000);
cout << "reserve后capacity:" << str.capacity() << endl; // 容量≥1000
cout << "reserve后size:" << str.size() << endl; // 输出0,有效长度不变
// 优化场景:循环拼接,避免多次扩容
for (int i = 0; i < 1000; i++) {
str += 'a';
}
cout << "拼接后capacity:" << str.capacity() << endl; // 容量不会再次扩容
return 0;
}3. 开发中的注意事项
reserve(n)是预分配至少 n 的容量 ,编译器可能分配比 n 更大的空间,保证capacity≥n;- 当 n 小于当前
capacity时,reserve()不会缩容,不会修改capacity,属于无操作; - 仅修改内存容量,不改变有效字符和
size,不会修改字符串内容; - 仅当提前知道字符串最终长度时使用,否则无优化意义,过度预分配会造成内存浪费。
七、resize () 函数(重点)
1. 函数应用场景
修改字符串的有效字符长度,用于截断过长的字符串、扩容字符串并填充指定字符、固定长度字符串的初始化,需要同时修改有效长度和字符串内容的场景。
2. 函数的功能与代码实现
核心功能 :修改 string 对象的有效字符个数size为 n ,分两种核心场景,提供两个重载版本:void resize(size_t n);、void resize(size_t n, char c);
-
n < 当前
size:截断字符串,保留前 n 个有效字符,size变为 n,capacity不变; -
n > 当前
size:扩容有效长度到 n,多出的位置用指定字符c填充(不指定则默认用\0填充),若 n 超过capacity会自动扩容。#include
#include
using namespace std;int main() {
string str = "hello";
cout << "初始内容:" << str << " | size:" << str.size() << endl; // hello | 5// 用法1:截断字符串 str.resize(3); cout << "截断后内容:" << str << " | size:" << str.size() << endl; // hel | 3 // 用法2:扩容并指定填充字符 str.resize(6, 'x'); cout << "扩容后内容:" << str << " | size:" << str.size() << endl; // helxxx | 6 // 用法3:扩容不指定填充字符,默认用'\0'填充 str.resize(8); cout << "默认扩容后size:" << str.size() << endl; // 8 return 0;}
3. 开发中的注意事项
resize()直接修改有效字符长度size,会改变字符串的实际内容 ,这是和reserve()最核心的区别;- 当 n 超过当前
capacity时,会自动扩容capacity,扩容策略由编译器决定; - 截断字符串时,仅修改
size,不会释放底层capacity内存; - 填充字符仅在扩容时生效,截断时不会修改保留的字符内容。
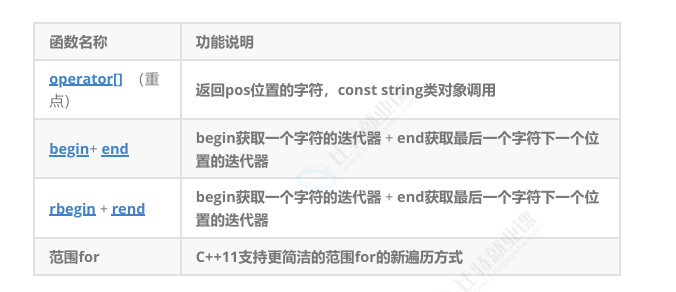
3.string类对象的访问及遍历操作
链接:
cplusplus.com/reference/string/string/?kw=string
一、operator \[\] 运算符重载(重点)
1. 函数应用场景
string 类单个字符的随机访问与修改的核心方式,支持数组式的下标操作,O (1) 时间复杂度,是日常开发中最高频的字符访问方式,适用于指定位置字符读写、下标循环遍历、单字符修改等场景。
2. 函数的功能与代码实现
核心功能 :重载 \[\] 运算符,返回字符串中下标pos位置字符的引用;非 const 对象调用返回可写引用,支持修改字符;const 对象调用返回 const 只读引用,仅支持读操作,不可修改字符。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello";
// 1. 读操作:获取指定下标字符
cout << "下标1的字符:" << str[1] << endl; // 输出 e
// 2. 写操作:修改指定下标字符
str[0] = 'H';
cout << "修改后字符串:" << str << endl; // 输出 Hello
// 3. 下标循环遍历
for (size_t i = 0; i < str.size(); ++i) {
cout << str[i] << " ";
}
// const对象只读访问
const string const_str = "const test";
cout << "\nconst对象下标0:" << const_str[0] << endl; // 合法只读
// const_str[0] = 'C'; // 非法,编译报错,const引用不可修改
return 0;
}3. 开发中的注意事项
- 下标合法范围为
0 ≤ pos < str.size(),越界访问会触发未定义行为,大概率导致程序崩溃,operator \[\]不做边界检查; - 如需带边界安全检查的访问,使用
at()成员函数,越界会抛出out_of_range异常; - 空字符串访问下标 0 行为未定义,访问前必须先判空;
- const 对象仅能调用 const 版本的 operator \[\],不可修改字符内容。
二、begin () + end () 正向迭代器对
1. 函数应用场景
string 类STL 兼容的正向遍历、区间操作的标准方式,是所有 STL 容器通用的遍历规范,适配 sort、reverse 等所有 STL 算法,适用于全量 / 区间正向遍历、容器通用代码编写、配合 STL 算法做字符串处理等场景。
2. 函数的功能与代码实现
核心功能:
-
begin():返回指向字符串第一个有效字符的正向迭代器; -
end():返回指向字符串最后一个有效字符的下一个位置的尾后迭代器(不指向任何有效字符,不可解引用); -
两者组成左闭右开区间
[begin(), end()),完整覆盖所有有效字符;const 对象调用返回 const 迭代器,仅可读不可修改。#include
#include
#include
using namespace std;int main() {
string str = "abcdef";
// 1. 正向迭代器遍历
string::iterator it;
for (it = str.begin(); it != str.end(); ++it) {
