文章目录
-
- 摘要
- [1. 这篇论文要解决什么问题?](#1. 这篇论文要解决什么问题?)
- [2. TDAG 的核心思路是什么?](#2. TDAG 的核心思路是什么?)
- [3. ItineraryBench:这篇论文为什么不只是提出了一个框架?](#3. ItineraryBench:这篇论文为什么不只是提出了一个框架?)
- [4. TDAG 的执行流程可以怎么理解?](#4. TDAG 的执行流程可以怎么理解?)
- [5. 实验结果说明了什么?](#5. 实验结果说明了什么?)
- [6. 从开源代码看,论文中的设计是如何落地的?](#6. 从开源代码看,论文中的设计是如何落地的?)
-
- [6.1 主流程入口](#6.1 主流程入口)
- [6.2 主代理](#6.2 主代理)
- [6.3 子代理生成器](#6.3 子代理生成器)
- [6.4 子代理执行器](#6.4 子代理执行器)
- [6.5 技能检索与更新](#6.5 技能检索与更新)
- [6.6 细粒度评估器](#6.6 细粒度评估器)
- [7. TDAG 真正有价值的地方是什么?](#7. TDAG 真正有价值的地方是什么?)
- [8. 这篇论文有哪些局限?](#8. 这篇论文有哪些局限?)
- [9. 总结](#9. 总结)
- 参考资料
摘要
大语言模型让 Agent 成为近两年最热门的研究方向之一,但一个核心问题始终没有被彻底解决:为什么模型看起来很聪明,一到复杂、多步骤、真实世界任务里就频繁失效?
TDAG: A Multi-Agent Framework based on Dynamic Task Decomposition and Agent Generation 试图回答的正是这个问题。论文指出,现有方法的主要瓶颈不只是"能力不够",而是任务分解过于静态、子代理适配性不足、评估粒度过粗 。为此,作者提出了 TDAG 框架:通过动态任务分解 、面向子任务的代理生成 以及增量式技能库 ,提升 Agent 在复杂场景中的适应能力;同时构建了 ItineraryBench,用更细粒度的方式评估复杂任务中的中间完成度。
这篇文章将从问题背景、方法设计、实验结果、代码和局限性几个方面,系统解读 TDAG 的价值与边界。
1. 这篇论文要解决什么问题?
TDAG 关注的是一个很实际的问题:LLM Agent 在复杂现实任务中,为什么容易出现"前面一步错,后面步步错"的情况?
论文认为,现有方法主要有两类缺陷。
静态任务分解导致错误传播
很多 Agent 方法会先把复杂任务拆成多个子任务,再逐个执行。问题在于,这种拆分通常是一次性完成的,后续执行阶段很难根据中间结果重新调整计划。
这样一来,只要前面某个子任务失败,后续步骤就会建立在错误前提上,最终导致整条任务链崩掉。论文把这个问题概括为 error propagation。
预定义子代理适配性有限
另一类常见做法是为不同子任务预设不同"专家代理"。例如一个代理负责检索信息,一个代理负责规划路线,一个代理负责调用工具。
这类设计虽然比单代理更模块化,但仍然有明显局限:
- 子代理的能力边界是人工写死的;
- 面对新任务时,已有角色未必足够合适;
- 维护和扩展成本高。
换句话说,不是所有任务都适合被固定角色处理。
复杂任务不能只做二元评估
论文还指出,很多 Agent Benchmark 的评估过于粗糙,只看任务最终成功或失败。
但在复杂任务里,这样的评估方式会丢失大量有效信息。一个旅行规划任务即使没有完全满足所有约束,也可能已经正确完成了购票、路线查询、景点安排中的大部分步骤。若只给一个 0/1 分数,就很难准确反映系统的真实能力。
