发表时间:2026.4.1
论文地址:https://arxiv.org/html/2604.01193v1
测试代码:https://github.com/apple/ml-ssd/tree/main
研究背景与核心问题
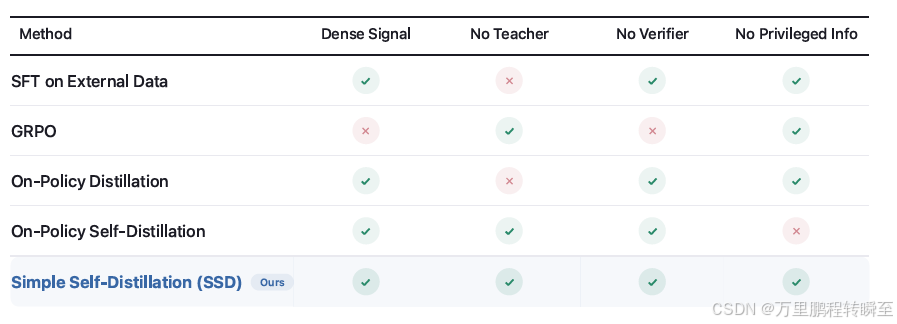
论文研究了一个基本问题:大型语言模型能否仅使用自身的原始输出来改进代码生成能力,而不需要验证器、教师模型或强化学习?

结论与意义
主要贡献
- 方法创新:证明了仅使用模型自身未验证输出就能显著改进代码生成
- 机制发现:识别了精度-探索冲突,并展示了如何通过分布重塑来解决
- 理论支持:提供了完整的理论分析和实证验证
核心创新点
- 无需外部监督:仅使用模型自身的原始输出
- 标准交叉熵训练:不需要复杂的强化学习或奖励机制
- 温度和截断的巧妙组合:通过训练时和评估时温度的组合实现性能提升
实际意义
- 简化训练流程:无需复杂的验证或强化学习基础设施
- 通用性:在5个不同模型上均有效,跨越两个模型系列、三个规模和两种推理风格
- 可扩展性:方法简单,易于实现和部署
未来方向
- 探索在其他任务领域(如数学推理、自然语言理解)的应用
- 研究更复杂的温度和截断调度策略
- 分析不同模型架构对SSD效果的敏感性
核心方法:简单自蒸馏(SSD)
方法流程
1. 数据合成
- 使用训练时温度 Ttrain和截断配置 ρtrain 从冻结的预训练模型 pθ 采样候选解决方案
- 关键特性:不进行任何形式的处理(无执行、无测试用例、无正确性过滤)
2. 训练
- 使用标准监督微调(SFT)在合成数据集 DSSDDSSD 上进行训练;即仅对模型输出值进行监督;
- 损失函数:
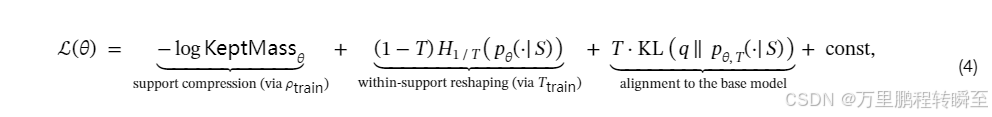
温度组合效应