cout << *it << " "; // 解引用获取字符
}
cout << endl;
// 2. 迭代器修改字符
for (it = str.begin(); it != str.end(); ++it) {
*it = toupper(*it); // 转大写
}
cout << "转大写后:" << str << endl; // 输出 ABCDEF
// 3. 配合STL算法:反转字符串
reverse(str.begin(), str.end());
cout << "反转后:" << str << endl; // 输出 FEDCBA
return 0;
}
3. 开发中的注意事项
end()是尾后迭代器,绝对禁止解引用、自增操作,否则触发未定义行为;- 字符串发生扩容(如 push_back、append)、删除操作后,原迭代器会失效,不可继续使用;
- const 对象只能获取 const 迭代器,无法通过 const 迭代器修改字符;
- 迭代器遍历是 STL 容器通用规范,代码可无缝适配 vector、list 等其他 STL 容器。
三、rbegin () + rend () 反向迭代器对
1. 函数应用场景
string 类反向遍历、逆序区间操作的专用方式,无需手动倒序控制下标,适用于从后往前查找字符、逆序输出字符串、逆序区间处理等场景,代码更简洁安全。
2. 函数的功能与代码实现
核心功能:
-
rbegin()(reverse begin):返回指向字符串最后一个有效字符的反向迭代器; -
rend()(reverse end):返回指向字符串第一个有效字符的前一个位置的反向尾后迭代器,不可解引用; -
两者组成左闭右开的反向区间
[rbegin(), rend()),完整覆盖所有有效字符;反向迭代器执行++操作时,会向字符串头部移动,实现逆序遍历。#include
#include
using namespace std;int main() {
string str = "hello";
// 1. 反向遍历
string::reverse_iterator rit;
for (rit = str.rbegin(); rit != str.rend(); ++rit) {
cout << *rit << " "; // 输出 o l l e h
}
cout << endl;
// 2. 反向修改字符
for (rit = str.rbegin(); rit != str.rend(); ++rit) {
*rit = toupper(*rit);
}
cout << "转大写后:" << str << endl; // 输出 HELLO
// 3. const对象只读反向遍历
const string const_str = "reverse test";
string::const_reverse_iterator crit;
for (crit = const_str.rbegin(); crit != const_str.rend(); ++crit) {
cout << *crit << " ";
}
return 0;
}
3. 开发中的注意事项
rend()是反向尾后迭代器,禁止解引用、自增操作,否则触发未定义行为;- 反向迭代器的
++操作是向字符串头部移动,与正向迭代器移动方向相反; - 字符串扩容、删除操作后,原反向迭代器会失效,不可继续使用;
- 如需完整反转整个字符串,优先使用
reverse(str.begin(), str.end()),比反向遍历赋值性能更优。
四、范围 for 循环(C++11 及以上)
1. 函数应用场景
C++11 新增的极简全量遍历语法,无需关心下标、迭代器边界,代码可读性极强,适用于无特殊区间要求的字符串全量遍历,是日常开发中无特殊需求时的首选遍历方式。
2. 函数的功能与代码实现
核心功能 :底层基于begin()+end()迭代器实现,自动遍历字符串的全部有效字符,自动处理迭代器的起止与移动,无需手动管理边界;支持只读遍历与可写遍历。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello world";
// 1. 只读遍历:值拷贝,不修改原字符串
for (char ch : str) {
cout << ch << " ";
}
cout << endl;
// 2. 可写遍历:引用传递,直接修改原字符串
for (char& ch : str) {
ch = toupper(ch);
}
cout << "转大写后:" << str << endl; // 输出 HELLO WORLD
// 3. 高效只读遍历:const引用避免拷贝
const string const_str = "const test";
for (const char& ch : const_str) {
cout << ch << " ";
}
return 0;
}3. 开发中的注意事项
- 范围 for 仅支持全量遍历整个字符串,无法指定区间、无法反向遍历,有区间要求的场景需使用普通迭代器;
- 遍历过程中,若对字符串执行扩容、删除操作,会导致底层迭代器失效,遍历行为未定义,禁止在范围 for 循环内修改字符串容量;
- 只读遍历推荐使用
const char&,避免字符拷贝,提升性能;需要修改原字符串必须使用char&,值拷贝的修改不会影响原字符串; - 仅支持 C++11 及以上标准,老版本编译器需开启对应编译标准。
4.string类对象的修改操作

注意: 1. 在string尾部追加字符时,s.push_back© / s.append(1, c) / s += 'c'三种的实现方式差 不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可 以连接字符串。
- 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
一、push_back 函数
1. 函数应用场景
单字符粒度的字符串尾部追加,是最小单位的字符串拼接操作,适用于循环逐个读取字符、单字符增量拼接的场景,比如从输入流逐字符读取、字符过滤后追加存储。
2. 函数的功能与代码实现
核心功能:在 string 对象的尾部追加 1 个 char 类型字符,自动维护字符串有效长度 size,容量不足时触发自动扩容,无返回值。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello";
// 核心用法:尾部追加单个字符
str.push_back(' ');
str.push_back('w');
cout << "基础追加后:" << str << endl; // 输出 hello w
// 典型场景:循环追加字符
