更新时间:2026-04-12
0. 论文卡片
- 论文标题:π*0.6: a VLA That Learns From Experience
- 作者 / 机构:Physical Intelligence
- 论文形式:arXiv / 官方技术博客
- 论文链接 :https://arxiv.org/abs/2511.14759
- 论文 PDF :https://www.pi.website/download/pistar06.pdf
- 官方文章 / 项目页 :https://www.pi.website/blog/pistar06
- 官方网站 :https://www.pi.website/
- GitHub 地址 :https://github.com/Physical-Intelligence/openpi
- 核心方法名:RECAP(RL with Experience and Corrections via Advantage-conditioned Policies)
- 任务类型:真实机器人、VLA、离线/迭代式 RL、长时序操作
- 一句话总结 :这篇论文最关键的不是"又做了一次机器人 RL",而是把大 VLA 的策略改进,改写成一套更适合工程落地的 value function + advantage-conditioned policy extraction 闭环。
0.5 核心图速览(先看这张就够你抓住主线)
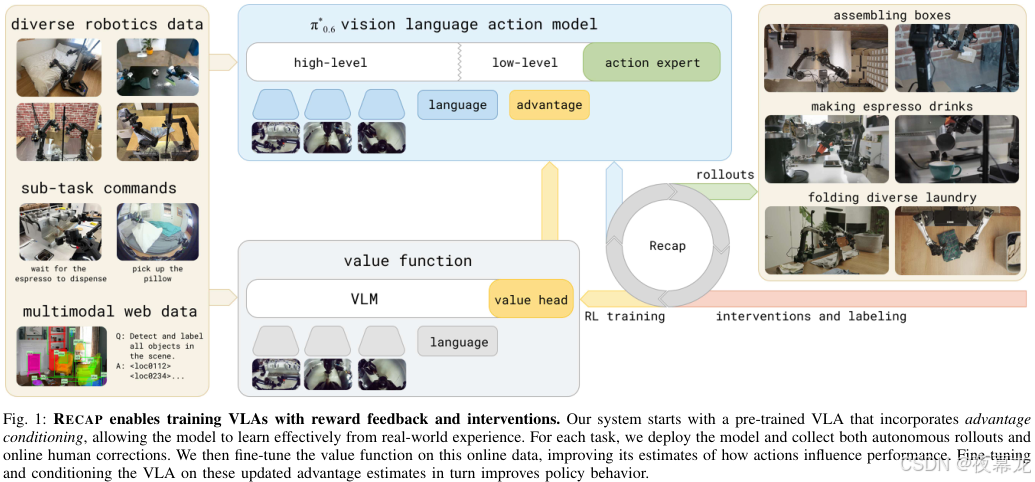
图源 :论文 Fig.1
图解:
- 左边:多源预训练数据,包括 diverse robotics data、sub-task commands、web/multimodal data。
- 中间上方:带 advantage conditioning 的 π*0.6 VLA。
- 中间下方:独立训练的 value function。
- 右边:真实部署任务,如装箱、做 espresso、折衣服。
- 底部横向流程:真实部署收集 rollouts / interventions / labeling,再回流到 RL training,形成 RECAP 闭环。
1. 30 秒 TL;DR
- 这篇论文解决了什么问题:如何让一个已经预训练好的 VLA,在真实机器人部署里继续通过经验、自主尝试和人工纠错变强。
- 核心创新是什么 :不用直接把大 VLA 硬塞进 PPO,而是先学一个多任务 value function,再把动作 advantage 二值化,做成 advantage-conditioned policy 来提取更优策略。
- 最关键的结果是什么:在 espresso、diverse laundry、box assembly 这类长时序真机任务上,RECAP 显著提高 success rate 和 throughput;在最难任务上,吞吐提升可超过 2 倍,失败率大约减半。
- 最大限制是什么:论文最关键的 RECAP 训练栈目前还没有和论文结果等价的官方开源代码,公开仓库更多还是 π 系列 VLA 的基础骨架,不是完整的 π*0.6 训练闭环。
2. 背景与问题定义
2.1 这个任务到底在解决什么
传统 imitation learning 的上限很明显:机器人只能尽量模仿示范者,很难靠自己越做越熟、越做越快。尤其是真实部署时,机器人会犯各种"小错"------抓偏、碰歪、节奏慢、恢复差。
这篇论文要解决的是:
- 让 VLA 不只会模仿,还能从部署经验里继续学习。
- 让模型能同时吃 demonstrations、autonomous rollouts、expert interventions 这几类异构数据。
- 让大模型 VLA 的 RL 训练,比传统 PPO 路线更稳定、更可扩展。
2.2 作者真正想证明什么
作者真正想证明的不是"RL 能提升机器人",而是:
- 大 VLA 也可以做真实世界 RL;
