在具身智能领域,如何让机器人既能听懂人类的高层指令,又能精确执行空间操作,一直是个老大难 问题。视觉语言模型(VLM)擅长语义理解,却缺乏三维空间推理能力;传统方法要么依赖昂贵的3D数据微调,要么将规划与感知割裂。最新一期《Science Robotics》刊发的一项研究提出了检索增强操作(RAM)框架,通过"以对象为中心"的知识库,让通用VLM在推理时主动查询精确的几何与操作先验,从而在零样本条件下完成复杂的空间指令跟随、图像引导重排和自适应规划任务。以下是该研究的核心内容梳理。
一、背景:语义与几何之间的鸿沟
近年来,视觉语言模型(VLM)展现出解析高层指令、分解长期任务的强大能力,被视为机器人的"智能大脑"。然而,机器人操作的成败往往取决于**"如何做、在哪里做"**------这需要感知物体三维姿态、接触点、功能区域等细粒度空间信息。现有VLM的训练数据主要来自互联网上的二维图像和文本,缺乏对三维物理世界的直接经验。当被要求提供空间细节(如"将碗口朝上放在盘子中心")时,它们常常"幻觉"------输出听起来合理但物理上不可行的方案。
已有尝试包括:用语言驱动的握持检测、生成可通行图、或在图像上叠加方向矢量等。这些方法或将规划与感知割裂 ,或仅提供局部线索 ,无法让VLM获得对场景的整体空间理解。而通过对三维数据进行微调来"教会"VLM空间知识,则面临三维数据稀缺、标注成本高昂的困境。核心矛盾在于:VLM的参数记忆无法穷举真实世界无穷的几何与交互知识。
为此,研究团队提出方法论转变------不试图把所有物理知识"塞进"VLM参数,而是赋予VLM在推理时主动查询结构化外部知识库的能力 ,以精确、可验证的事实支撑抽象计划。这便是**检索增强操作(Retrieval-Augmented Manipulation, RAM)**框架的核心理念。
二、技术方法:以对象为中心的三级架构
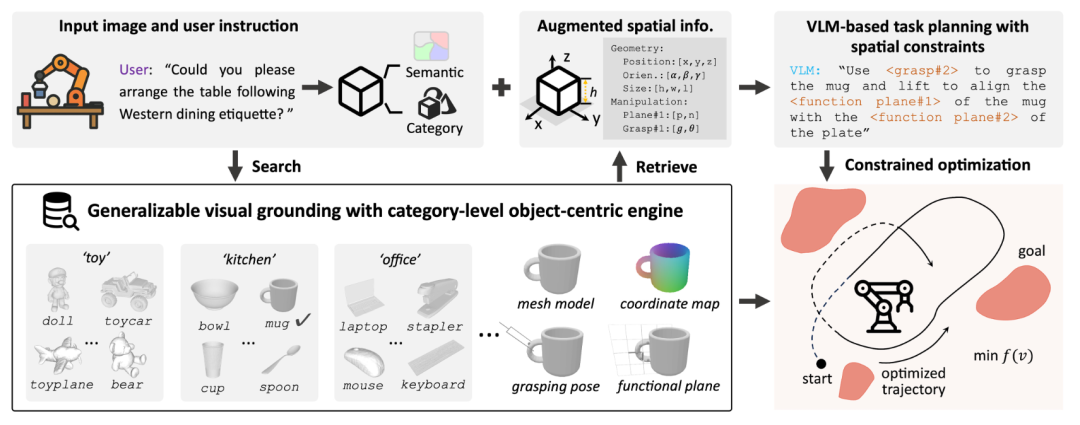
RAM框架由三个相互连接的模块构成,形成一个从感知到规划再到执行的闭环。
1. 类别级以对象为中心的视觉基础
首先构建一个可扩展的知识库 ,为每个对象类别存储"规范模板",包含:规范姿态、三维网格、稳定抓取配置、功能平面(如碗口平面、盘面)等几何与操作先验。给定RGB-D图像后,系统分割出任务相关对象,利用增强后的DINO-v2特征建立观察对象与模板之间的密集对应关系------通过图像级匹配找到最相似模板视角,再通过像素级匹配预测坐标映射,从而估计出真实物体的姿态、大小、抓取点和功能平面。该模块在ShapeNet的20个类别上训练,却能泛化到CO3D数据集中从未见过的椅子、摩托车等类别,对形状变化和遮挡具有鲁棒性。
2. 空间增强上下文的任务分解
将前述估计出的几何信息(如"碗口平面位于中心高度5cm,法线垂直向上")连同其文本描述结构化后,作为空间增强上下文 输入VLM(该研究采用Gemini-2.5-Pro,也验证了GPT-4o、Claude Sonnet 4等模型)。VLM据此将用户指令分解为一系列带有显式空间约束的子目标 ,例如:"将碗的<平面#1>(碗底)与盘子的<平面#2>(盘面)平行对齐,且使两平面中心水平重合"。这种表达方式让VLM不再是"天真的规划器",而成为一个空间感知的推理器。
3. 空间约束驱动的轨迹优化
该模块将每个子目标编码为体素地图上的成本场,包含四个关键地图:适用性地图像(引导机械臂朝向目标)、避障地图、方向地图(控制末端执行器姿态)、夹爪状态地图。通过成本引导的采样优化,生成连续、平滑、无碰撞的机器人轨迹。该方法兼容平行夹爪,也可通过扩展抓取表示支持多指灵巧手。