for (char c = 'o'; c <= 'd'; c++) {
str.push_back(c);
}
cout << "循环追加后:" << str << endl; // 输出 hello world
return 0;
}3. 开发中的注意事项
- 仅支持追加单个 char 字符,传入字符串、多个字符会直接编译报错;
- 频繁调用会触发多次自动扩容,有性能损耗,提前知晓总长度建议先用
reserve()预分配内存; - 追加触发扩容后,原字符串的迭代器、指针、引用会全部失效,不可继续使用。
二、append 函数
1. 函数应用场景
批量字符 / 字符串的尾部追加,比 push_back 效率更高,支持多类型入参的灵活拼接,适用于整串追加、指定区间片段追加、批量重复字符追加等多字符拼接场景。
2. 函数的功能与代码实现
核心功能:在 string 尾部追加指定的字符序列,提供多版本重载,支持 string 对象、C 风格字符串、指定个数的重复字符、字符串区间片段等入参形式,返回字符串自身的引用,支持链式调用。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello";
// 1. 追加完整string对象
str.append(" world");
cout << "追加整串:" << str << endl; // 输出 hello world
// 2. 追加n个相同字符
str.append(3, '!');
cout << "追加重复字符:" << str << endl; // 输出 hello world!!!
// 3. 追加字符串的指定区间
string temp = "abcdef";
str.append(temp, 1, 3); // 从temp下标1开始,截取3个字符追加
cout << "追加区间片段:" << str << endl; // 输出 hello world!!!bcd
return 0;
}3. 开发中的注意事项
- 注意重载参数顺序:
append(n, c)是追加 n 个 c 字符,不要和append(const char*, n)的参数顺序搞反; - 追加 C 风格字符串时,必须保证字符串以
\0结尾,否则会触发内存越界读取; - 返回自身引用,支持链式调用,如
str.append("a").append("b"); - 大段内容频繁追加,建议先通过
reserve()预分配内存,避免多次扩容。
三、operator+= 运算符重载(重点)
1. 函数应用场景
日常开发中首选的字符串追加方式,语法极简、可读性极强,底层封装 append 逻辑,支持追加 string 对象、C 风格字符串、单个字符,适用于绝大多数无特殊区间要求的字符串拼接场景。
2. 函数的功能与代码实现
核心功能:重载 += 运算符,在 string 尾部追加指定的字符 / 字符串,兼容多种入参类型,返回字符串自身的引用,支持链式拼接,是 string 类最常用的语法糖。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello";
// 1. 追加C风格字符串
str += " world";
cout << "追加字符串:" << str << endl; // 输出 hello world
// 2. 追加单个字符
str += '!';
cout << "追加字符:" << str << endl; // 输出 hello world!
// 3. 追加string对象
string add_str = " 123456";
str += add_str;
cout << "追加string对象:" << str << endl; // 输出 hello world! 123456
// 4. 链式调用
string s;
s += "a" += "b" += "c";
cout << "链式拼接:" << s << endl; // 输出 abc
return 0;
}3. 开发中的注意事项
- 日常开发优先使用,仅特殊区间 / 批量字符场景用 append,无性能差异,可读性更强;
- 拼接触发扩容后,原字符串的迭代器、引用会失效,不可继续使用;
- 多段长字符串拼接,建议先
reserve()预分配内存,避免多次扩容带来的性能损耗。
四、c_str () 函数(重点)
1. 函数应用场景
C++ string 与 C 语言接口的兼容桥梁 ,用于将 C++ string 对象转换为 C 风格的const char*字符串,适配所有接收 C 风格字符串的系统函数、第三方库、C 标准库接口,是跨语言 / 接口兼容的核心函数。
2. 函数的功能与代码实现
核心功能 :返回一个指向const char类型的只读指针,指向 string 底层存储的、以\0结尾的 C 风格字符串,指针内容与 string 当前内容完全一致,生命周期与 string 对象强绑定。
#include <iostream>
#include <string>
#include <cstdio>
#include <cstring>
using namespace std;
int main() {
string str = "hello c_str";
// 1. 适配C标准库printf函数
printf("C风格输出:%s\n", str.c_str()); // 输出 hello c_str
// 2. 适配C语言字符串函数
int len = strlen(str.c_str());
cout << "strlen获取长度:" << len << endl; // 输出 11
// 3. 适配系统接口(如文件操作)
string file_path = "./test.txt";
FILE* fp = fopen(file_path.c_str(), "r");
if (fp) {
cout << "文件打开成功" << endl;
fclose(fp);
}
return 0;
}3. 开发中的注意事项
- 返回的是
const char*只读指针,绝对禁止通过该指针修改字符串内容,否则触发未定义行为; - 指针生命周期与 string 绑定,string 对象销毁、内容修改(追加、赋值、清空)后,原指针会立即失效,不可继续使用;
- 不可长期保存返回的指针,仅用于临时调用 C 接口,避免指针失效后非法访问;
- 返回的字符串保证以
\0结尾,这是 C++11 前与data()函数的核心区别。
五、find () + npos 常量(重点)
1. 函数应用场景
字符串正向查找匹配的核心函数,用于查找指定字符 / 子串在目标字符串中第一次出现的位置,适用于关键词匹配、子串存在性判断、字符定位、字符串分割等高频业务场景。
2. 函数的功能与代码实现
核心功能:
-
