多模态智能体长期记忆突破:M3-Agent让AI像人一样"看、听、记、想"
1. 你的AI助手,为什么总是"失忆"?
想象一个场景:你家里有一个机器人管家,每天早上你起床,它递给你一杯咖啡------不用问"要咖啡还是茶?",因为它记得你过去三个月每天早上的选择。它知道你喜欢黑咖啡、不加糖,知道你周末会晚起半小时,甚至知道你心情不好的时候会多喝一杯。
这不是科幻电影的桥段,而是多模态智能体(Multimodal Agent)的终极目标。
但现实是------今天的AI助手,几乎全是"金鱼记忆"。你和它聊了两小时,关掉窗口再打开,它对你一无所知。即便是最先进的多模态大模型,处理一段30分钟的视频,也常常前后矛盾:前5分钟认出的人,到第20分钟就"不认识"了。
问题出在哪?不是模型不够大,不是参数不够多,而是AI根本没有一套像人类一样的长期记忆系统。
2. 长期记忆:多模态智能体的"最后一公里"
过去几年,AI在"看"和"听"上的能力突飞猛进。GPT-4o能看图说话,Gemini能处理百万Token的上下文,Qwen2.5-Omni能同时理解视频和音频。但这些能力有一个共同的天花板------它们都是"即时处理",没有真正的记忆。
这带来了三个致命问题:
第一,身份一致性崩塌。一个人在视频前半段穿红衣服、后半段换了蓝衣服,模型就可能把同一个人当成两个人。用文字描述"一个穿红衣服的女人"来追踪身份?时间一长,这种描述必然产生歧义和冲突。
第二,世界知识无法积累。传统的视频描述方法只关注"发生了什么"------低层级的视觉细节,却忽略了"这意味着什么"------高层级的世界知识。比如"Alice每天早上喝咖啡"这种偏好信息,"绿色垃圾桶是用来回收的"这种环境知识,现有方法几乎无法提取和保存。
第三,无限流处理的不可能。现有方法要么靠扩展上下文窗口(但窗口再大也有限),要么靠压缩视觉Token(但压缩必然丢信息)。面对一个持续运行的机器人每天接收的无限视频流,这些方案全部失效。
就在这样的背景下,字节跳动Seed团队联合浙江大学、上海交通大学,提出了M3-Agent------一个真正具备长期记忆的多模态智能体框架。
研究团队由字节跳动Seed的Yuan Lin(通讯作者)领衔,核心成员包括Lin Long(浙江大学/字节跳动,共同一作)、Yichen He(字节跳动,共同一作)、Wentao Ye(浙江大学/字节跳动)、Yiyuan Pan(上海交通大学/字节跳动)等。这支团队横跨工业界和学术界,既有字节跳动在大规模模型训练上的工程能力,又有浙大和上交在多模态理解上的研究积累------是一个典型的"产学研深度融合"组合。
3. M3-Agent的核心设计:像人脑一样组织记忆
M3-Agent的名字里藏着它的核心理念------Multimodal Memory-augmented Agent,多模态记忆增强智能体。它的架构灵感直接来自认知科学中对人类记忆系统的研究。
人类的长期记忆分为两种:情景记忆(Episodic Memory)------你记得"昨天Alice在咖啡厅说了一句'我早上离不开咖啡'"这个具体事件;语义记忆(Semantic Memory)------你从多次观察中总结出"Alice喜欢早上喝咖啡"这个一般性知识。
M3-Agent完整复刻了这个双轨结构。
整个系统由两个并行流程驱动:记忆化流程(Memorization)和控制流程(Control)。记忆化流程持续处理实时的视频和音频输入,生成情景记忆和语义记忆;控制流程在接收到指令时被触发,通过多轮推理和记忆检索来完成任务。