因此,TDAG 的贡献不只在方法本身,也在于提出了更合理的评估方式。
2. TDAG 的核心思路是什么?
如果要用一句话概括 TDAG,可以写成:
TDAG 的关键不在于"把任务拆开",而在于"在执行过程中动态调整任务结构,并为当前子任务生成更合适的代理"。
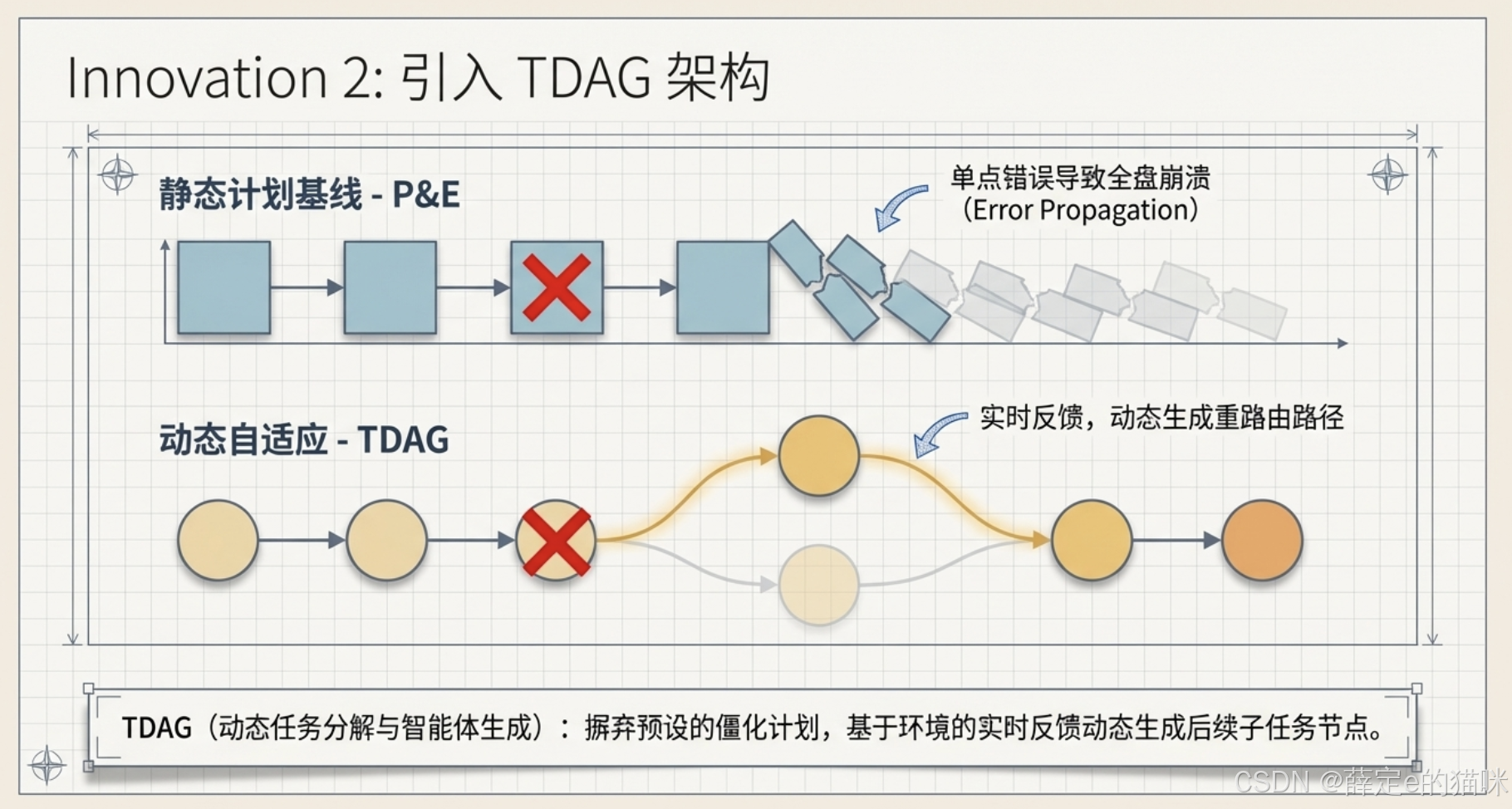
围绕这个目标,论文设计了三层核心机制。
动态任务分解
TDAG 不采用"一开始就把完整计划写死"的方式,而是在执行过程中持续根据上下文和已有结果调整子任务。
这意味着:
- 子任务不是固定不变的;
- 前一个子任务的结果会影响后一个子任务的定义;
- 系统允许在执行过程中重规划。
这和传统 Plan-and-Execute 的差异非常大。后者更像是"先列待办清单,再逐条执行",而 TDAG 更像是"边做边更新计划"。
论文认为,这一设计能有效缓解级联失败,因为系统不必死守最初的规划。
面向子任务的代理生成
TDAG 的第二个创新点是 Agent Generation。
它并不是简单把多个固定子代理拼起来,而是针对当前子任务,动态生成一个更适合它的执行代理。更准确地说,是为子任务生成一份更精准的 action document 或工具说明文档,让子代理只看到它真正需要的工具和操作规则。
这样做的好处有两个:
- 降低工具文档冗余,减少干扰;
- 让代理的可用动作更贴近当前任务目标,提高执行效率。
从方法论上看,TDAG 做的不是"增加更多代理",而是让每个代理更贴合当前任务上下文。
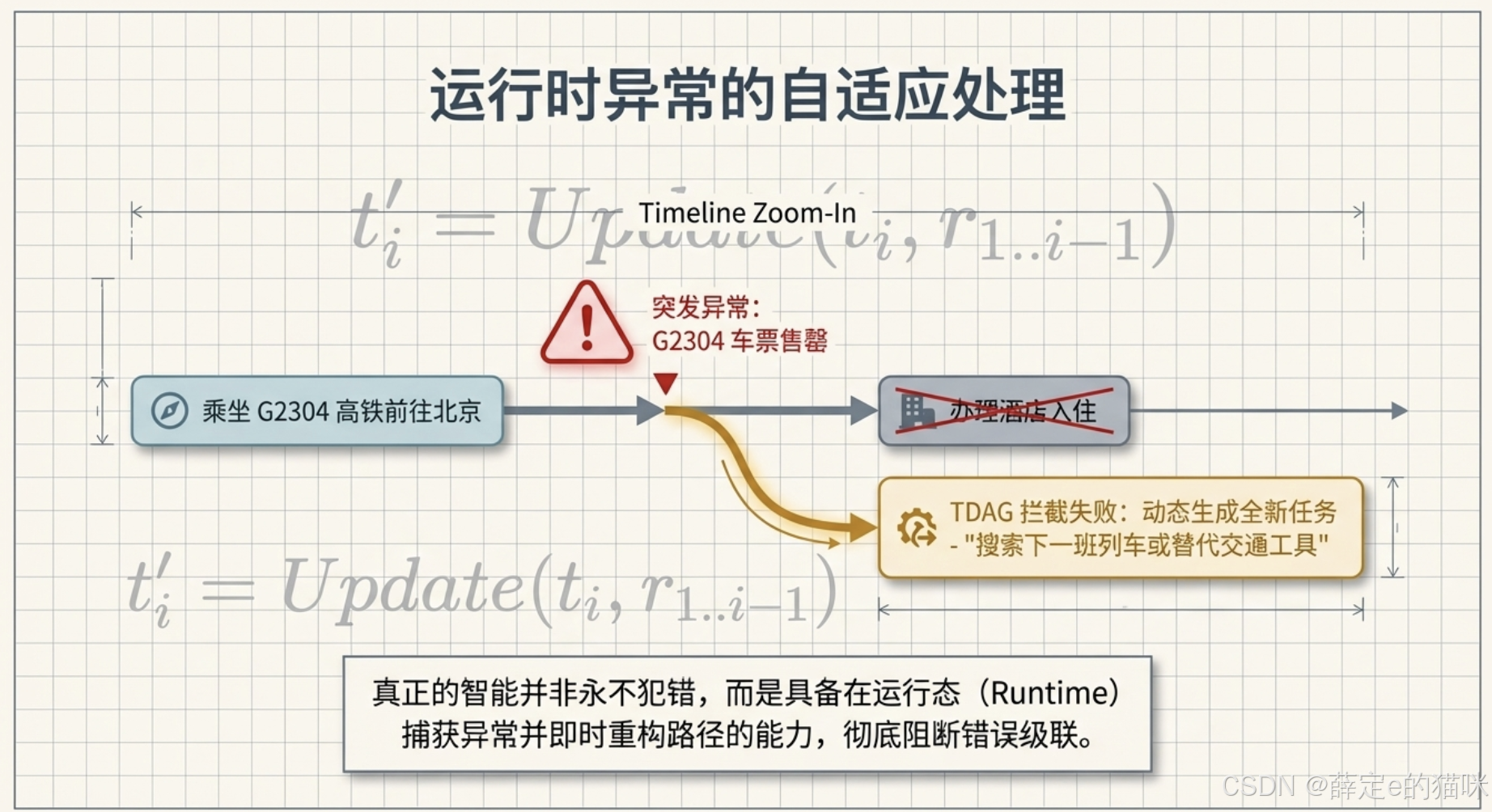
增量式技能库
TDAG 还引入了一个可演化的技能库。
流程大致如下:
- 子代理完成一个子任务;