- 而且最有效的路线未必是 policy gradient,而是 value-guided policy extraction;
- 这条路线不仅能涨平均分,还能修特定 failure mode。
3. 方法主线(人话版)
3.1 RECAP 到底怎么工作
RECAP = RL with Experience and Corrections via Advantage-conditioned Policies。
它的核心闭环可以压缩成 4 句:
- 先拿一个预训练的 VLA 去部署。
- 在真实机器人上收集三类数据:demonstrations、autonomous rollouts、human corrections。
- 用这些数据训练一个 value function,判断"当前离成功还有多远"。
- 根据 value 估计 advantage,把动作打成
positive / negative,再继续训练 VLA,让它更偏向"更优动作"。
3.2 结构图:VLA 与 Value Function 如何交互
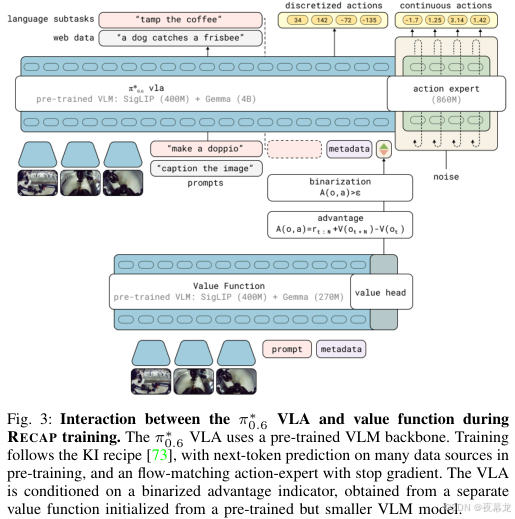
图源 :论文 Fig.3
这张图特别重要,因为它把论文最容易说混的地方讲清了:
- 上半部分是 π*0.6 VLA;
- 下半部分是 独立 value function;
- 中间不是直接 PPO 更新,而是先算 advantage,再做 binarization,最后把结果作为文本式条件喂回策略。
3.3 模块拆解
模块 A:数据收集
- 输入:当前策略、真实机器人任务、人工监控
- 输出:demonstrations / autonomous episodes / interventions / success labels
- 作用:给后续 value training 和 policy extraction 提供混合数据源
模块 B:distributional value function
- 输入 :观测
o_t+ 语言命令ℓ - 输出:离散 value bins 上的分布
- 作用 :估计"离成功还有多少步",或者更准确地说,估计负的剩余步数到成功
- 为什么重要:它是 RECAP 的 critic,但作者选的是更稳、更工程化的 Monte Carlo / distributional 路线,而不是复杂的 off-policy Q
模块 C:advantage-conditioned policy extraction
- 输入 :动作 advantage 的二值标签
positive / negative - 输出:一个既能建模普通动作分布、也能建模"更优动作"条件分布的 VLA
- 作用:从 value function 中提取更好的 policy
- 为什么重要:这一步替代了传统 PPO 式 end-to-end policy gradient
3.4 一句话讲清创新点
这篇论文最关键的新东西不是"加了 value function",而是:
把大 VLA 的 RL 训练,改写成了"先学 value,再做 advantage-conditioned supervised extraction"的问题。
这让它比 PPO 更适合:
- 大模型骨干
- flow-matching action head
- 异构离线 / 旧策略 / 人工纠错混合数据
- 多轮部署后反复迭代
4. 关键公式 / 算法,只讲必须懂的
4.1 Value function:预测"离成功还差几步"
论文定义了一个很朴素但很有用的 sparse reward:
- 成功终止:
0 - 失败终止:
-C_fail - 中间每一步:
-1
这样训练出的 value 就有非常直接的语义:
value ≈ 负的剩余步数到成功
也就是说,value 越接近 0,表示越接近完成任务;value 越负,表示离成功越远,或者已经走向失败。
4.2 Figure 4:Value function 真正在看什么