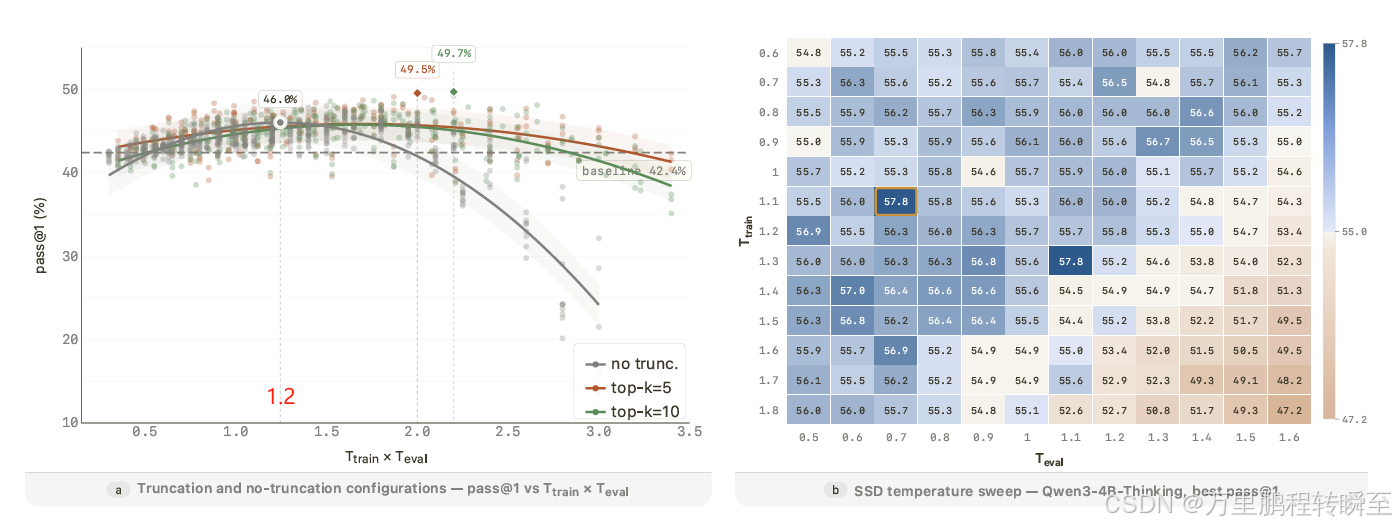
论文发现,训练时温度 Ttrain和评估时温度 Teval通过有效温度 Teff=Ttrain⋅Teval 组合:
- 无截断情况:性能主要由 Teff决定,值为1.2时效果最好
- 有截断情况:截断提供了额外的性能提升通道
理论意义
这个分解表明,简单自蒸馏不仅仅是模仿,而是通过三个明确的机制来改进模型:
- 支持压缩:改变分布的支持集(哪些token被考虑)
- 支持内重塑:改变支持集内的概率分配
- 对齐约束:确保改变是有益的而不是有害的
3. 推理
- 使用评估时解码配置 (Teval,ρeval)(Teval,ρeval) 部署微调后的模型
实验结果
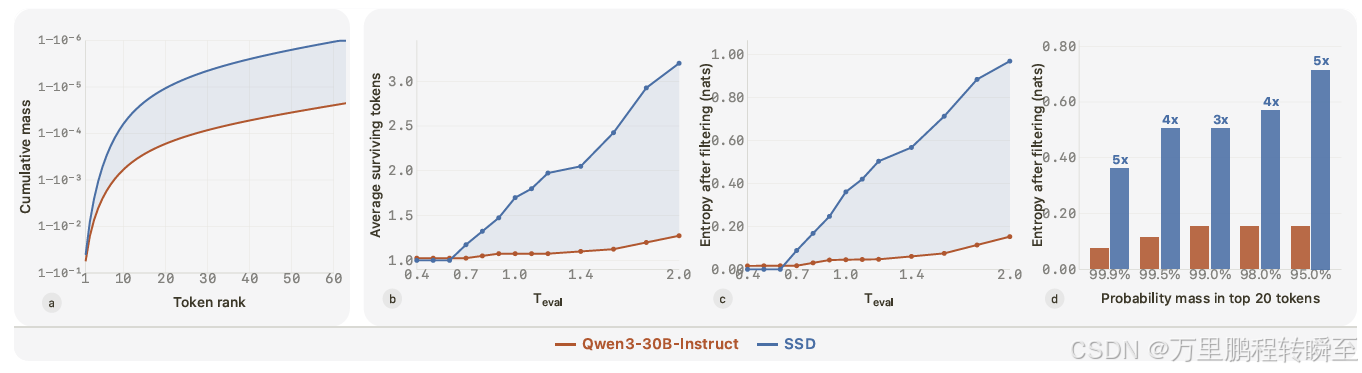
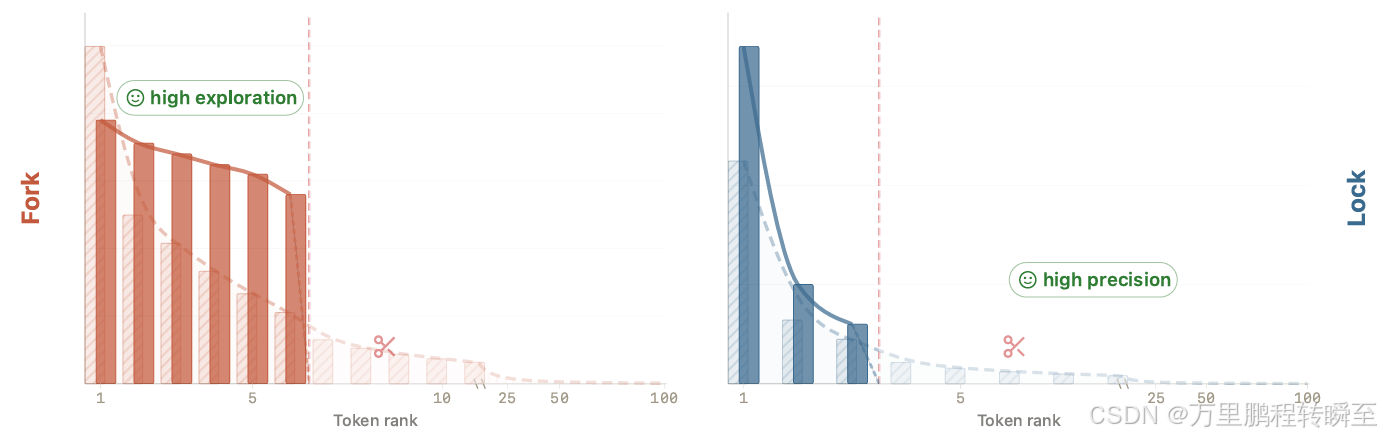
来自真实模型的实验证据表明:SSD 既能压缩干扰性尾部概率,又能让评估温度 Teval 在概率头部区域发挥更有效的作用。
- 琥珀色:基础模型 Qwen3-30B-Instruct
- 蓝色:经过 SSD 优化后的模型
(a) 当词元按模型概率排序时,SSD 模型的累积概率上升更快,说明其概率头部更干净、弥散的尾部更弱。(b) 随着 Teval 升高,经过截断后,SSD 模型保留的有效词元多于基础模型。(c) 截断后的分布熵在 SSD 模型上提升幅度显著更大。(d) 即便两个模型在前 20 个词元上的累积概率相近,SSD 截断后的熵依然更高,为推理阶段的探索提供了更多可行候选。
综上,基础模型在解码时会携带更多尾部无效概率;而 SSD 为温度调节留出了更有效的空间,使概率头部的分布更多样化。
主要性能提升
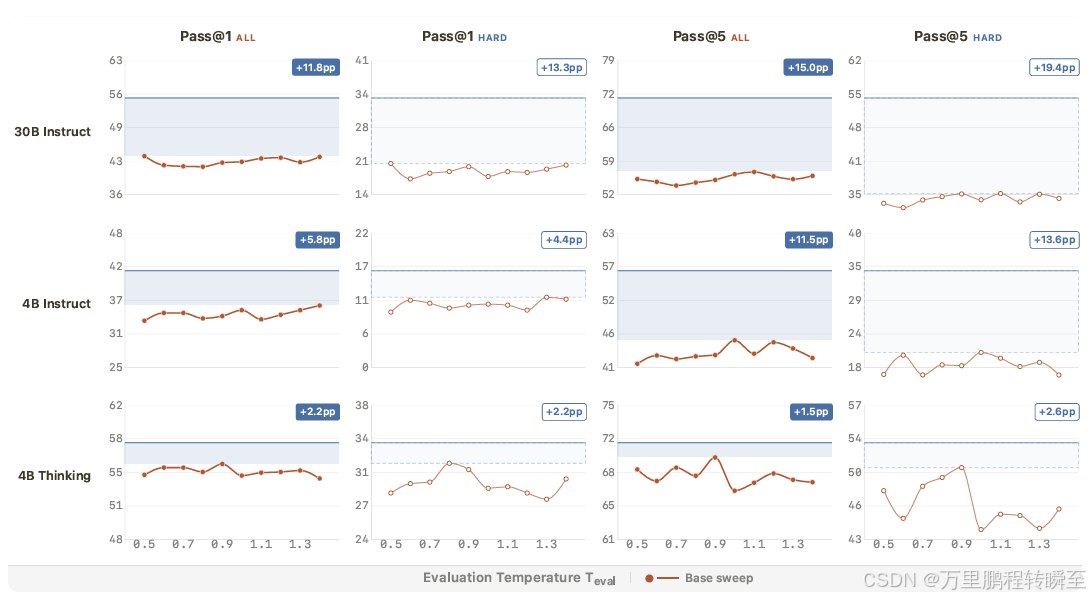
