一、形式语言定义
形式语言就是由有限个符号组成,并且满足某种形式规则的字符串集合。
- 字母表,也就是语言所使用的基本符号集合;
- 字符串,也就是由这些符号按顺序组成的有限序列;
- 集合,说明形式语言不是某一个单独的串,而是一类满足规则的串的整体。
形式语言 = 某字母表上满足规则的一组字符串的集合。
- 文法:用来生成形式语言。
- 自动机:用来识别形式语言。
- 不同类型的文法和自动机:对应不同复杂程度的形式语言。
二、文法的定义与组成
文法(Grammar) ,是用来描述形式语言结构规则 的一种形式化工具。
它规定了:在一个语言中,符号应该如何组合、如何替换、如何一步步生成合法的字符串。
文法的本质,就是一套"从开始符号出发,按规则不断替换,最终生成字符串"的系统。从开始符号出发,按照产生式不断替换非终结符,直到最终得到一个只含终结符的字符串。
一个文法 G 所生成的全部句子构成的集合,记作:L(G) 。它表示"由文法 G 生成的语言"。



三、句子 VS 句型
句型是指:从开始符号出发,经过若干步推导后所得到的任意符号串。
句子 是指:从开始符号出发,经过若干步推导后得到的、只由终结符组成的句型。
四、最左推导 VS 最右推导
- 最左推导 是指:在每一步推导中,总是优先替换当前句型中最左边的非终结符。
- 最右推导 是指:在每一步推导中,总是优先替换当前句型中最右边的非终结符。
最左推导和最右推导的核心区别在于每一步替换非终结符的顺序不同。
对于同一个目标句子,它们可以给出不同的推导过程;
而从整个文法来看,它们也都可以生成该文法所定义语言中的不同句子。
五、Chomsky 文法分类
- 0 型文法:无限制文法
- 1 型文法:上下文有关文法
- 2 型文法:上下文无关文法
- 3 型文法:正则文法
3型⊆2型⊆1型⊆0型
也就是说:
- 任何正则文法一定是上下文无关文法;
- 任何上下文无关文法一定是上下文有关文法;
- 任何上下文有关文法一定是 0 型文法。
0 型文法:无限制文法
它对产生式几乎没有严格限制,只要求产生式左边至少含有一个非终结符。
1 型文法:上下文有关文法
非终结符 A 能否被替换,以及替换成什么,可能与它所处的左右环境有关。
1 型文法的产生式一般满足:∣右部∣≥∣左部∣
也就是右边长度不能小于左边长度,因此推导过程中串长度通常不会缩短。
2 型文法:上下文无关文法
替换一个非终结符时,不需要看它前后是什么。
3 型文法:正则文法
左线性和右线性不能混用。
- 如果在同一个文法中既有左线性规则又有右线性规则,那它就不再是正则文法 ,而应看作上下文无关文法。






六、正则文法与有限自动机(FA)的对应关系
- 3 型文法 ↔ 有限自动机(FA)
- 2 型文法 ↔ 下推自动机(PDA)
- 1 型文法 ↔ 线性有界自动机
- 0 型文法 ↔ 图灵机
正则文法负责"生成"正则语言,有限自动机负责"识别"正则语言。
有限自动机(Finite Automaton, FA) ,是一种具有有限个状态 的抽象计算模型。它从一个初始状态出发,按输入串中的字符逐个进行状态转移;当整个输入串读完后,如果停在某个接受状态(终态),则认为该串被自动机接受。
有限自动机就是一种"边读字符、边换状态、最后判断接不接受"的模型。
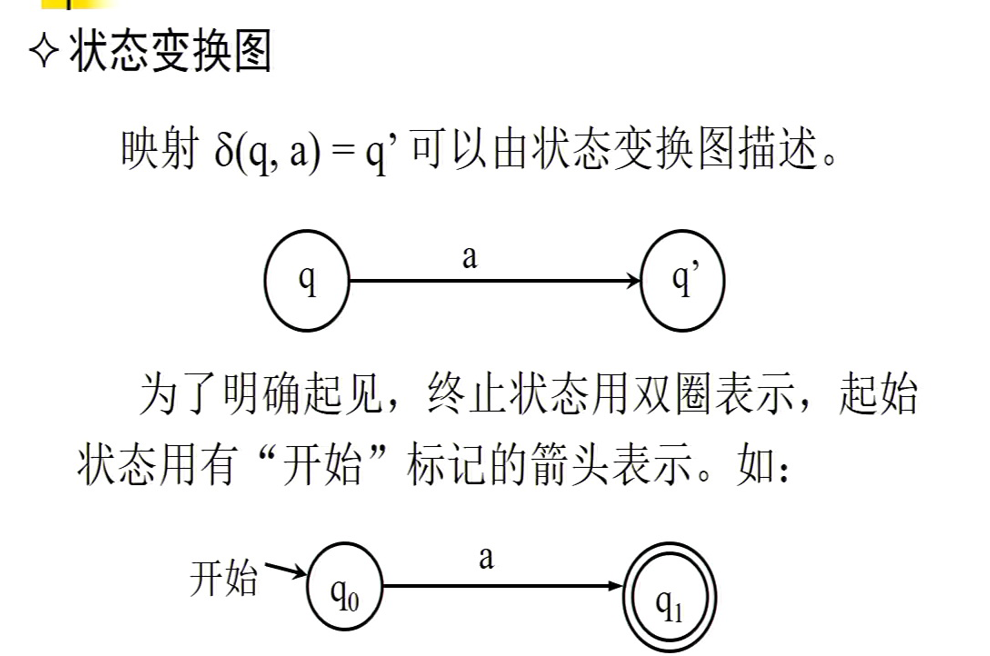
- 自动机:处在 A 这个阶段时,如果匹配到一个 a,就进入 B 这个阶段。
如果文法里有产生式 A→aB,就说明:当前还需要按 A 的规则继续生成时,先产生一个字符 a,然后剩下的生成任务交给 B。把这个过程翻译成自动机语言,就是:处在状态 A时,如果读到输入字符 a,就转到状态 B。

6.1 有限自动机的组成
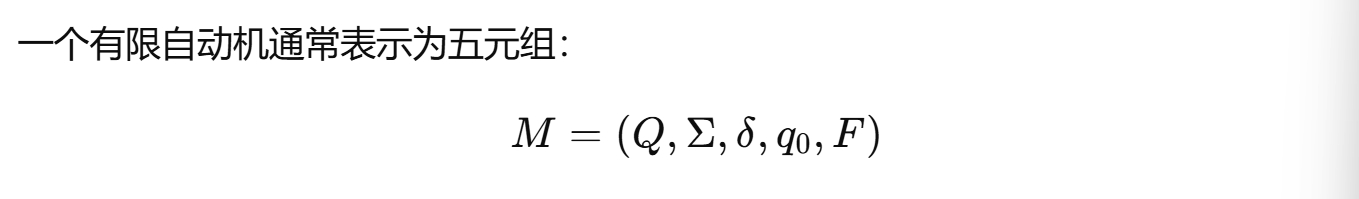
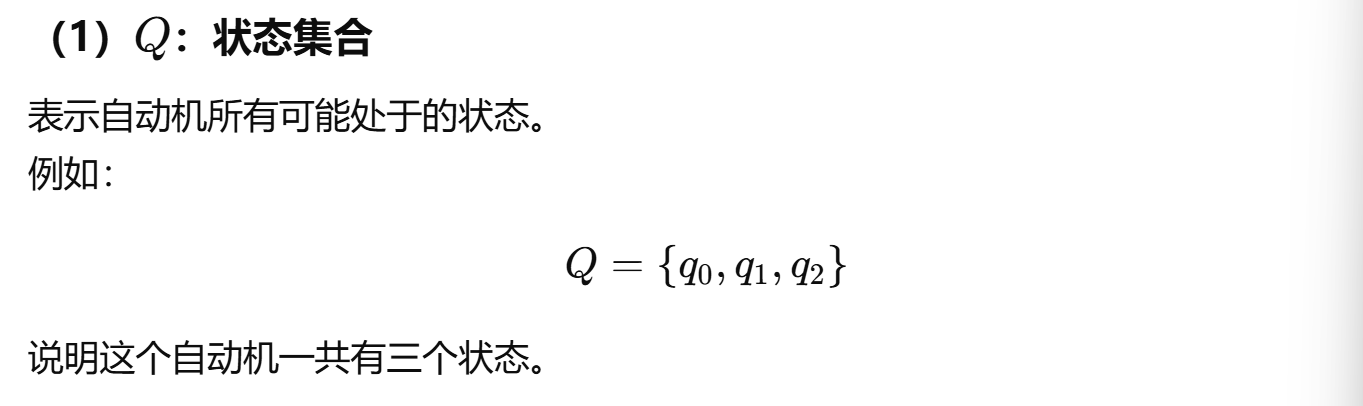



6.2 自动机工作流程
自动机的运行过程可以概括成四步:
第一步,从初始状态出发;
第二步,读取输入串的第一个字符;
第三步,根据转移函数跳到下一个状态;
第四步,重复这个过程,直到输入串读完。
最后看它停在哪:
- 如果停在终态,接受
- 如果不在终态,拒绝
所以自动机判断一个串是否合法,不是看"中途经过了什么",而主要看:
输入读完时最后停在哪个状态。
6.3 DFA (确定有限自动机)
"确定"的意思是:对于任意一个状态和任意一个输入符号,下一状态都是唯一确定的。
示例



6.4 NFA 非确定有限自动机
它和 DFA 的区别在于:
对于同一个状态和同一个输入符号,下一步可能有多个选择。
也就是说,自动机在某一步上可以"分叉"。
面对某个输入时,不止一种走法,系统可以"同时尝试多条路径"。
最后只要有一条路径能在输入读完时到达终态,这个串就算被接受。
6.5 DFA VS NFA


6.6 状态图


七、自动机在自然语言处理中的应用
7.1 编辑距离
Levenshtein 距离 ,通常叫编辑距离 ,是指:
把一个字符串转换成另一个字符串所需要的最少编辑操作次数。
常见的编辑操作包括:
- 插入
- 删除
- 替换
也就是说,两个字符串越相近,它们的编辑距离通常越小。