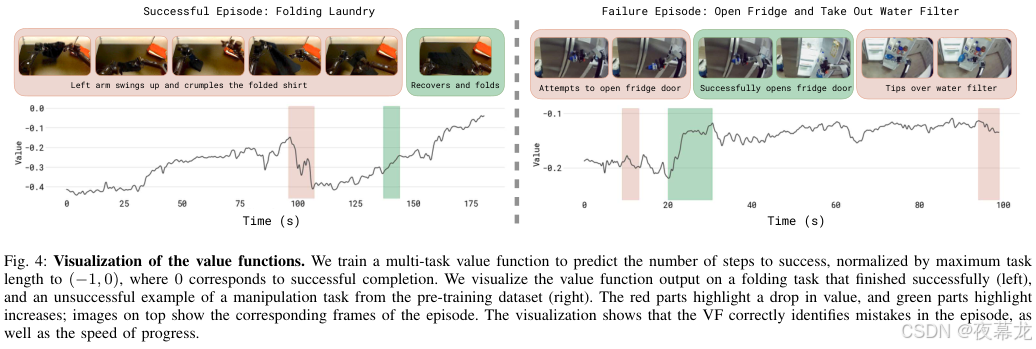
图源 :论文 Fig.4
这张图很值得单独讲,因为它展示了:
- 机器人动作出错时,value 会明显下跌;
- 机器人恢复时,value 会回升;
- 所以这个 critic 不是只会"事后打分",而是能在轨迹中段识别失误与恢复。
4.3 Advantage-conditioned policy 的直觉
有了 value 之后,就能估计某个动作是不是让后续更接近成功。
作者把这个 advantage 不直接拿来做 PPO,而是转成一个二值 indicator:
Advantage: positiveAdvantage: negative
然后把它作为策略输入的一部分。
这其实很像"条件生成":
- 无条件时:模型学普通动作分布
- 正优势条件时:模型学更优动作分布
所以推理时只要让模型偏向 positive advantage,就相当于做了一次 policy extraction。
4.4 这套算法为什么比 PPO 更适合这里
原因主要有三个:
- flow-matching action head 不像普通高斯策略那样天然适合 PPO
- 真实机器人数据昂贵,很难频繁 on-policy 更新
- 作者想吃掉 demonstrations、旧 rollouts、interventions 这些全部历史数据,而不是只吃最近那一小段数据
5. 模型与系统实现细节
5.1 从 π0.6 到 π*0.6
论文里的 π*0.6 不是完全重写一个模型,而是在 π0.6 基础上新增 advantage conditioning。
已公开的信息可以这样理解:
- π0.6 延续了 π0 / π0.5 路线
- 使用更大的 VLM backbone
- 连续动作部分采用 flow matching
- 同时还预测离散 token / 子任务信息
- π*0.6 只是在输入侧再加一个 improvement indicator
5.2 机器人平台与观测设置

图源 :论文 Fig.5
这张图在复现时很关键,因为它说明了实验平台并不是抽象仿真,而是一个固定双臂系统:
- 两个 6 DoF arms
- 平行夹爪
- 50Hz joint position 控制
- 三个相机视角(中间 base camera + 两个 wrist cameras)
5.3 论文训练流程总结
算法上可以压缩成:
- 用 demonstrations 训练 pretrain value
- 用 value 给 VLA 训练 advantage-conditioned policy
- 针对具体任务先做 demonstrations 的 SFT
- 部署收集 autonomous episodes + corrections
- 重训 value
- 再用更新后的 advantage 继续训 policy
- 多轮迭代
6. 实验到底证明了什么
6.1 任务图:论文到底测了哪些真实任务

图源 :论文 Fig.6
评测任务分成三大类:
- Laundry:普通折衣、多样衣物折叠、failure-mode removal 专项折衣
- Cafe / Espresso:完整双份 espresso 制作
- Box Assembly:工厂场景装箱、贴标、堆放
6.2 主结果:最该看的就是 Fig.7 和 Fig.8
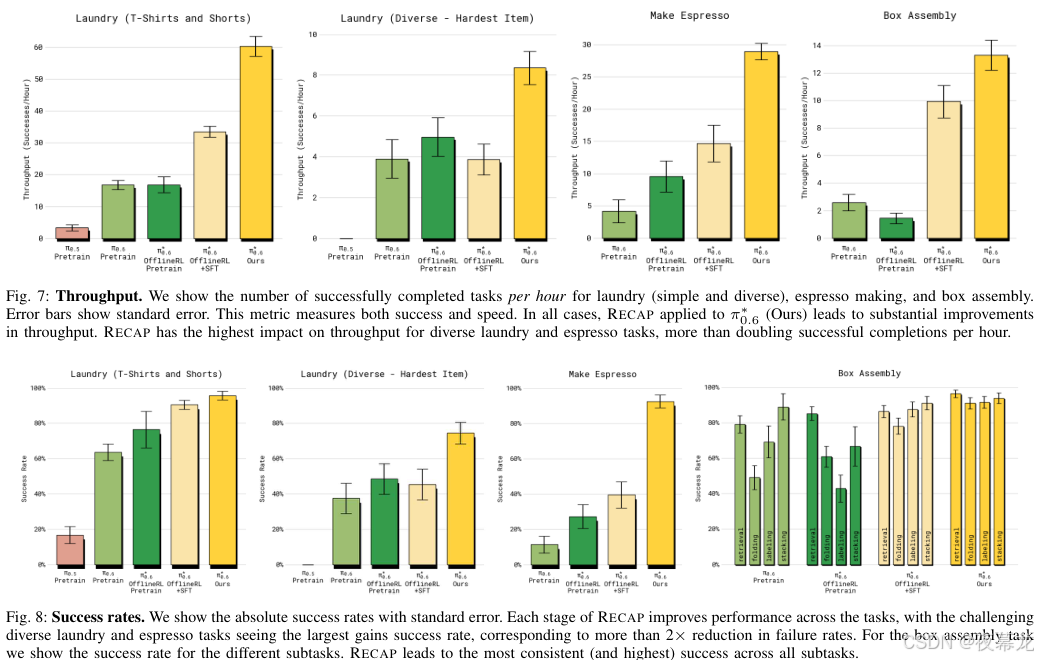
图源 :论文 Fig.7-8
怎么读这张图:
- 上半部分看 Throughput:每小时成功任务数,同时反映成功率和速度
- 下半部分看 Success Rate:单次任务成功比例
- 四组模型对比的是:
π0.6 supervised pretrain -> π*0.6 offline RL pretrain -> π*0.6 offline RL + SFT -> 最终 RECAP