三、结果验证:真实机器人上的三大能力
研究团队在真实机器人平台上设计了14种空间感知操作任务,涉及11个类别31个不同对象实例,并在零样本条件下测试RAM的三大核心能力。
1. 复杂空间指令跟随能力
任务分为三类:单物体单步(如"将勺子逆时针旋转90°")、多物体单步(如"将相机对准泰迪熊正面")、多物体多步(如"将所有散落勺子对齐到蓝色勺子右侧并同向")。在12个任务、各10次重复试验(共120次)中,RAM平均成功率89.17%;最具挑战的多物体多步任务成功率为80%。对比Gemini-2.5-Pro、GPT-4o、Claude Sonnet 4和Qwen-VL,RAM均显著提升了原始VLM的空间指令跟随能力。
2. 单张图像引导的空间感知重排
传统方法受限于固定俯视视角,而RAM允许任意视角拍摄的目标图像 。机器人需将桌面物体重新排列成目标图像中的空间布局。常规平面设置(10张目标图×5次重复)成功率92% ;困难设置(物体分布在多个垂直平面上)成功率72%。这表明RAM能有效桥接2D图像中隐含的3D关系,并分解为可执行的多步操作。
3. 基于空间推理的自适应规划
设计了一个桌面清洁任务:桌面高度可调(15-60cm),提供大小不一的箱子和簸箕刷子。仅靠语义无法决策------若箱子开口高于桌面,扫地不可行。RAM能够自主识别隐性空间约束 (如簸箕边缘需与桌边齐平、刷子扫入方向需对准簸箕口),并自适应生成物理可行的计划。在20组不同工具和桌面高度的实验中,平均成功率为65%。相比之下,普通VLM常产生"语义正确但物理错误"的计划(如选择开口过高的箱子)。
此外,在CO3D数据集上的定量评估显示:RAM的视觉基础模块在10个未见类别上的姿态估计平均精度显著优于Zero-shot Pose(ZSP)和FoundPose;对形状模板选择和遮挡(<50%时)均表现鲁棒。团队还构建了涵盖位置关系、判断、旋转、规划、测量五类问题的VQA数据集,RAM在所有类别上均优于Gemini-2.5-Pro、SpaceOM和SpaceThinker。
四、展望:结构化知识赋能具身智能
RAM框架的核心价值在于证明了经典结构化知识与现代大模型并非对立,而是协同。通过"检索增强"范式,它让VLM的抽象推理扎根于可验证的几何与物理事实,从而在复杂操作任务中实现了此前端到端方法难以企及的精度与鲁棒性。
未来方向包括:
-
自动构建知识库:目前手动标注模板仍较耗时,下一步将探索从人类操作视频、产品手册或大型3D数据集中自动学习以对象为中心的先验。
-
处理非刚体与关节物体:RAM已通过多模板策略展示了初步能力,但对于高度可变形物体(如布料、绳索),仍需开发更通用的连续状态空间建模方法。
-
融合多模态反馈 :研究已初步验证了将触觉感知集成到框架中,使VLM能推理摩擦、重量等不可观属性并纠正抓取错误。未来的具身智能系统将更依赖于结构化知识库作为多模态信息的统一锚点。
RAM的工作为构建既具备语言能力又具备身体智能的机器人提供了清晰的蓝图------用结构化知识桥接语义与几何的鸿沟,让机器人真正"理解"并"执行"人类期望的空间操作,朝着在日常生活中安全、可靠、能干活的助手迈出坚实一步。
*论文信息:K. Chen et al., "Retrieval-Augmented Manipulation: Grounding Semantic Planning with Object-Centric Knowledge," Science Robotics, 2026.*