简介
很多人第一次认真看 IL,通常不是因为"想学一门汇编",而是因为碰到了这些问题:
- 同一段 C#,编译之后到底变成了什么
async/await、yield、lock这些语法糖到底被编译成了什么样- 为什么有些代码看着简单,运行时却没你想的那么直接
- JIT 优化、装箱、虚调用这些事,真正发生在什么阶段
这时候,IL 往往就会进入视野。
一句话先说透:
IL不是给日常业务开发替代 C# 的语言,而是 .NET 运行时世界里连接"高级语言代码"和"JIT/native code"的那一层中间表示。
这篇文章我不想写成一份指令表,也不想堆一堆术语。
更务实一点,我想围绕这些问题来讲:
IL到底在整个 .NET 执行链路里扮演什么角色;- 为什么说它比机器码更稳定,也比 C# 更接近运行时;
- 一段普通 C# 代码编译成
IL后,大概长什么样; - 为什么
IL常被说是"栈机"; - 普通开发者到底什么时候值得去看
IL,什么时候没必要。
先别急着看指令,先看它在整个执行链路里的位置
如果把一段 C# 代码真正执行起来的过程压缩一下,大致是这样:
text
C# 源码
-> 编译器编译成 IL + Metadata
-> CLR 加载程序集
-> JIT 把 IL 编译成当前平台的本机代码
-> CPU 执行本机代码这里最重要的认知是:
- C# 编译器通常不会直接把你的代码编译成最终机器码
- 它先生成的是
IL
微软官方关于托管执行过程的文档也明确说了这件事:
源码先被编译成 CPU 无关的 CIL(也就是常说的 IL),然后在运行时再由 JIT 编译成本机代码。
来源: learn.microsoft.com/en-us/dotne...
所以 IL 真正的定位不是"可有可无的中间结果",而是:
- .NET 托管执行模型的一等公民
IL 到底是什么?
它的全名通常是:
ILCILCommon Intermediate Language
本质上,它是一套和 CPU 架构无关的中间指令。
可以先这样理解:
- C# 不是直接喂给 CPU 的
IL才是编译器先生成出来、交给运行时去理解和继续处理的那层代码
这也是为什么:
- 同一个
.NET程序可以在不同架构上跑 - 因为先有一层相对统一的中间表示
除了 IL,编译器还生成了什么?
只说 IL 还不够,因为程序集里不只有指令。
编译之后,一起生成的还有:
- 类型元数据
- 方法签名
- 字段信息
- 引用关系
- 特性信息
也就是说,程序集里真正关键的是两部分:
ILMetadata
这两者合在一起,CLR 才能真正知道:
- 有哪些类型
- 每个方法签名是什么
- 这些
IL指令对应的是哪些成员和类型
所以更准确地说,运行时不是单独在看一段"裸指令",而是在看:
IL + Metadata
为什么普通开发者有时候值得看 IL?
因为它处在一个很有价值的位置:
- 比 C# 更接近运行时
- 比机器码更容易看懂
如果你只看 C#,很多语法糖会把真实执行过程藏起来。
如果你直接看机器码,又往往离业务理解太远。
IL 的价值刚好在中间。
它特别适合拿来理解这些事:
- 语法糖怎么展开
- 装箱/拆箱有没有发生
- 虚调用还是非虚调用
newobj、call、callvirt这些调用差异- 异常处理和状态机的大致形状
所以你不必天天看 IL,但在这些问题上,它往往比猜更靠谱。
如果你想自己动手,最小执行步骤是什么?