- 系统让它总结本次任务的解决方案;
- 把这份经验存入技能库;
- 遇到相似子任务时,先检索相关技能作为参考;
- 若新任务带来更优经验,则更新旧技能。
这个机制让 TDAG 不只是一次性求解系统,而具备了轻量的经验积累能力。
需要注意的是,这种技能库并不是训练意义上的参数更新,而更像是外部记忆 + 检索增强。
3. ItineraryBench:这篇论文为什么不只是提出了一个框架?
TDAG 的另一个重要贡献是构建了 ItineraryBench。
这个 benchmark 选择了旅行规划场景,要求 Agent:
- 查询票务信息;
- 安排行程路线;
- 处理预算、时间、景点停留时长等约束;
- 在多步骤、多依赖关系下完成整体规划。
旅行规划并不是一个"炫技型"任务,但它很适合测 Agent 的真实能力,因为它同时包含:
- 外部工具调用;
- 多阶段推理;
- 约束满足;
- 时间和资源分配;
- 中间状态持续更新。

为什么要做细粒度评估?
论文认为,复杂任务不能只用 success/fail 来评价。因为很多系统即便没完全完成目标,也可能完成了不少中间步骤。
因此,ItineraryBench 引入了更细粒度的评分方式,用于评估任务在不同层级上的完成情况。
从开源代码中的 task/travel/simulator.py 可以看到,这种评分大致分成三层:
elementary:基本动作是否正确,比如时间、地点、票据是否匹配;intermediate:中间约束是否满足,比如停留时长、营业时间、休息和用餐要求;advanced:更高层优化目标,比如花费更少时间或更少预算。
更关键的是,它采用了 progressive score。也就是说:
- 只有底层动作做对了,才能继续累积更高层分数;
