导读
当前的视频理解模型有一个根本矛盾:推理和感知是脱节的。无论模型有多强,它所能"看到"的画面在推理开始前就已经固定------要么均匀采样丢失关键帧,要么启发式选帧无法在推理过程中调整策略。
LensWalk提出了一种主动观察的Agent框架,让LLM推理器在理解视频的过程中自己决定"看哪里、看多密、用什么工具看"。它配备三个粒度各异的观察工具和一套双记忆系统,在不微调任何模型的前提下,将o3在LVBench上的得分从57.1提升到68.6(+11.5),VideoMME Long从64.7提升到71.4(+6.7),而每次查询平均仅消耗290.3帧,是Deep Video Discovery的1/28。
论文信息
- 标题:LensWalk: Agentic Video Understanding by Planning How You See in Videos
- 作者:Keliang Li, Yansong Li, Hongze Shen, Mengdi Liu, Hong Chang, Shiguang Shan
- 机构:中国科学院计算技术研究所、中国科学院大学、湖南大学、鹏城实验室
- 发表:CVPR 2026
- 代码:未公布
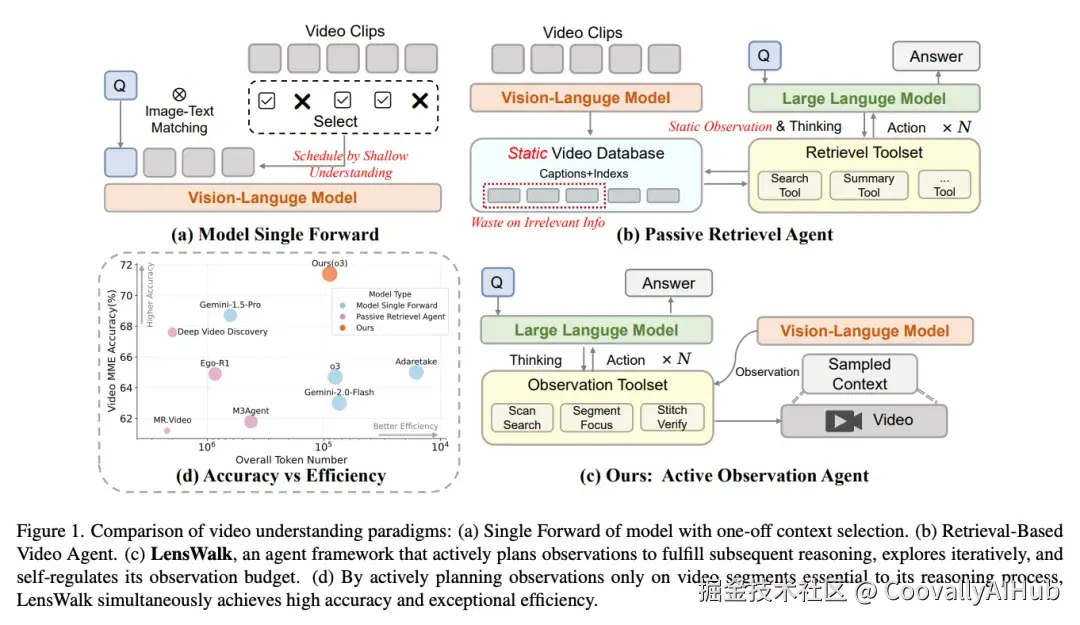
一、被动观看 vs 主动探索:视频理解的核心矛盾
视频理解任务面临一个结构性难题:视频内容在时间轴上高度冗余,但关键事件往往稀疏分布。现有方法大致分为三类,每一类都存在明显的感知局限。
第一类是单模型前向推理。将长视频均匀采样到固定数量的帧,一次性送入VLM(Vision-Language Model,视觉语言模型)。这种方式的问题在于,一小时的视频被压缩到几百帧后,一个持续几秒的关键动作很可能恰好落在采样间隙中,被完全遗漏。
第二类是检索式视频Agent 。先对整段视频做离线预处理------提取ASR(Automatic Speech Recognition,自动语音识别)转录、OCR文本、逐帧描述等------再让Agent从这些预处理结果中检索信息。这类方法虽然引入了多轮推理,但Agent操作的始终是静态的文本表示,而非视频的原始视觉内容。感知的粒度在预处理阶段就已经锁死,Agent无法在推理过程中重新选择观察策略。
第三类是启发式帧选择。用关键帧检测、token压缩等方法预先筛选帧。一旦选定,推理过程中即使发现假设有误,也无法回头重新采样。
这三类方法的共同问题是:推理和感知是单向的。模型先看,再想,看的过程不受想的过程指导。
LensWalk的核心主张是:观察应当像人类的注意力一样,被推理目标主动调度。人类理解一段视频时,会先快速浏览全局获取大致线索,发现可疑片段后切换到仔细观看,必要时还会回放多个片段进行对比验证。LensWalk将这种"从外围扫描到中心注视再到跨时刻整合"的认知过程,转化为Agent的工具调用循环。
图片来源于原论文
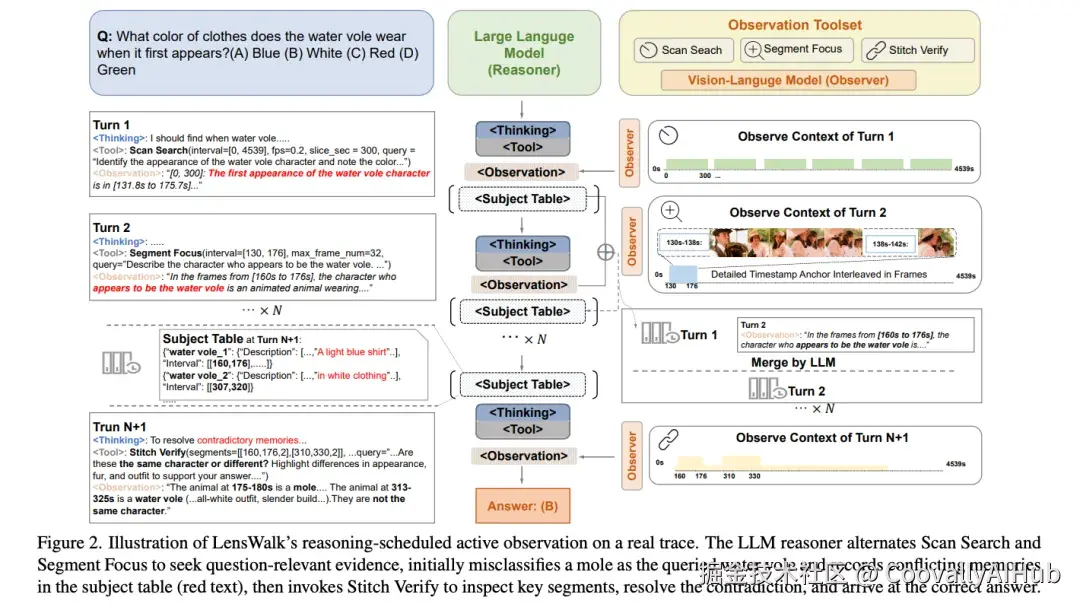
二、三个观察工具 + 双记忆系统
LensWalk由三个核心组件构成:一个基于LLM的Reasoner (推理器)、三个VLM驱动的观察工具 ,以及两个轻量级记忆模块 。整个系统运行在一个紧密的 reason-plan-observe循环中:每一轮,Reasoner分析当前累积的证据,决定下一步该用哪个工具、观察视频的哪个时间段、以什么密度采样,然后将观察结果写入记忆,进入下一轮推理。