这篇讲了很多"看 IL 有什么价值",但如果你自己从来没动手看过一次,还是会觉得它有点悬。
更务实的学习方式通常不是先背指令,而是:
- 自己写一小段 C#
- 自己编译
- 自己把
IL看出来
下面给一个最小可重复流程。
第一步:先建一个最小项目
bash
dotnet new console -n IlDemo
cd IlDemo然后把 Program.cs 改成这种很小的例子:
csharp
public static class Demo
{
public static int Add(int a, int b)
{
return a + b;
}
}
Console.WriteLine(Demo.Add(1, 2));这类代码足够小,方便你把"源代码"和"IL"一一对上。
第二步:先正常编译和运行一次
bash
dotnet run目的不是为了证明程序能跑,而是先确认:
- 环境没问题
- 生成物已经出来了
如果只是想产出程序集,不运行也可以:
bash
dotnet build编译后,程序集一般会在:
text
bin/Debug/netX.Y/下面。
第三步:最快的看法,其实是先用 SharpLab
如果你只是想最快看到:
- 这段 C# 编译成了什么
IL
那最省事的通常是用:
SharpLab
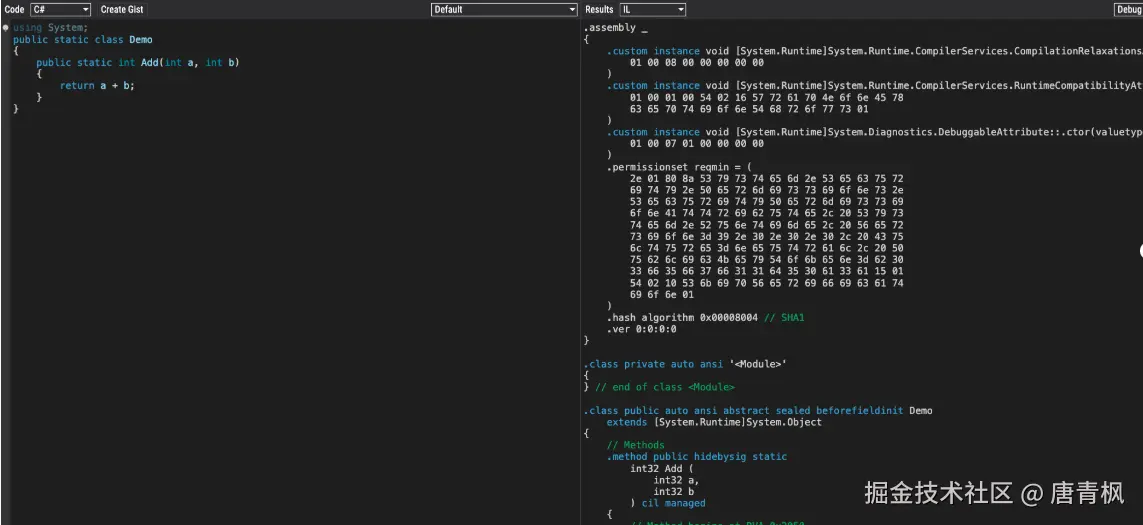
把代码贴进去,右侧切到:
IL
你马上就能看到编译结果。
它的价值特别适合学习阶段,因为:
- 不用自己找程序集
- 不用额外反编译
- 改一行代码,结果立刻变
如果你想理解:
- 装箱
callvirtasync/await
SharpLab 往往是第一站。
第四步:如果想看本地程序集,用 ILSpy 更顺
如果你想看的是:
- 本地真实编译出来的程序集
- 一个项目里多个类型、多个方法的 IL
那更顺手的通常是:
ILSpy
流程也很简单:
- 打开编译后的 DLL 或 EXE
- 找到对应类型和方法
- 切到
IL视图
这样你看到的就是:
- 这份本地程序集真实长什么样
而不是在线演示环境的结果。
第五步:如果你更偏官方工具,也可以看 ildasm
再底一点的方式是:
ildasm
它更像"原始视图",适合你已经开始认真看:
- 方法签名
- 异常块
- 元数据结构
但对刚开始学的人来说,通常不如:
- SharpLab
- ILSpy
来得顺手。
第六步:看 IL 时,先从哪种代码开始最顺?
最建议的顺序其实很朴素:
- 加法、字段访问、条件判断
- 装箱、方法调用、对象创建
- 异常处理
- 泛型、委托
async/await、yield
也就是说,最好别一上来就看:
- 状态机
- 复杂 LINQ
- 大段业务代码
那样你很容易把自己看乱。
第七步:为什么同一段代码最好同时看 Debug 和 Release?
这是一个很实用的小建议。
因为:
Debug版本通常更接近你写下去的结构Release版本更接近真实运行时优化前的编译输出
虽然最终机器码还要继续经过 JIT,但很多时候只切一下:
DebugRelease
你就会更直观地感受到:
- 编译结果并不是完全固定不变的
一句话总结"怎么开始"
如果你今天就想开始看 IL,我建议最简单的路线就是:
- 先写最小 C# 示例
- 先用 SharpLab 看第一眼
- 再用本地 ILSpy 看真实程序集
- 最后再去看更复杂的状态机和异常结构
一段最普通的 C#,编译成 IL 后是什么感觉?