下面这张架构图清晰地展示了整个系统的运作方式:
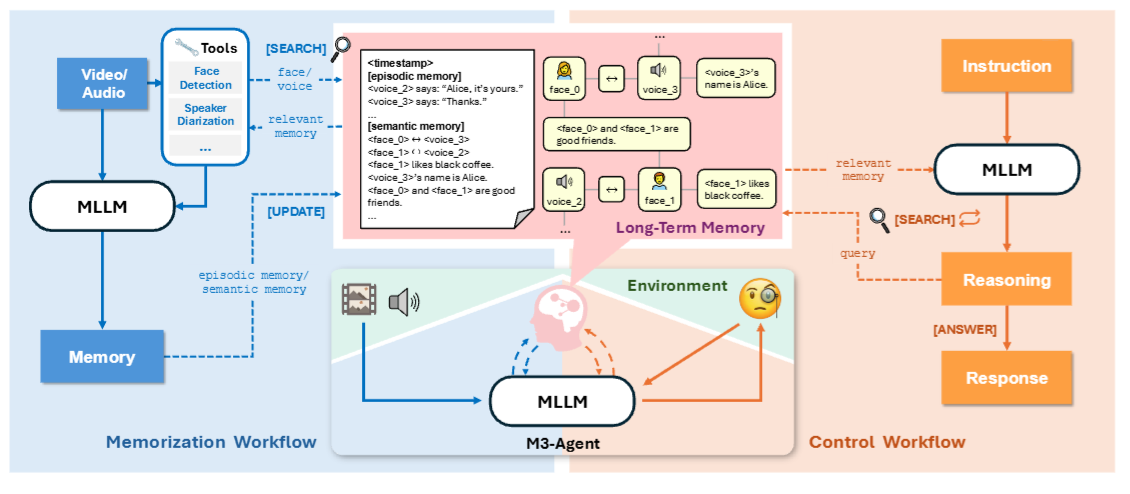
图1
图1:M3-Agent整体架构。左侧为记忆化流程------多模态大模型处理视频/音频流,借助人脸检测和说话人识别等工具,生成情景记忆和语义记忆,并更新到以实体为中心的多模态图谱中;右侧为控制流程------接收指令后,通过多轮推理迭代检索长期记忆,最终生成回答。
这就像人脑的两个模式------你走在街上,大脑在不断"录制"周围的信息(记忆化);当有人问你"刚才那个路口有没有红绿灯?",你的大脑切换到"回忆+推理"模式(控制)。
更关键的是,M3-Agent的记忆不是一堆散乱的文本片段,而是一个以实体为中心的多模态图谱(Entity-Centric Multimodal Graph)。每个记忆节点可以是文本、图像或音频,节点之间通过边连接------同一个人的脸、声音和相关知识被关联在一起,形成一个完整的"人物档案"。
翻译成人话------M3-Agent不是在做"视频笔记",而是在建"人物百科"。
4. 身份一致性:用人脸和声纹替代文字描述
长期记忆最大的敌人是什么?不一致。
传统方法用文字描述来追踪人物------"一个戴眼镜的男人""一个穿红裙子的女人"。这在短视频里勉强能用,但在30分钟以上的长视频里,同一个人可能换了衣服、摘了眼镜、换了发型,文字描述就彻底失效了。
M3-Agent的解决方案非常直接------不用文字描述身份,用原始的多模态特征。
具体来说,M3-Agent配备了两个外部工具:人脸识别(Facial Recognition)和说话人识别(Speaker Identification)。对于每个视频片段,系统会提取出现的人脸和声音,并为每个人分配一个持久化的ID------比如<face_1>代表某张脸,<voice_2>代表某个声音。
这些ID不是临时标签,而是锚定在长期记忆图谱中的节点。当系统在不同时间段看到同一张脸或听到同一个声音时,它会自动关联到同一个节点,而不是创建一个新的"穿蓝衣服的男人"。
更巧妙的是跨模态身份关联。M3-Agent能推断出<face_1>和<voice_3>属于同一个人------比如通过观察到某个人说话时嘴在动,或者通过对话内容中的名字线索。一旦建立关联,这两个节点就被合并为一个<character_id>,后续检索时可以跨模态统一推理。
为了处理偶尔的识别错误,系统引入了基于权重的投票机制。正确的关联会随着时间积累更高的权重,最终压过错误的关联。这就像人类的记忆纠错------你第一次可能把两个长得像的人搞混,但见多了自然就分清了。
这是一个关键的设计决策。它意味着M3-Agent的记忆一致性不依赖于单次识别的准确率,而是依赖于长期积累的统计优势。
5. 双轨记忆生成:从"发生了什么"到"这意味着什么"
M3-Agent以30秒为一个片段(clip)处理视频流。对于每个片段,它同时生成两种记忆:
情景记忆捕捉具体事件------谁做了什么、说了什么、穿了什么。比如:"<face_1>穿着白色T恤和绿色图案,戴着黑色棒球帽和绿色墨镜""<voice_2>说:'我们要去池塘钓鱼,我要买一个喂鱼器'"。
语义记忆提取高层知识------人物属性、人际关系、环境知识、一般性常识。比如:"<face_1>展现出对户外活动和家庭体验的兴趣""<face_1>和<face_2>似乎有一种舒适和支持性的关系,可能是伴侣或亲密家人""这段视频可能属于家庭Vlog类型"。
为什么语义记忆如此重要?因为它提供了额外的检索线索。
