
信息熵是机器学习中最常见、也最容易"看懂却没想透"的一个公式:
H(X)=−∑i=1np(xi)log2p(xi) H(X) = - \sum_{i=1}^{n} p(x_i) \log_2 p(x_i) H(X)=−i=1∑np(xi)log2p(xi)
你可能已经很熟悉它:
- 分类问题里的损失函数
- 文本分析中的信息量衡量
- 异常检测中的"随机性刻画"
但有一个问题,很多人其实没有真正想清楚:**这个函数什么时候最小?什么时候最大?为什么一定是这样?**这篇文章,我们把这个问题彻底讲透。
需要注意的是,对数底数的选择不会影响信息熵的极值位置,仅改变单位表示。本文采用 log2\log_2log2,以符合信息论中的标准定义。
一、结论:熵的两个极值
信息熵有两个非常重要的极值状态,最小值对应完全确定的分布,最大值对应均匀分布(各事件等概率)。
1.1 最小值:完全确定(onehot分布)
当某一个事件的概率为 1,其余全为 0 时,信息熵最小,且等于 0
| 结果 | 概率 |
|---|---|
| A | 1 |
| B | 0 |
| C | 0 |
代入公式:
H(X)=−(1⋅log21+0+0)=0 H(X) = -(1 \cdot \log_2 1 + 0 + 0) = 0 H(X)=−(1⋅log21+0+0)=0
其中:
-
log21=0\log_2 1 = 0log21=0
-
对于0⋅log200 \cdot \log_2 00⋅log20,在极限意义下有:
limp→0+plog2p=0 \lim_{p \to 0^+} p \log_2 p = 0 p→0+limplog2p=0因此,该项被定义为0。
最终,可以得到:当系统完全确定时,其信息熵为 0。
1.2 最大值:完全随机(均匀分布)
当所有事件概率相等:
p(xi)=1n p(x_i) = \frac{1}{n} p(xi)=n1
代入公式:
H(X)=−∑i=1n1nlog21n=−log21n=log2n H(X) = -\sum_{i=1}^{n} \frac{1}{n} \log_2 \frac{1}{n} = -\log_2 \frac{1}{n} = \log_2 n H(X)=−i=1∑nn1log2n1=−log2n1=log2n
因此,当分布完全均匀时,信息熵最大,等于\\log_2 n 。
二、信息熵的函数性质:为什么最小在边界、最大在均匀分布?
为了分析信息熵的极值位置,我们可以将其拆解为单变量函数的形式:
H(X)=∑f(pi),f(p)=−plog2p H(X) = \sum f(p_i), \quad f(p) = -p \log_2 p H(X)=∑f(pi),f(p)=−plog2p
也就是说,信息熵可以看作是函数 f(p)f(p)f(p) 在各个概率上的加权求和。
2.1 单个函数的形状
函数 f(p)=−plog2pf(p) = -p \log_2 pf(p)=−plog2p具有如下性质:
-
当p→0+p \to 0^+p→0+ 时,f(p)→0f(p) \to 0f(p)→0(在极限意义下定义为 0)
-
当p=1p = 1p=1时,f(p)=0f(p) = 0f(p)=0
-
在区间中间取得最大值,且最大值出现在 p = \\frac{1}{e}
通过对函数 f(p)=−plog2pf(p) = -p \log_2 pf(p)=−plog2p 求导并令导数为 0,可以得到其极值点满足 lnp=−1\ln p = -1lnp=−1,从而解得 p=1ep = \frac{1}{e}p=e1。结合二阶导数小于 0,可知该点为函数的最大值点。
- 换底:log2p=lnpln2\log_2 p = \frac{\ln p}{\ln 2}log2p=ln2lnp
- f§ = -p \\cdot \\frac{\\ln p}{\\ln 2} = -\\frac{1}{\\ln 2}\\cdot p \\ln p
- 求导:f′(p)=−1ln2(lnp+1)=0⇒lnp=−1f'(p) = -\frac{1}{\ln 2}(\ln p + 1) = 0 \Rightarrow \ln p = -1f′(p)=−ln21(lnp+1)=0⇒lnp=−1,解得p=1ep = \frac{1}{e}p=e1
因此,该函数的图像呈现为一个"倒 U 型"。这意味着,单个概率项对不确定性的贡献,在"中等概率"时最大,在"边界概率"时最小。
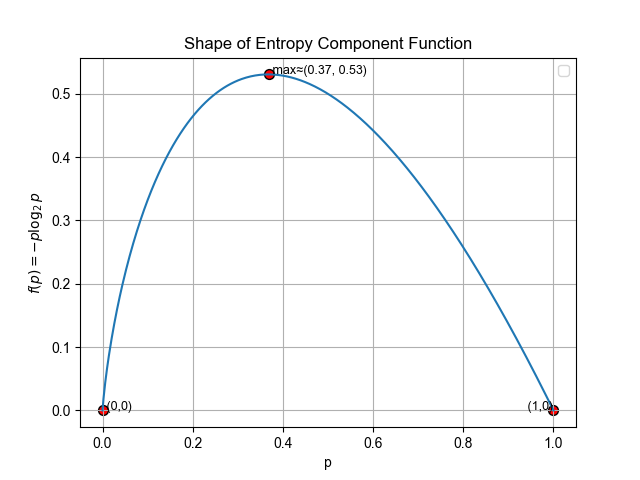
需要特别注意的是,f(p)f(p)f(p)最大值并不在p=0.5p = 0.5p=0.5。这是因为−plog2p-p \log_2 p−plog2p不是对称函数,而是"概率ppp与信息量log2p\log_2 plog2p的乘积权衡"。
当ppp增大时,log2p\log_2 plog2p 增加趋于 0(贡献下降), 而ppp本身增大权重上升。因此,最终平衡点出现在p=1ep = \frac{1}{e}p=e1,而不是 0.5。