先看一个很简单的方法:
csharp
public static int Add(int a, int b)
{
return a + b;
}对应的 IL 大致会像这样:
il
.method public hidebysig static int32 Add(int32 a, int32 b) cil managed
{
.maxstack 2
ldarg.0
ldarg.1
add
ret
}第一次看可能有点陌生,但其实没那么玄。
你可以这样读:
ldarg.0:把第一个参数压栈ldarg.1:把第二个参数压栈add:把栈顶两个值相加ret:返回结果
这时候你已经能看到 IL 最关键的一个特点了:
- 它是栈式指令模型
为什么总有人说 IL 是"栈机"?
因为它的大多数指令并不是像寄存器机器那样显式指定一堆寄存器,而是围绕"计算栈"工作。
最简单的理解方式就是:
- 先把数据压到栈上
- 指令再从栈顶取数据做运算
- 运算结果再压回栈
例如前面的:
il
ldarg.0
ldarg.1
add心智模型其实就是:
text
压入 a
压入 b
弹出 a 和 b
相加
把结果压回栈这就是为什么看 IL 时,最重要的往往不是单条指令本身,而是:
- 当前栈里放了什么
.maxstack 是什么意思?
这是读 IL 时经常会看到的一行:
il
.maxstack 2它表达的是:
- 这个方法执行过程中,计算栈最大需要多深
前面的 Add 方法最多只会同时把两个参数压栈,所以它是 2。
这不是业务层会直接碰到的概念,但它很能帮助你建立"IL 是栈机"的感觉。
再看一个稍微像样一点的例子
例如:
csharp
public static string GetName(Person person)
{
return person.Name;
}对应的 IL 往往会出现这类指令:
il
ldarg.0
callvirt instance string Person::get_Name()
ret这里最容易让人误会的是:
il
callvirt很多人会下意识觉得:
- 看到了
callvirt,就一定是在做虚调用
其实不完全是。
在很多普通实例方法调用里,编译器也会生成 callvirt,因为它还能顺手做实例为空检查。
所以看 IL 时,一个很实用的经验是:
- 不要只按指令名字字面猜语义
- 要结合上下文看它为什么会这样生成
call / callvirt / newobj 更细一点怎么区分?
这是看 IL 时最值得单独拆开的三条指令。
call
它通常更像"直接调用"。
最常见的场景包括:
- 静态方法调用
- 某些非虚实例方法调用
- 基类方法显式调用
可以先这样理解:
- 调用目标更直接
- 不走虚分派那套语义
例如:
csharp
Console.WriteLine("hello");对应的 IL 里很常见:
il
ldstr "hello"
call void [System.Console]System.Console::WriteLine(string)callvirt
它通常会出现在实例方法调用里。
但最容易误解的地方也在这里:
- 它不等于"这个方法一定是 virtual"
因为编译器在很多普通实例方法调用里,也会生成 callvirt,其中一个现实原因就是:
- 顺便做实例为空检查
所以更稳的理解方式是:
callvirt经常意味着"按实例方法语义调用"- 至于是不是最终真的发生虚分派,还要继续结合方法本身和运行时上下文看
newobj
这条指令很直观:
- 调用构造函数
- 创建对象实例
例如:
csharp
var p = new Person();对应 IL 里往往会看到:
il
newobj instance void Person::.ctor()
stloc.0这里很值得记住的一点是:
newobj不只是"分配内存"这个抽象动作- 它在 IL 语义上明确和构造函数调用绑在一起
如果只记一句话:
call更像直接调callvirt更像实例方法语义调用newobj更像"创建 + 调构造"
这比死记"某个一定虚、某个一定不虚"更稳。
IL 里最常见的几类指令,大概可以怎么记?
