摘要
本周阅读了论文Self-Supervised Cross-Language Scene Text Editing和CLIP is Almost All You Need: Towards Parameter-Efficient Scene Text Retrieval without OCR,探索跨语言图片文本编辑和无监督学习训练的方法。
Abstract
This week I read the papers Self-Supervised Cross-Language Scene Text Editing and CLIP is Almost All You Need: Towards Parameter-Efficient Scene Text Retrieval without OCR, exploring methods for cross-language image text editing and unsupervised learning training.
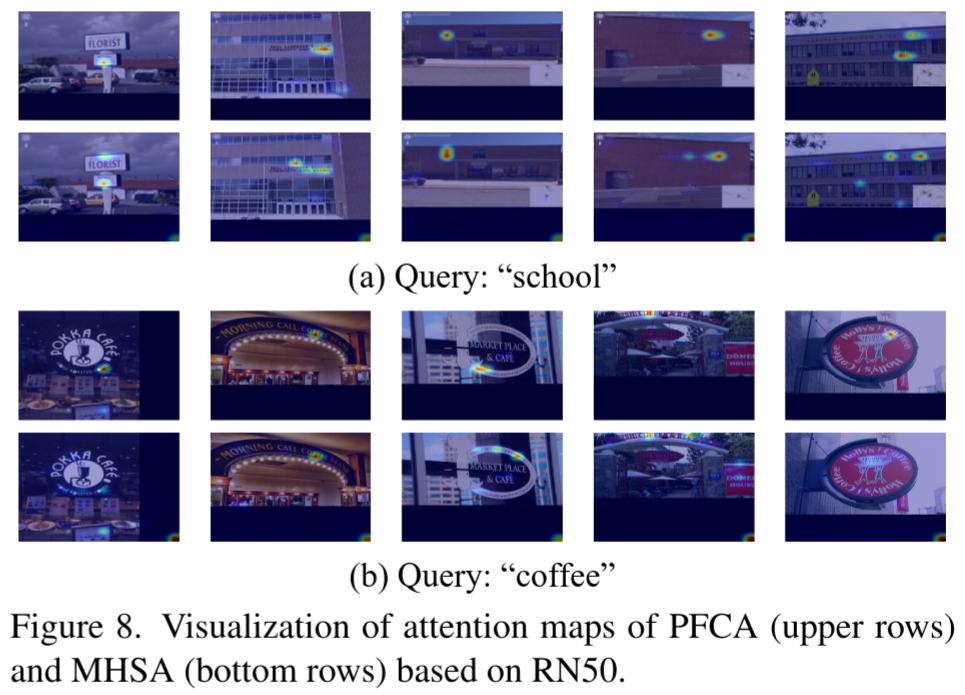

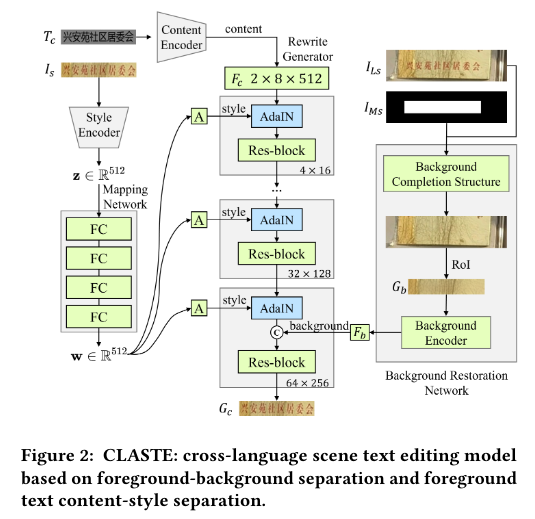
Self-Supervised Cross-Language Scene Text Editing

模型
跨多种语言的文本图片生成模型,先将输入的文本转换成字形图(glyph),然后把原始图片经过resnet提取特征,通过AdaIN注入生成过程,在最后一层加入背景特征得到生成的图片。
自监督:原始图片本身的文本作为文本输入,原始图片作为风格条件,最后由生成结果和原始图片计算损失。这样生成的图片中的文本信息来源只有输入的字形文件。
损失函数:
L1 Loss: L1=∣∣Is−Gc∣∣L_1=||I_s-G_c||L1=∣∣Is−Gc∣∣
Perceptual Loss: LPer=EΣ1Mi∣∣ϕi(Gc)−ϕi(Is)∣∣L_{Per}={E}\\Sigma\\frac{1}{M_i}\|\|\\phi_i(G_c)-\\phi_i(I_s)\|\|LPer=EΣMi1∣∣ϕi(Gc)−ϕi(Is)∣∣
此外,还加入了判别器损失和识别损失
Discriminator Loss: LD=E(logD(Is,Tc)+log(1−D(Gc,Tc)))L_D = E(log D(I_s,T_c)+log(1-D(G_c,T_c)))LD=E(logD(Is,Tc)+log(1−D(Gc,Tc)))
识别损失是计算CTC损失,仅由一个中英文预训练的RCNN识别模型来识别。在面临多语言参与训练时计算失败。但是是可接受的,因为多语言数据占比少,主要是中英文数据训练。
Text Renognition Loss: LRec=σ(CTC(R(Gci),Sci))L_{Rec} = \sigma(CTC(R(G_{c_i}),S_{c_i}))LRec=σ(CTC(R(Gci),Sci))

效果
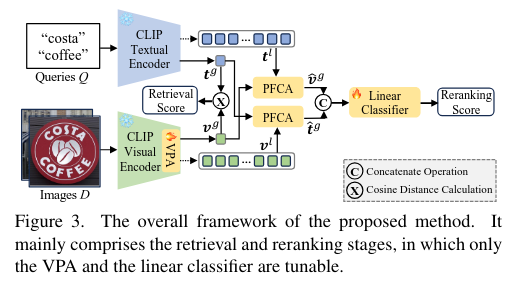
CLIP is Almost All You Need: Towards Parameter-Efficient Scene Text Retrieval without OCR

模型
输入一组文本查询Q=Q1,...,QNQQ={Q_1,...,Q_{N_Q}}Q=Q1,...,QNQ和一组图片D=D1,...,DNDD={D_1,...,D_{N_D}}D=D1,...,DND
检索阶段:文本查询集Q和图片集D计算一个NQ×NDN_Q\times N_DNQ×ND大小的相似度矩阵S。
重排序阶段:基于上一阶段得到的相似度,对于每一个查询QiQ_iQi,从图片集中找到Top-K候选图像。
细粒度验证,通过无参交叉注意力(PFCA)增强特征,输入一个线性分类器进行二分类检测。全局文本特征tgt^gtg去查询图片的局部token特征vlv^lvl,得到与文本语义相关的视觉局部信息,对称的,也用全局视觉特征查询局部文本token。
增强后的全局特征会被拼接,输入两层的线性分类器,预测这对'图像-文本'对是正样本还是负样本。

粗粒度检索

细粒度验证

模型
当前对多语言的效果不好:
1、vqgan提取中文的字形特征的能力不足。
2、模型没有学会真正的字形学习。
3、训练不足。
需要解决的问题
1、自监督训练,模型可以使用任何语言的数据进行训练,数据层面就不会有限制,模型的能力也就不会有限制。通过Clip的对比学习的方式,目标文本的字形(Glyph)经过vqgan得到特征GiG_iGi,生成的目标图片特征ItI_tIt,计算相似度矩阵S,再进行相似的细粒度验证。损失函数为交叉熵损失,最大化匹配的文本-图像对的相似度,建立跨模态对齐。\
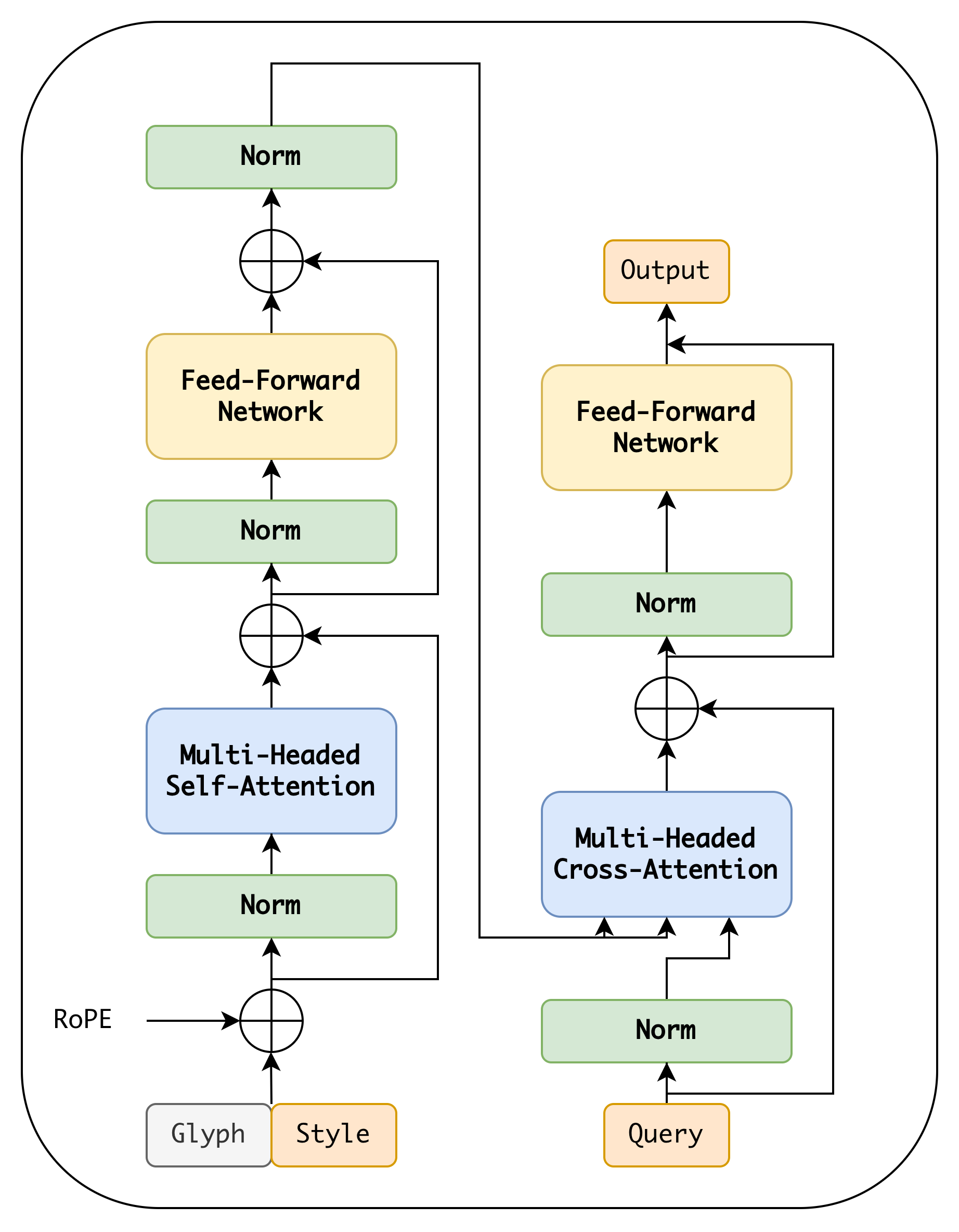
2、让模型真正的学习字形。模型可能在训练中走了捷径,从风格特征中找相似的纹理来拼凑这个字,而不是由字形图片提供字形信息,也就是为什么面对中文没见过的部首,没有办法生成。AdaIN将风格向量调制到内容特征上
AdaIN=σ(y)((x−μ(x))σ(x))+μ(y)AdaIN=\sigma(y)(\frac{(x-\mu(x))}{\sigma(x)})+\mu(y)AdaIN=σ(y)(σ(x)(x−μ(x)))+μ(y)
(x−μ(x))/σ(x)(x - \mu(x)) / \sigma(x)(x−μ(x))/σ(x) ------ 内容归一化
这一步强制去除了输入特征图 x 的通道级均值和方差。
均值μ\muμ:在 VGG/ResNet 深层特征中,通常编码了亮度和全局颜色偏移。
方差σ(x)\sigma(x)σ(x):编码了对比度和纹理强度(即笔画边缘的锐利程度、光照变化的剧烈程度)。
去除后,剩下的零均值、单位方差的特征张量,主要保留了内容的结构信息------比如"这里是横折钩的拐角","那里是背景区域"。
风格注入
μ(y)\mu(y)μ(y)(风格图均值):赋予特征图新的色调基准(如变成暖黄色、冷蓝色)。σ(y)\sigma(y)σ(y)(风格图方差):赋予特征图新的对比度基准(高方差 -> 高对比度、粗重边缘;低方差 -> 低对比度、细柔边缘)。
在 CNN 特征空间中,边缘的粗细、纹理的密度会直接反映在特征响应的强度变化(方差)上。
粗笔触、强阴影:在风格图像的边缘区域,特征图的激活值会经历剧烈的跳跃(从背景的-1到文字的+1),导致整个通道的方差 σ(y)\sigma(y)σ(y)极大。
细笔触、平滑字体:边缘过渡平缓,特征响应变化小,方差σ(y)\sigma(y)σ(y) 较小
需要风格向量化,避免模型走捷径:在img1_latent后加 Global Average Pooling 和 MLP,将其压缩为 1D 向量。将 Decoder 中的 Cross-Attn 替换为 AdaIN(或 AdaLN),将该向量作为 Scale/Bias 调制到 Decoder 每一层。
总结
下周将尝试将这些机制实现到自己的任务中,检验哪个是对任务有益的。