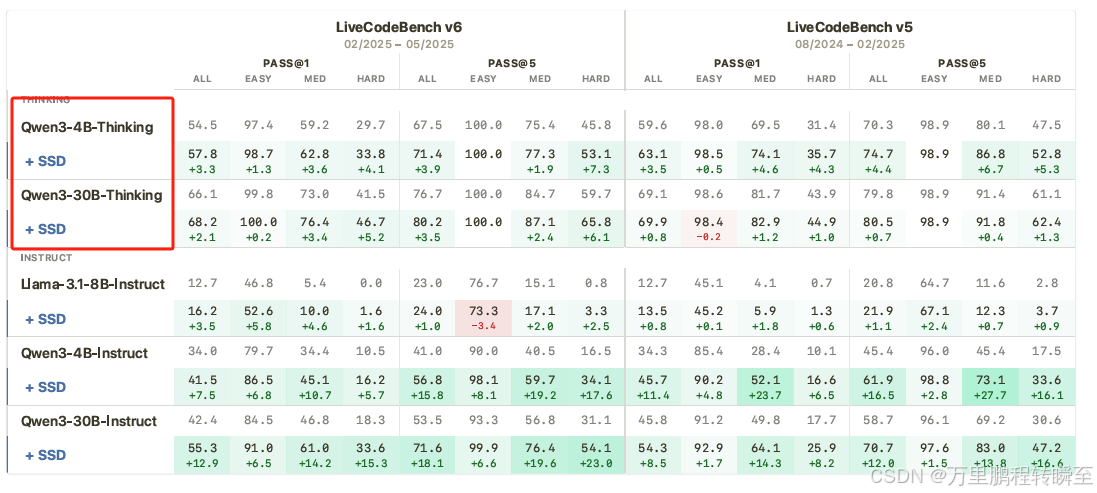
在LiveCodeBench v6基准测试上的表现:
Qwen3-30B-Instruct:
- Pass@1:从42.4%提升至55.3%(+12.9个百分点,+30.4%相对提升)
- 硬题提升最为显著:+15.3个百分点(pass@1),+23.0个百分点(pass@5)
关键发现
1. 难度依赖性
- 简单问题:+6.5个百分点
- 中等问题:+14.2个百分点
- 困难问题:+15.3个百分点
- 结论 :改进主要集中在更困难的问题上;对于thinking模型提升没有instruct模型明显
2. 多样性保持
- Pass@5的提升通常大于Pass@1的提升
- 表明SSD不仅提高了准确性,还保持了生成多样性
- 例如:Qwen3-30B-Instruct在硬题上,pass@5提升+23.0个百分点,而pass@1提升+15.3个百分点
3. 解码策略无法匹配
- 即使对基础模型进行广泛的解码参数调优(温度、topP、topK等解码策略),也无法达到SSD的性能
- 最佳调优的基础模型与SSD相比仍有显著差距
- 表明训练改变了模型本身,而不仅仅是解码策略
理论分析与机制解释
精度-探索冲突假说
论文提出并验证了一个核心假说:代码生成中存在精度-探索冲突
锁(Lock)位置:
- 语法和上下文几乎没有歧义(语义定义是通用知识)
- 需要高精度:承诺主导标记并抑制尾部
- 降低温度有助于锁,但会限制探索
叉(Fork)位置:
- 分布在多个可行的延续之间扩散(变量定义等基本功能实现)
- 需要探索:在可行的替代方案之间分散质量
- 升高温度有助于叉,但会破坏锁
冲突:任何固定的解码配置都必须在这两种需求之间妥协
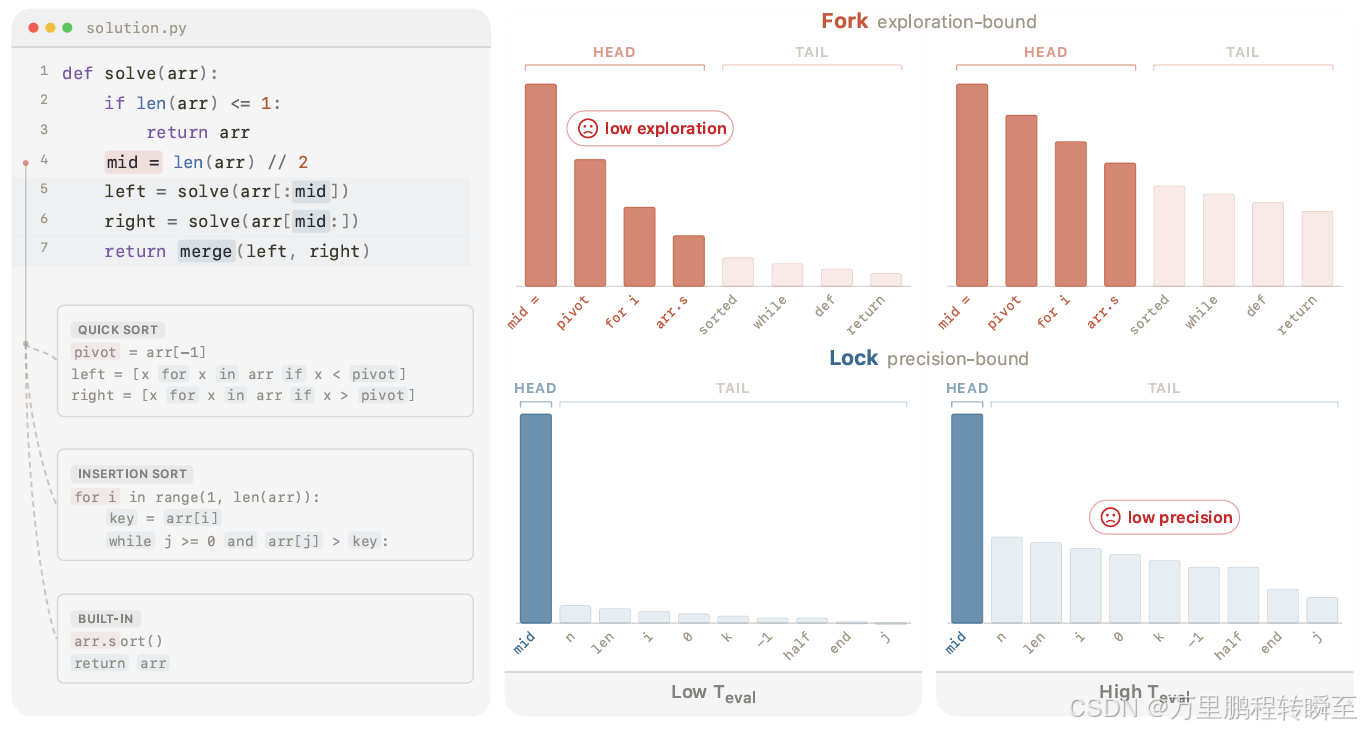