- 不会出现"底层全错,但上层优化看起来不错"的虚高情况。
层级 1,可执行性得分:
S 1 = w 1 ⋅ e right e right + e wrong S_1 = w_1 \cdot \frac{e_{\text{right}}}{e_{\text{right}} + e_{\text{wrong}}} S1=w1⋅eright+ewrongeright
其中,w_1 = 60,e_right 表示基础动作中执行正确的项数,e_wrong 表示基础动作中执行错误的项数。
层级 2,约束满足度得分:
S 2 = w 2 ⋅ i right i right + i wrong S_2 = w_2 \cdot \frac{i_{\text{right}}}{i_{\text{right}} + i_{\text{wrong}}} S2=w2⋅iright+iwrongiright
其中,w_2 = 20,i_right 表示约束检查中满足的项数,i_wrong 表示违反约束的项数。
层级 3,时间或成本效率得分:
S 3 = { w 3 , s ≤ a w 3 ⋅ b − s b − a , a < s < b 0 , s ≥ b S_3 =\begin{cases}w_3, & s \le a \\\\w_3 \cdot \frac{b-s}{b-a}, & a < s < b \\\\0, & s \ge b\end{cases} S3=⎩ ⎨ ⎧w3,w3⋅b−ab−s,0,s≤aa<s<bs≥b
其中,w_3 = 20,s 是实际时间或成本开销,[a, b] 是由有效候选方案统计得到的参考区间。含义也很直观:如果开销低于下界 a,拿满分;如果高于上界 b,记 0 分;介于两者之间则线性衰减。
