从一个小白的角度学习AI,如果有任何问题,欢迎指出
从 RNN 简单介绍
在 Transformer 出现之前,序列建模领域的主角长期是 RNN 及其变体。
如果把这段历史简化成一句话:RNN 先解决"能处理序列",Seq2Seq 解决"输入输出不等长",Attention 再解决"信息压缩与长距离依赖"。
这篇文章按我的学习顺序整理,尽量把关键概念说清楚。
一、解决了什么问题
在早期神经网络里,前馈网络(FNN)更擅长固定长度输入,不天然适合语言这种"先后有序、长度不固定"的数据。
RNN(循环神经网络)出现后,主要带来了三点能力:
- 能够建模词序:RNN 按时间步(token 顺序)逐个处理输入;
- 能够建模上下文依赖:通过隐藏状态传递历史信息;
- 支持不定长输入:句子长度不需要固定模板。
也就是说,当前时刻的结果不只看当前输入,还会受到历史输入影响。
二、RNN 的基本结构与公式
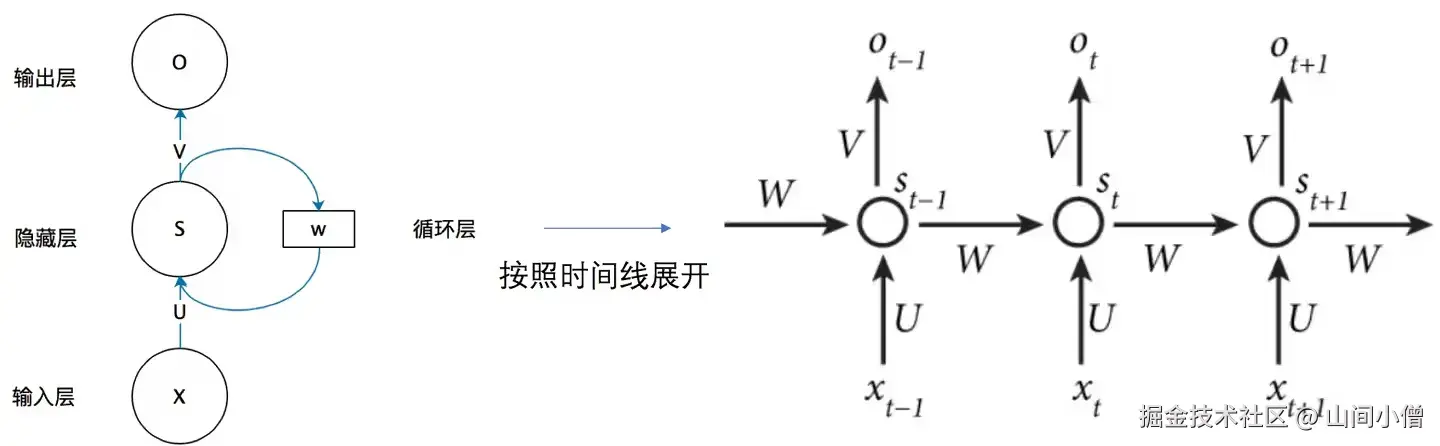
一个标准 RNN 单元通常包含以下变量:
- (X_t):第 (t) 个时间步的输入(一个 token 的向量表示)
- (S_t)(或 (h_t)):隐藏状态(内部记忆)
- (O_t):第 (t) 个时间步的输出
- (U):输入到隐藏层的权重矩阵
- (W):隐藏状态到隐藏状态的循环权重矩阵
- (V):隐藏层到输出层的权重矩阵
从公式可以看出,当前隐藏状态 (S_t) 由两部分决定:
- 当前输入 (X_t)
- 上一时刻隐藏状态 (S_{t-1})。
因此,RNN 的"记忆"本质上是通过隐藏状态在时间维度上传递的。
三、RNN 的优势与问题
3.1 优势
RNN 的优势在于它第一次让神经网络能"顺着时间"理解序列,尤其适用于语言、语音等时序数据。
3.2 问题
但 RNN 也有两个非常关键的局限:
-
长序列遗忘问题
信息需要经过很多时间步传递,远距离信息会衰减,导致模型更偏向最近上下文(常见解释是梯度消失/爆炸导致长程依赖学习困难)。
-
串行计算,难并行
第 (t) 步依赖 (t-1) 步,训练和推理都很难在时间维度并行,效率受限。
-
输入输出等长
这就引出了后面的 Encoder-Decoder。
四、引入编码器-解码器(Encoder-Decoder)
为了解决"输入输出长度不一致"的问题,Seq2Seq 架构被提出:
- Encoder(编码器):负责读取输入序列并编码语义;
- Decoder(解码器):负责基于编码结果生成输出序列。
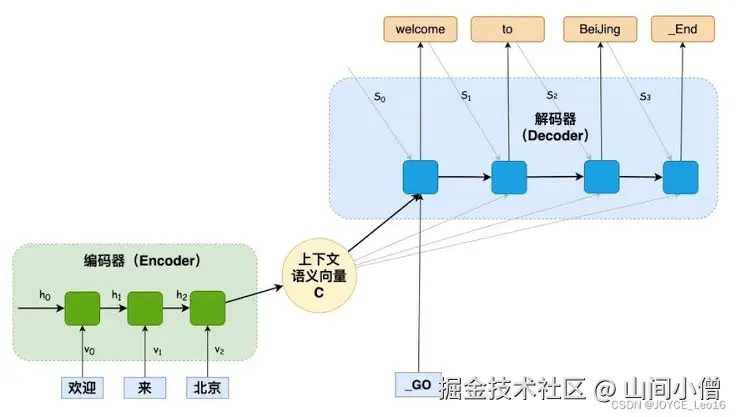
在基础版本中,会用一个上下文向量 (C) 承接输入语义。通过(C)来进行解耦。
简单的来说就是:
把整句信息压到一个固定向量里
但是也暴露出来一个问题: 序列一长就容易丢细节
五、Attention 机制:让每一步输出"看见"不同输入重点
基础 Seq2Seq 的核心瓶颈是固定上下文向量 (C)。
Attention 的改进点是:解码器在每个输出时刻,都去参考编码器所有时间步的隐藏状态,并计算一组权重。
直观上可以理解为:
- 生成不同目标词时,模型关注的源词位置不同;
- 每个输出位置都有自己的"上下文向量",而不是所有位置共享同一个 (C)。
这里还是很简单的就是对于不同位置,算上不同的权重