三个观察工具
三个工具覆盖了从粗到细、从局部到跨段的完整观察粒度:
Scan Search(广域扫描) :用于在指定时间区间内进行高效的粗粒度搜索。它将目标区间分割为多个切片,每个切片内稀疏采样,逐切片查询VLM,快速定位可能包含关键信息的时间段。默认帧预算为180帧,采样率0.25 fps。这个工具的核心价值是"快速缩小搜索范围"。
Segment Focus(精细聚焦) :对单一连续时间段进行密集采样的深入检查。当Scan Search锁定了可疑区间后,Segment Focus以更高的采样密度(默认1 fps、32帧)对该区间进行精读,用于验证假设、提取具体属性、消除歧义。
Stitched Verify(跨段验证) :将来自多个不连续时间段的帧合并为一个batch送入VLM,用于跨时刻的因果推理和对比验证。它支持非对称采样------对动作密集的片段分配更高帧率,对过渡段分配更低帧率。默认帧预算128帧。
三个工具在设计上高度互补:Scan Search负责"发现线索",Segment Focus负责"确认事实",Stitched Verify负责"整合证据"。
双记忆系统
为了在多轮观察中保持一致性,LensWalk引入了两个记忆组件:
Timestamp Anchors(时间戳锚点) :在每次观察时,将精确的时间戳信息直接嵌入VLM的视觉上下文中,促使Observer将回答锚定到具体的时间引用(如"在01:15-01:40")。这使得Reasoner在后续轮次中能够精准定位此前观察到的证据来源,避免时间信息在多轮传递中丢失。
Subject Memory Table(主体记忆表) :在推理历史之外维护一个全局实体注册表,记录持久实体(人、物)及其属性和出现的时间区间。每轮观察后由LLM更新,采用"合并而非堆叠"的策略(最多保留15个主体)。它的双重作用是:提供规范化的实体标识消除重复辨识成本,同时作为结构化知识库指导后续的观察规划。
图片来源于原论文
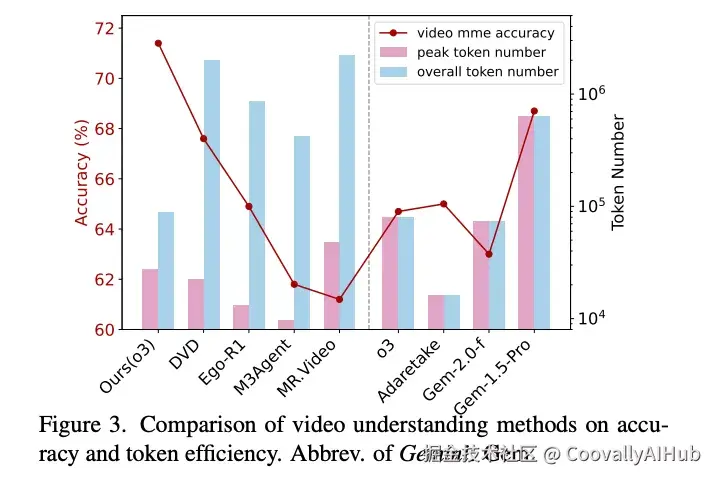
三、实验:帧数少28倍,性能反而更好
LensWalk在6个视频理解基准上进行了评测,覆盖长视频理解(LVBench、LongVideoBench、Video-MME)、视频推理(MMVU、Video-MMMU)和自我中心视频(EgoSchema)。框架采用即插即用的方式,可任意组合不同的Reasoner和Observer模型。
长视频基准上的主要结果
| 方法 | LVBench | VideoMME Long | LongVideoBench | EgoSchema |
|---|---|---|---|---|
| o3(直接推理) | 57.1 | 64.7 | 60.6 | 63.2 |
| GPT-5(直接推理) | 59.8 | 68.4 | 61.8 | 73.8 |
| Qwen2.5-VL-72B | 47.7 | 63.1 | 54.2 | 75.4 |
| MR.Video | 60.8 | 61.8 | 61.6 | 73.0 |
| Deep Video Discovery | 74.2 | 67.3 | 68.6 | 76.6 |
| LensWalk (o3) | 68.6 | 71.4 | 70.6 | 74.8 |