这比传统二元评分更接近真实复杂任务的结构。
4. TDAG 的执行流程可以怎么理解?
从论文和代码结合来看,TDAG 的整体流程可以概括为:
- 主代理接收总任务;
- 主代理拆出当前需要处理的子任务;
- Agent Generator 为该子任务定制 action document;
- 子代理在这个定制环境里执行任务;
- 若任务完成,系统校验结果并总结技能;
- 主代理根据当前结果,决定后续还要做什么;
- 重复以上过程,直到整个任务结束。
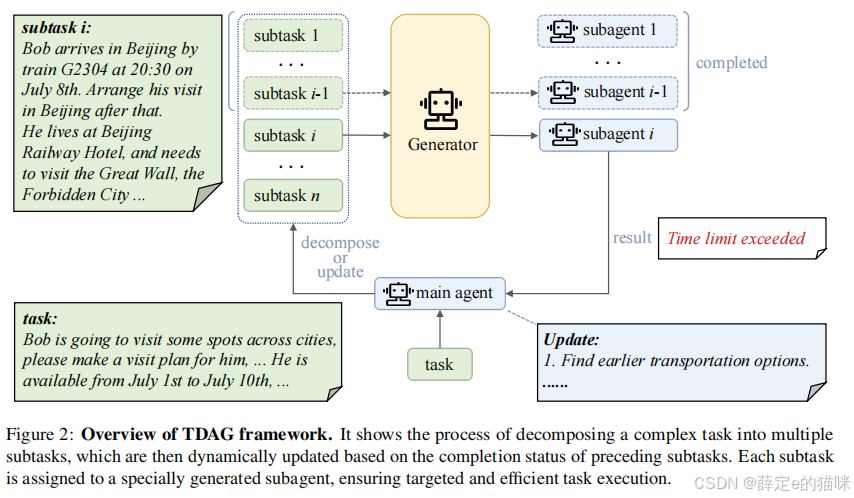
这个流程有两个关键点。
子任务不是提前全部定死的
这意味着 TDAG 不把复杂任务看成一条线性流水线,而是看成一个会根据执行情况不断更新的过程。
子代理也不是固定角色
它更像是"当前子任务的临时执行体",其能力边界由上下文和 action document 决定,而不是由一组预定义身份决定。
这也是 TDAG 和很多"多智能体但其实只是固定分工"方法的本质区别。
5. 实验结果说明了什么?
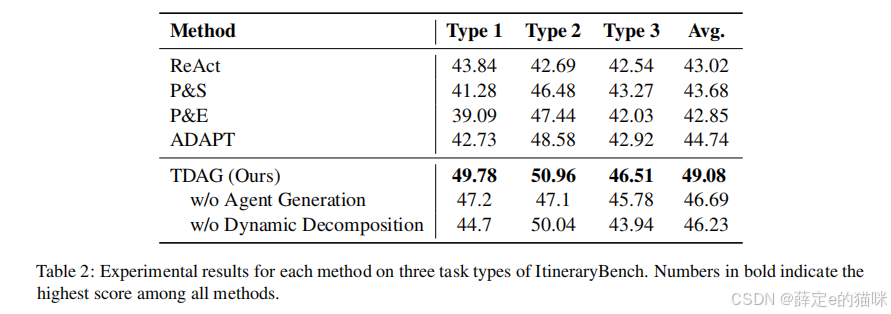
论文把 TDAG 和几个典型基线方法做了比较,包括:
ReActPlan-and-Solve (P&S)Plan-and-Execute (P&E)ADAPT
整体结果显示,TDAG 在 ItineraryBench 上显著优于这些基线。
为什么 TDAG 比静态规划方法更强?
