Agent应用与图状态编排框架LangGraph
💡目标
- LangGraph 的核心概念和使用场景
- LangGraph 构建 ReAct Agent
- LangGraph 创建自定义工作流
- Memory 与 Persistence
1. LangGraph 介绍
1.1 基本概述
LangGraph 是由 LangChain 团队开发的一个开源框架,旨在帮助开发者构建基于大型语言模型(LLM)的复杂、有状态、多主体的应用。它通过将工作流表示为图结构(graph),提供了更高的灵活性和控制能力,特别适合需要循环逻辑、状态管理以及多主体协作的场景,比如智能代理(agent)和多代理工作流。
LangGraph 是为智能体和工作流设计的一套底层编排框架,旨在构建、部署和管理复杂的生成式 AI 代理工作流。它提供了一套工具和库,使用户能够以可扩展且高效的方式创建、运行和优化大型语言模型(LLM)。LangGraph 的核心是利用基于图的架构的强大功能来建模和管理AI 代理工作流中各个组件之间的复杂关系。
官方文档:https://langchain-ai.github.io/langgraph/
1.2 核心概念
图结构(Graph Structure)
LangGraph 将应用逻辑组织成一个有向图,其中:
- 节点(Nodes):代表具体的操作或计算步骤,可以是调用语言模型、执行函数或与外部工具交互等
- 边(Edges):定义节点之间的连接和执行顺序,支持普通边(直接连接)和条件边(基于条件动态选择下一步)
状态管理(State Management)
LangGraph 的核心特点是自动维护和管理状态
状态(State)是一个贯穿整个图的共享数据结构,记录了应用运行过程中的上下文信息
每个节点可以根据当前状态执行任务并更新状态,确保系统在多步骤或多主体交互中保持一致性
循环能力(Cyclical Workflows)
与传统的线性工作流(如 LangChain 的 LCEL)不同,LangGraph 支持循环逻辑,这使得它非常适合需要反复推理、决策或与用户交互的代理应用。例如,一个代理可以在循环中不断调用语言模型,直到达成目标。
1.3 主要特点
灵活性: 开发者可以精细控制工作流的逻辑和状态更新,适应复杂的业务需求
持久性: 内置支持状态的保存和恢复,便于错误恢复和长时间运行的任务
多主体协作: 允许多个代理协同工作,每个代理负责特定任务,通过图结构协调交互
工具集成: 可以轻松集成外部工具(如搜索API)或自定义函数,增强代理能力
人性化交互: 支持"人机交互"(human-in-the-loop)功能,让人类在关键步骤参与决策
1.4 使用场景
LangGraph 特别适用于以下场景:
对话代理: 构建能够记住上下文、动态调整策略的智能聊天机器人
多步骤任务: 处理需要分解为多个阶段的复杂问题,如研究、写作或数据分析
多代理系统: 协调多个代理分工合作,比如一个负责搜索信息、另一个负责总结内容的系统
1.5 与 LangChain 的关系
- LangGraph 是 LangChain 生态的一部分,但它是独立于 LangChain 的一个模块
- LangChain 更擅长处理简单的线性任务链(DAG),而 LangGraph 专注于更复杂的循环和多主体场景
- 你可以单独使用 LangGraph,也可以结合 LangChain 的组件(如提示模板、工具接口)来增强功能
2. 快速开始
2.1 创建 ReAct Agent
python
# !pip install -U langgraph langchain
# !pip install langchain-community
# !pip install dashscope
python
from langchain_community.chat_models.tongyi import ChatTongyi
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
# 配置内存存储
checkpointer = InMemorySaver()
model = ChatTongyi(
model="qwen-max",
temperature=0
)
# langgraph 内置了 ReAct 架构的 Agent
agent = create_react_agent(
model=model, # 配置LLM
tools=[get_weather], # 配置工具
checkpointer=checkpointer, # 配置短期记忆检查点
prompt="You are a helpful assistant" # 配置自定义提示
)
# Run the agent
config = {"configurable": {"thread_id": "1"}}
shanghai = agent.invoke(
{"messages": [{"role": "user", "content": "上海的天气怎样"}]},
config
)
shanghai
hangzhou = agent.invoke(
{"messages": [{"role": "user", "content": "杭州怎么样?"}]},
config
)
hangzhou{'messages': [HumanMessage(content='上海的天气怎样', additional_kwargs={}, response_metadata={}, id='00e29276-ae29-4fa6-a734-772079dd43c7'),
AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'get_weather', 'arguments': '{"city": "上海"}'}, 'index': 0, 'id': 'call_d0e5333fd49f4e70867d30', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-max', 'finish_reason': 'tool_calls', 'request_id': '30f4304d-5486-906e-bc66-ea51cc38d5e6', 'token_usage': {'input_tokens': 169, 'output_tokens': 17, 'total_tokens': 186, 'prompt_tokens_details': {'cached_tokens': 0}}}, id='run--9d672852-7229-4434-8b07-bf5f0e826d2a-0', tool_calls=[{'name': 'get_weather', 'args': {'city': '上海'}, 'id': 'call_d0e5333fd49f4e70867d30', 'type': 'tool_call'}]),
ToolMessage(content="It's always sunny in 上海!", name='get_weather', id='faecdc0c-5246-4553-a33a-5b019b696bd2', tool_call_id='call_d0e5333fd49f4e70867d30'),
AIMessage(content='上海的天气总是晴朗!不过这可能不是最准确的实时信息,获取最新天气情况请查询可靠的天气预报。如果需要,我可以帮您查找更准确的信息。', additional_kwargs={}, response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': '4348079f-0c34-91d2-9e27-43a73c69766d', 'token_usage': {'input_tokens': 201, 'output_tokens': 40, 'total_tokens': 241, 'prompt_tokens_details': {'cached_tokens': 0}}}, id='run--6ee300f9-d789-4d4a-95f0-44538f3a6daa-0'),
HumanMessage(content='杭州怎么样?', additional_kwargs={}, response_metadata={}, id='6ec6288b-afe4-47c1-93ab-780cac21755f'),
AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'get_weather', 'arguments': '{"city": "杭州"}'}, 'index': 0, 'id': 'call_6772c5e9528a4946acebd6', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-max', 'finish_reason': 'tool_calls', 'request_id': 'bd4d4173-dc98-906b-b27e-3cb27d8f3c22', 'token_usage': {'input_tokens': 254, 'output_tokens': 17, 'total_tokens': 271, 'prompt_tokens_details': {'cached_tokens': 0}}}, id='run--7e1269db-3ada-445a-9126-3e4ee636ea7c-0', tool_calls=[{'name': 'get_weather', 'args': {'city': '杭州'}, 'id': 'call_6772c5e9528a4946acebd6', 'type': 'tool_call'}]),