| LensWalk (GPT-5) | 66.9 | 69.2 | 68.8 | 74.6 |
几个关键对比:
- LensWalk将o3在LVBench上的得分从57.1提升到68.6(+11.5 ),在VideoMME Long上从64.7提升到71.4( +6.7)
- 在LongVideoBench和VideoMME Long上,LensWalk (o3)超过了所有对比方法,包括Deep Video Discovery
- Deep Video Discovery在LVBench上得分更高(74.2 vs 68.6),但代价是每次查询消耗8202帧和2180秒的离线预处理时间
视频推理基准上的结果
在推理密集型的MMVU和Video-MMMU上,LensWalk同样带来了提升:
- MMVU MC:o3单独78.9 → LensWalk (o3/GPT-4.1) 80.9(+2.0)
- Video-MMMU Overall:o3单独75.44 → LensWalk (o3) 78.33(+2.89)
效率对比:帧消耗与预处理时间
| 方法 | 准确率 (%) | 在线推理 (s) | 离线预处理 (s) | 平均帧数/query |
|---|---|---|---|---|
| o3(基线) | 57.1 | 38.9 | 0 | 256 |
| LensWalk | 68.6 | 190.35 | 0 | 290.3 |
| DVD | 74.2 | 153.3 | 2180.4 | 8202 |
| MR.Video | 65.5 | 326.2 | 4135.2 | 9227 |
| VideoAgent | 64.1 | 200.5 | 1131.3 | 4101 |
LensWalk的效率优势体现在两个维度:
- 零离线预处理:不需要提前对视频做任何处理,而DVD需要2180秒、MR.Video需要4135秒
- 帧消耗极低 :平均每次查询仅使用290.3帧,是DVD(8202帧)的1/28 ,是MR.Video(9227帧)的1/32
此外,LensWalk的帧消耗是自适应的。在短视频或简单问题上,Agent通常2.6-2.8步即可收敛;随着视频变长、问题变复杂,步数和帧使用量自动增加(VideoMME Long平均6.8步、387帧)。
Reasoner的重要性
不同Reasoner和Observer组合的实验揭示了一个重要发现:Reasoner的认知强度是决定性因素。
| Observer | Reasoner | VideoMME Long |
|---|---|---|
| GPT-4.1 | 无(基线) | 63.1 |
| GPT-4.1 | o3 | 70.0 (+6.9) |
| Qwen2.5-VL-7B | 无(基线) | 55.4 |
| Qwen2.5-VL-7B | o3 | 61.3 (+5.9) |
| Qwen2.5-VL-7B | Qwen3-235B-A22B | 59.7 (+4.3) |
强Reasoner(o3)能有效提升弱Observer的表现,但规划能力相对较弱的Reasoner(如Qwen3-235B-A22B,相比o3)配强Observer时效果有限,甚至出现负面结果(Qwen3-235B-A22B + Qwen2.5-VL-72B出现了-0.6%的下降)。这说明生成高质量观察计划的能力比视觉感知能力更关键。