2.2 二分类熵HHH与单变量函数f(p)f(p)f(p)
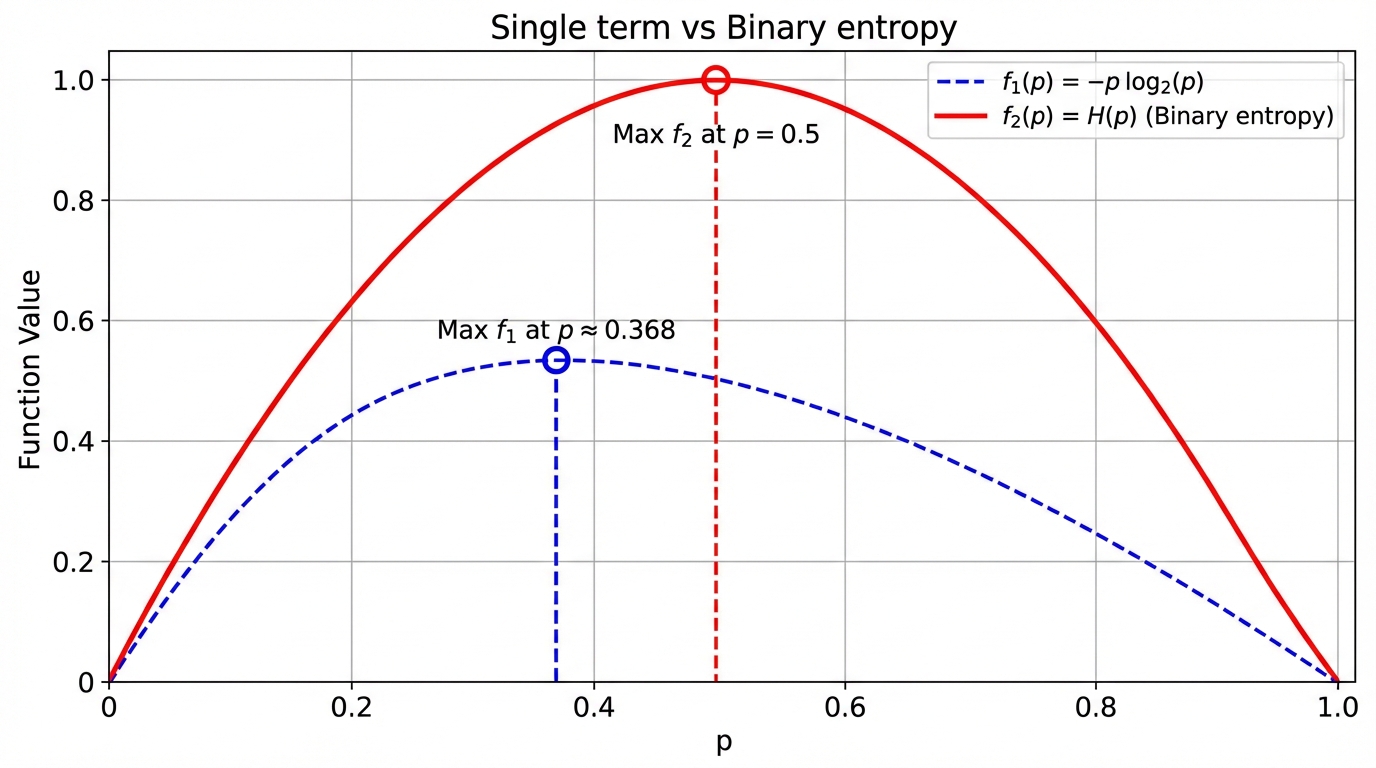
-
对比可以发现,一个非常重要的区别:
- 单项函数f(p)=−plog2pf(p) = -p \log_2 pf(p)=−plog2p的最大值出现在p=1/ep = 1/ep=1/e
- 而二分类熵H§ = -p \\log_2 p - (1-p) \\log_2(1-p) 的最大值出现在的最大值出现在的最大值出现在p = 0.5
-
这种差异的本质原因在于结构不同:
- f(p)f(p)f(p)只描述"单个事件的贡献",是不对称的
- H(p)H(p)H(p) 同时考虑两个互补事件,因此整体呈现对称结构
因此,0.5 对应的是"整体系统最均衡状态",而对应的是"整体系统最均衡状态",而对应的是"整体系统最均衡状态",而 1/e 对应的是"单个信息贡献的最优折中点"。
2.3 整体性质:熵是凹函数
从整体来看,信息熵关于概率分布 {pi}\{p_i\}{pi} 是一个凹函数(concave function)。
这个结论的直观含义是:把概率"分散开",会增加熵;把概率"集中起来",会降低熵
在约束条件∑i=1npi=1\sum_{i=1}^{n} p_i = 1∑i=1npi=1下,我们可以得到关于熵的两个关键结论。
(1) 最小值为什么在边界?
如果我们把全部概率集中在一个事件上,例如:
(1,0,0,...,0) (1, 0, 0, \dots, 0) (1,0,0,...,0)
此时系统是完全确定的,结果已经"锁死",不存在任何不确定性。因此信息熵达到最小值:H(X)=0H(X) = 0H(X)=0。
这类分布位于概率空间的"边界",也被称为 one-hot 分布。
(2) 最大值为什么出现在均匀分布?
反过来看,如果我们把概率尽可能"平均分配":
pi=1n p_i = \frac{1}{n} pi=n1
此时每个结果的可能性完全相同, 没有任何偏好,每种结果都一样难预测。
系统的不确定性达到最大,因此信息熵也达到最大:
H(X)=log2n H(X) = \log_2 n H(X)=log2n
(3)一句话理解凹函数的作用
可以把信息熵理解为一个"偏好均匀"的函数:
- 越均匀 → 熵越大
- 越集中 → 熵越小
而凹函数的性质,正好保证了这一点。
三、严格推导:为什么最大值一定是均匀分布?