举个例子:如果有人问"Tomasz有没有想象力?",仅靠情景记忆,你需要翻遍所有片段去找Tomasz做过什么。但如果语义记忆中已经记录了"Tomasz具有创新和前瞻性思维,他对将无人机技术扩展到个人飞行表现出浓厚兴趣",答案就能直接检索到。
消融实验的数据非常说明问题:去掉语义记忆后,M3-Bench-robot上的准确率下降了17.1%,M3-Bench-web下降了19.2%,VideoMME-long下降了13.1%。
这不是锦上添花,而是系统的核心支柱。
6. 控制流程:不是一次检索,而是多轮推理
传统的RAG(检索增强生成)方案是"一问一检索一回答"------收到问题,检索一次记忆,生成答案。这对简单问题够用,但对需要多步推理的复杂问题完全不够。
M3-Agent的控制流程采用了一种迭代式的多轮推理机制。收到指令后,智能体会自主决定:当前信息够不够回答问题?如果不够,应该搜索什么?搜索到新信息后,再判断:现在够了吗?还需要什么?
论文中给出了一个精彩的案例。问题是:"Tomasz是一个有丰富想象力的人,还是缺乏想象力的人?"
第一轮:智能体发现记忆库中没有关于Tomasz的信息,于是搜索"Tomasz的character ID是什么?"------找到Tomasz是<character_4>。
第二轮:用<character_4>搜索"关于想象力的性格特征"------没有直接结果。
第三轮:智能体推理------Tomasz是一家公司的CTO,也许可以从他的创新行为中推断想象力。于是搜索"<character_4>的创造性问题解决方法"------找到了关键语义记忆:"<character_4>具有创新和前瞻性思维,他对将无人机技术扩展到个人飞行表现出兴趣。"
第四轮:信息充足,输出答案:"Tomasz是一个有丰富想象力的人。"
四轮推理,三次检索,每次检索的角度都不同。这不是简单的关键词匹配,而是真正的推理驱动的信息搜集。
去掉多轮推理能力后,三个基准测试上的准确率分别下降了11.7%、8.8%和9.5%。
7. 强化学习训练:从"提示工程"到"自主进化"
M3-Agent的训练策略是整篇论文中最值得关注的工程决策之一。
团队没有用同一个模型同时处理记忆化和控制------而是分别用不同的基座模型初始化:记忆化用Qwen2.5-Omni-7B(擅长多模态理解),控制用Qwen3-32B(擅长推理)。
记忆化模型通过模仿学习(Imitation Learning)训练。训练数据的合成过程本身就很精巧:先用GPT-4o生成帧级别的视觉描述,再把这些描述作为上下文喂给Gemini-1.5-Pro,让后者生成更丰富的情景记忆。两个模型的互补------GPT-4o提供细粒度视觉细节,Gemini-1.5-Pro提供事件级叙述------产生了比任何单一模型都更高质量的训练数据。
控制模型则通过DAPO(一种强化学习算法)训练。奖励信号非常简洁:GPT-4o评估最终答案是否正确,正确得1分,错误得0分。没有中间奖励,没有过程监督------纯粹的结果导向。
强化学习带来的提升是决定性的。对比纯提示工程的版本,RL训练后的控制模型在M3-Bench-robot上提升了10.0%,M3-Bench-web上提升了8.0%,VideoMME-long上提升了9.3%。
更值得注意的是模型规模的影响:8B、14B、32B三个尺寸的模型都从DAPO训练中获得了显著提升,且提升幅度随模型增大而增加。这说明强化学习和模型规模之间存在正向协同------模型越大,RL能释放的潜力越大。