find():从指定 pos 位置(默认 0,字符串开头)开始,正向查找 指定的字符 / 字符串,找到则返回第一次匹配的起始下标(size_t无符号类型);找不到则返回string::npos。 -
string::npos:string 类内置的静态常量,值为 - 1(转为size_t是无符号最大值),专门用于标记查找失败的场景。#include
#include
using namespace std;int main() {
string str = "hello world, hello C++";
// 1. 查找子串第一次出现的位置
size_t pos1 = str.find("hello");
if (pos1 != string::npos) {
cout << "hello首次出现下标:" << pos1 << endl; // 输出 0
}// 2. 从指定位置开始查找 size_t pos2 = str.find("hello", 5); if (pos2 != string::npos) { cout << "下标5后hello首次出现:" << pos2 << endl; // 输出 13 } // 3. 查找单个字符 size_t pos3 = str.find('w'); if (pos3 != string::npos) { cout << 'w' << "出现下标:" << pos3 << endl; // 输出 6 } // 4. 查找失败判断 size_t pos4 = str.find("java"); if (pos4 == string::npos) { cout << "未找到java子串" << endl; } return 0;}
3. 开发中的注意事项
- 必须通过
== string::npos/!= string::npos判断查找结果,禁止直接和 - 1 比较,避免无符号类型转换导致的逻辑错误; - 如需查找所有匹配项,可循环从「上次找到的位置 + 1」开始继续查找;
- 查找大小写敏感,
"Hello"和"hello"会被判定为不匹配,不区分大小写需自行处理; - 查找空串时,直接返回 pos 起始位置(默认 0)。
六、rfind () 函数
1. 函数应用场景
字符串反向查找匹配,从字符串尾部向前查找,用于获取指定字符 / 子串最后一次出现的位置,适用于文件后缀名提取、路径最后一级目录提取、最后一次关键词定位等反向匹配场景。
2. 函数的功能与代码实现
核心功能 :从指定 pos 位置(默认string::npos,字符串最后一个字符)开始,从后往前反向查找 指定的字符 / 字符串,找到则返回最后一次匹配的起始下标;找不到则返回string::npos。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello world, hello C++";
// 1. 查找子串最后一次出现的位置
size_t pos1 = str.rfind("hello");
if (pos1 != string::npos) {
cout << "hello最后一次出现下标:" << pos1 << endl; // 输出 13
}
// 2. 从指定位置向前查找
size_t pos2 = str.rfind("hello", 10);
if (pos2 != string::npos) {
cout << "下标10前hello最后一次出现:" << pos2 << endl; // 输出 0
}
// 3. 实用场景:提取文件后缀名
string file_name = "test.tar.gz";
size_t dot_pos = file_name.rfind('.');
if (dot_pos != string::npos) {
string suffix = file_name.substr(dot_pos + 1);
cout << "文件后缀:" << suffix << endl; // 输出 gz
}
return 0;
}3. 开发中的注意事项
- 查找方向为从后往前,返回的是匹配内容的起始下标,不是结束下标,与 find () 返回值规则一致;
- 同样必须用
string::npos判断查找是否失败,禁止直接和 - 1 比较; - 当 pos 参数超过字符串长度时,默认从整个字符串的末尾开始查找;
- 反向查找匹配的是完整子串,不是反向子串,如
rfind("ab")查找的是"ab"最后一次出现的位置,不是"ba"。
七、substr () 函数
1. 函数应用场景
字符串子串截取,从原字符串中提取指定区间的片段,适用于字符串分割、内容提取、固定长度截取、关键词提取等场景,常和 find ()/rfind () 配合完成复杂字符串处理。
2. 函数的功能与代码实现
核心功能:从原字符串的 pos 下标(默认 0)开始,截取长度为 n 的子串,返回一个全新的 string 对象;若 n 不指定、或 n 超过剩余字符长度,会自动截取到字符串末尾。
函数原型:string substr(size_t pos = 0, size_t n = npos) const;
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello world";
// 1. 从指定位置截取到末尾
string sub1 = str.substr(6);
cout << "下标6截取到末尾:" << sub1 << endl; // 输出 world
// 2. 截取指定位置、指定长度的子串
string sub2 = str.substr(0, 5);
cout << "0开始截取5个字符:" << sub2 << endl; // 输出 hello
// 3. 配合find提取区间内容
string info = "name:zhangsan;age:20";
size_t name_start = info.find(':') + 1;
size_t name_end = info.find(';');
string name = info.substr(name_start, name_end - name_start);
cout << "提取姓名:" << name << endl; // 输出 zhangsan
return 0;
}3. 开发中的注意事项
- 起始 pos 必须在合法范围
0 ≤ pos < str.size(),越界会直接抛出out_of_range异常; - 截取长度 n 超过剩余字符数时,不会报错,会自动截取到字符串末尾,无越界风险;
- substr () 返回的是新的 string 对象,原字符串不会被修改;
- 频繁截取长字符串会产生大量临时对象,有性能损耗,大段内容处理建议用迭代器区间操作。
5. string类非成员函数