6.3 从图里可以读出的核心结论
- 最终 π*0.6 显著强于纯监督 π0.6
- 只做 offline RL pretraining 还不够,加入 on-robot experience 后还能明显涨
- 最难任务上提升最大,尤其是 diverse laundry 和 espresso
- throughput 是这篇论文特别该重视的指标,因为作者不只想让机器人"能做成",还想让它"做得快、做得稳"
6.4 这说明了什么
这说明 RECAP 不只是把策略往"更会完成任务"推,还往"更高效完成任务"推。
这也是它比单纯 SFT 更有价值的地方:SFT 可以把成功率堆上去,但很容易学到偏保守、偏慢的动作风格。
7. 多轮迭代与 ablation:这套方法能不能持续改、能不能精准修 bug
7.1 多轮迭代结果(Fig.9 / Fig.10)
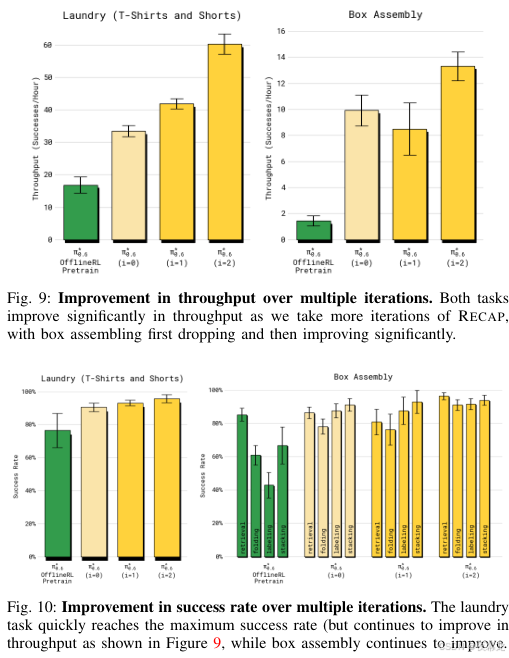
图源 :论文 Fig.9-10
这两张图说明,RECAP 不是一次性 trick:
- Laundry 任务随着迭代继续涨 throughput
- Box assembly 在更多数据后提升更明显
- 说明它有"持续吃经验、持续变强"的趋势
7.2 Policy extraction 对比 + failure mode removal(Fig.11 / Fig.12)
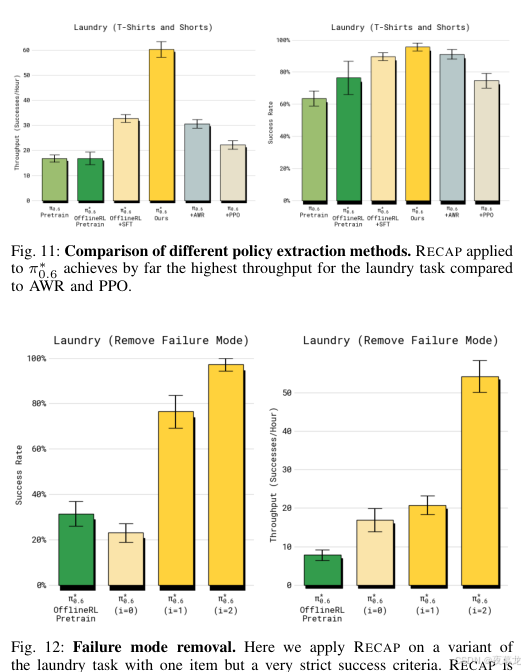
图源 :论文 Fig.11-12
这两张图回答了两个很关键的问题:
- 为什么不用 AWR / PPO?
因为在作者设置下,它们都明显不如 advantage-conditioned extraction。- RECAP 能不能定点修某个坏习惯?
可以。作者在"领口朝向"这个严格 failure mode 上做实验,结果表明它能用相对少的数据,把某种稳定错误几乎清掉。
7.3 我对实验的总判断
这篇论文最强的地方,不是 benchmark 数字本身,而是:
- 任务都是真实世界、长时序、麻烦任务
- 指标不只看 success rate,还看 throughput
- 实验把"整体变强"和"局部修 bug"都做了验证
8. 当前开源代码分析:论文和 repo 能对上多少
8.1 当前最重要的开源现状判断
结论先说:当前公开代码能帮助理解 π 系列 VLA 的骨架,但还不能等价复现 π*0.6 / RECAP 论文训练闭环。
公开仓库 openpi 当前的重点是:
- π0
- π0-FAST
- π0.5
- JAX / PyTorch 两套模型骨架
- 训练、推理、examples、policy server 等基础设施
但论文里最关键的 RECAP 组件,目前官方公开仓库里并不完整。
8.2 论文概念 -> 当前公开代码入口映射
8.3 当前 repo 和论文真正缺口在哪里
从论文视角看,最关键缺口不是"少了几个配置文件",而是少了 RECAP 的核心训练链路:
- value function training
- advantage computation
- advantage-conditioned policy architecture
- online RL training loop
- human correction integration
也就是说,我们现在公开拿到的是 VLA 基础骨架 ,不是论文里那套完整的 RECAP RL training stack。
8.4 我对开源状态的理解
所以当前开源最适合拿来做三件事:
- 理解 π 系列模型结构
- 跑通已有公开 checkpoint / inference / fine-tuning
- 作为我们自己补 RECAP 的工程底座
但它不适合拿来直接声称"复现了 π*0.6 论文结果"。
9. 复现步骤(补充关键节点网址)
先讲结论:现在更准确的说法是"工程近似复现 / 论文对照实现",而不是"官方等价复现"。