8. M3-Bench:为什么需要一个新的评测基准?
现有的长视频问答基准------EgoSchema、LongVideoBench、HourVideo、Video-MME------几乎都聚焦于视觉理解:动作识别、时空感知、场景描述。但对于一个真正的多模态智能体来说,这些只是"基础体检"。
M3-Agent需要的是"高阶认知测试":你能不能记住一个人的名字?能不能从多个片段中推断出一个人的性格?能不能把视觉信息和听觉信息结合起来推理?
M3-Bench正是为此而生。它包含两个子集:M3-Bench-robot(100个真实机器人视角视频,平均34分钟,1276个QA对)和M3-Bench-web(920个YouTube视频,平均27分钟,3214个QA对)。
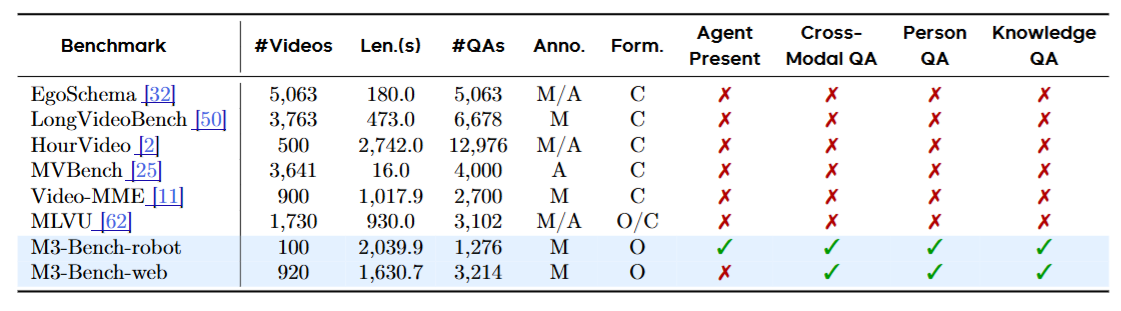
表1
表1:M3-Bench与现有长视频问答基准的全面对比。可以看到,M3-Bench是唯一同时覆盖跨模态推理、人物理解和知识提取三类问题的基准,且全部采用开放式问答而非选择题------这对模型的要求高出一个量级。
五种问题类型直击智能体的核心能力:
多证据推理------需要聚合视频中分散在不同片段的多条信息。比如"视频中展示的五件藏品,哪件起拍价最高?"你得分别找到五个片段,记住每个价格,再比较。
多跳推理------需要跨片段的链式推理。比如"他们去了鼎茶之后,又去了哪家奶茶店?"你得先定位"鼎茶"的片段,再追踪后续行程。
跨模态推理------需要结合视觉和听觉信息。比如Bob展示一个红色文件夹说"机密文件放这里",又展示白色文件夹说"普通文件放这里"------你得把颜色(视觉)和指令(听觉)对应起来。
人物理解------需要推断人物属性。比如"Lucas擅长做饭吗?"视频不会直接告诉你答案,你得从Lucas多次做饭的表现中推断。
一般知识提取------需要从具体事件中提炼通用知识。比如看到有人把不同食材分类放进冰箱不同层,你得总结出"蔬菜应该放在哪一层"。