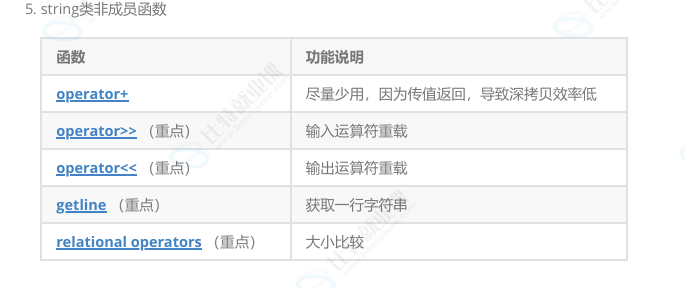
上面的几个接口大家了解一下,下面的OJ题目中会有一些体现他们的使用。string类中还有 一些其他的操作,这里不一一列举,大家在需要用到时不明白了查文档即可。
一、operator+ 加法运算符重载
1. 函数应用场景
仅用于简单、少量字符串的临时拼接,生成全新字符串对象,不修改原字符串,适合一次性短串拼接场景,不推荐高频、长串拼接使用。
2. 函数的功能与代码实现
核心功能 :string 类非成员函数,重载 + 运算符,实现两个可转为 string 的对象(string 对象、C 风格字符串、单个字符)的拼接,返回一个全新的 string 深拷贝对象,原左右操作数均不被修改,支持多类型组合的链式拼接。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str1 = "hello";
string str2 = " world";
// 1. 两个string对象拼接
string res1 = str1 + str2;
cout << "两个string拼接:" << res1 << endl; // 输出 hello world
// 2. string与C风格字符串拼接
string res2 = str1 + " C++";
cout << "string+字面量:" << res2 << endl; // 输出 hello C++
// 3. 链式多段拼接
string res3 = str1 + " " + "world" + "!";
cout << "链式拼接:" << res3 << endl; // 输出 hello world!
return 0;
}3. 开发中的注意事项
- 核心性能问题:传值返回会触发深拷贝,每次拼接都会生成临时对象,高频 / 长串拼接性能极低,优先使用 operator+=、append 替代;
- 语法限制:拼接的两个操作数中,至少有一个必须是 string 对象,直接两个 C 风格字符串字面量用 + 拼接会编译报错(如 "hello"+"world" 非法);
- 不会修改原操作数,所有修改仅体现在返回的新对象中,原字符串内容保持不变。
二、operator>> 输入运算符重载(重点)
1. 函数应用场景
从标准输入流(cin)读取字符串到 string 对象,适用于读取无空格、无换行的单个单词 / 短字符串,是简单无空格输入场景的首选方式。
2. 函数的功能与代码实现
核心功能 :string 类非成员函数,重载 >> 运算符,从输入流中自动跳过开头的空白字符(空格、换行、制表符),直到遇到下一个空白字符停止读取,将读取内容赋值给 string 对象,自动扩容适配内容长度,返回输入流引用,支持链式输入。
#include <iostream>
#include <string>
using namespace std;
int main() {
string name;
string age;
// 1. 基础单值输入
cout << "请输入你的姓名:";
cin >> name;
cout << "你输入的姓名:" << name << endl;
// 2. 链式多值输入,空格分隔
cout << "请输入姓名和年龄,空格分隔:";
cin >> name >> age;
cout << "姓名:" << name << ",年龄:" << age << endl;
return 0;
}3. 开发中的注意事项
- 核心限制:遇到空格、换行、制表符立即停止读取,无法读取包含空格的完整句子 / 带空格字符串,该场景必须使用 getline;
- 自动跳过输入开头的所有空白字符,正常场景下不会读取到空串;
- 输入流异常(如 EOF)时,会停止读取,string 对象保持原有内容不变;
- 自动扩容适配输入内容,无需手动处理内存,安全性远高于 C 语言字符数组。
三、operator<< 输出运算符重载(重点)
1. 函数应用场景
将 string 对象内容输出到标准输出流(cout),是 string 内容控制台打印、流输出的核心方式,适用于所有需要将字符串内容输出到流的场景。
2. 函数的功能与代码实现
核心功能:string 类非成员函数,重载 << 运算符,将 string 对象的有效字符完整输出到输出流,无额外内容输出,返回输出流引用,支持链式输出,可与其他类型输出组合使用。
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "hello C++ string";
// 1. 基础字符串输出
cout << "字符串内容:" << str << endl;
// 2. 链式多类型组合输出
string name = "zhangsan";
int age = 20;
cout << "姓名:" << name << ",年龄:" << age << endl;
// 3. 空串输出
string empty_str;
cout << "空串输出:[" << empty_str << "]" << endl;
return 0;
}3. 开发中的注意事项
- 仅输出 string 的有效字符(size 长度内的内容),不会输出底层 \0 结束符,也不会自动换行,换行需手动添加 endl 或 '\n';
- 完全兼容 const string 对象的输出,无使用限制;
- 支持输出包含空格、特殊字符的完整字符串,无输入运算符的空白限制。
四、getline 函数(重点)
1. 函数应用场景
从输入流中读取一整行包含空格的完整字符串,是读取带空格用户输入、整行文本内容的唯一标准方式,适用于读取完整句子、带空格的地址 / 描述、整行文件内容等场景。
2. 函数的功能与代码实现
核心功能 :string 类非成员函数,从指定输入流中读取字符,直到遇到换行符 '\n'(或自定义分隔符)为止,换行符会被读取并丢弃,不会存入目标 string 对象;读取内容(含中间空格、制表符)完整赋值给 string 对象,自动扩容适配长度,返回输入流引用。
常用原型:istream& getline(istream& is, string& str, char delim = '\n');
#include <iostream>
#include <string>
using namespace std;
int main() {
string address;
string content;
// 1. 基础用法:读取一整行,直到换行
cout << "请输入你的完整地址(含空格):";
cin.ignore(); // 清除之前可能残留的换行符,避免读空
getline(cin, address);
cout << "你输入的地址:" << address << endl;
