
在开篇中,我们用 3 分钟跑通了第一个手写数字识别网络。接下来,我们将从头开始深入 PyTorch 的每一个核心组件。第一步,就是 张量(Tensor) ------它是 PyTorch 的基石,相当于 NumPy 的 ndarray 嫁接了 GPU 加速和自动求导。
很多新手一上来就写网络,却发现数据处理错误、形状不匹配、device 不对。根本原因就是张量操作不熟。这篇文章会用大量实例,带你系统掌握张量的创建、变形、索引、运算和广播机制,并对比 NumPy 的异同,让你彻底告别形状错误。
一、张量是什么?
张量就是多维数组。你完全可以把它理解成 可以跑在 GPU 上、且支持自动求导的 NumPy 数组。
在 PyTorch 里,几乎所有的数据和模型参数都是张量。一个标量是 0 维张量,一个向量是 1 维张量,矩阵是 2 维,图像数据通常是 4 维 (batch, channel, height, width)。

二、创建张量的 10 种常用方法

引入库:
python
import torch
import numpy as np2.1 从数据直接创建
python
# 从列表创建
a = torch.tensor([1, 2, 3])
b = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
print(a, a.dtype) # torch.int64
print(b, b.dtype) # torch.float322.2 从 NumPy 互相转换
python
y([1, 2, 3]) t = torch.from_numpy(arr) # numpy -> tensor,共享内存 t2 = torch.tensor(arr) # 会复制一份 # tensor 转 numpy n = t.numpy() # 同样共享内存注意 :
from_numpy创建出来的张量和原数组共享内存,修改其中一个,另一个也会变。torch.tensor()则是深拷贝。
2.3 创建特殊张量
python
zeros = torch.zeros(2, 3) # 全 0
ones = torch.ones(2, 3) # 全 1
eye = torch.eye(3) # 单位矩阵
rand = torch.rand(2, 3) # [0,1) 均匀分布
randn = torch.randn(2, 3) # 标准正态分布 N(0,1)2.4 按范围创建
python
arange = torch.arange(0, 10, step=2) # tensor([0,2,4,6,8])
linspace = torch.linspace(0, 1, steps=5) # tensor([0.00, 0.25, 0.50, 0.75, 1.00])2.5 创建同形状张量
python