四、消融实验:哪个工具贡献最大?
消融实验在VideoMME Long上进行,使用o3/GPT-4.1配置(完整系统得分70.0)。
观察工具消融
| 配置 | VideoMME Long | 变化 |
|---|---|---|
| 完整系统(三工具 + 双记忆) | 70.0 | --- |
| 移除 Scan Search | 65.4 | -4.6 |
| 移除 Stitched Verify | --- | -3.2 |
| 移除 Segment Focus | --- | -1.9 |
Scan Search的移除导致了最大幅度的下降(-4.6) ,说明广域扫描------在大范围时间区间内快速发现线索的能力------是整个框架的基石。没有它,Agent失去了"先看全局"的能力,后续的精细聚焦和跨段验证也就无从谈起。
Stitched Verify的移除导致3.2的下降,反映了跨段因果分析的重要性;Segment Focus的移除导致1.9的下降,对应细粒度事实提取的价值。三个工具呈现出论文所描述的"高度互补"特征。
记忆模块消融
| 配置 | VideoMME Long |
|---|---|
| 三工具 + 无记忆模块 | 66.8 |
| + Timestamp Anchors | 69.7 (+2.9) |
| + Subject Memory Table | 70.0 (+0.3) |
Timestamp Anchors带来了2.9个点的提升,表明精确的时间锚定对多轮推理的一致性至关重要。Subject Memory Table在此基础上额外贡献了0.3个点。
主动推理 vs 静态帧选择
论文还设计了一个关键的对照实验:将LensWalk在推理过程中访问过的帧收集起来,不经过多轮推理,直接一次性送入VLM做前向推理(称为"Extracted Frames"基线)。结果显示,这种方式仅获得+0.8到+2.6的微弱提升,远低于LensWalk的完整多轮推理带来的提升。这个实验说明,性能增益不来自于选到了更好的帧,而来自于主动的多轮推理调度本身。
图片来源于原论文
五、总结与思考
LensWalk将视频理解从"先看再想"转变为"边想边看"。通过让LLM推理器主动控制观察行为------决定在哪个时间段、以什么密度、用什么工具去获取视觉信息------它在不微调任何模型的前提下,在多个长视频基准上实现了5-11个点的提升,同时将帧消耗控制在检索式Agent的1/28到1/32。三个观察工具和双记忆系统的设计将人类认知中"外围扫描→中心注视→跨时刻整合"的过程形式化,使Agent在推理过程中自发涌现出渐进聚焦、策略反思、整合验证等行为模式。
在此基础上,有几点值得进一步关注。首先,LensWalk在LVBench上低于Deep Video Discovery(68.6 vs 74.2),DVD的全量预处理策略在特定场景下仍有优势,这意味着"主动观察"和"全量预处理"两种范式之间可能存在互补空间。其次,消融实验和Extracted Frames对照实验共同指向一个重要结论:在Agent式视频理解中,规划能力比感知能力更具杠杆效应------这对Agent框架的设计优先级有参考价值。最后,论文目前未公布代码,实际部署中多轮API调用的成本和延迟如何在不同场景下权衡,还有待进一步观察。