// 2. 自定义分隔符:遇到','停止读取
cout << "请输入用逗号分隔的内容:";
getline(cin, content, ',');
cout << "逗号前的内容:" << content << endl;
return 0;
}3. 开发中的注意事项
- 核心优势:可读取包含空格的完整行,这是与 cin>> 的核心区别;
- 高频坑点:若之前用 cin>> 读取过内容,输入流会残留换行符,直接调用 getline 会读取到空串,必须先用
cin.ignore()清除残留换行符; - 换行符 '\n' 是默认终止符,会被读取并丢弃,不会存入目标 string;
- 可通过第三个参数自定义终止分隔符,遇到该字符即停止读取;
- 输入流触发 EOF 时,会停止读取,string 对象保留已读取的内容。
五、relational operators 关系运算符(重点)
1. 函数应用场景
两个字符串的相等性判断、字典序大小比较,适用于字符串内容校验、条件分支判断、字符串排序、字典序匹配等高频业务场景。
2. 函数的功能与代码实现
核心功能 :string 类非成员函数,重载==、!=、<、<=、>、>=全套关系运算符,按照 ASCII 码值逐字符字典序比较,支持 string 与 string、string 与 C 风格字符串的直接比较,返回 bool 类型结果。
比较规则:
-
逐字符对比 ASCII 码值,第一个不同字符的大小,决定两个字符串的大小;
-
若前缀字符全部相同,长度更长的字符串判定为更大;
-
仅当长度和所有字符完全一致时,判定为相等(==)。
#include
#include
using namespace std;int main() {
string str1 = "abc";
string str2 = "abd";
string str3 = "abc";
string str4 = "abcd";// 1. 相等性判断 cout << "str1 == str3:" << (str1 == str3) << endl; // 输出 1(true) cout << "str1 != str2:" << (str1 != str2) << endl; // 输出 1(true) // 2. 字典序大小比较 cout << "str1 < str2:" << (str1 < str2) << endl; // 输出 1,'c' ASCII码 < 'd' cout << "str1 < str4:" << (str1 < str4) << endl; // 输出 1,前缀相同,str4更长 cout << "str2 > str1:" << (str2 > str1) << endl; // 输出 1 // 3. 与C风格字符串直接比较 cout << "str1 == \"abc\":" << (str1 == "abc") << endl; // 输出 1 return 0;}
3. 开发中的注意事项
- 比较大小写敏感,大写字母 ASCII 码小于小写字母(如 'A' < 'a'),因此 "ABC" < "abc",不区分大小写比较需先统一转换大小写再对比;
- 比较的是字符串内容,而非内存地址,两个不同的 string 对象,只要内容完全一致,就会判定为相等,与 C 语言 char * 指针比较完全不同;
- 空串永远小于任何非空字符串,两个空串判定为相等;
- 支持 string 对象与 C 风格字符串字面量直接比较,无需手动转换类型。
6.vs和g++下string结构的说明
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节。
vs下string的结构 :
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义 string中字符串的存储空间:
(1)当字符串长度小于16时,使用内部固定的字符数组来存放
(2)当字符串长度大于等于16时,从堆上开辟空间

这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建 好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。 其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的 容量
最后:还有一个指针做一些其他事情。 故总共占16+4+4+4=28个字节
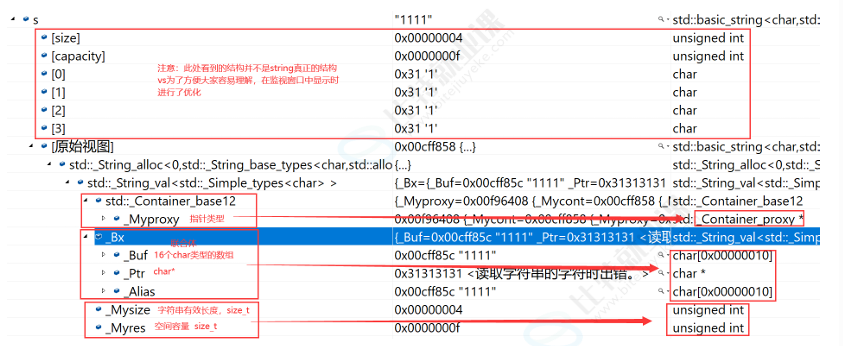
g++下string的结构
G++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个 指针,该指针将来指向一块堆空间,内部包含了如下字段:
空间总大小
字符串有效长度
引用计数

指向堆空间的指针,用来存储字符串。
3.与string相关的oj题练习
1.仅仅反转字母
https://leetcode-cn.com/problems/reverse-only-letters/submissions/
class Solution {
public:
bool isLetters(char ch)
{
if(ch >= 'a' && ch <='z')
return true;
else if(ch >= 'A' && ch <='Z')
return true;
return false;
}
string reverseOnlyLetters(string s) {
size_t left = 0, right = s.size() - 1;
while(left < right)
{
while(left < right && !isLetters(s[left]))
{
left++;
}
while(left < right && !isLetters(s[right]))
{
right--;
}
swap(s[left++],s[right--]);
}
return s;
}
};2.找字符串中第一个只出现一次的字符
https://leetcode-cn.com/problems/first-unique-character-in-a-string/
class Solution {
public:
int firstUniqChar(string s) {
int count[250] = {0};
for(auto ch : s)
count[ch]++;
//for(int i=0;i<s.size();i++)
// {
// count[s[i]]++;
// }
for(int i=0; i < s.size(); i++)
{
if(1==count[s[i]])
return i;
}
return -1;
}
};3.字符串里面最后一个单词的长度