9.1 第一步:先对齐论文目标
目标:确认你要复现的是哪一层。
- 先 理解 RECAP 方法 ,先看:
9.2 第二步:把 openpi 公开骨架先跑通
目标:先确保 openpi 的现有推理 / 微调链路能跑。
- 官方仓库:https://github.com/Physical-Intelligence/openpi
- README:https://github.com/Physical-Intelligence/openpi#readme
- 安装说明:https://github.com/Physical-Intelligence/openpi#installation
- examples 目录:https://github.com/Physical-Intelligence/openpi/tree/main/examples
- inference notebook:https://github.com/Physical-Intelligence/openpi/blob/main/examples/inference.ipynb
实践建议:
- 先按 README 安装环境
- 先跑一个公开 checkpoint 的推理示例
- 再看
examples/里的平台示例,而不是直接改训练脚本
9.3 第三步:定位训练与模型入口
目标:知道论文里的"模块"在现有 repo 里大概该放哪。
- 模型骨架:https://github.com/Physical-Intelligence/openpi/tree/main/src/openpi/models
- PyTorch 模型骨架:https://github.com/Physical-Intelligence/openpi/tree/main/src/openpi/models_pytorch
- policies:https://github.com/Physical-Intelligence/openpi/tree/main/src/openpi/policies
- training:https://github.com/Physical-Intelligence/openpi/tree/main/src/openpi/training
- scripts:https://github.com/Physical-Intelligence/openpi/tree/main/scripts
train.py:https://github.com/Physical-Intelligence/openpi/blob/main/scripts/train.pyserve_policy.py:https://github.com/Physical-Intelligence/openpi/blob/main/scripts/serve_policy.py
我建议的阅读顺序:
READMEexamples/scripts/train.pysrc/openpi/training/src/openpi/models//models_pytorch/src/openpi/policies/
9.4 第四步:明确哪些 RECAP 组件需要自己补
关键参考:
- 官方 issue #857(最直接):
https://github.com/Physical-Intelligence/openpi/issues/857
这里几乎就是一张"缺失模块清单",里面点得很直白:
- value function training
- advantage computation
- advantage-conditioned policy architecture
- online RL training loop
- human correction integration
建议做法:
- 补最小链路:
- value function
- advantage 计算