在前面的直觉分析中,我们已经知道:信息熵在"均匀分布"时达到最大。但这个结论也可以通过数学方法严格推导出来。这里我们使用拉格朗日乘子法来求解该最优化问题。
3.1 问题建模
设离散随机变量共有 nnn 个可能取值,其概率分布为:
{p1,p2,...,pn} \{p_1, p_2, \dots, p_n\} {p1,p2,...,pn}
我们希望在满足概率约束的条件下,使信息熵最大:
max H(X)=−∑i=1npilogpi \max \; H(X) = -\sum_{i=1}^{n} p_i \log p_i maxH(X)=−i=1∑npilogpi
约束条件为:
∑i=1npi=1,pi≥0 \sum_{i=1}^{n} p_i = 1, \quad p_i \ge 0 i=1∑npi=1,pi≥0
3.2 构造拉格朗日函数
为了处理约束 ∑pi=1\sum p_i = 1∑pi=1,引入拉格朗日乘子 λ\lambdaλ,构造函数:
\\mathcal{L}(p_1, \\dots, p_n, \\lambda) = -\\sum_{i=1}\^{n} p_i \\log p_i * \\lambda \\left(\\sum_{i=1}\^{n} p_i - 1\\right)
其中, pip_ipi是第 iii 个事件的概率 ,λ\lambdaλ是拉格朗日乘子,用于引入约束条件(在优化过程中"强制"满足概率和为 1 的约束。)。
3.3 求极值点
对每个变量 pip_ipi 求偏导,并令其为 0:
∂L∂pi=−(1+logpi)+λ=0 \frac{\partial \mathcal{L}}{\partial p_i} = -(1 + \log p_i) + \lambda = 0 ∂pi∂L=−(1+logpi)+λ=0
整理得到:
logpi=λ−1 \log p_i = \lambda - 1 logpi=λ−1
3.4 解的形式
由于右侧 λ−1\lambda - 1λ−1 是一个常数,这意味着所有 pip_ipi 的对数相同,因此所有 pip_ipi 本身也相同。即:
p1=p2=⋯=pn p_1 = p_2 = \dots = p_n p1=p2=⋯=pn
再结合约束条件 ∑pi=1\sum p_i = 1∑pi=1,可以得到:
pi=1n,i=1,2,...,n p_i = \frac{1}{n}, \quad i = 1,2,\dots,n pi=n1,i=1,2,...,n
3.5 结论
因此可以严格证明:在所有满足概率约束的分布中,均匀分布使信息熵取得最大值 。结合前面的凹函数性质,可以进一步说明:该解是唯一的全局最大值点。
四、直觉理解:熵到底在衡量什么?
如果暂时不看公式,可以把信息熵理解成一个更直观的问题:你有多"猜不准"?。换句话说,信息熵衡量的是:在平均意义下,我们对结果的不确定程度。
4.1 两个极端情况
(1) 完全确定