#include <iostream>
#include <string>
using namespace std;
int main() {
string str;
// 一直读取,直到没有单词可读(遇到 EOF)
// 每次读取的新单词都会覆盖掉旧的 str
while (cin >> str) {
// 循环里面什么都不用做!
}
// 当循环结束时,str 里保存的就是输入的最后一个单词
cout << str.length() << endl;
return 0;
}4.验证一个字符串是否是回文
class Solution {
public:
bool isPalindrome(string s) {
string clean_s = ""; // 准备一个新的字符串,只装有用的字符
// 1. 预处理阶段:清洗并收集字符
for(int i = 0, n = s.size(); i < n; i++)
{
if(s[i] >= 'A' && s[i] <= 'Z')
{
clean_s += (s[i] + 32); // 大写转小写,并加入新字符串
}
else if(s[i] >= 'a' && s[i] <= 'z')
{
clean_s += s[i]; // 小写字母直接加入
}
else if(s[i] >= '0' && s[i] <= '9')
{
clean_s += s[i]; // 把遗漏的数字也加上!
}
// 注意:如果是标点或空格,这里什么都不做。
// 这样自然就过滤掉了所有无效字符,新字符串紧凑无比。
}
// 2. 双指针阶段:对洗干净的字符串进行对比
// 注意这里要检查 clean_s 是否为空,虽然 size()-1 处理空串有时会溢出,
// 但如果 clean_s 为空,下面的 while 根本进不去,直接 return true,逻辑是安全的。
int left = 0, right = clean_s.size() - 1;
while(left < right)
{
if(clean_s[left++] != clean_s[right--])
{
return false;
}
}
return true;
}
};5.字符串相加
class Solution {
public:
string addStrings(string num1, string num2)
{
// 从后往前相加,相加的结果到字符串可以使用insert头插
// 或者+=尾插以后再reverse过来
int end1 = num1.size()-1;
int end2 = num2.size()-1;
int value1 = 0, value2 = 0, next = 0;
string addret;
while(end1 >= 0 || end2 >= 0)
{
if(end1 >= 0)
value1 = num1[end1--]-'0';
else
value1 = 0;
if(end2 >= 0)
value2 = num2[end2--]-'0';
else
value2 = 0;
int valueret = value1 + value2 + next;
if(valueret > 9)
{
next = 1;
valueret -= 10;
}
else
{
next = 0;
}
//addret.insert(addret.begin(), valueret+'0');
addret += (valueret+'0');
}
if(next == 1)
{
//addret.insert(addret.begin(), '1');
addret += '1';
}
reverse(addret.begin(), addret.end());
return addret;
}
};6.反转字符串II
#include <algorithm>
#include <string>
using namespace std;
class Solution {
public:
string reverseStr(string s, int k) {
int n = s.size();
int left = 0; // left 代表当前这块 2k 字符的起始下标
// 只要左指针还没越界,就继续处理
while (left < n) {
// 计算当前还剩下多少个字符没处理
int remain = n - left;
// 情况 1:如果剩余字符少于 k 个
// 题目要求:将剩余字符全部反转
if (remain < k) {
reverse(s.begin() + left, s.end());
}
// 情况 2:剩余字符 >= k 个(不管它是不是小于 2k)
// 题目要求:反转前 k 个字符
else {
reverse(s.begin() + left, s.begin() + left + k);
}
// 处理完当前这一批,left 指针往后跳 2k 步,进入下一个轮回
left += 2 * k;
}
return s;
}
};7.反转字符串中的单词III
557. 反转字符串中的单词 III - 力扣(LeetCode)
class Solution {
public:
string reverseWords(string s) {
int sum = 0,left = 0;
int n = s.size();
int add = 0;
while(left <= n)
{
if((s[left] == ' ') || left == n)
{
reverse(s.begin() + add,s.begin() + left );
add = left + 1;
}
left++;
}
return s;
}
};8.字符串相乘
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
string multiply(string num1, string num2) {
// 特殊情况:如果其中一个数是 0,直接返回 "0"
if (num1 == "0" || num2 == "0") {
return "0";
}
int m = num1.size();
int n = num2.size();
// 准备一个长度为 m + n 的数组,初始化为 0
vector<int> res(m + n, 0);
// 从后往前,双层循环模拟竖式乘法
for (int i = m - 1; i >= 0; i--) {
for (int j = n - 1; j >= 0; j--) {
// 将字符转为数字并相乘
int mul = (num1[i] - '0') * (num2[j] - '0');
// 乘积在结果数组中对应的两个位置