ToolMessage(content="It's always sunny in 杭州!", name='get_weather', id='30558a1c-8169-4cbe-8675-0309d51d4efd', tool_call_id='call_6772c5e9528a4946acebd6'),
AIMessage(content='杭州的天气也总是晴朗!但请注意,这可能不是当前最准确的信息。为了获取最新的天气情况,请参考实时天气预报。如果您需要最新信息,我可以帮助您查找。', additional_kwargs={}, response_metadata={'model_name': 'qwen-max', 'finish_reason': 'stop', 'request_id': '98995810-7f38-9672-91fc-0d67bcb0f801', 'token_usage': {'input_tokens': 287, 'output_tokens': 43, 'total_tokens': 330, 'prompt_tokens_details': {'cached_tokens': 0}}}, id='run--651609e5-a2f3-4a08-903d-5c445bb78a8f-0')],
'structured_response': None}2.2 创建自定义工作流
2.2.1 构建一个基本的聊天机器人
python
from typing import Annotated
from langchain_community.chat_models.tongyi import ChatTongyi
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
# 1. 创建 StateGraph
graph_builder = StateGraph(State)
llm = ChatTongyi(model="qwen-max", temperature=0)
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# 添加一个 chatbot 节点
graph_builder.add_node("chatbot", chatbot)
# 添加一个entry点来告诉图表每次运行时从哪里开始工作
graph_builder.add_edge(START, "chatbot")
# 添加一个exit点来指示图表应该在哪里结束执行
graph_builder.add_edge("chatbot", END)
# 编译图
graph = graph_builder.compile()
python
# 可视化图(可选)
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass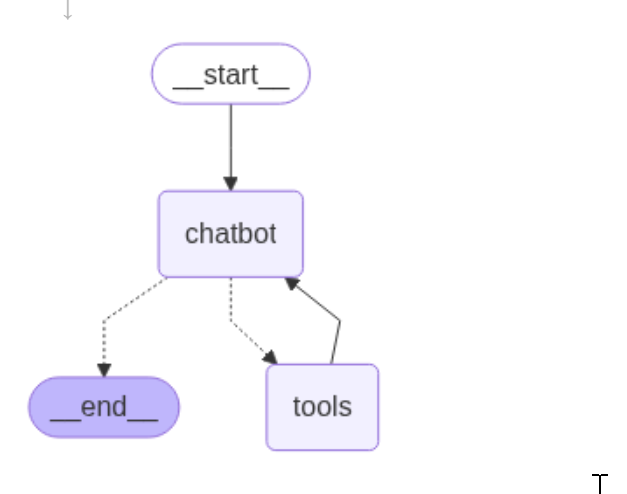
python
# 运行聊天机器人
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except:
# fallback if input() is not available
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
breakUser: 我是kevin
Assistant: 你好,Kevin!很高兴认识你。有什么我可以帮助你的吗?
User: 我是谁
Assistant: 您好!您是使用阿里云开发的超大规模语言模型"通义千问"的用户。在这里,您可以提出问题、寻求帮助或与我交流。如果您想分享更多关于您的信息,我会更具体地了解您的情况,并提供更有针对性的帮助。不过,请记得不要分享过于私密的信息以保护您的隐私安全。
User: q
Goodbye!2.2.2 添加工具
安装使用Tavily 搜索引擎
python
# !pip install -U langchain-tavily
python
from langchain_tavily import TavilySearch
tavily_search = TavilySearch(max_results=2)
tools = [tavily_search]
tavily_search.invoke("What's a 'node' in LangGraph?"){'query': "What's a 'node' in LangGraph?",
'follow_up_questions': None,
'answer': None,
'images': [],
'results': [{'url': 'https://www.ibm.com/think/topics/langgraph',
'title': 'What is LangGraph? - IBM',
'content': 'LangGraph, created by LangChain, is an open source AI agent framework designed to build, deploy and manage complex generative AI agent workflows. At its core, LangGraph uses the power of graph-based architectures to model and manage the intricate relationships between various components of an AI agent workflow. LangGraph illuminates the processes within an AI workflow, allowing full transparency of the agent's state. By combining these technologies with a set of APIs and tools, LangGraph provides users with a versatile platform for developing AI solutions and workflows including chatbots, state graphs and other agent-based systems. Nodes: In LangGraph, nodes represent individual components or agents within an AI workflow. LangGraph uses enhanced decision-making by modeling complex relationships between nodes, which means it uses AI agents to analyze their past actions and feedback.',
'score': 0.90907925,
'raw_content': None},
{'url': 'https://www.ionio.ai/blog/a-comprehensive-guide-about-langgraph-code-included',
'title': 'A Comprehensive Guide About Langgraph: Code Included - Ionio',
'content': 'A node can be any function or tool your agent uses in langgraph and these nodes are connected with other nodes using edges. Every workflow ends with a "END"',
'score': 0.89166987,
'raw_content': None}],
'response_time': 1.21,
'request_id': '37712321-9fb2-484b-8355-f8dc4bf4fe3c'}
python
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import tools_condition, ToolNode
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
# Modification: tell the LLM which tools it can call
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode([tavily_search])
graph_builder.add_node("tools", tool_node)<langgraph.graph.state.StateGraph at 0x26b0488dc50>
python
def route_tools(
state: State,
):
"""
Use in the conditional_edge to route to the ToolNode if the last message
has tool calls. Otherwise, route to the end.