- positive / negative conditioning
- offline data 上的 policy extraction
- human correction / online loop 放后面
9.6 第六步:社区实现"参考"
- LeRobot 0.6.0 路线图:
https://github.com/huggingface/lerobot/issues/3134 - 其中提到的社区 PR(π0.6 RECAP RL implementation):
https://github.com/huggingface/lerobot/pull/3245
9.7 当前最小可跑通路径
-
读官方说明
-
按 README 配环境并拉起 openpi
-
先跑 examples 与已有 checkpoint
-
再读训练与模型入口
-
按 issue #857 补 RECAP 缺失链路
10. 评价
10.1 优点
- 方法路线非常聪明:没有把大 VLA 强行套进最传统的 PPO 训练逻辑。
- 实验任务非常真实:不是玩具抓取,而是 espresso、折衣、装箱这类麻烦任务。
- throughput 指标很有工程价值:作者关心的不只是"能不能做成",还关心"能不能持续高效地做成"。
- failure mode removal 很有说服力:它证明这方法不只是提平均分,而是可以定点修错误行为。
10.2 局限
- 官方 RECAP 训练栈还没完整开源
- 真实复现门槛高:硬件、数据、人工纠错都很重
- 系统还不 fully autonomous:仍依赖人工 labeling / intervention / reset
- 探索策略还偏保守:更多是"在已有不错 policy 上继续改",不是强探索式 RL
10.3 适用场景
- 值得用:VLA、部署后持续优化、human correction + RL 结合
- 落地门槛:高,尤其是硬件与部署数据环节
10.4 我最关心的开放问题
- RECAP 官方训练代码何时开源?
- 这套方法能否在更弱硬件 / 更少人工成本下迁移?
- online RL loop 能否做成真正并发、持续更新的系统?
- value function 能否进一步升级成更强的 off-policy critic?
11. 三种阅读粒度总结
11.1 30 秒版本
- 这篇论文讲的是如何让 VLA 从真实部署经验里继续学习。
- 它的关键不是 PPO,而是 value function + advantage-conditioned policy extraction。
- 它最大的现实限制是:论文最关键的 RECAP 栈还没有官方等价开源。
11.2 5 分钟版本
- 背景:imitation learning 上限明显,真实部署里需要从错误和经验中继续学习
- 方法:收集 demonstrations / rollouts / interventions,先训 value,再做 advantage-conditioned policy extraction
- 实验:espresso、laundry、box assembly 三类长时序真机任务显著提升
- 代码:公开 repo 能看懂骨架,但还不够直接复现 RECAP
- 结论:这是一篇"方法 recipe 很值钱"的论文
11.3 30 分钟精读顺序
- Fig.1(总流程)
- Section IV(RECAP)
- Fig.3(VLA + value function 结构)
- Fig.4(value function 可视化)
- Section V(implementation)
- Fig.7-12(主结果、迭代、对比、failure mode)
- openpi repo + issue #857
12. 一句话结论
这篇论文真正给行业的不是一个小改进,而是一条"让大 VLA 从真实经验中持续变强"的更像工程 recipe 的 RL 路线。