不用背完整指令表,但常见大类最好能读懂。
更实用的学习方法是:
- 先认大类
- 再认这一类里最常出现的几条
- 最后回到具体方法里,结合栈状态一起看
下面这几类,基本已经覆盖了你平时看 IL 时最常遇到的大部分内容。
1. 加载类指令:把值压到栈上
这一类最常见,因为 IL 是栈机。
只要你看到 ld*,通常都可以先往这个方向理解:
- load
- 把某个值放到计算栈上
最常见的有这些:
ldarg.*:加载方法参数ldloc.*:加载本地变量ldfld:加载实例字段ldsfld:加载静态字段ldstr:加载字符串常量ldnull:加载空引用ldc.i4.*/ldc.i8/ldc.r4/ldc.r8:加载常量值
先看最简单的参数加载:
csharp
public static int Add(int a, int b)
{
return a + b;
}对应:
il
ldarg.0
ldarg.1
add
ret这里的:
ldarg.0:把第一个参数压栈ldarg.1:把第二个参数压栈
再看一个字段访问例子:
csharp
public sealed class Person
{
public string Name = "";
}
public static string GetName(Person p)
{
return p.Name;
}大致会看到:
il
ldarg.0
ldfld string Person::Name
ret也就是说:
- 先把
p压栈 - 再从这个实例里取出
Name字段
再看常量:
csharp
int x = 42;
string s = "hello";大致会看到:
il
ldc.i4.s 42
stloc.0
ldstr "hello"
stloc.1所以这一类最值得记住的是:
ldarg看参数ldloc看局部变量ldfld看字段ldc.*看常量ldstr看字符串
2. 存储类指令:把栈顶值存回去
这一类通常是 st*。
可以先理解成:
- store
- 把栈顶值写回某个位置
最常见的有这些:
stloc.*:存回本地变量stfld:存回实例字段stsfld:存回静态字段starg.*:写回参数位置,较少见但会出现
例如:
csharp
int x = 1;
x = 2;大致会看到:
il
ldc.i4.1
stloc.0
ldc.i4.2
stloc.0再看字段赋值:
csharp
public static void SetName(Person p, string name)
{
p.Name = name;
}大致会看到:
il
ldarg.0
ldarg.1
stfld string Person::Name
ret这里可以这样理解:
ldarg.0把对象压栈ldarg.1把要写入的值压栈stfld把值存进对象字段
所以看 st* 时,最重要的是想清楚:
- 这个值从哪来
- 它最终被写到哪去
3. 算术和逻辑类指令:对栈顶值做计算
这一类最常见的有:
addsubmuldivremnegandorxornot
例如:
csharp
public static int Calc(int a, int b)
{
return (a + b) * 2;
}大致对应:
il
ldarg.0
ldarg.1
add
ldc.i4.2
mul
ret读法其实很直接:
- 压入
a - 压入
b add- 压入常量
2 mul
这类指令的关键不是名字难,而是:
- 你要始终知道栈顶现在有哪几个值
4. 比较类指令:产出真假结果
这一类经常和条件判断一起出现。
常见的有:
ceq:相等比较cgt:大于比较clt:小于比较
例如:
csharp
public static bool IsZero(int x)
{
return x == 0;
}大致会看到:
il
ldarg.0
ldc.i4.0
ceq
ret这里的 ceq 可以理解成:
- 比较栈顶两个值是否相等
- 然后把比较结果压回栈
这类指令通常不会单独存在太久,后面经常马上接:
- 分支跳转
5. 调用类指令:方法、构造函数、实例语义
这一类最常见的就是:
callcallvirtnewobj
前面已经单独讲过一次,这里再压缩成一版方便回忆:
call:更像直接调用callvirt:更像实例方法语义调用,很多时候还带空引用检查语义newobj:创建对象并调用构造函数
再补两个常见但容易忽略的调用相关指令:
constrained.:常见于泛型和值类型调用场景,用来帮助后续调用选择正确语义tail.:尾调用相关提示,平时不算高频,但在递归或优化场景里会遇到
日常阅读里,先把 call / callvirt / newobj 看明白,已经能覆盖大部分情况。
6. 控制流类指令:方法怎么跳、怎么返回
这一类指令非常重要,因为它们决定:
ifelseforwhileswitchreturn
在 IL 里到底怎么落地。
常见的有:
brbr.sbrtruebrfalsebeqbne.unswitchret
例如:
csharp