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
graph_builder.add_conditional_edges(
"chatbot",
route_tools,
{"tools": "tools", END: END},
)
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
python
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass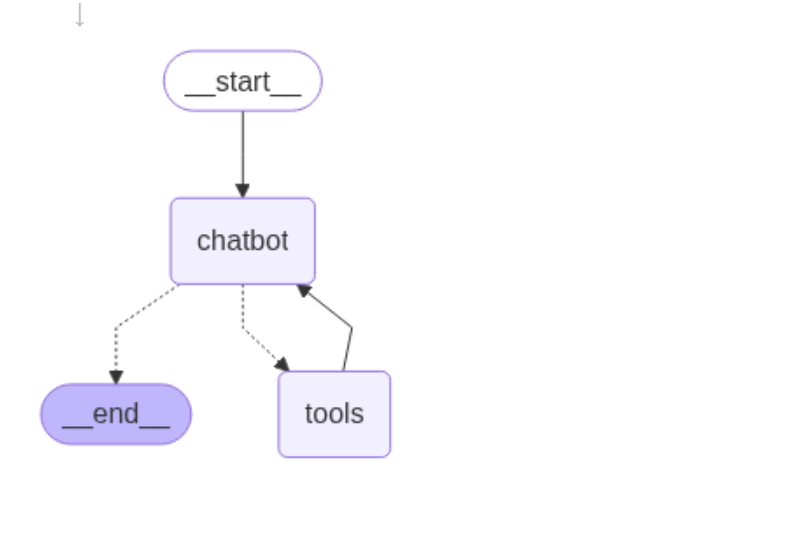
python
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except:
# fallback if input() is not available
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
breakUser: 你好
Assistant: 你好!有什么可以帮助你的吗?
User: 推荐2款性价比最高的苹果手机?
Assistant:
Assistant: {"query": "最高性价比的苹果手机", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://finance.sina.com.cn/tech/roll/2025-04-07/doc-inesiwtr4369361.shtml", "title": "苹果手机价格大跳水,2025"最值得买"的苹果手机推荐 - 新浪财经", "content": "点击手机上的确认即可登录\n\nImage 7Image 8\n\nImage 9\n\n\n\n腾讯QQQQ空间\n\n尽管国产手机厂商近年来不断冲击高端市场,但苹果在高端机市场的销量依旧"遥遥领先",占据了国内市场一大半市场份额。进入2025年4月,苹果多款机型价格集体"大跳水",这对"等等党"来说,无疑是福音了。\n\n不过目前在售的苹果手机有很多,某些机型价格存在重合,这个时候,哪款更值得买,是很多消费者都会纠结的问题。本期,我们盘点2025公认"最值得买"的4款苹果手机,公认好口碑,一起看看有你喜欢的吗?\n\n首先,划重点!一定要先领!手机数码国补的领取方法是:京东APP搜「数码省2000」国补直接立减2000元,家电国补的领取方法是:京东APP搜「家电省2000」进入活动页面领取。\n\n秘诀:先在app搜一下上面的口令,以后每天点历史搜索记录就可以!\n\n一、iPhone 16\n\n京东搜"苹果省500"国补后价格:4499元(128GB)\n\n推荐理由:iPhone 16系列"性价比最高"的手机,参数党"沉默机"。 [...] 虽然iPhone 16e也上市了,但目前的iPhone 16降价力度更大,相比发布时便宜了1500元,成为了比iPhone 16e更有性价比的选择,它搭载的A18处理器,单核跑分3500+,多核8700+,GPU性能比上代提升20%,可以轻松驾驭搭载手游。\n\n搭载的那块6.1英寸的XDR屏幕,虽然没有高刷,实际画质表现,却可以和iPhone 16 Pro系列一较高下。具备2000尼特峰值亮度,阳光下清晰可视,还是灵动岛全面屏的设计,耐用性出色,使用了航空级铝金属边框+超瓷晶玻璃,支持IP68防水。\n\n该机后置使用了4800万主摄,1200万超广角的组合,支持2倍光学变焦,4K 60帧视频录制,还有空间视频,空间照片功能,给到了全新的快捷拍照物理按键,且具备3561mAh大电池,续航比前代提升2-3小时。\n\n这款手机非常适合轻度游戏用户使用,对于摄影小白,或者是追求耐用性的职场新人,还有追求性价比的用户,iPhone 16都是不错的选择,目前来说,粉色、蓝色、白色的保值率更高,推荐优先考虑这几个配色。\n\n二、iPhone 13 [...] 京东搜"苹果省500"国补后价格:2849元(128GB)\n\n推荐理由:经典钉子户之选,中端机市场的"性价比屠夫",诸多体验不输新款。\n\n虽然iPhone 13是4年前发布的机型,但搭载的A15处理器,至今仍可流畅运行《王者荣耀》《原神》等主流游戏,搭配iOS 18系统优化,日常使用无卡顿;它搭载的6.1英寸XDR屏幕,画质表现不输iPhone 16e,却便宜了1000多元。\n\n影像方面,后置给到了1200万双摄,并支持位移式的光学防抖。满足日常拍照已经没啥压力,内置了3227mAh电池,配合20W快充,一天一充依旧没啥压力,15W无线充电和新款差距不大。\n\n它的耐用性依旧不错,给到了超瓷晶玻璃面板,金属中框,IP68防水的设计,原本需要5999元,如今不到2900元的价格,就具备Face ID、4K视频录制,流畅的系统体验,还有轻薄的机身设计,也是非常划算了。\n\n这款手机非常适合预算有限的学生党、或者是买苹果手机过渡,或者是首次入手iOS生态的用户,目前128GB版本的性价比更高。\n\n三、iPhone 16 Pro\n\n京东搜"苹果省500"惊喜卷后价格:7899元(256GB)", "score": 0.7781275, "raw_content": null}, {"url": "https://www.sohu.com/a/902116471_121830331", "title": "2025年5款性价比无敌苹果手机!