一、Redis简介
 出现的问题
出现的问题
(一)NoSQL概念
1.介绍
即Not-Only SQL(泛指非关系型的数据库),作为关系型数据库的补充。能够应对基于海量用户和海量数据前提下的数据处理问题。
2.特征
- 可扩容,可伸缩
- 大数据量下高性能
- 灵活的数据模型
- 高可用
3.常见NoSQL数据库
- Redis
- memcache
- HBase
- MongoDB
4.解决方案(电商场景)
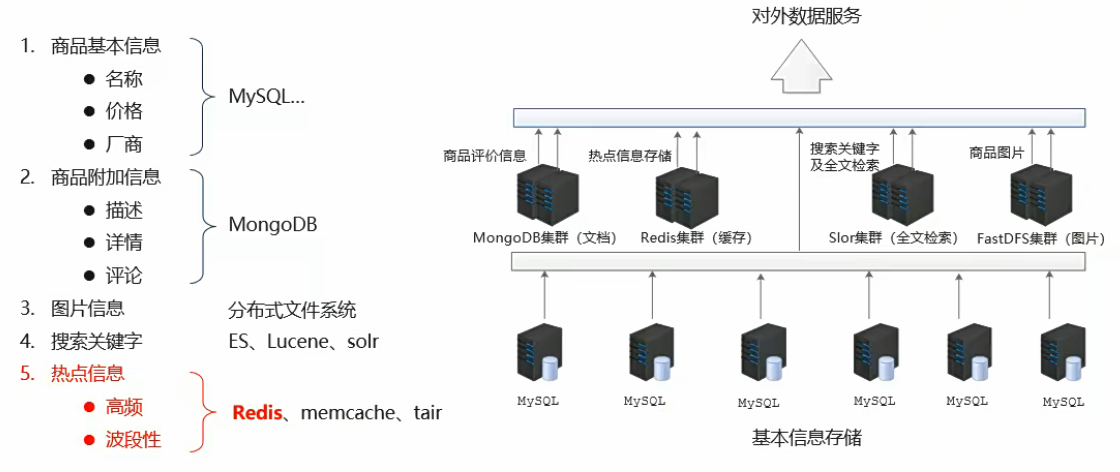
(二)Redis概念
1.介绍
Redis(REmote DIctionary Server )是用C语言开发的一个**开源的高性能键值对(key-value)**数据库
2.特征
- 数据间没有必然的关联关系
- 内部采用单线程机制进行工作
- 高性能
- 多数据类型支持(String、list、hash(散列类型)、set、zset/sorted_set(有序集合类型))
- 支持持久化,可以进行数据灾难恢复
3.应用场景


二、Redis的下载和安装(用apt安装的 Redis)
(一)进入安装路径
1.启动Ubuntu,在桌面右键点击,选择"在终端打开"
2.随便进入一个路径完成下面的命令即可,因为apt 安装的 Redis时安装目录是固定的,不能改

(二)更新软件源
1.更新软件源(sudo apt update)不安装任何东西,只刷新 "软件目录清单"

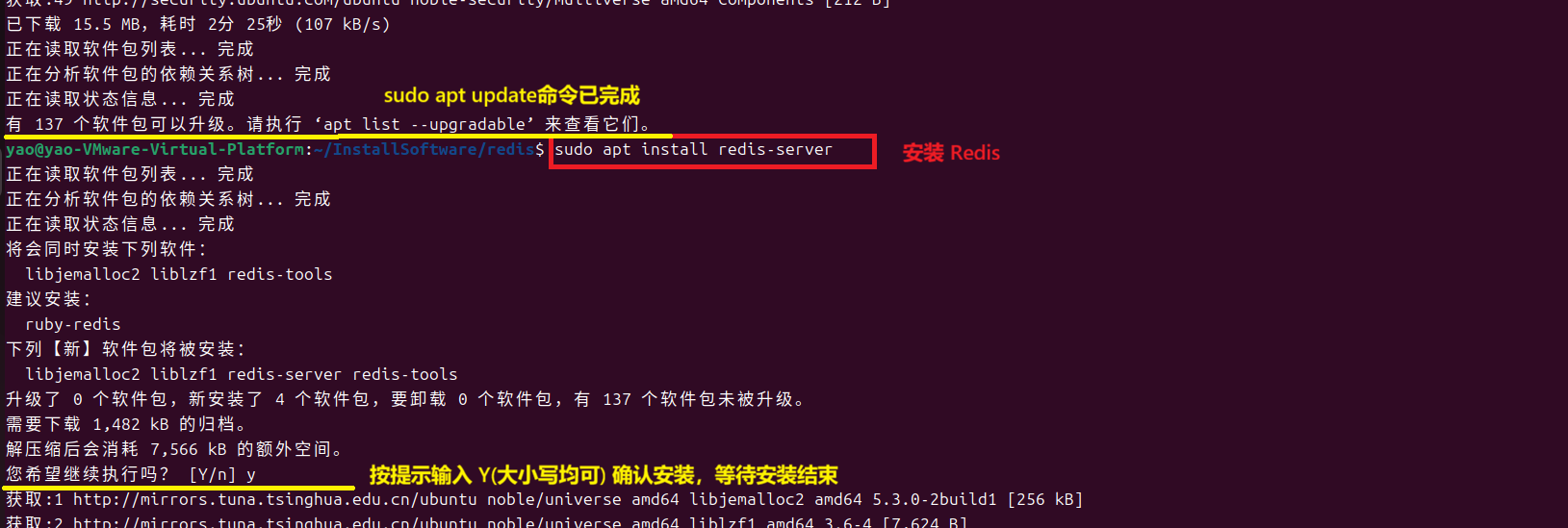
(三)安装 Redis
1.安装 Redis(sudo apt install redis-server)
(四)验证是否成功
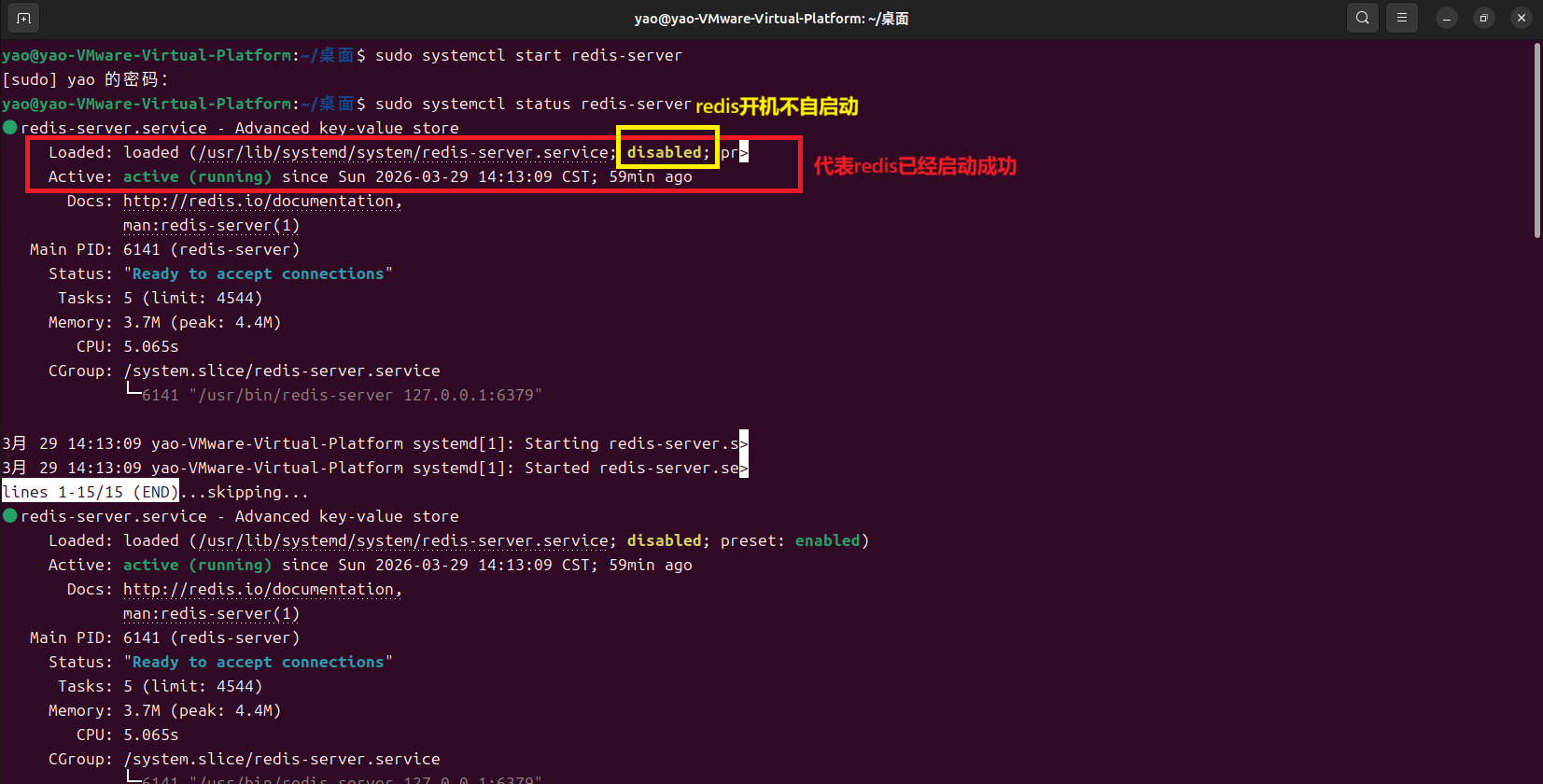
1.启动 Redis 服务(sudo systemctl start redis-server)
2.验证(redis-cli ping)出现**"PONG"**,就说明 Redis 已经正常运行了!

