1、问题
下面是最近项目中发现的写法
bash
select t1.c2,t1.c3,case when exists (select 1 from t2,t3 where t2.c1=t3.c1 and
t2.id=t1.id and t2.c4='2') then 1 else 0 end as status
from t1 where t1.c1='A1';计划:
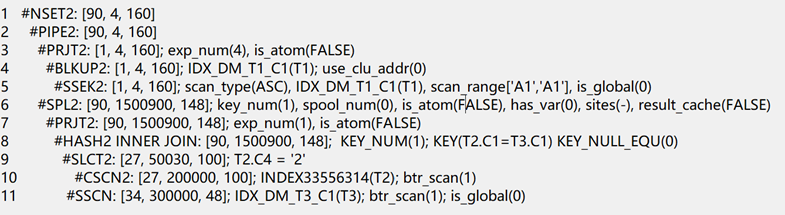 执行时间:执行成功, 执行耗时854毫秒
执行时间:执行成功, 执行耗时854毫秒
case when exists (select 1 from t2,t3 where t2.c1=t3.c1 and
t2.id=t1.id and t2.c4='2') then 1 else 0 end as status,受到参数refed_exists_opt_flag的影响
dm.ini中默认该参数为1,即将exists转换成非相关in查询

即会将子查询做完获取其结果集再和主查询关联,而测例中主查询只获取四条数据,那么其实每获取一行数据到标量子查询中判断即做成nest loop会更佳高效,因此我们可以将参数改为0。
2、调整优化参数
bash
select /*+REFED_EXISTS_OPT_FLAG(0)*/t1.c2,t1.c3,case when exists (select 1 from t2,t3 where t2.c1=t3.c1 and
t2.id=t1.id and t2.c4='2') then 1 else 0 end as status
from t1 where t1.c1='A1';计划:

执行时间:执行成功, 执行耗时1毫秒
该参数对exists有影响,实际上我们可以通过改写避免。我们只要判断满足t2.id=t1.id的就为1,不满足就为0。相当于最终t2.id是否为空,不为空就存在,为空就不存在的意思
3、改写
bash
select t1.c2,t1.c3,case when (select t2.id from t2,t3 where t2.c1=t3.c1 and
t2.id=t1.id and t2.c4='2' and rownum=1) is not null then 1 else 0 end as status
from t1 where t1.c1='A1'计划:

执行时间:执行成功, 执行耗时1毫秒
改写和优化参数效率一样
4、小结
对于标量子查询存在exists写法会受到REFED_EXISTS_OPT_FLAG影响,我们可以简单转换改写为普通的关联判断可绕过。