再战3年不是问题!这5款iPhone都 ...", "content": "重量感人:227 克的机身,单手操作几乎不可能。他直播时得用三脚架固定,不然手酸得发抖。\n 价格破万:1TB 版本售价高达 13999 元,存储溢价明显。他买的 256GB 版本,存了 50 个 4K 视频就满了,只能外接硬盘。\n\n选购指南:哪款最适合你?\n============\n\n学生党 / 预算有限:\n===========\n\n 推荐型号:iPhone 15\n 理由:价格亲民,性能够用,适合日常使用。二手平台 4000 元左右就能拿下,性价比超高。\n\n追剧党 / 游戏玩家:\n===========\n\n 推荐型号:iPhone 15 Plus\n 理由:大屏 + 长续航,看电影、玩游戏都很爽。二手平台 4500-5500 元,比同价位安卓大屏手机便宜 1000+。\n\n摄影师 / 内容创作者:\n============\n\n 推荐型号:iPhone 15 Pro Max\n 理由:专业级影像系统,拍 Vlog、照片都很惊艳。二手平台 6000-7000 元,适合预算充足的用户。\n\n科技发烧友 / 追求极致:\n============= [...] 重点推荐! 作为 2024 年的 Pro 版,iPhone 16 Pro 在 2025 年堪称「性价比之王」。我自己刚入手一台,用了三个月,只能说两个字:真香!\n\n核心优势:\n\n 性能天花板:A18 Pro 芯片 + 8GB 运存,性能比 A17 Pro 提升 20%。我试过同时开微信、抖音、游戏、修图软件,切换起来毫无卡顿。\n 拍照升级:4800 万像素主摄 + 4800 万超广角 + 1200 万长焦,拍照效果比 iPhone 15 Pro Max 更上一层楼。我用它拍夜景,噪点控制得比专业相机还好。\n 续航提升:3860mAh 电池,实测连续玩《原神》6 小时还剩 20% 电。我每天通勤刷短视频、听音乐,两天充一次电完全没问题。\n 价格亲民:叠加国补后,128GB 版本只要 5499 元,比发布价便宜了 2500 元!这价格能买到 Pro 版,简直是「捡漏」。\n\nImage 11\n\n缺点提醒: [...] 作为苹果 2023 年的入门旗舰,iPhone 15 在 2025 年依然是「性价比担当」。我去年给老妈买了一台,她到现在还夸「这手机拍照比广场舞大姐的华为 P60 还清楚」!\n\n核心优势:\n\n 性能够用:A16 芯片虽然不如 A18 Pro,但日常刷微信、看视频、轻度游戏完全没问题。我实测《王者荣耀》高清画质能稳定 60 帧,一点不卡顿。\n 拍照能打:4800 万像素主摄 + 1200 万超广角,拍风景、人像都很自然。老妈用它拍广场舞视频,连领舞阿姨的皱纹都能看清(阿姨差点跟她急)。\n 价格亲民:二手平台 3000 元左右就能拿下,比同价位安卓机耐用多了。我同事去年买的某安卓旗舰,现在已经卡成「老年机」了。\n\nImage 6\n\n缺点提醒:\n\n_展开全文_\n\n 续航一般:3349mAh 电池,重度使用一天得充两次电。建议给长辈买的话,搭配个 20W 快充头。\n 信号拉胯:在地下车库、电梯里经常没信号,我妈有次在超市结账,扫码付款愣是转了 3 分钟圈圈。\n\n【隐藏彩蛋】618的折扣与2025年国家补贴\n======================", "score": 0.6892434, "raw_content": null}], "response_time": 3.61, "request_id": "63d80a23-5f7c-4fb4-8416-21db4a47751b"}
Assistant: 根据搜索结果,以下是两款性价比最高的苹果手机推荐:
1. **iPhone 16**:
- 京东国补后价格:4499元(128GB)
- 推荐理由:搭载A18处理器,性能强大;6.1英寸XDR屏幕,画质优秀;后置4800万主摄和1200万超广角的相机组合,支持多种拍摄功能。这款手机适合轻度游戏用户、摄影新手以及追求性价比的用户。
- [更多详情](https://finance.sina.com.cn/tech/roll/2025-04-07/doc-inesiwtr4369361.shtml)
2. **iPhone 13**:
- 京东国补后价格:2849元(128GB)
- 推荐理由:尽管是几年前发布的机型,但其A15处理器依然能够流畅运行主流游戏和应用。它同样配备了6.1英寸XDR屏幕,并且在影像方面提供良好的表现。对于预算有限的学生党或初次尝试iOS生态系统的用户来说非常合适。
- [更多详情](https://finance.sina.com.cn/tech/roll/2025-04-07/doc-inesiwtr4369361.shtml)
这两款手机均被认为是在当前市场上性价比较高的选择。具体购买时可根据个人需求及偏好进一步考虑。
另外还有一款值得一提的是 **iPhone 16 Pro**:
- 京东惊喜卷后价格:7899元 (256GB)
- 推荐理由:该型号拥有A18 Pro芯片与8GB运存,性能卓越;升级后的三摄像头系统提供了出色的拍照体验;电池续航也有所提升。虽然价格稍高一些,但是叠加国家补贴之后变得相当有吸引力,特别是对那些寻求高端配置同时又注重成本效益的消费者而言。