下面这组案例直观展示了这些问题类型的难度:

图2
图2:M3-Bench的典型案例。左上角的"跨模态推理"需要结合语音指令和视觉画面判断酒放在冰箱第几层;右上角的"一般知识提取"需要从五个分散片段中比较起拍价;下方的"人物理解"需要从Lucas多次做饭的表现中推断他是否擅长烹饪------注意视频中还有一个做饭很熟练的父亲作为干扰项。
M3-Bench-robot的数据收集尤其用心:67名演员在51个不同地点拍摄,每个视频至少70个事件、12个QA对,人类标注者的准确率为90.7%------这意味着即便是人类,也有近10%的问题答不对。
这是一个真正有挑战性的基准。
9. 实验结果:全面超越,但远未到顶
一句话概括:M3-Agent在三个基准测试上全面超越所有基线方法。
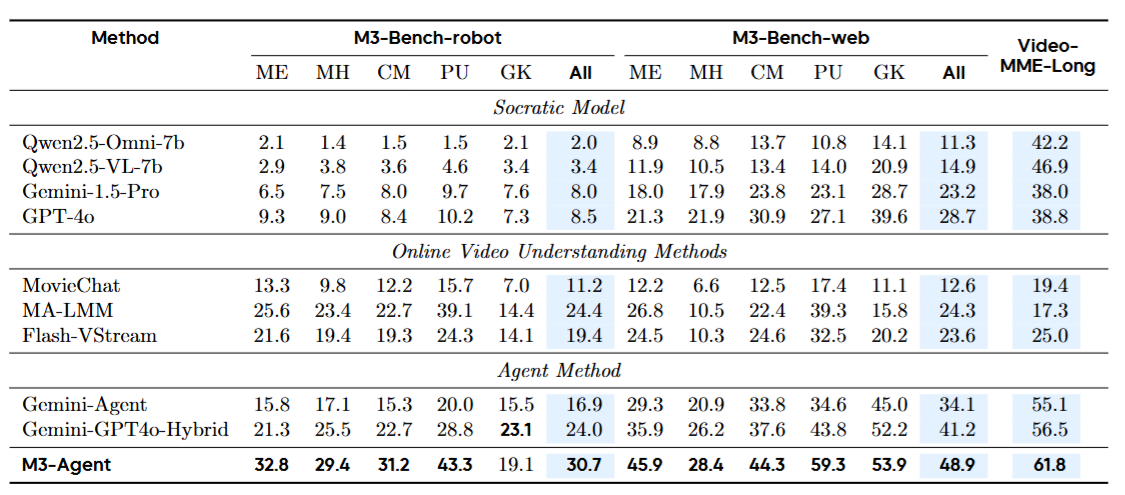
表2
表2:所有方法在M3-Bench-robot、M3-Bench-web和VideoMME-long上的完整结果。M3-Agent(最后一行)在几乎所有维度上都取得了最高分,尤其在人物理解(PU)和跨模态推理(CM)上优势显著。
对比最强基线Gemini-GPT4o-Hybrid(用Gemini-1.5-Pro做记忆、GPT-4o做控制的提示工程方案),M3-Agent在M3-Bench-robot上高出6.7%,M3-Bench-web上高出7.7%,VideoMME-long上高出5.3%。
在人物理解维度上,优势更加明显:M3-Bench-robot上比最强基线高出4.2%,M3-Bench-web上高出15.5%。这直接验证了实体中心记忆图谱的价值------当你能持续追踪一个人的身份、行为和属性时,理解这个人就变得容易得多。
但论文也坦诚地指出了两类困难案例:
第一类是细粒度细节推理。"谁想吃火腿肠?""Emma的帽子应该挂在高的还是矮的衣架上?"------这些问题需要记住极其具体的细节,而把所有细节都存入记忆既不现实也会造成认知过载。