单一的评估温度无法同时满足分叉位置的探索需求 与锁定位的精度需求 。左侧:一个排序算法示例,其中算法选择词元 为分叉位置 (锈橙色),后续对 mid 的使用则为锁定位 (蓝色);灰色虚线路径代表在该分叉点可选择的其他有效算法。右侧:在低 / 高评估温度 下,上述两类上下文对应的词元概率分布,头部与尾部概率均明确标出。低评估温度能保证锁定位精准,但会导致分叉点的有效头部分布坍塌(探索能力不足);高评估温度能恢复分叉点的探索能力,却会让锁定位的干扰尾部概率重新激活(精度下降)。
SSD如何解决冲突
1. 支持压缩(Support Compression)
- 训练时截断移除了低概率尾部
- 在锁位置,这使得主导标记更难被取代
- 降低整体熵
2. 支持内重塑(Within-Support Reshaping)
- 温度调整重新分配了保留支持内的质量
- 在叉位置,保留多个可行的延续,但使它们更加均匀
- 保持条件头部熵用于探索
3. 温度组合效应
- 训练时和评估时温度通过有效温度 Teff=Ttrain⋅Teval组合
- 在无截断情况下,性能主要由 Teff决定
- 截断提供了额外的性能提升通道

理论分解
SSD 会将分叉状态塑造成平缓的平台 ,将锁定状态塑造成尖锐的峰值 。图中词元按概率从高到低排序。阴影柱形与虚线曲线代表基础模型 ;实心柱形与实线曲线代表SSD 优化后的模型;红色虚线截断线表示 SSD 过程中保留的概率支撑集。
(a) 类分叉状态 :弥散的尾部概率被裁剪,但多个靠前的合理续存 token 被保留,且权重变得更均匀,在有效分支上形成宽阔平缓的平台分布。
(b) 类锁定状态 :同样的截断规则会更激进地剔除尾部概率,并将概率高度集中在主导 token 上,形成更尖锐的峰值分布。
论文提供了详细的理论分析,将SSD损失分解为三个关键项:
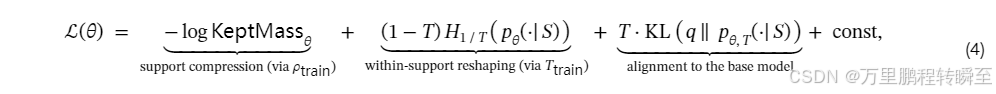
第一项:支持压缩(Support Compression)
公式: −logKeptMassθ
含义:
- KeptMassθ表示优化中的模型分配给保留集合 SS 的概率质量
- S是在训练时温度 Ttrain 和截断 ρtrain下,从基础模型采样时存活下来的token集合
作用机制:
- 移除尾部扩散质量:通过截断操作,低概率的尾部token被移除
- 集中概率质量:迫使模型将概率质量集中在更小的可行token集合上
- 降低整体熵:使分布更加尖锐,减少不确定性
实际效果:
- 在"锁"(Lock)位置(语法和上下文几乎没有歧义的地方),这使得主导标记更难被取代
- 提高了生成的确定性和准确性
第二项:支持内重塑(Within-Support Reshaping)
公式: (1−T)H1/T(pθ(⋅∣S))
含义:
- H1/T(pθ(⋅∣S))是限制在集合 S上的Rényi熵,阶数为 1/T
- Ttrain是训练时温度
作用机制:
- 重新分配保留支持内的质量:在保留的token集合 S 内,重新调整概率分布
- 保持条件头部熵:在"叉"(Fork)位置(分布扩散在多个可行延续之间的地方),保留多个可行的延续
- 使分布更加均匀:在可行的替代方案之间分散质量,但使它们更加均匀
实际效果:
- 在需要探索的位置,保持了生成的多样性
- 平衡了精度和探索的需求
第三项:与基础模型对齐(Alignment to the Base Model)
公式: T⋅KL(q∥pθ,T(⋅∣S))
含义:
- KL(q∥pθ,T(⋅∣S))是KL散度,衡量分布 qq和模型的温度化分布 pθ,Tpθ,T 之间的差异
- q 是在集合 S 上重新归一化的分布