public static int Abs(int x)
{
if (x >= 0)
return x;
return -x;
}大致会有这种结构:
il
ldarg.0
ldc.i4.0
blt.s NEGATIVE
ldarg.0
ret
NEGATIVE:
ldarg.0
neg
ret这里最重要的不是精确记住每个分支名字,而是看出:
- 条件判断最终都会落成"比较 + 跳转"
循环本质上也一样。
例如 while、for 最后通常就是:
- 某个标签
- 条件比较
- 分支跳转回去
7. 对象和类型相关指令:类型系统在 IL 里怎么露面
这一类在读运行时行为时特别有用。
最常见的有:
boxunboxunbox.anycastclassisinstinitobjsizeof
先看装箱:
csharp
int value = 42;
object obj = value;大致会看到:
il
ldloc.0
box [System.Runtime]System.Int32
stloc.1再看类型转换:
csharp
object o = "hello";
var s = (string)o;大致会看到:
il
ldloc.0
castclass [System.Runtime]System.String
stloc.1而如果是:
csharp
if (o is string s)
{
}经常会和:
isinst
这类指令有关。
这一类指令的价值很大,因为它们通常直接暴露了:
- 是否发生了装箱
- 是否发生了类型检查
- 是否发生了显式转换
8. 数组和间接访问类指令:你开始更贴近内存模型的时候会遇到
常见的有:
ldelem.*stelem.*ldelemaldind.*stind.*
其中:
ldelem.*:取数组元素stelem.*:写数组元素ldelema:取数组元素地址ldind.*/stind.*:通过地址做间接读写
这类指令在普通业务代码里不一定天天见,但一旦你开始看:
Span<T>ref- 指针
- 更偏底层的性能代码
就会明显多起来。
所以你现在不用死记所有变体,但至少知道:
- 这类指令通常和数组、地址、间接访问有关
9. 异常处理类指令:异常不是"插一句 catch"那么简单
这一类常见的有:
throwrethrowleaveendfinally
前面已经专门讲过异常块结构,这里再压一遍重点:
throw:抛出一个异常对象rethrow:在 catch 中重新抛出当前异常leave:从受保护区域退出,并正确触发 finally 路径endfinally:finally 块结束
其中最值得单独记的是:
throw和rethrow不是一回事
因为:
throw ex;和throw;
在高层代码里就已经有语义差异,到了 IL 里也确实对应不同处理方式。
10. 元数据和方法体辅助指令:不显眼,但很常见
还有一类指令不一定总是最抢眼,但你经常会看到它们:
nopduppop
可以先这样理解:
nop:什么都不做,常见于调试和对齐dup:复制一份栈顶值pop:丢弃栈顶值
例如有些对象初始化、链式调用、调试版生成结果里,dup 会挺常见。
它们看起来不起眼,但经常能帮助你理解:
- 编译器为了组织栈状态,具体做了什么
如果只记一句话:
nop看成占位dup看成复制栈顶pop看成丢弃栈顶
异常块在 IL 里大概长什么样?
很多人第一次看 try/catch/finally 对应的 IL,会有点不适应。
因为它不像 C# 那样直接写成:
csharp
try
{
}
catch
{
}
finally
{
}在 IL 里,你通常会看到的是:
- 一段正常指令流
- 再配上一组异常处理块边界
- 以及像
leave、endfinally这样的控制流指令
例如这样一段 C#:
csharp
try
{
DoWork();
}
catch (Exception)
{
Handle();
}
finally
{
Cleanup();
}对应的 IL 心智模型大概是:
il
.try
{
call void DoWork()
leave.s DONE
}
catch [System.Runtime]System.Exception
{
call void Handle()
leave.s DONE
}
finally
{
call void Cleanup()
endfinally
}
DONE:
ret这里最值得注意的不是逐字背下来,而是理解两个点:
1. leave 很重要
它不是普通跳转那么简单。
在异常块语义里,leave 表达的是:
- 退出当前受保护区域
- 并在需要时保证
finally正确执行
所以很多和异常块有关的控制流,都会看到它。
2. finally 不是"单独插一段代码"
它真正依赖的是:
- 异常块元数据
endfinally- 正确的控制流退出方式
也就是说,C# 里看起来很自然的 finally,在 IL 层其实是更明确的结构化异常处理模型。
一个更贴近实际的问题:为什么看 IL 能帮你识别装箱?