第二类是空间推理。"机器人在哪里能拿到零食?""Leo的水杯现在在架子从上往下数第几层?"------语言记忆天然不擅长保存空间信息,长期记忆需要引入更丰富的视觉内容(比如快照)来支持空间推理。
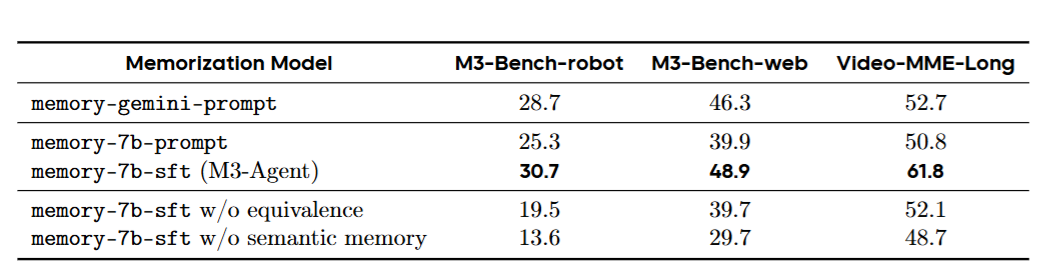
表3
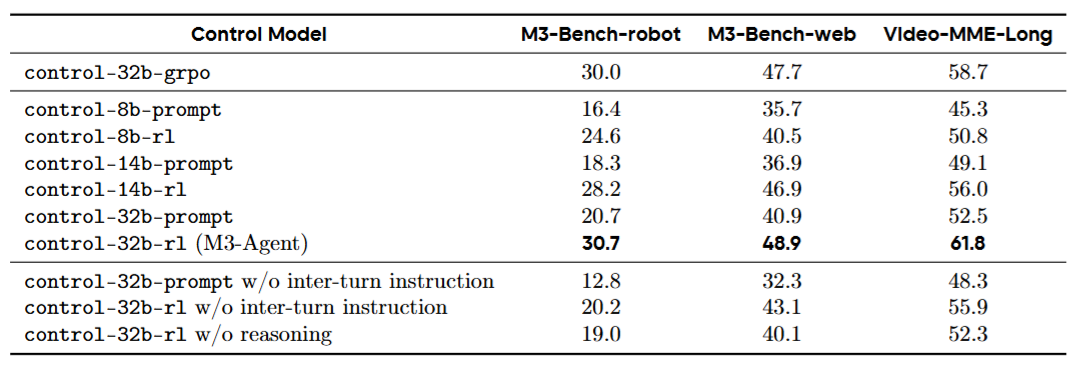
表4
表3和表4分别展示了记忆化和控制的消融实验结果,清晰地量化了每个组件的贡献------语义记忆、身份等价关系、RL训练、多轮推理,去掉任何一个都会造成显著的性能下降。
M3-Bench-robot上30.7%的整体准确率说明了一个事实:这个问题远未解决。但M3-Agent指出了正确的方向。
10. 从"即时智能"到"积累智能"
如果把过去几年的AI进步画成一条线,你会发现一个清晰的趋势:从"更大的模型"到"更聪明的系统"。
GPT-4o、Gemini、Qwen------这些模型的能力已经足够强大,但它们本质上都是"即时智能":给一个输入,产生一个输出,然后遗忘一切。M3-Agent代表的是另一种范式------"积累智能":通过持续感知和记忆积累,智能体的能力随时间增长。
这篇研究的意义不仅在于一个框架或一组数据,而在于它清晰地定义了多模态智能体走向实用化的三个核心能力:持续感知(Seeing & Listening)、知识建构(Remembering)、记忆推理(Reasoning)。
未来的演化方向至少有三个:
第一,注意力机制的引入。不是所有信息都值得记住------智能体需要学会"选择性记忆",根据任务需求动态调整记忆的粒度和重点。
第二,视觉记忆的增强。当前的长期记忆以文本为主,但空间信息、物体状态等视觉知识用文字很难精确表达。更高效的视觉记忆存储和检索机制是下一个突破口。
第三,从单智能体到多智能体。当多个具备长期记忆的智能体协作时,记忆的共享、同步和冲突解决将成为全新的研究课题。
如果说过去的多模态AI是"看一眼就忘"的金鱼,M3-Agent展示的是"越活越聪明"的第一块基石。