三、Redis操作
(一)基础知识
1.apt 安装后redis系统标准路径
| 用途 | apt 安装后的实际路径 |
|---|---|
| 配置文件 | /etc/redis/redis.conf |
| 数据文件 | /var/lib/redis |
| 日志文件 | /var/log/redis/redis-server.log |
| 可执行程序 | /usr/bin/redis-server、/usr/bin/redis-cli |
2.Redis中服务端和客户端的区别
①服务器端(redis-server)
= 后台运行的 Redis 服务
= 相当于 电视机
②客户端(redis-cli)
= 你打开的这个连接窗口
= 相当于 遥控器
③四种关闭操作(------>代表"发给"的意思)
- shutdown(客户端------>服务端=="++用遥控器关电视机++";客户端还活着,服务器端死了)
- exit / Ctrl + C(客户端------>客户端=="++只是关遥控器++ ";客户端退出连接,Redis 服务器还在后台运行)
- redis-cli shutdown(服务端------>服务端=="++直接关电视++";Redis 服务彻底停止,所有客户端都连不上了,数据会被安全保存)
- sudo systemctl stop redis-server(系统------>服务端=="++拉电闸 / 拔插头来关闭电视++ ";系统直接关闭 Redis,只能关默认端口)
3.配置文件中重要内容
4.关闭Redis服务器一直卡住
情况:真正的 Redis 6380(还在跑),一堆卡住的 systemctl stop 残留进程
- 强制杀死所有 Redis 相关卡住进程(sudo pkill -9 redis-server)
- 杀死所有卡住的 systemctl 停止命令(sudo pkill -f "systemctl stop redis-server")
- 再确认一次服务关闭(sudo systemctl stop redis-server@端口号)
- 检查是否干净(ps aux | grep redis)
(二)基本操作
1.服务器(redis-server)启动
①启动默认端口:6379
| 命令 | 含义 |
|---|---|
| sudo systemctl start redis-server | 配置文件的方法启动默认(一个)端口号 的服务器命令(正式、稳定、持久生效)【同方法++修改++默认端口号的服务器方法看②;同方法启动多个不同端口号的服务器方法看③**】** |
| sudo systemctl start redis-server@端口号 | 配置文件的方法启动指定端口号的服务器命令(正式、稳定、持久生效) |
| redis-server --port 端口号 | 启动(多个)指定端口号 服务器命令,(如果Redis开了自启动 ,使用该命令端口可能冲突; 该方法为前台运行关了终端,Redis 就关掉了**;**不会加载配置、数据目录、日志等) |
| sudo systemctl stop redis-server | 服务器停止 命令(操作系统 去关闭 Redis,只能关默认端口的Redis) |
| redis-cli shutdown | 服务器关闭默认端口 命令(客户端 发指令让 Redis 自己关自己) |
| redis-cli -p 端口 shutdown | 服务器关闭指定端口 命令(客户端 发指令让 Redis 自己关自己) |
| sudo systemctl restart redis-server | 服务器重启命令 |
| sudo systemctl status redis-server | 服务器状态命令 |
| ps aux | grep redis | 查看所有正在运行的 Redis 进程 |
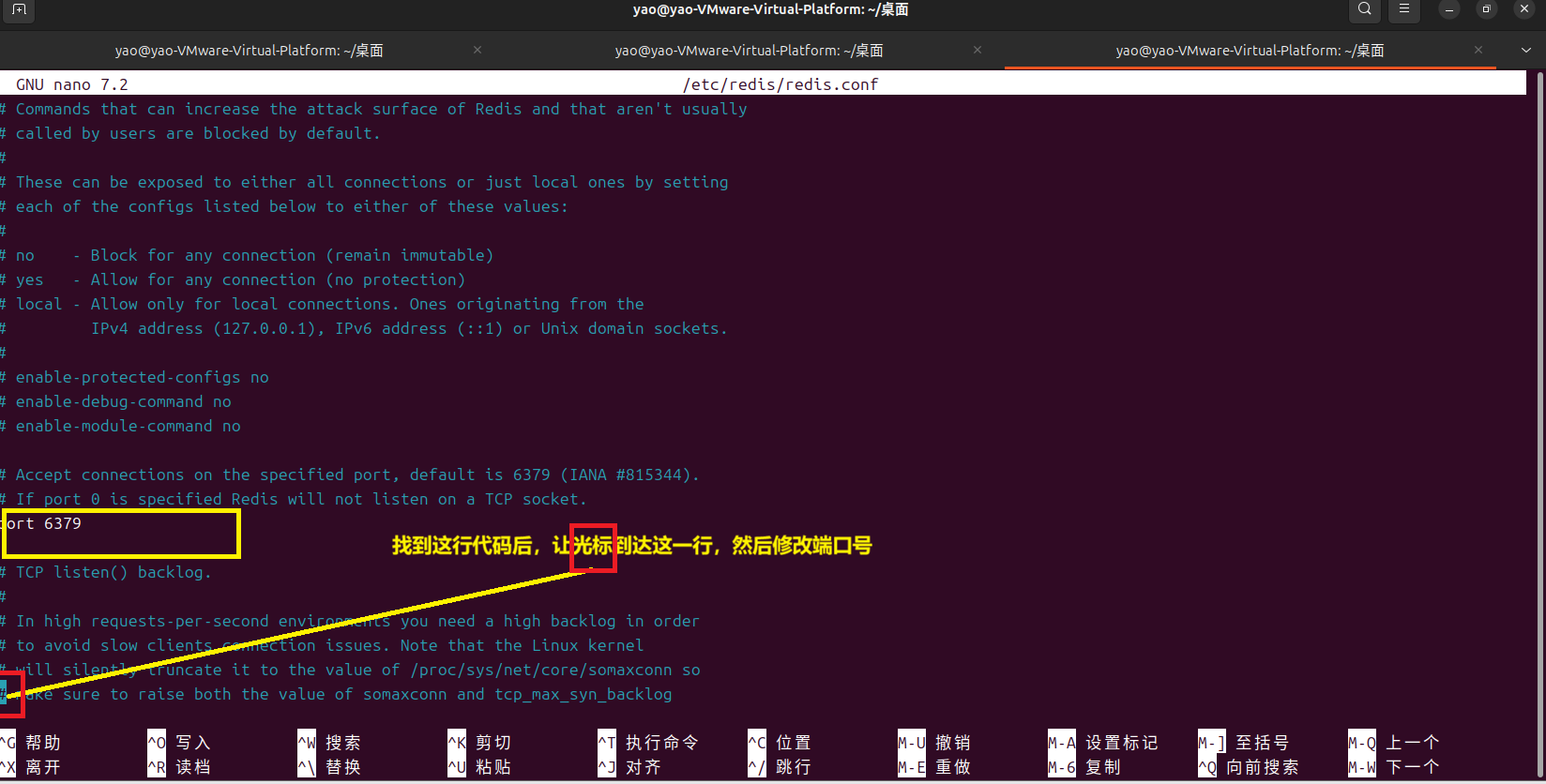
②用配置文件的方法修改默认端口号(要修改配置文件 + 重启服务)
a.打开 Redis 配置文件(sudo nano /etc/redis/redis.conf)