论文给出的核心解释是:动态任务分解能减少错误传播。
例如,在旅行规划里,如果早期查询到的票务信息不满足预算或时间要求,那么后面的城市切换和景点规划都必须跟着调整。静态规划方法往往无法自然处理这类变化,而 TDAG 可以在中途重新组织后续步骤。
消融实验说明了什么?
论文还做了消融实验,分别去掉:
- 动态任务分解;
- 子代理生成。
结果显示,两部分移除后性能都会下降。
这说明 TDAG 的提升不是来自某个单点技巧,而是来自多个设计协同作用:
- 动态分解负责减少计划僵化;
- 子代理生成负责提升执行适配性;
- 技能库进一步增强了经验复用。
论文把错误分成几类:
- 级联任务失败;
- 常识性知识错误;
- 外部信息错位;
- 约束不遵守。
其中最值得关注的是级联任务失败。固定规划方法在这类错误上最严重,这正好支撑了 TDAG 的理论动机。
论文还提到一个有趣现象:某些更复杂的 Agent 框架在外部信息错位问题上并不一定总优于简单方法。这说明系统变复杂后,上下文变长、交互轮数增加,也会带来新的幻觉风险。
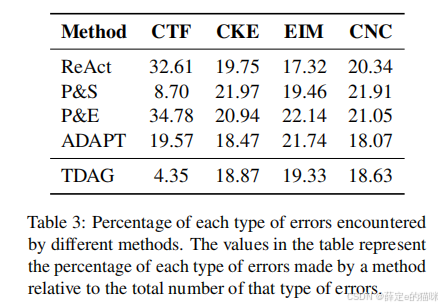
这是一种比较诚实的结论,也提醒我们:Agent 框架不是越复杂越好。
6. 从开源代码看,论文中的设计是如何落地的?
论文配套代码仓库为:https://github.com/yxwang8775/TDAG
从仓库结构看,论文中的关键模块基本都有对应实现。
6.1 主流程入口
run/run_incre.py 是 TDAG 的主入口,负责:
- 调用主代理进行任务拆解;
- 生成子代理;
- 执行子任务;
- 调用校验代理;
- 更新技能库;
- 最后进入 simulator 打分。
这是论文主流程最核心的代码入口。
6.2 主代理
agents/main_agent/agent.py
这个模块负责全局任务管理。它的主要职责不是直接执行所有任务,而是:
- 理解总任务;
- 拆分子任务;
- 决定何时调用子代理;
- 整理最终输出计划。
6.3 子代理生成器
agents/agent_generator/agent.py
这个模块是 TDAG 方法里非常关键的一环。它会结合:
- 总任务;
- 当前子任务;
- 已完成任务;
生成更适合当前子任务的 action document。
也就是说,论文中的 "Agent Generation" 在代码里不是重新训练一个代理,而是生成更适合当前任务的工具说明和动作空间约束。
6.4 子代理执行器
agents/sub_agent/agent.py
子代理负责在给定动作空间内执行具体子任务。它支持:
- 查询工具;
- 调用动作;
- 汇总结果;