- [更多详情](https://www.sohu.com/a/902116471_121830331)
希望这些建议能帮助您找到合适的苹果手机!如果您需要更多信息,请随时告诉我。
User: q
Goodbye!2.2.3 添加记忆
聊天机器人现在可以使用工具来回答用户的问题,但它无法记住之前交互的上下文。这限制了它进行连贯、多轮对话的能力。
LangGraph 通过持久化检查点checkpointer解决了这个问题。如果您在编译图时提供,并thread_id在调用图时提供 ,LangGraph 会在每一步之后自动保存状态。当您再次使用相同的调用图时thread_id,图会加载其已保存的状态,从而允许聊天机器人从上次中断的地方继续执行。
python
from langgraph.checkpoint.memory import InMemorySaver
# 这是内存检查点,这对于本教程来说很方便。
# 但是,在生产应用程序中,需要将其更改为使用SqliteSaver、PostgresSaver 或 RedisSaver数据库。
memory = InMemorySaver()
graph = graph_builder.compile(checkpointer=memory)
python
# 与聊天机器人互动
config = {"configurable": {"thread_id": "1"}}
user_input = "Hi there! My name is Kevin."
# The config is the **second positional argument** to stream() or invoke()!
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config,
stream_mode="values",
)
for event in events:
event["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
Hi there! My name is Kevin.
==================================[1m Ai Message [0m==================================
Hello Kevin! It's nice to meet you. How can I assist you today?
python
# 提出后续问题,看能否记得我是谁?
user_input = "Remember my name?"
config = {"configurable": {"thread_id": "2"}}
# The config is the **second positional argument** to stream() or invoke()!
events = graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config,
stream_mode="values",
)
for event in events:
event["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
Remember my name?
==================================[1m Ai Message [0m==================================
I'm sorry, but as an AI, I don't have the capability to remember specific user information across different conversations to protect your privacy. Could you please tell me your name again?3. 持久化状态
LangGraph 内置了一个持久化层,通过检查点(checkpointer)机制实现。当你使用检查点器编译图时,它会在每个超级步骤(super-step)自动保存图状态的检查点。这些检查点被存储在一个线程(thread)中,可在图执行后随时访问。由于线程允许在执行后访问图的状态,因此实现了人工介入(human-in-the-loop)、记忆(memory)、时间回溯(time travel)和容错(fault-tolerance)等强大功能。
3.1 什么是记忆(Memory)
记忆是一种认知功能,允许人们存储、检索和使用信息来理解他们的现在和未来。通过记忆功能,代理可以从反馈中学习,并适应用户的偏好。
-
短期记忆(Short-term memory) 或称为线程范围内的记忆,可以在与用户的单个对话线程中的任何时间被回忆起来。LangGraph将短期记忆管理为代理状态的一部分。状态会被使用检查点机制保存到数据库中,以便对话线程可以在任何时间恢复。当图谱被调用或者一个步骤完成时,短期记忆会更新,并且在每个步骤开始时读取状态。这种记忆类型使得AI能够在与用户的持续对话中保持上下文和连贯性,确保了交互的流畅性和效率。例如,在一系列的询问、回答或命令执行过程中,用户无需重复之前已经提供的信息,因为AI能够记住这些细节并根据需要利用这些信息进行响应或进一步的操作。这对于提升用户体验,尤其是复杂任务处理过程中的体验至关重要。
-
长期记忆(Long-term memory) 是在多个对话线程之间共享的。它可以在任何时间、任何线程中被回忆起来。记忆的范围可以限定在任何自定义命名空间内,而不仅仅局限于单个线程ID。LangGraph提供了存储机制,允许您保存和回忆长期记忆。
这种记忆类型使得AI能够在不同对话或用户交互中保留和利用信息。例如,用户的偏好、历史记录或特定的上下文信息可以跨会话保存下来,并在未来的任何交互中被调用。这种方式为用户提供了一种无缝体验,无论他们何时或以何种方式与AI交互,AI都能根据过去的信息做出更个性化、更智能的响应。这对于构建深度用户关系和增强系统适应性至关重要。
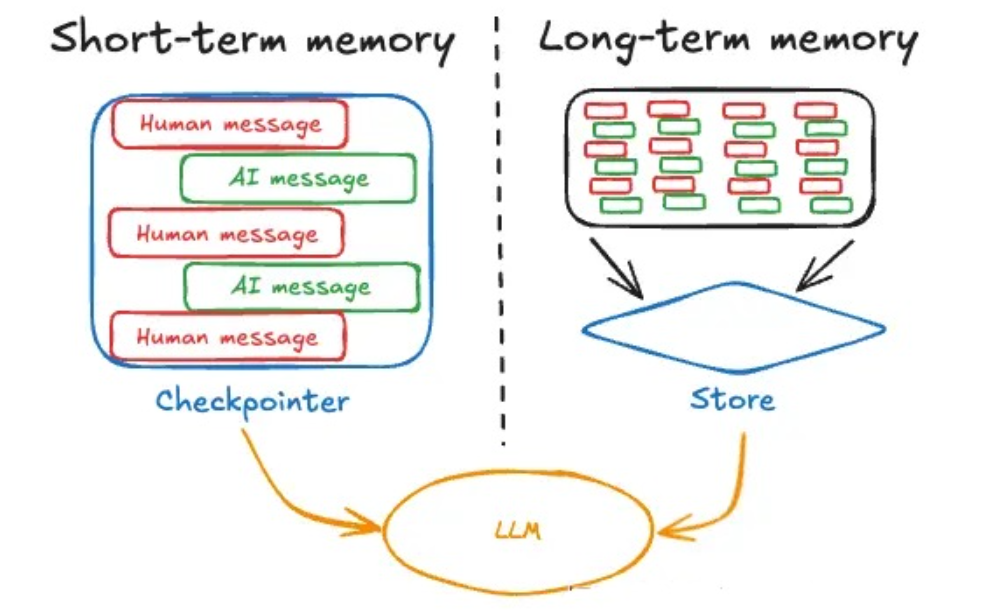
3.2 持久化(Persistence)
许多AI应用需要记忆功能来在多次交互中共享上下文。在LangGraph中,这种类型的记忆可以通过线程级别的持久化添加到任何StateGraph中。
通过使用线程级别的持久化,LangGraph允许AI在与用户的连续对话或交互过程中保持信息的连贯性和一致性。这意味着,在一个交互中获得的信息可以被保存并在后续的交互中使用,极大地提升了用户体验。例如,用户在一个会话中表达的偏好可以在下一个会话中被记住和引用,使得交互更加个性化和高效。这种方法对于需要处理复杂或多步骤任务的应用特别有用,因为它确保了用户无需重复提供相同的信息,同时也让AI能够更好地理解和响应用户的需求。
4. LangGraph 中使用 Memory
python
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.checkpoint.memory import MemorySaver
# 创建 Graph
# MessagesState 是一个 State 内置对象,add_messages 是内置的一个方法,将新的消息列表追加在原列表后面
graph_builder = StateGraph(MessagesState)
python
# 定义一个执行节点
# 输入是 State,输出是系统回复
def chatbot(state: MessagesState):
# 调用大模型,并返回消息(列表)
# 返回值会触发状态更新 add_messages
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# 为了添加持久性,我们需要在编译图表时传递检查点。使用 MemorySaver 就可以记住以前的消息!
graph = graph_builder.compile(checkpointer = MemorySaver())
python
from IPython.display import Image, display
# 可视化展示这个工作流
try:
display(Image(data=graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(e)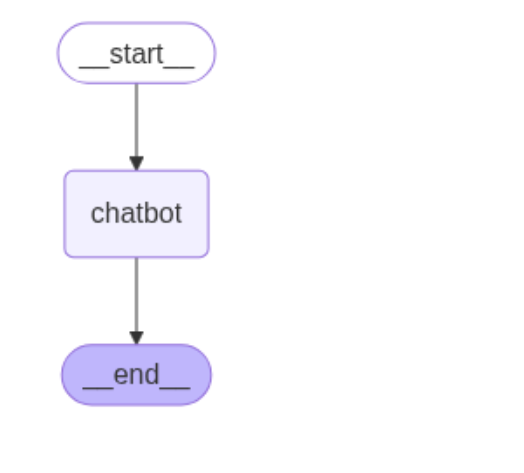
python
config = {"configurable": {"thread_id": "1"}}
input_message = {"role": "user", "content": "hi! I'm kevin"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
hi! I'm kevin
==================================[1m Ai Message [0m==================================
Hello Kevin! It's nice to meet you. How can I assist you today?
python
input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
what's my name?
==================================[1m Ai Message [0m==================================
Your name is Kevin! Is there anything specific you'd like to chat about or any questions you have?如果我们想开始一个新的对话,可以通过传递不同的会话标识符或配置来实现。这意味着为新的交互创建一个独立的上下文,确保新对话不会受到之前对话状态的影响,从而保持数据和记忆的隔离。但是这样所有记忆都会消失!
python
input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream(
{"messages": [input_message]},
{"configurable": {"thread_id": "2"}},
stream_mode="values",
):
chunk["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
what's my name?
==================================[1m Ai Message [0m==================================
I'm sorry, but I don't have access to personal information about you, including your name, as our conversation is designed to be private and secure. Could you please tell me your name or how I should address you?5. LangGraph 中使用 InMemoryStore
InMemoryStore是一个基于内存的存储系统,用于在程序运行时临时保存数据。它通常用于快速访问和存储短期记忆或会话数据。我们可以使用使用 langgraph 和 langchain_openai 库来创建一个基于内存的存储系统(InMemoryStore),并结合 OpenAI 的嵌入模型 (OpenAIEmbeddings) 来处理嵌入向量。
大家可能有疑惑,我们不是用了MemorySaver持久化消息吗,为啥还要用InMemoryStore,他们的主要区别在于数据的持久性和应用场景。InMemoryStore主要用于短期、临时的数据储,强调快速访问;而MemorySaver则侧重于将数据从临时存储转移到持久存储,确保数据可以在多次程序执行间保持不变。在我们设计系统时,可以根据具体需求选择合适的存储策略。对于只需要在会话内保持的数据,可以选择InMemoryStore;而对于需要长期保存并能够在不同会话间共享的数据,则应考虑使用MemorySaver或其他形式的持久化存储解决方案。
下面给大家展示一个结合两种方式的例子,我们实现了一个对话模型的调用逻辑,通过从存储系统中检索与用户相关的记忆信息并将其作为上下文传递给模型,同时支持根据用户指令存储新记忆,确保每个用户的记忆数据独立且自包含,从而提升对话的个性化和连贯性。
python
from langgraph.store.memory import InMemoryStore
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddings
in_memory_store = InMemoryStore(
index={
"embed": DashScopeEmbeddings(model="text-embedding-v1"),
"dims": 1536,
}
)
import uuid
from typing import Annotated
from typing_extensions import TypedDict
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import MemorySaver
from langgraph.store.base import BaseStore
from langchain.chat_models import init_chat_model
model = ChatTongyi(model="qwen-max")
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Kevin"
store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=MemorySaver(), store=in_memory_store)
python
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
input_message = {"role": "user", "content": "Hi! Remember: my name is Kevin"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
Hi! Remember: my name is Kevin
==================================[1m Ai Message [0m==================================
Hello Kevin! Nice to meet you. I'll do my best to remember your name going forward. Is there anything in particular you'd like to chat about today, or did you just want to introduce yourself?
python
# 我们先改变一下config,使用一个新的线程,用户保持不变
config = {"configurable": {"thread_id": "2", "user_id": "1"}}
input_message = {"role": "user", "content": "what is my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
what is my name?
==================================[1m Ai Message [0m==================================
Your name is Kevin.
python
# 现在,我们可以检查我们的store,并验证我们实际上已经为用户保存了记忆:
for memory in in_memory_store.search(("memories", "1")):
print(memory.value){'data': 'User name is Kevin'}
python
# 现在,让我们为另一个用户运行这个图,以验证关于第一个用户记忆是独立且自包含的。
config = {"configurable": {"thread_id": "3", "user_id": "2"}}
input_message = {"role": "user", "content": "what is my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()================================[1m Human Message [0m=================================
what is my name?
==================================[1m Ai Message [0m==================================
I don't have access to personal information unless you share it with me. You can tell me your name, and I'll happily use it in our conversation! 😊6. 实现RAG
python
# !pip install pymupdf
# !pip install faiss-cpu
python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import PyMuPDFLoader
# 加载文档
loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf")
pages = loader.load_and_split()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=200,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents(
[page.page_content for page in pages[:2]]
)
# 灌库
embeddings = DashScopeEmbeddings(model="text-embedding-v1")
db = FAISS.from_documents(texts, embeddings)
# 检索 top-5 结果
retriever = db.as_retriever(search_kwargs={"k": 5})
python
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
# Prompt模板
template = """请根据对话历史和下面提供的信息回答上面用户提出的问题:
{query}
"""
prompt = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate.from_template(template),
]
)
python
def retrieval(state: MessagesState):
user_query = ""
if len(state["messages"]) >= 1:
# 获取最后一轮用户输入
user_query = state["messages"][-1]
else:
return {"messages": []}
# 检索
docs = retriever.invoke(str(user_query))
# 填 prompt 模板
messages = prompt.invoke("\n".join([doc.page_content for doc in docs])).messages
return {"messages": messages}
python
graph_builder = StateGraph(MessagesState)
graph_builder.add_node("retrieval", retrieval)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "retrieval")
graph_builder.add_edge("retrieval","chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
python
from IPython.display import Image, display
# 可视化展示这个工作流
try:
display(Image(data=graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(e)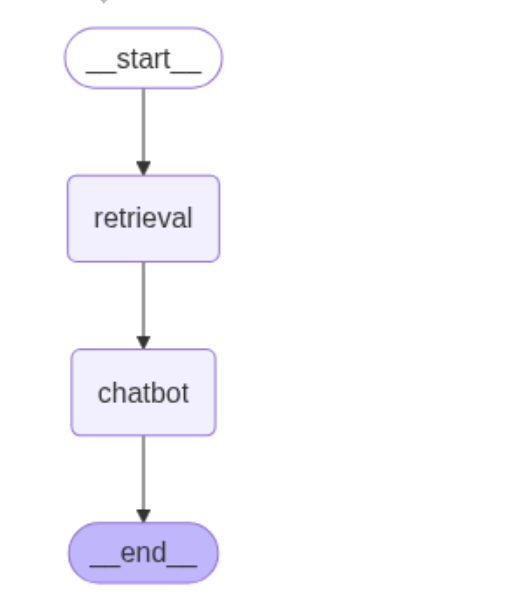
7. 加入分支:若找不到答案则转人工处理
python
from langchain.schema import HumanMessage
from typing import Literal
from langgraph.types import interrupt, Command
# 校验
def verify(state: MessagesState)-> Literal["chatbot","ask_human"]:
message = HumanMessage("请根据对话历史和上面提供的信息判断,已知的信息是否能够回答用户的问题。直接输出你的判断'Y'或'N'")
ret = llm.invoke(state["messages"]+[message])
if 'Y' in ret.content:
return "chatbot"
else:
return "ask_human"
# 人工处理
def ask_human(state: MessagesState):
user_query = state["messages"][-2].content
human_response = interrupt(
{
"question": user_query
}
)
# Update the state with the human's input or route the graph based on the input.
return {
"messages": [AIMessage(human_response)]
}
python
from langgraph.checkpoint.memory import MemorySaver
# 用于持久化存储 state (这里以内存模拟)
# 生产中可以使用 Redis 等高性能缓存中间件
memory = MemorySaver()
graph_builder = StateGraph(MessagesState)
graph_builder.add_node("retrieval", retrieval)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_node("ask_human", ask_human)
graph_builder.add_edge(START, "retrieval")
graph_builder.add_conditional_edges("retrieval", verify)
graph_builder.add_edge("ask_human", END)
graph_builder.add_edge("chatbot", END)
# 中途会被转人工打断,所以需要 checkpointer 存储状态
graph = graph_builder.compile(checkpointer=memory)
python
from langchain.schema import AIMessage
# 当使用 checkpointer 时,需要配置读取 state 的 thread_id
# 可以类比 OpenAI Assistants API 理解,或者想象 Redis 中的 key
thread_config = {"configurable": {"thread_id": "100"}}
def stream_graph_updates(user_input: str):
# 向 graph 传入一条消息(触发状态更新 add_messages)
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
thread_config
):
for value in event.values():
if isinstance(value, tuple):
return value[0].value["question"]
elif "messages" in value and isinstance(value["messages"][-1], AIMessage):
print("Assistant:", value["messages"][-1].content)
return None
return None
def resume_graph_updates(human_input: str):
for event in graph.stream(
Command(resume=human_input), thread_config, stream_mode="updates"
):
for value in event.values():
if "messages" in value and isinstance(value["messages"][-1], AIMessage):
print("Assistant:", value["messages"][-1].content)
def run():
# 执行这个工作流
while True:
user_input = input("User: ")
if user_input.strip() == "":
break
question = stream_graph_updates(user_input)
if question:
human_answer = input("Ask Human: "+question+"\nHuman: ")
resume_graph_updates(human_answer)
python
run()User: deepseek v3 有多少参数?
Assistant: DeepSeek-V3 是一个具有 671 亿参数的大型 Mixture-of-Experts (MoE) 模型,其中每个 token 激活 37 亿参数。
User: Qwen3 有多少参数?
Ask Human: Qwen3 有多少参数?
Human: 800B
Assistant: 800B
User:
python
from IPython.display import Image, display
# 可视化展示这个工作流
try:
display(Image(data=graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(e)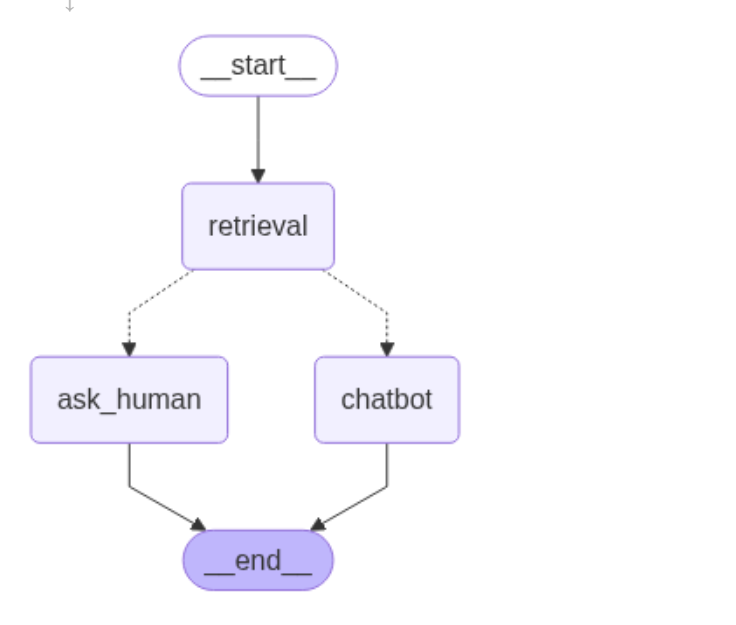
LangGraph 还支持:
- 工具调用
- 并行处理
- 状态持久化
- 对话历史管理
- 历史动作回放(用于调试与测试)
- 子图管理
- 多智能体协作
- MCP
- ...
更多关于 LangGraph 的 HowTo,参考官方文档:https://langchain-ai.github.io/langgraph/how-tos
python
break
question = stream_graph_updates(user_input)
if question:
human_answer = input("Ask Human: "+question+"\nHuman: ")
resume_graph_updates(human_answer)
```python
run()
User: deepseek v3 有多少参数?
Assistant: DeepSeek-V3 是一个具有 671 亿参数的大型 Mixture-of-Experts (MoE) 模型,其中每个 token 激活 37 亿参数。
User: Qwen3 有多少参数?
Ask Human: Qwen3 有多少参数?
Human: 800B
Assistant: 800B
User:
python
from IPython.display import Image, display
# 可视化展示这个工作流
try:
display(Image(data=graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(e)外链图片转存中...(img-BX0xJaWW-1775984976015)
LangGraph 还支持:
- 工具调用
- 并行处理
- 状态持久化
- 对话历史管理
- 历史动作回放(用于调试与测试)
- 子图管理
- 多智能体协作
- MCP
- ...
更多关于 LangGraph 的 HowTo,参考官方文档:https://langchain-ai.github.io/langgraph/how-tos
python