x = torch.ones(2, 3)
y = torch.zeros_like(x) # 形状同 x,全 0
z = torch.randn_like(x) # 形状同 x,正态分布2.6 指定数据类型和设备
python
f = torch.tensor([1, 2], dtype=torch.float32, device='cuda')三、张量的基本属性
python
t = torch.randn(2, 3, 4)
print(t.shape) # torch.Size([2, 3, 4])
print(t.size()) # 功能同上
print(t.dtype) # torch.float32
print(t.device) # cpu 或 cuda:0
print(t.ndim) # 维度数 3
print(t.numel()) # 元素总数 2*3*4=24四、张量索引与切片:和 NumPy 一模一样
索引方式完全遵循 Python / NumPy 的规范。
python
t = torch.arange(12).reshape(3, 4)
print(t)
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# 取第 1 行
print(t[0]) # tensor([0, 1, 2, 3])
# 取第 1 列
print(t[:, 0]) # tensor([0, 4, 8])
# 区域切片
print(t[0:2, 1:3]) # 前 2 行,第 1-2 列
# 步长步取
print(t[::2, ::2]) # 每隔一行一列取一次高级索引(与 NumPy 一样的 fancy indexing):
python
# 整数数组索引
idx = [0, 2]
print(t[idx]) # 取第 0 和第 2 行
# 布尔索引
mask = t > 5
print(t[mask]) # tensor([6, 7, 8, 9, 10, 11])五、张量变形:reshape, view, transpose, permute
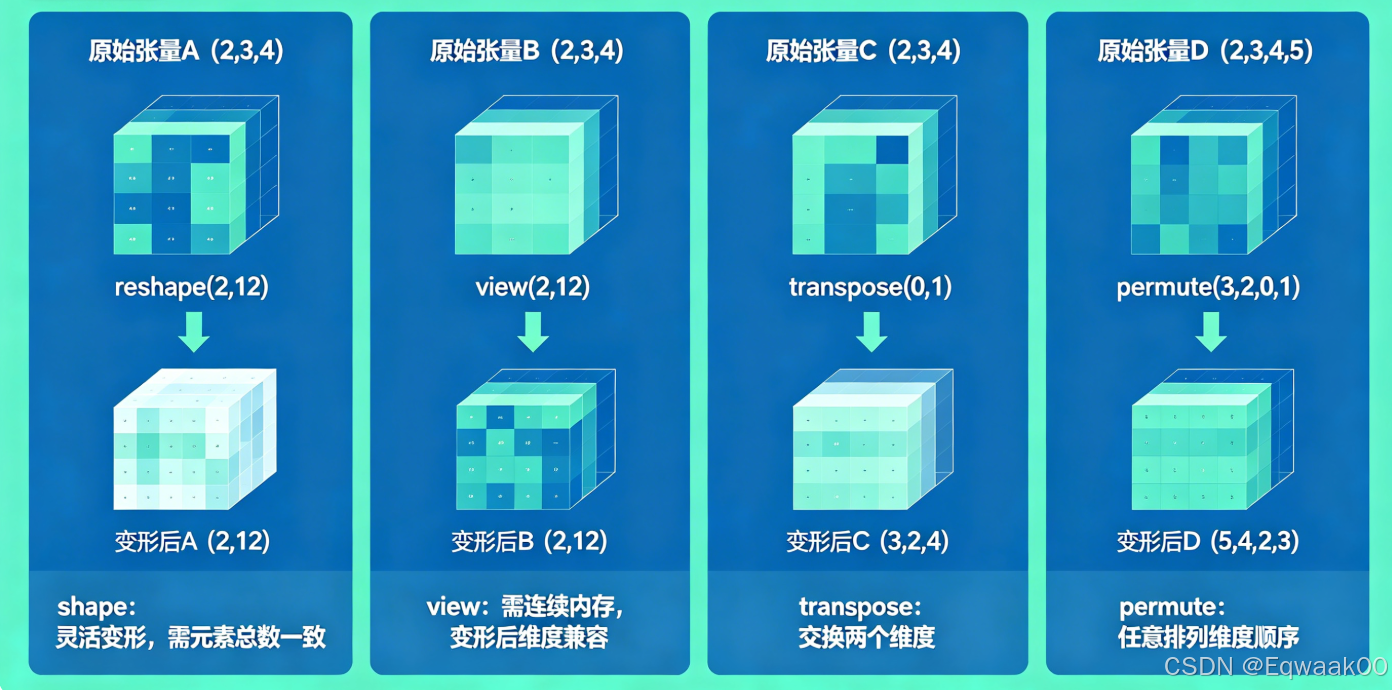
这是实际写代码时出错最多的地方,必须记牢。
5.1 reshape vs view
python
x = torch.arange(12)
a = x.reshape(3, 4) # 安全,但可能复制
b = x.view(3, 4) # 必须内存连续,否则报错
c = x.contiguous().view(3, 4) # 保证内存连续后再 view规则 :view 只在张量内存连续时可用,通常 reshape 更保险;但 reshape 在非连续时会复制一份,不共享数据。
5.2 增加/移除维度
python
x = torch.tensor([1, 2, 3]) # shape (3,)