因为装箱这种事,写 C# 时不一定直观。
例如:
csharp
int value = 42;
object obj = value;对应的 IL 里,通常会看到:
il
ldloc.0
box [System.Runtime]System.Int32
stloc.1这里的:
il
box就非常明确地告诉你:
- 装箱真的发生了
这也是 IL 在性能分析里最实用的地方之一。
你不用全凭经验猜"这里可能有装箱",而是能直接看到:
- 对,它真的发生了
async/await、yield 这些语法糖,为什么值得看 IL?
因为它们表面看起来很自然,但编译后形态已经完全不是你写下去的那个样子了。
以 async/await 为例,编译器通常会把方法改写成:
- 一个状态机
- 带状态字段
- 带
MoveNext方法
所以当你在排查:
- 为什么异常堆栈长这样
- 为什么局部变量生命周期看起来怪怪的
- 为什么状态会被提到字段里
这时候看 IL 或反编译后的状态机代码,就会比只盯着源代码更有效。
这也是为什么很多性能和运行时问题,最后都会顺着走到:
IL- 状态机展开
- JIT 行为
一个完整一点的 async/await 状态机拆解
如果只说"它会被编译成状态机",还是偏抽象。
不如直接看一个最小例子:
csharp
public static async Task<int> GetValueAsync()
{
await Task.Delay(100);
return 42;
}这段代码表面上很简单,但编译器通常不会把它原样保留成一个"普通方法"。
更接近真实情况的是:
- 原方法变成状态机入口
- 编译器生成一个状态机结构
- 真正逻辑主要进到
MoveNext
第一步:原方法通常会变成什么?
原方法更像会被改写成这种结构:
csharp
public static Task<int> GetValueAsync()
{
var stateMachine = new GetValueAsyncStateMachine();
stateMachine._builder = AsyncTaskMethodBuilder<int>.Create();
stateMachine._state = -1;
stateMachine._builder.Start(ref stateMachine);
return stateMachine._builder.Task;
}这里最值得记住的是三个角色:
state:当前执行到哪一步builder:负责把状态机和最终Task绑定起来MoveNext:真正推进状态机的方法
第二步:状态机里通常会有哪些字段?
大致会有这些:
int _stateAsyncTaskMethodBuilder<int> _builderTaskAwaiter _awaiter
如果原方法里还有局部变量,并且它们需要跨 await 保留下来,这些变量也可能被提到状态机字段里。
这就是为什么你会看到:
- 一些原本看起来像局部变量的东西
- 在编译后不再只是局部变量
第三步:MoveNext 到底在干什么?
你可以把 MoveNext 理解成:
- 状态机的真正执行体
它大致会做这些事:
- 看当前
state - 决定是首次执行,还是从某个
await恢复回来 - 如果遇到还没完成的 awaiter,就保存状态并挂起
- 如果 awaiter 已完成,就继续往下执行
- 最终调用
SetResult或SetException
更接近真实心智模型的伪代码大概像这样:
csharp
void MoveNext()
{
try
{
if (_state == -1)
{
var awaiter = Task.Delay(100).GetAwaiter();
if (!awaiter.IsCompleted)
{
_state = 0;
_awaiter = awaiter;
_builder.AwaitUnsafeOnCompleted(ref awaiter, ref this);
return;
}
_awaiter = awaiter;
}
if (_state == 0)
{
var awaiter = _awaiter;
_awaiter = default;
_state = -1;
awaiter.GetResult();
}
_builder.SetResult(42);
}
catch (Exception ex)
{
_builder.SetException(ex);
}
}第四步:这和 IL 有什么关系?
如果你去看编译结果,会发现:
- 原方法不再只是简单几条指令
- 状态机类型、字段、
MoveNext都进入了IL await被拆成了"检查完成 -> 保存状态 -> 注册续体 -> 恢复继续执行"这一整套结构
也就是说,async/await 真正值钱的地方不只是语法简洁,而是:
- 编译器替你写了一个非常复杂的状态机
所以当你在排查:
- 为什么这里有额外分配
- 为什么局部变量生命周期延长
- 为什么异常堆栈不是你源代码里那种线性样子
这时候去看状态机展开,往往就会豁然开朗。
IL 和 JIT 到底是什么关系?