如果某个结果一定会发生,例如:概率为 1 ,其他结果概率为 0 。那么我们在观察之前就已经知道答案,这不需要猜,因为不存在任何不确定性 。此时信息熵为:
H(X)=0 H(X) = 0 H(X)=0
(2) 完全随机
如果所有结果的概率完全相同,例如每种结果的概率都是 1n\frac{1}{n}n1, 那么在观察之前:
-
每个结果都一样可能
-
无法做出任何有偏向的预测
此时系统最难预测,信息熵达到最大:
H(X)=log2n H(X) = \log_2 n H(X)=log2n
4.2 本质总结
从前面的分析可以看出,信息熵并不是在看"某一个结果",而是在看:在做出预测之前,我们平均需要承担多少不确定性。也就是说,它刻画的是整个系统的"不可预测程度":
- 分布越集中 → 越容易预测 → 熵越小
- 分布越均匀 → 越难预测 → 熵越大
五、一个非常容易踩坑的误区
一个容易产生的误解是: "某个事件的概率越小,信息熵就越小"。这一说法是不准确的。
5.1 正确理解
信息熵刻画的是概率分布的整体不确定性,而非某一个概率的大小。更准确地说:信息熵取决于分布的整体结构,而不是单个概率值。
5.2 举例说明
| 分布 | 直觉解释 | 熵 |
|---|---|---|
| (1, 0, 0) | 完全确定 | 最小 |
| (0.9, 0.1, 0) | 基本确定 | 较小 |
| (0.5, 0.5, 0) | 有明显不确定性 | 更大 |
| (1/3, 1/3, 1/3) | 完全均匀 | 最大 |
因此,在分析信息熵时,应关注概率分布的整体形态,而不是孤立地考察某一个概率值。
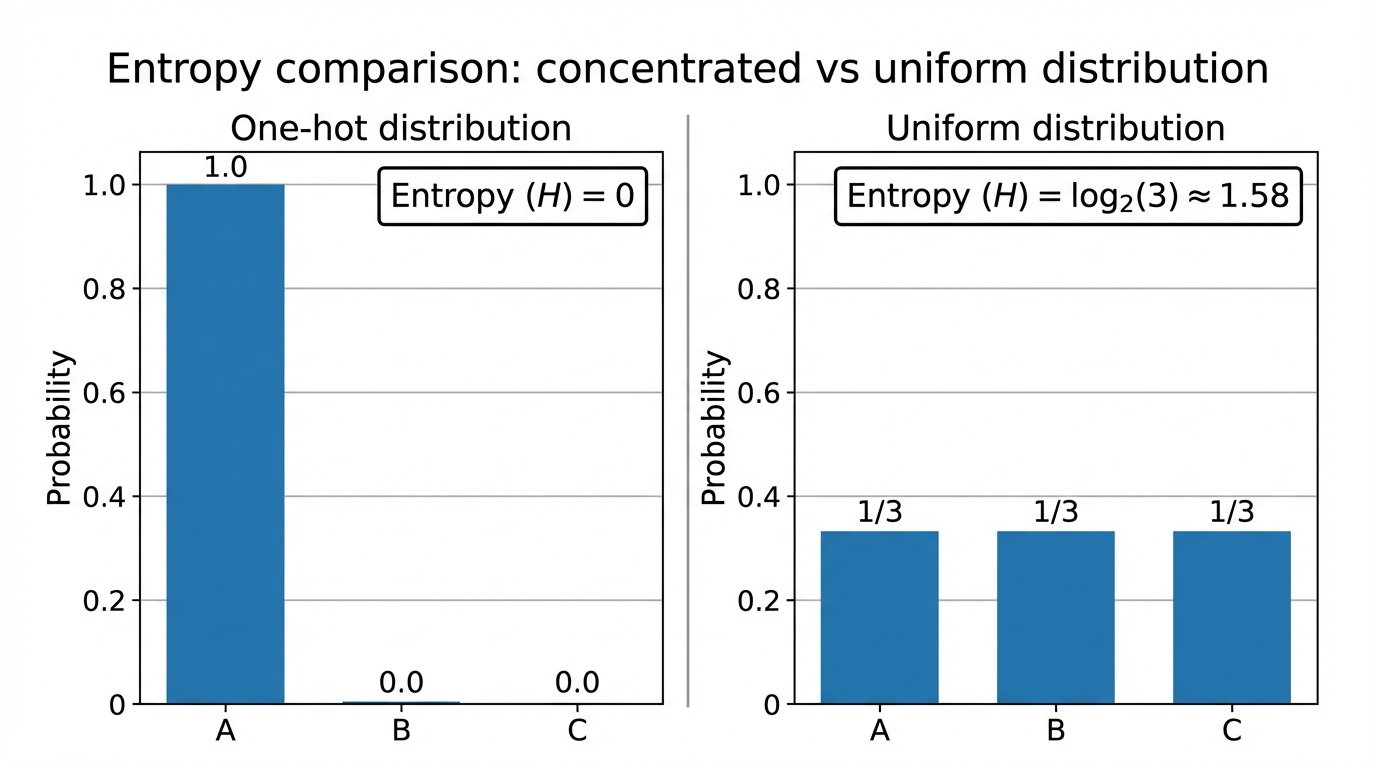
如图所示,从直觉上可以验证信息熵衡量的是"分布是否均匀",而不是某个概率的大小。
六、总结
信息熵的极值问题,本质上可以从"数学结构"和"直觉理解"两个角度来统一认识。
6.1 数学视角
从函数结构来看,信息熵可以写成单变量函数的求和形式:
H(p1,...,pn)=∑i=1nf(pi),f(p)=−plogp H(p_1, \dots, p_n) = \sum_{i=1}^{n} f(p_i), \quad f(p) = -p \log p H(p1,...,pn)=i=1∑nf(pi),f(p)=−plogp
由于单个函数 f(p)f(p)f(p) 在区间 (0,1)(0,1)(0,1) 上是凹函数,而凹函数的加和仍然保持凹性,因此信息熵关于概率分布 {pi}\{p_i\}{pi} 也是一个凹函数。
在约束 ∑pi=1\sum p_i = 1∑pi=1 下,可以得到:
- 最小值出现在边界分布(one-hot)
- 最大值出现在均匀分布
6.2 直觉视角
从直觉上看,信息熵刻画的是系统的不可预测性:
- 当分布高度集中时,结果几乎可以确定 → 不确定性最低
- 当分布完全均匀时,结果最难预测 → 不确定性最高
归根结底,信息熵并不是在描述结果本身,而是在描述:在给定概率分布下,"做出正确预测"这件事到底有多困难。