b.找到并修改端口配置(把 6379 改成你想要的端口,比如 6380)
c.保存并退出(按**Ctrl+O** →回车(保存) → 按 **Ctrl+X**退出)
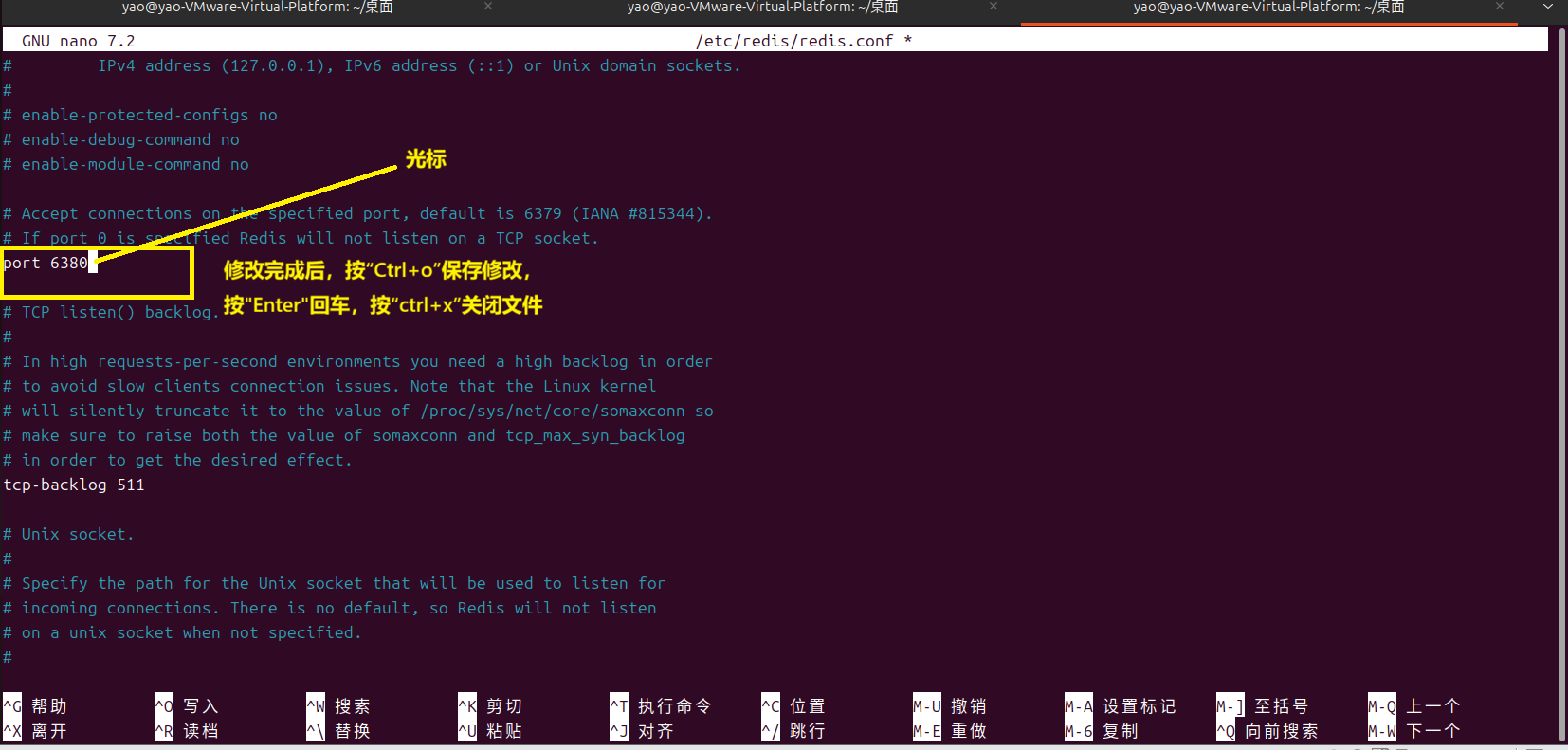
d.重启 Redis 服务让配置生效(sudo systemctl restart redis-server)
e.以管理员身份,查看当前系统中所有被 Redis 占用的端口(sudo ss -tulnp | grep redis)

③配置启动(多个)redis(给每个 Redis 端口,单独配一套文件 + 目录,让它变成系统服务)
a.复制 ++原配置文件【redis.conf】++ 到 /etc/redis(该路径是专门放配置文件的) 下,并命名++新的配置文件为【redis-6380.conf】++ (sudo cp /etc/redis/redis.conf /etc/redis/redis-6380.conf)
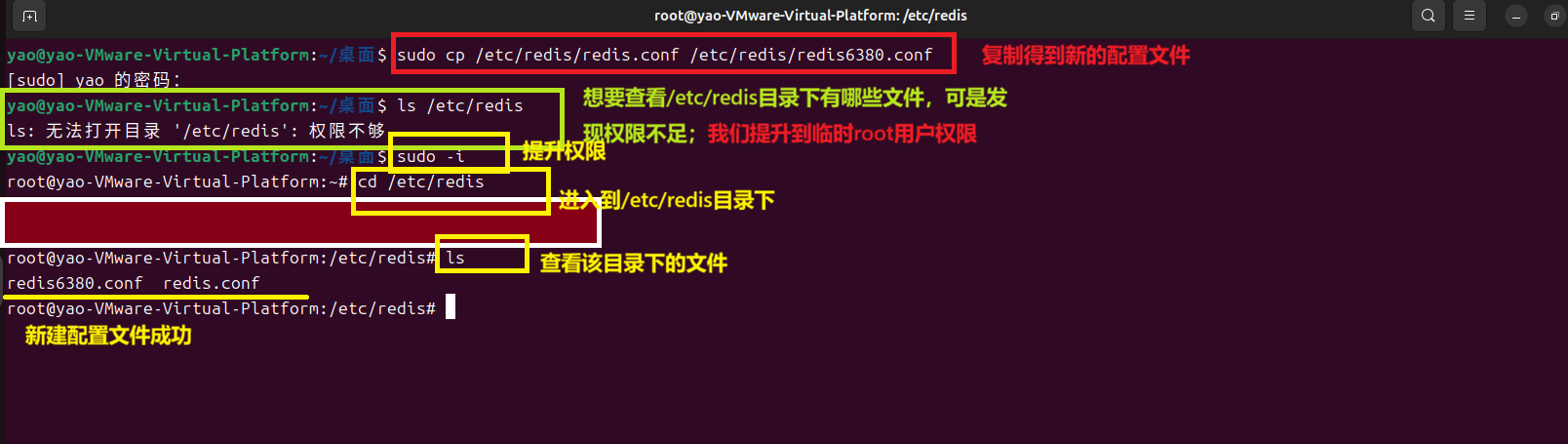 图片中的新配置文件名改为:++redis-6380.conf++
图片中的新配置文件名改为:++redis-6380.conf++
b.创建【存放端口为6380的Redis数据的】数据目录文件夹(sudo mkdir /var/lib/redis6380)
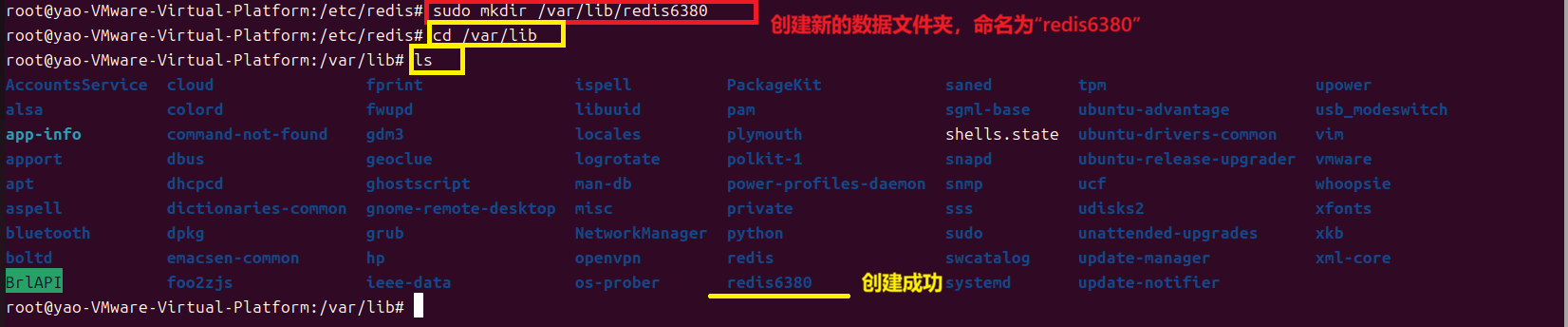
c.修改数据目录文件夹权限(sudo chown redis:redis /var/lib/redis6380)

d.在"/etc/redis"路径下,以编辑状态打开 ++新配置文件【redis6380.conf】++ (sudo nano redis6380.conf)

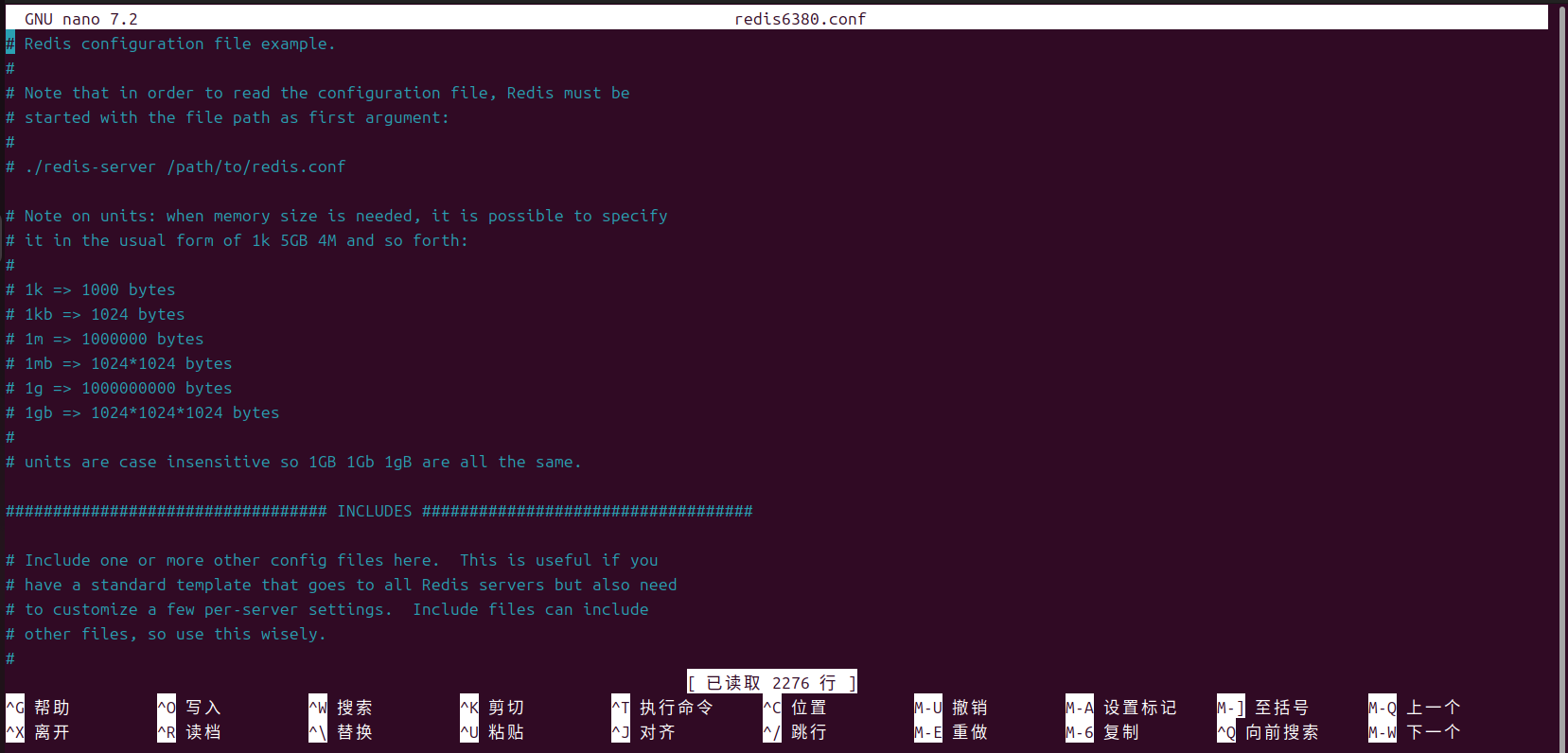
e.修改 3 个地方
①端口(port 6380)