可以先把关系说得非常简单:
- 编译器先把 C# 编译成
IL - JIT 再把
IL编译成本机代码
所以 IL 不是最终执行结果,它更像 JIT 的输入。
这也是为什么:
- 你能从
IL看出方法的大致结构 - 但最终性能表现还要继续受 JIT 优化影响
也就是说,IL 能回答:
- 编译器大概生成了什么
但不完全等于:
- CPU 最终一定怎么执行
这两层别混。
一个很常见的误区:看懂 IL,不等于看懂最终性能
这个要专门说一下。
因为很多人会把:
- "我看懂 IL 了"
直接等同成:
- "我完全知道它为什么快/慢了"
这其实不够。
真正影响最终运行性能的,还包括:
- JIT 内联
- 去虚调用
- 边界检查消除
- 常量传播
- 平台架构差异
所以更准确地说:
IL适合帮你理解编译器做了什么- JIT 和本机代码层面,才决定很多最终性能细节
普通开发者到底什么时候值得看 IL?
我觉得最值的场景主要有这几类:
1. 理解语法糖
例如:
async/awaityieldlockusing
2. 排查性能细节
例如:
- 有没有装箱
- 有没有额外分配
- 调用形态是不是你以为的那样
3. 理解运行时行为
例如:
- 泛型
- 虚调用
- 委托
- 异常处理结构
如果只是普通 CRUD 业务开发,其实完全没必要天天盯着 IL。
但当你已经开始关心:
- 编译结果
- 运行时行为
- 性能细节
它就很值得。
看 IL 最容易踩的坑
1. 把 IL 当成机器码
它不是最终机器码,它只是 JIT 之前的中间表示。
2. 只看单条指令,不看栈状态
很多指令单看没意义,要结合当前栈来读。
3. 看到 callvirt 就机械理解成虚调用
这在很多实例方法场景下都不准确。
4. 以为 IL 长得复杂,就代表运行一定慢
这中间还隔着 JIT。
一个非常务实的学习顺序
如果你想学 IL,我建议别从指令表硬背开始。
更顺的顺序通常是:
- 先理解 C# -> IL -> JIT -> Native 这条链
- 再理解"IL 是栈机"
- 先看最简单的方法:加法、字段访问、条件判断
- 再看装箱、调用、异常、泛型
- 最后再看
async/await、迭代器这种编译器改写比较重的场景
这个顺序会比一上来翻完整指令集轻松很多。
面试里怎么答比较到位?
如果面试官问:
"什么是 IL,中间码的意义是什么?"
一个比较自然的回答可以是:
IL 是 .NET 编译器生成的中间语言,处在 C# 源码和 JIT 生成的本机代码之间。它是 CPU 无关的,并且和程序集里的元数据一起构成 CLR 后续执行和 JIT 编译的基础。它的价值不只是跨平台,更重要的是让高级语言和运行时之间有了一层统一表示,所以很多语法糖、装箱、调用方式、状态机改写这些细节,都可以通过看 IL 来理解。
如果继续追问"为什么说 IL 是栈机",可以答:
因为大多数 IL 指令都是围绕计算栈工作的,先通过
ldarg、ldloc这类指令把值压栈,再由add、call等指令从栈顶取值继续运算。
如果再追问"看 IL 有什么实际价值",优先答这三个:
- 理解语法糖展开
- 判断装箱和调用形态
- 帮助分析编译器和运行时行为
总结
IL 最值得记住的,不是那些指令名,而是它在整个 .NET 执行链路里的位置:
它既不是你写出来的源代码,也不是 CPU 最终跑的机器码,而是 .NET 运行时真正开始接手你程序之前的那一层统一表示。
如果你只想记住几句话,可以记这几条:
- C# 通常先编译成
IL + Metadata,再由 JIT 编译成本机代码; IL更接近运行时,但又比机器码更容易读;- 它本质上是栈机模型,读的时候要盯着"栈";
- 装箱、调用方式、语法糖展开,都是看
IL的高价值场景; - 看懂
IL不等于完全理解最终性能,中间还隔着 JIT。
参考资料:
- Microsoft Learn: Managed execution process
learn.microsoft.com/en-us/dotne... - Microsoft Learn: What is managed code?
learn.microsoft.com/en-us/dotne...