print(x.unsqueeze(0)) # shape (1,3) 在第 0 维前加一维
print(x.unsqueeze(1)) # shape (3,1) 在第 1 维后加一维
y = torch.randn(1, 3, 1, 4)
print(y.squeeze()) # 移除所有大小为 1 的维度,变成 (3,4)
print(y.squeeze(0)) # 只移除第 0 维,若它等于 15.3 transpose 和 permute
python
t = torch.randn(2, 3, 4)
# 交换两维
t1 = t.transpose(0, 2) # shape (4,3,2)
# 多重转置用 permute
t2 = t.permute(2, 1, 0) # shape (4,3,2)
transpose一次只能交换两个维度,permute可以一次性对全部维度重新排列。
5.4 扩维广播常用 expand 与 repeat
python
a = torch.tensor([[1], [2], [3]]) # shape (3,1)
b = a.expand(3, 4) # 广播成 (3,4),不复制数据
c = a.repeat(1, 4) # 实际复制数据成 (3,4)expand 只在需要时扩展,不分配新内存;repeat 是真正复制。
六、张量的数学运算
6.1 基本运算
python
a = torch.tensor([1.0, 2.0])
b = torch.tensor([3.0, 4.0])
print(a + b) # 按元素加
print(a * b) # 按元素乘(不是矩阵乘法)
print(a @ b) # 点积
print(a.pow(2)) # 平方
print(a.sqrt()) # 开方6.2 矩阵乘法
python
x = torch.randn(2, 3)
y = torch.randn(3, 4)
result = torch.mm(x, y) # 矩阵乘,结果 (2,4)
result = x @ y # 等价写法
# 对于批量矩阵乘用 torch.bmm 或 torch.matmul6.3 聚合操作
python
t = torch.randn(3, 4)
print(t.sum()) # 所有元素和
print(t.sum(dim=0)) # 按行方向求和(压缩第 0 维),形状 (4,)
print(t.sum(dim=1, keepdim=True)) # 按列方向求和并保持维度,形状 (3,1)
print(t.mean(), t.max(), t.min())
print(t.argmax(dim=1)) # 每行最大值的索引
dim参数必须理解清楚 :sum(dim=0)就是把第 0 维压缩掉,你可以想象成"在这个方向上拍扁"。
七、广播机制 (Broadcasting)
广播是 PyTorch 里最重要的隐式操作之一,它允许形状不同的张量在运算时自动扩展。
规则:从最后一个维度向前对比,满足以下条件之一即可广播:
-
两个维度大小相等
-
其中一个维度是 1
-
其中一个维度不存在
-

例子:
python
a = torch.randn(3, 1) # shape (3,1)
b = torch.randn(1, 4) # shape (1,4)
c = a + b # 广播成 (3,4)常见错误形如 (3,4) + (3,) 会触发广播吗?答案是不会直接报错,因为 (3,) 可以被广播成 (1,3) 再和 (3,4) 尝试,但最后一个维度 4 vs 3 不匹配,会报错 。要显式调成 (3,1) 或 (1,4)。
八、张量在 CPU 与 GPU 间移动
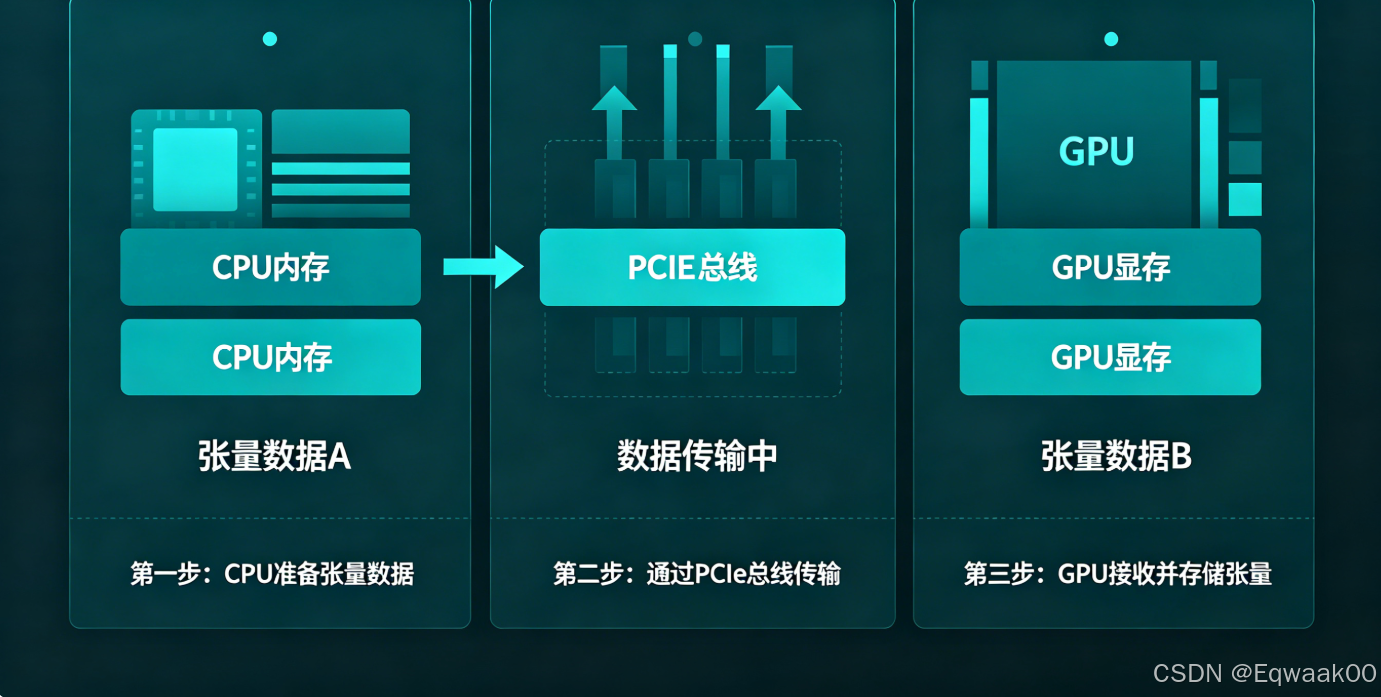
python
x = torch.randn(3, 3)
if torch.cuda.is_available():
device = torch.device("cuda")
x_gpu = x.to(device) # 搬到 GPU
# 或者 x.cuda()
x_cpu = x_gpu.cpu() # 搬回 CPU注意:模型和数据必须在同一个设备上,否则会报 RuntimeError。
九、张量与自动求导的初遇
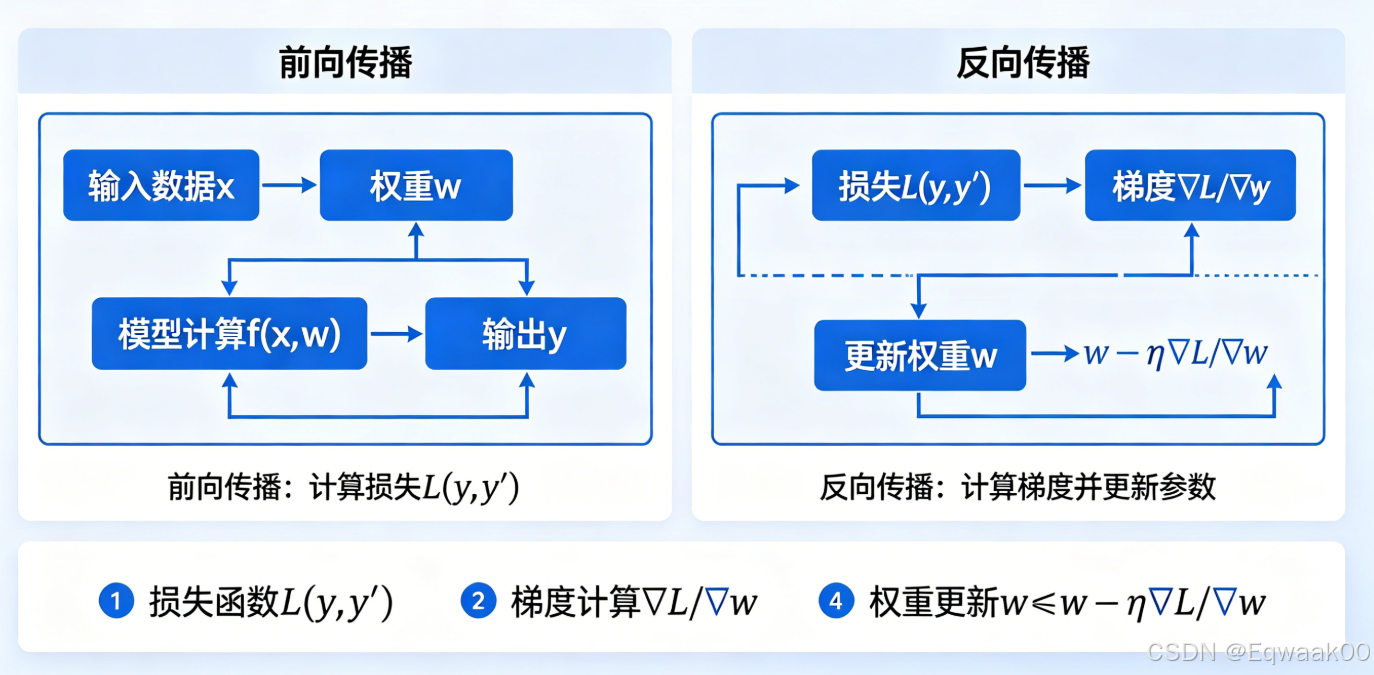
张量通过 requires_grad=True 开启梯度追踪:
python
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x.pow(2).sum()
y.backward()
print(x.grad) # tensor([2., 4., 6.])每当你对一个标量调用 backward(),所有路径上的梯度都会自动计算并累加到张量的 .grad 属性中。
这也是后面要详细讲解的 autograd 机制,现在你只需要知道张量自带这个超级能力。
十、本讲总结与练习
今天我们全面拆解了张量的创建、索引、变形、运算和广播。掌握这些操作,你就拿到了玩转 PyTorch 的钥匙。
试着做几个练习:
-
用
torch.randn创建一个形状为(4, 5)的张量,提取出第 1、3 行和第 2、4 列构成的子矩阵。 -
实现一个形状为
(3, 1)的张量与形状为(4,)的向量相加,结果形状是什么? -
将上面创建的张量搬到 GPU 并验证 device。
如果这篇文章对你有帮助,请你:
-
点个赞 和收藏,方便后面查阅
-
关注我,第一时间收到系列更新
-
在评论区打卡:你平时在张量上最常犯的错误是什么?一起避坑!
下篇见,我们继续拆解 PyTorch 的核心。