- 输出过程总结。
6.5 技能检索与更新
utils/retrieve.py
agents/update_agent
data/travel/skill.json
这里实现了论文里的增量技能库。代码中使用 SentenceTransformer 进行语义相似检索,再由更新代理对新旧技能进行融合或修正。
6.6 细粒度评估器
task/travel/simulator.py
这是论文评估设计最直接的代码映射。它把动作执行、约束检测和最终计分整合到一个模拟器里,支持论文所强调的 progressive score。
7. TDAG 真正有价值的地方是什么?
我认为 TDAG 的价值不只是"提出了一个多智能体框架",而在于它把 Agent 研究里几个经常被混淆的问题分开了。
它指出了问题不只是"会不会规划"
很多方法把重点放在"如何让模型先列出一个好计划",但 TDAG 指出,复杂任务里真正难的是:
- 执行过程中会发生变化;
- 中间结果可能偏离预期;
- 后续步骤需要被重新组织。
因此,难点不是一次性规划,而是规划与执行的耦合更新。
它强调了"代理适配性"而非"代理数量"
很多多智能体工作容易陷入一个误区:代理越多,好像系统越强。
TDAG 给出的启发是,真正重要的不是代理数量,而是当前执行体是否适合当前子任务。与其固定一堆专家角色,不如动态裁剪动作空间和工具说明。
它认真处理了评估问题
很多 Agent 论文容易把 benchmark 当作展示结果的背景板,但 TDAG 很清楚地意识到:如果评估方法不对,很多方法差异根本看不出来。
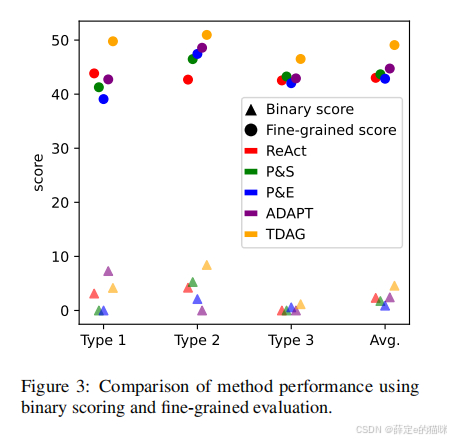
这一点其实很有研究价值,因为复杂任务系统的进步,很大程度上依赖更合理的评估方式。
8. 这篇论文有哪些局限?
TDAG 是一篇不错的论文,但也有明显边界。
验证场景仍然是较强约束环境
旅行规划确实复杂,但它仍然属于:
- 动作空间较清晰;
- 环境规则较明确;
- 可模拟;
- 结构化约束较多。
如果迁移到开放网页操作、长期记忆交互或高度开放式任务,TDAG 面临的挑战会更大。
它优化的是系统组织,不是模型真实性
TDAG 改善的是:
- 任务拆解方式;
- 子代理适配方式;
- 经验复用方式。
但它并没有从根本上解决底层模型的幻觉、事实性错误和工具误用问题。也就是说,它让 Agent 更像一个组织得更好的系统,但不等于让模型本身变得更可靠。
动态分解仍然是受控的工程机制
从代码上看,TDAG 仍然有很多启发式边界:
- 最大迭代次数;
- 最大递归深度;
- 错误重试上限。
这意味着它不是"无限自适应"的开放系统,而是一个工程上可控的动态框架。
技能库的泛化能力有限
技能库对相似任务有效,但如果任务分布变化很大,已有技能未必还能正确迁移,甚至可能误导当前决策。这类问题在真实部署中会更加明显。
9. 总结
TDAG 是一篇值得看的 Agent 论文,不是因为它简单地提出了"多智能体",而是因为它抓住了复杂任务中的三个关键矛盾:
- 任务分解不能太静态;
- 子代理不能完全预定义;
- 复杂任务不能只用二元评分来评估。
它的核心启发可以浓缩成一句话:
复杂任务里的 Agent 能力,不只是推理能力问题,更是任务组织能力问题。
从这个角度看,TDAG 的贡献主要体现在三点:
- 用动态任务分解缓解错误传播;
- 用子代理生成提升执行适配性;
- 用细粒度评估更真实地衡量复杂任务完成度。
如果你关注的是如何让 LLM Agent 在真实、多步骤、强约束任务中更稳定地工作,那么 TDAG 提供了一条比"单代理 + 长提示词"更有工程价值的路线。
它未必是终极答案,但确实比很多只强调"多代理协作"的工作更扎实,也更值得认真读。
参考资料
- 论文:
TDAG: A Multi-Agent Framework based on Dynamic Task Decomposition and Agent Generation - 论文配套代码:
https://github.com/yxwang8775/TDAG