②PID 文件(pidfile /run/redis/redis-server6380.pid)

③数据目录(dir /var/lib/redis6380)

f.保存退出(Ctrl + O → 回车→ Ctrl + X)
g.启动 6380 端口的 Redis(sudo systemctl start redis-server@6380)

2.客户端(redis-cli)启动
| 命令 | 含义 |
| redis-cli | 连接本地 Redis(不加-h默认连接 本机(127.0.0.1); 不加-p默认连接 6379 端口) |
| redis-cli -p 端口 | 连接指定端口(不加 -h 默认连接 本机(127.0.0.1)) |
| redis-cli -h 地址 | 连接远程 Redis(不加 -p 默认连接 6379 端口) |
| redis-cli -h 地址 -p 端口 | 连接远程 Redis指定端口 |
| exit / quit / Ctrl + C | 关闭客户端(客户端**退出连接,Redis 服务器还在后台运行,**其他客户端还能连,数据还在,端口还在) |
| shutdown | 在客户端关闭Redis(必须在连接客户端后使用;如果在终端使用,则代表关闭系统) |
|---|


3.命令行模式基本工具使用
| 命令 | 含义 |
|---|---|
| set key value | 设置信息(key,value) |
| get key | 获取key对应的value(不存在,返回null) |
| help (想查询的命令) | 帮助查询 |
| clear | 清屏 |
四、数据存储类型
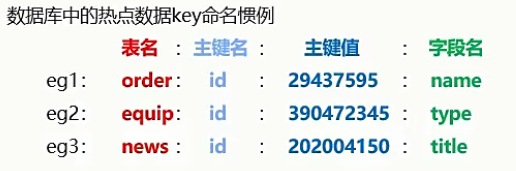
redis自身是一个Map ,其中所有的数据都是采用key : value的形式存储。++数据类型++ 指的是存储的数据的类型,也就是++value部分的类型++ ,++key部分永远都是字符串++ (5种常用:string、hash、list、set、sorted_set/zset)
(一)string类型
1.介绍

2.注意事项

3.基本操作
| 命令 | 含义 |
|---|---|
| set key value | 添加/修改数据 |
| get key | 获取数据 |
| del key | 删除数据 |
| setnx key value | 判定性添加数据(key不存在给key添加value;key存在,不做操作) |
| mset key1 value1 key2 value2... | 添加/修改多个数据 |
| mget key1 key2... | 获取多个数据 |
| strlen key | 获取数据字符个数(字符串长度) |
| append key value | 追加信息到原始信息后部(原始信息不存在就新建) |
4.string类型数据的扩展操作
①数值自增操作
a.incr key------给key对应的vaule值整数数值+1(原子自增)
- 如果**
key不存在** ,会先将其值初始化为0,再执行 +1 ,最终结果为1 - 如果
key对应的值不是整数(比如字符串、小数),会报错ERR value is not an integer or out of range - 适用场景:文章阅读量、点赞数、用户访问次数等简单计数器
b.incrby key increment------给key对应的value整数数值增加指定的步长increment
- 和
incr一致,仅支持整数,步长可为正数或负数 key不存在 ,则初始化为 0再计算- 适用场景:批量增减积分、库存扣减 / 补充、批量统计等需要自定义步长的计数器
c.incrbyfloat key increment------给key对应的数值(支持整数 / 浮点数)增加指定的浮点数步长
- 支持整数、浮点数,步长也可以是正数 / 负数
key不存在 ,则初始化为 0 再计算- 结果会以浮点数形式返回(即使是整数,也会保留小数位)
- 适用场景:金额计算、温度 / 湿度等带小数的统计、汇率计算等
②数值自减操作
a.decr key------给key对应的value整数数值 -1(原子自减)
- 和
incr完全对称,key不存在 则初始化为 0 再 - 1,结果为-1; - 非整数会报错
- 适用场景:库存扣减、倒计时、次数限制等
b.decrby key increment------给key对应的value整数数值减去指定的步长
- 和
incrby对称,仅支持整数,步长正负均可 key不存在则初始化为 0 再计算- 适用场景:批量扣减库存、积分扣除等
③设置数据生命周期(过期时间)
a.setex key seconds value------设置 key 的值为 value,同时指定秒级过期时间
- 原子操作,相当于
set key value+expire key seconds二合一 - 如果
key已存在,会直接覆盖旧值和旧的过期时间 - 过期时间单位为秒 ,必须是正整数
- 适用场景:登录态 token、验证码、临时缓存等需要自动过期的数据
b.psetex key milliseconds value------设置 key 的值为 value,同时指定毫秒级过期时间(1 秒 = 1000 毫秒)
- 原子操作,相当于
set key value+expire key seconds二合一 - 如果 **
key已存在,**覆盖旧值和旧过期时间 - 对value 类型无限制,只要是字符串即可 ;过期时间单位为毫秒 ,必须是正整数
- 适用场景:需要毫秒级精度的过期控制,比如短信验证码、短时效缓存
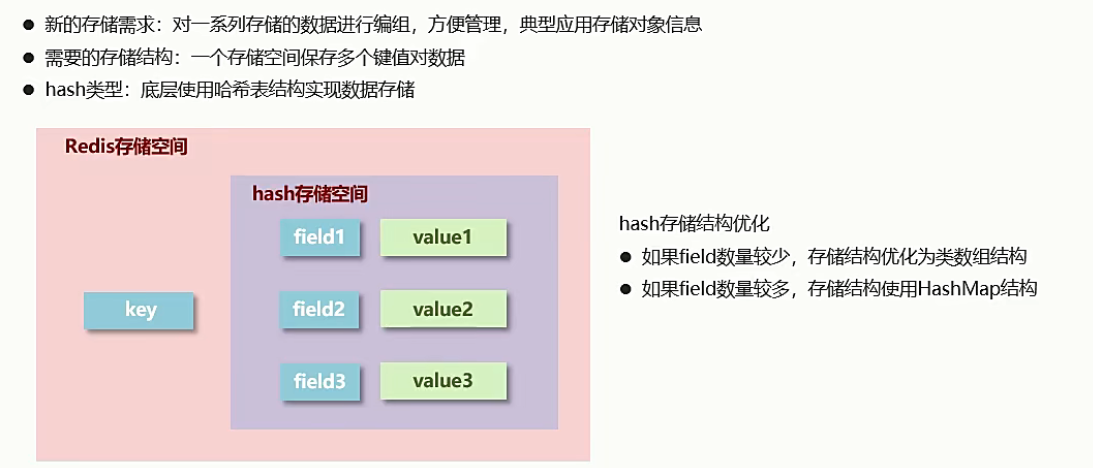
(二)hash类型(field------字段)
1.介绍
2.注意事项

3.基本操作
①基础增删查操作
a.hset key field value------给key的哈希表中,添加/修改 一个 field(字段)和对应的 value(值)
- 如果
field不存在:新增字段,返回1;如果**field已存在:覆盖旧值,返回0** - 适用场景:单个字段的新增 / 更新,比如修改用户昵称、年龄
b.hget key field------从key的哈希表中,获取单个 field 对应的值
- 如果**
field存在:返回对应value** ;如果field不存在:返回(nil) - 适用场景:查询单个字段,比如获取用户姓名
c.hgetall key------从key的哈希表中,获取所有 field 和对应的 value
- 按「field1, value1, field2, value2...」的顺序返回
- 哈希表数据量大时,避免频繁使用,会阻塞 Redis
- 适用场景:查询整个对象的所有信息,比如获取用户完整资料
d.hdel key field1 field2...------从key的哈希表中,删除一个或多个 field
- 返回成功删除的字段数量;
- 不存在的
field会被自动忽略 - 适用场景:删除对象的某个属性,比如注销用户、删除用户手机号
e.hsetnx key field value------给key的哈希表中,仅当 field 不存在时,才设置值 (判定性添加)
- 如果**
field不存在:新增字段,返回1** ;如果field已存在:不做任何操作,返回0 - 适用场景:防止字段被覆盖、初始化默认值、分布式锁的字段校验
②批量操作与统计
a.hmset key field1 value1 field2 value2...------给key的哈希表中,批量添加 / 修改多个 field-value 对
- 等价于多次执行
hset,但一次命令完成,性能更高 - 已存在的
field会直接覆盖旧值 - 适用场景:批量新增 / 更新对象属性,比如批量创建用户、商品信息
- Redis 4.0+ 推荐用
hset替代(hset已支持多字段),hmset已被标记为废弃
b.hmget key field1 field2...------从key的哈希表中,批量获取多个 field 对应的值
- 按输入
field的顺序返回对应值,不存在的字段返回(nil) - 适用场景:批量查询对象的部分属性,比如获取用户姓名、年龄、手机号
c.hlen key------获取key的哈希表中,字段(field)的总数量
- 如果
key不存在,返回0 - 适用场景:统计对象属性数量、校验数据完整性
d.hexists key field------判断key的哈希表中,是否存在某个 field
- 存在返回
1,不存在返回0 - 适用场景:字段存在性校验、条件判断(比如用户是否绑定手机号)
4.hash类型数据的扩展操作
①获取哈希表中所有的字段名或字段值
a.hkeys key------获取key对应的哈希表中,所有的字段名(field)
- 如果
key不存在,返回空列表 - 适用场景:遍历哈希表的所有字段、校验字段是否存在、批量操作字段前的枚举
b.hvals key------获取key对应的哈希表中,所有的字段值(value)
- 如果
key不存在,返回空列表 - 适用场景:批量获取所有字段值、统计数值总和、导出哈希表数据
②设置指定字段的数值数据增加指定范围的值
a.hincrby key field increment------给key哈希表中,对应 field 的整数数值value增加指定步长 (increment)
- 如果
key或field不存在:会先将值初始化为0,再执行自增 - 仅支持整数 ,非整数会报错
ERR value is not an integer or out of range increment支持正数(自增)、负数(自减)- 适用场景:哈希表中整数型字段的计数,比如用户积分、商品库存、文章点赞数
b.hincrbyfloat key field increment------给key哈希表中,对应 field 的整数 / 浮点数数值value增加指定浮点数步长
- 支持整数、浮点数,
increment步长也支持正数(自增)、负数(自减) key或field不存在则初始化为0再计算- 结果以浮点数形式返回(即使是整数,也会保留小数位)
- 适用场景:哈希表中浮点型数值的计算,比如用户余额、商品折扣、温度 / 湿度统计
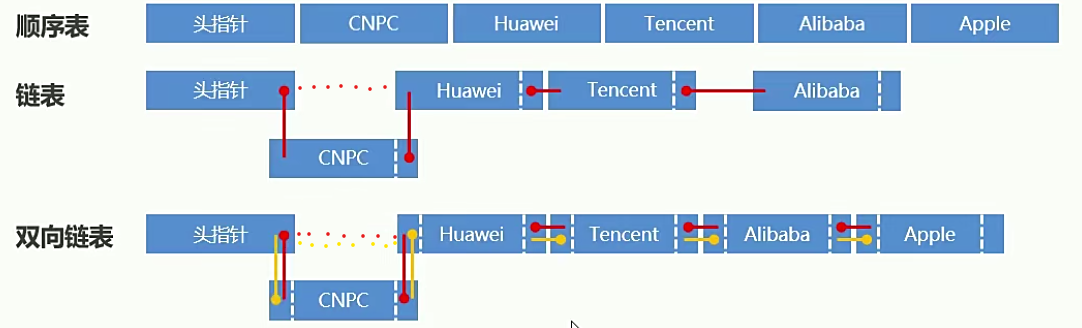
(三)list类型(field------字段)
1.介绍

链表知识回忆
2.注意事项

3.基本操作
①添加/修改数据
a.lpush key value1 value2 ...------从列表左侧(头部)插入一个或多个元素
- 列表不存在则自动创建
- 多个元素按从左到右 的顺序依次插入头部,最终顺序为
valueN ... value2 value1 - 适用场景:栈结构(后进先出)、最新消息置顶
b.rpush key value1 value2 ...------从列表右侧(尾部)插入一个或多个元素
- 列表不存在则自动创建
- 多个元素按从左到右 的顺序依次插入尾部,最终顺序为**
value1 value2 ... valueN** - 适用场景:队列结构(先进先出)、消息队列、任务队列
②获取数据
a.lrange key start stop------获取列表中指定区间的元素(按索引下标,从 0 开始)
start=0表示第一个元素,stop=-1表示最后一个元素 (0 -1可获取全部元素)- 索引超出范围不会报错,仅返回有效元素
- 适用场景:分页查询列表、获取全部元素、截取列表
b.lindex key index------获取列表中指定索引下标的单个元素
- 索引从 0 开始,
-1表示最后一个元素 ,-2表示倒数第二个 - 索引超出范围返回
(nil) - 适用场景:获取列表中指定位置的元素、随机访问
c.llen key------获取列表的长度(元素总个数)
- 列表不存在则返回
0 - 适用场景:统计列表元素数量、判断列表是否为空
③获取并移除数据
a.lpop key------移除并返回列表左侧(头部)的第一个元素
- 列表为空返回
(nil) - 适用场景:栈弹出、队列头部消费
b.rpop key------移除并返回列表右侧(尾部)的最后一个元素
- 列表为空返回
(nil) - 适用场景:队列尾部消费、栈尾部弹出
4.list类型数据的扩展操作
①移除指定数据
a.lrem key count value------移除列表中指定数量的与 value 相等的元素
count > 0:从头部到尾部,移除前count个匹配的元素count < 0:从尾部到头部,移除前|count|个匹配的元素count = 0:移除列表中所有匹配的元素- 适用场景:批量删除列表中重复元素、清理指定值
②规定时间内获取并移除数据
a.blpop key1 key2 timeout------弹出列表key左侧(头部)的第一个元素,如果key1没有值,就查看key2...,所有的key中都没有元素,就堵塞客户端(客户端终端停在那里,不结束、不返回,一直等着timeout时间结束)
- 列表有元素:立即弹出并返回
- 列表无元素:阻塞等待
timeout秒,超时返回(nil);timeout=0表示永久阻塞,没数据就一直等,一有数据立刻弹! - 支持多个key,按顺序检查(先看 key1 → 再看 key2 → 再看 key3),弹出第一个非空列表的头部元素
- 适用场景:阻塞式消息队列、任务队列(消费者等待任务)
b.brpop key1 key2 timeout------弹出列表key右侧(尾部)的第一个元素,如果key1没有值,就查看key2...,所有的key中都没有元素,就堵塞客户端(客户端终端停在那里,不结束、不返回,一直等着timeout时间结束)
- 列表有元素:立即弹出并返回
- 列表无元素:阻塞等待
timeout秒,超时返回(nil);timeout=0表示永久阻塞,没数据就一直等,一有数据立刻弹! - 支持多个key,按顺序检查(先看 key1 → 再看 key2 → 再看 key3),弹出第一个非空列表的尾部元素
- 适用场景:阻塞式队列尾部消费
c.brpoplpush source destination timeout------将 source 列表的尾部一个元素弹出,并插入到 destination 列表的头部
source有元素 :原子操作完成弹出 + 插入,返回该元素source无元素:阻塞等待timeout秒,超时返回(nil);timeout=0 = 永久阻塞,没数据就一直等,一有数据立刻弹!- 整个操作是原子性,不会出现数据丢失
- 适用场景:消息队列的可靠传输(任务从一个队列转移到另一个队列,防止丢失)、循环队列
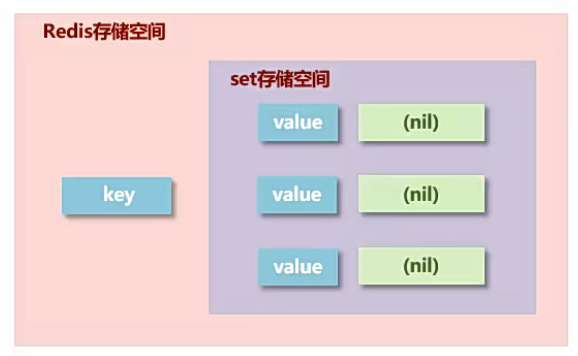
(四)set类型
1.介绍
Redis 的 Set 是无序、去重 的字符串集合,基于哈希表实现,支持快速增删查、集合运算(交 / 并 / 差),适合做去重、共同好友、标签等场景

2.注意事项

3.基本操作
①添加/删除
a.sadd key member member ...------向集合中添加一个或多个元素
- 集合不存在会自动创建
- 集合自动去重,重复元素添加无效
- 返回成功添加的新元素个数(已存在的不算)
- 适用场景:添加标签、添加好友、添加关注、去重存储
b.srem key member member ...------从集合中删除一个或多个元素
- 不存在的元素会自动忽略
- 返回真正删除掉的元素个数
- 适用场景:取消关注、删除标签、移除好友、清理数据
②判断集合中是否包含指定数据
a.sismember key member------判断指定元素 member 是否在集合 key 中
- 存在返回
1,不存在返回0 - 适用场景:元素存在性校验(比如用户是否关注某博主、是否拥有某权限)
③获取
a.smembers key------获取集合中所有元素
- 集合无序,返回顺序不固定
- 集合不存在返回空列表
- 大集合禁止频繁使用,会阻塞 Redis
- 适用场景:查看集合全部内容、小数据量集合遍历
b.scard key------获取指定集合中元素的总数量
- 集合不存在则返回
0 - 适用场景:统计集合元素数量、判断集合是否为空
c.srandmember key count------从集合中随机获取指定数量的元素(不会删除元素)
- 不写
count:随机返回 1 个元素 count > 0:返回count个不重复的元素count < 0:返回|count|个可能重复的元素- 集合为空返回
(nil) - 适用场景:随机抽奖、随机推荐、随机展示内容
d.spop key count------从集合中随机弹出指定数量的元素(会删除元素)
- 不写
count:随机弹出 1 个元素 count为正整数:弹出count个元素(count不能是:负数!)- 集合为空返回
(nil) - 适用场景:抽奖(抽完即出奖池)、任务池分配、随机出队
4.set类型数据的扩展操作
①求两个集合的交、并、差集
a.sinter key1 key2 ...------求多个集合的交集(所有集合都存在的元素)
- 支持多个集合,按顺序求交集
- 适用场景:共同好友、共同关注、共同标签
b.sunion key1 key2 ...------求多个集合的并集(所有集合的元素,自动去重)
- 支持多个集合,合并后自动去重
- 适用场景:全量标签、全量好友、合并多个集合
c.sdiff key1 key2 ...------求多个集合的差集(属于第一个集合,但不属于后面所有集合的元素)
- 差集顺序以第一个集合为基准,
key1 - key2 - key3... - 适用场景:A 的好友但不是 B 的好友、未完成的任务、差集过滤
②求两个集合的交、并、差集并存储到指定集合中
a.sinterstore destination key1 key2 ...------求多个集合的交集,并将结果存储到 destination 集合中
- 原子操作,返回结果集合的元素数量
destination集合存在:覆盖旧值;destination集合不存在:创建- 适用场景:缓存交集结果、持久化共同好友
b.sunionstore destination key1 key2 ...------求多个集合的并集,并将结果存储到 destination 集合中
- 原子操作,返回结果集合的元素数量
destination集合存在:覆盖旧值;destination集合不存在:创建- 适用场景:缓存并集结果、合并集合
c.sdiffstore destination key1 key2 ...------求多个集合的差集,并将结果存储到 destination 集合中
- 原子操作,返回结果集合的元素数量
destination集合存在:覆盖旧值;destination集合不存在:创建- 适用场景:缓存差集结果、过滤数据
③将指定数据从原始集合中移动到目标集合中
a.smove source destination member------将元素 member 从 source 集合移动到 destination 集合(原子操作)
- 移动成功返回
1 - 元素不存在于
source中返回0 destination中已存在该元素,仅从source中删除- 适用场景:任务状态转移(待办→已完成)、用户分组转移、标签转移
五、常用指令
(一)key常用指令
1.key基本操作
①del key------删除指定的一个或多个 key
- 支持批量删除:
del key1 key2 key3 - 不存在的 key 会被自动忽略
- 返回成功删除的 key 数量
- 注意:生产环境禁止直接
del *,会阻塞 Redis,大 key 删除用unlink替代 - 适用场景:删除过期数据、清理无用缓存、批量删除测试数据
②exists key------判断指定 key 是否存在
- 存在返回
1,不存在返回0 - 支持批量判断:
exists key1 key2,返回存在的 key 总数 - 适用场景:数据存在性校验、缓存命中判断、条件分支逻辑
③type key------获取指定 key 对应的数据类型
- 返回值:
string/list/hash/set/zset/none(key 不存在) - 适用场景:数据类型校验、避免类型错误操作、调试排查
2.key扩展操作
①sort key------对列表、集合、有序集合的元素进行排序(不修改原集合 / 列表 )
- 默认按数值升序排序,非数值按字典序
- 支持
desc降序、limit分页、alpha按字典序排序 - 仅返回排序结果,不修改原集合 / 列表
- 注意:大集合排序会阻塞 Redis,生产环境慎用
- 适用场景:列表 / 集合排序、排行榜临时排序、数据整理
②rename key newkey------将 key 重命名为 newkey
- 如果**
newkey已存在,直接覆盖旧值** key不存在则报错- 适用场景:key 命名规范整改、数据迁移、缓存 key 重命名
③renamenx key newkey------将 key 重命名为 newkey(安全重命名)
newkey不存在:重命名成功,返回1;newkey已存在:不做任何操作,返回0key不存在则报错- 适用场景:安全重命名、避免覆盖数据、分布式锁重命名
3.时效性控制(seconds:几秒后过期 (倒计时);timestamp:到时间点过期(定点))
①expire key seconds------为 key 设置秒级过期时间
- 过期后 key 自动删除
- 已设置过期时间的 key,重复执行该命令会覆盖原过期时间
- key 不存在返回
0 - 适用场景:临时缓存、验证码有效期、会话过期
②pexpire key milliseconds------为 key 设置毫秒级过期时间
- 过期后 key 自动删除
- 已设置过期时间的 key,重复执行该命令会覆盖原过期时间
- key 不存在返回
0 - 适用场景:高精度过期控制、短时效缓存
③expireat key timestamp------为 key 设置秒级时间戳 过期时间(指定具体过期时刻)
timestamp是 Unix 时间戳 (秒),如expireat key 1775419200 = key在2026-04-04 20:00:00 过期- 已过期的时间戳会直接删除 key
- 适用场景:定时删除、活动到期、固定时间失效
④pexpireat key milliseconds-timestamp------为 key 设置毫秒级时间戳 过期时间
timestamp是 Unix 时间戳(毫秒)- 已过期的时间戳会直接删除 key
- 适用场景:高精度定时删除
⑤ttl key------获取 key 的剩余秒级过期时间
- 永久有效 key:返回
-1;已过期 / 不存在 key:返回-2 - 有过期时间:返回剩余秒数
- 适用场景:查看缓存剩余有效期、调试过期逻辑
⑥pttl key------获取 key 的剩余毫秒级过期时间
- 永久有效 key:返回
-1;已过期 / 不存在 key:返回-2 - 有过期时间:返回剩余毫秒数
- 适用场景:高精度剩余时间查询
⑦persist key------移除 key 的过期时间,将其转为永久有效
- 移除成功返回
1 - key 不存在 / 无过期时间返回
0 - 适用场景:取消缓存过期、永久保留数据
5.查询模式
①keys pattern------按匹配模式查询所有符合条件的 key
| 通配符 | 作用 |
|---|---|
* |
匹配任意数量(0 个或多个)的任意字符 |
? |
匹配1 个任意字符 |
[] |
匹配括号内指定的1 个字符 (如 [st] 匹配 s 或 t) |
 使用案例
使用案例
(二)数据库常用指令

1.DB基本操作
①select index------切换到指定编号的逻辑数据库
- Redis 默认有 16 个库,编号从
0到15,客户端默认连接0号库 - 切换成功返回
OK,超出编号范围报错 - 不同数据库之间数据完全隔离,key 互不影响
- 注意:生产环境不推荐用多库隔离,建议用不同 Redis 实例,因为多库共享同一线程,会互相影响性能
- 适用场景:多业务数据隔离、测试环境与生产环境数据隔离、分库存储不同业务数据
②ping------测试 Redis 服务是否正常连通、存活
- 服务正常:返回
PONG;服务异常 / 断开:连接超时或报错 - 可带参数 :
ping "hello",返回"hello",用于自定义连通性校验 - 适用场景:服务健康检查、连接可用性测试、运维排查
2.DB扩展操作
①move key db------将当前库的指定 key 移动到目标数据库
- 原子操作,移动成功返回
1,源库的 key 会被删除,目标库新增该 key - 若目标库已存在同名 key,或源库 key 不存在,返回
0,不做任何操作 - 适用场景:数据迁移、业务分库、临时数据转移
②dbsize------统计当前数据库中 key 的总数量
- 返回当前库的 key 总数,空库返回
0 - 仅统计当前库,不影响其他库
- 适用场景:数据量统计、库容量监控、数据完整性校验
③flushdb------清空当前数据库的所有数据(不可逆!)
- 原子操作,执行后当前库所有 key 被永久删除,无法恢复
- 执行成功返回
OK - 仅清空当前库,其他库不受影响
- 警告:生产环境绝对禁止直接执行,会清空当前库所有业务数据!
- 适用场景:测试环境清空数据、重置当前库、清理无用数据
④flushall------清空所有数据库(0~15 号库)的所有数据(不可逆!)
- 原子操作,执行后 Redis 实例中所有库的所有 key 被永久删除,无法恢复
- 执行成功返回
OK - 会同时清空所有库,比
flushdb更危险 - 警告:生产环境严禁执行,会导致全实例数据丢失!
- 适用场景:Redis 实例重置、测试环境全量清空、初始化实例