int p1 = i + j; // 进位位置 (高位)
int p2 = i + j + 1; // 当前位位置 (低位)
// 累加上低位原本就有的数字
int sum = mul + res[p2];
// 更新当前位和进位
res[p2] = sum % 10; // 取个位留在低位
res[p1] += sum / 10; // 十位进上去 (注意这里是 +=,因为 p1 可能已经有值了)
}
}
// 此时 res 数组里存的就是最终结果的每一位数字
// 我们把它转回 string,要注意去掉开头的多余的 0
string ans = "";
for (int i = 0; i < res.size(); i++) {
// 如果 ans 是空的,且当前数字是 0,说明这是前导 0,跳过
if (ans.empty() && res[i] == 0) {
continue;
}
// 存入真实数字
ans += (res[i] + '0');
}
return ans;
}
};4.string类的模拟实现
4.1经典的string类问题
上面已经对string类进行了简单的介绍,大家只要能够正常使用即可。在面试中,面试官总喜欢让 学生自己来模拟实现string类,最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析 构函数。大家看下以下string类的实现是否有问题?
// 为了和标准库区分,此处使用String
class String
{
public:
/*String()
:_str(new char[1])
{*_str = '\0';}
*/
//String(const char* str = "\0") 错误示范
//String(const char* str = nullptr) 错误示范
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以认为程序非
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
// 测试
void TestString()
{
String s1("hello bit!!!");
String s2(s1);
}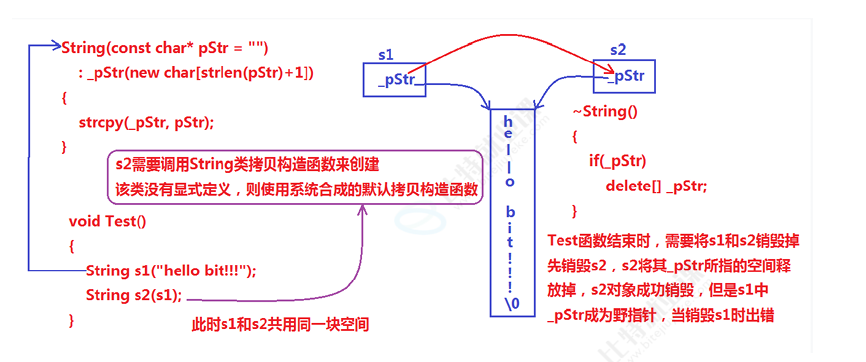
说明:上述String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会合成默认 的,当用s1构造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内 存空间,在释放时同一块空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
4.2浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致 多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该 资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
就像一个家庭中有两个孩子,但父母只买了一份玩具,两个孩子愿意一块玩,则万事大吉,万一 不想分享就你争我夺,玩具损坏。

可以采用深拷贝解决浅拷贝问题,即:每个对象都有一份独立的资源,不要和其他对象共享。父 母给每个孩子都买一份玩具,各自玩各自的就不会有问题了。

4.3深拷贝
如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给 出。一般情况都是按照深拷贝方式提供。

4.3.1传统版写法的String类
class String
{
public:
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以认为程序非
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
strcpy(_str, s._str);
}
String& operator=(const String& s)
{
if (this != &s)
{
char* pStr = new char[strlen(s._str) + 1];
strcpy(pStr, s._str);
delete[] _str;
_str = pStr;
}
return *this;
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};4.3.2现代版写法的String类
class String
{
public:
String(const char* str = "")
{
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(nullptr)
{
String strTmp(s._str);
swap(_str, strTmp._str);
}
// 对比下和上面的赋值那个实现比较好?
String& operator=(String s)
{
swap(_str, s._str);
return *this;
}
/*
String& operator=(const String& s)
{
if(this != &s)
{
String strTmp(s);
swap(_str, strTmp._str);
}
return *this;
}
*/
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};4.4 写时拷贝

写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的。 引用计数:用来记录资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该 资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源, 如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有 其他对象在使用该资源。
写时拷贝:
C++ STL string的Copy-On-Write技术 | 酷 壳 - CoolShell
写时拷贝在读取时的缺陷:
C++的std::string的"读时也拷贝"技术! | 酷 壳 - CoolShell
5.扩展阅读
C++面试中string类的一种正确写法 | 酷 壳 - CoolShell
STL 的string类怎么啦?_string类在stl里面吗-CSDN博客
看完是不是感觉有所收获呢?如果学有所获的话,麻烦给个三连支持一下呗。感谢观看,您的支持,将是我前进路上的重要动力。