- pθ,T(⋅∣S) 是模型在温度 T 下限制在集合 S 上的分布
作用机制:
- 保持与基础模型的一致性:确保重塑后的分布不会偏离基础模型太远
- 正则化效应:防止过度拟合合成数据
- 知识保留:保留基础模型的有用知识和能力
实际效果:
- 防止训练过程中的性能退化
- 确保改进是建设性的,而不是破坏性的
三项的协同作用
解决精度-探索冲突
这个loss函数的设计巧妙地解决了代码生成中的核心问题:精度-探索冲突
问题描述:
- 锁位置:需要高精度,降低温度有助于锁定正确标记
- 叉位置:需要探索,升高温度有助于保持多个可行选项
- 冲突:任何固定的解码配置都必须在这两种需求之间妥协
解决方案:
- 支持压缩(第一项):通过截断移除尾部,解决锁位置的精度需求
- 支持内重塑(第二项):通过温度调整重新分配质量,解决叉位置的探索需求
- 对齐约束(第三项):确保整体改进不会偏离基础模型太远
温度组合效应
论文发现,训练时温度 Ttrain 和评估时温度 Teval通过有效温度 Teff=Ttrain⋅Teval 组合:
- 无截断情况:性能主要由 Teff 决定
- 有截断情况:截断提供了额外的性能提升通道
理论意义
这个分解表明,简单自蒸馏不仅仅是模仿,而是通过三个明确的机制来改进模型:
- 支持压缩:改变分布的支持集(哪些token被考虑)
- 支持内重塑:改变支持集内的概率分配
- 对齐约束:确保改变是有益的而不是有害的
压力测试:坏数据,好结果
论文进行了一项有趣的实验:使用 Ttrain=2.0且无截断的高温度训练
结果:
- 合成数据质量极差:约62%的输出不含可提取的代码
- 但训练后的模型仍显著改进:达到48.1% pass@1和64.0% pass@5
- 改进集中在困难问题上
意义:这表明性能提升主要来自分布重塑,而非训练数据的正确性
相关工作对比
与其他方法的区别: