Transformer实战(39)------多模态生成式Transformer
0. 前言
能够理解多种类型输入的模型被称为多模态模型。多模态学习是人工智能 (Artificial Intelligence, AI) 领域的重要研究方向之一,长期受到众多研究人员的关注。本节将介绍使用多模态模型的生成式 AI,包括文本到图像 (text-to-image) 和文本到音乐 (text-to-music) 的生成模型。将介绍 Stable Diffusion 及其工作原理,同时也将介绍 MusicGen 和 AudioGen 模型。
1. 多模态学习
从广义上讲,多模态学习 (Multimodal Learning) 是指在机器学习中使用不同模态进行学习的过程。在机器学习中,模态指的是输入模型的数据类型。常见的模态包括文本、视觉(图像和视频)、听觉(声音、语音和音乐)等数据。
对比语言-图像预训练 (contrastive language-image pretraining, CLIP) 模型是经典的多模态模型,它能够将文本和视觉数据表示到同一个空间中。利用这种表示,我们可以创建不同的应用。例如,我们可以为来自同一数据集的图像和文本创建向量表示,并在此基础上构建分类器。或者,我们也可以通过摄像头、RAM、电池和设备外观图像等特征预测手机的价格。如何融合这些模态,使得模型能够理解并生成最佳输出,一直是该领域的一个重要问题。
多模态学习并不仅仅关注理解不同模态中的数据;它还涉及从一种模态获取输入,并生成另一种模态的输出。从这个意义上讲,图像描述 (image captioning) 也可以视为一种多模态学习形式,因为输入是视觉数据,而输出是文本数据。
传统方法融合不同模态特征通常采用手动加权或训练融合权重,而新的方法通过将所有特征转换为相同或非常相似的特征空间来解决这一问题。例如,文本-视觉多模态模型将图像分割为与文本词元类似的图像块。然后,这些视觉词元和文本词元以相似的方式表示,模型不再分别接受不同模态的输入,模型则以相同的方式处理它们。
在下一小节中,将了解更多关于生成式多模态 AI 的内容,从一种模态获取输入并生成另一种模态的输出。
2. 生成式多模态人工智能
生成式人工智能 (Generative AI, GenAI) 是一类能够生成输出的 AI 模型。这并不意味着其他模型不能生成输出(所有 AI 模型都会生成输出),生成式 AI 强调的是能够理解训练数据的潜在模式,并根据这些模式生成新数据的模型。
生成式 AI 由来已久,但由于过去我们对其生成输出的控制有限,因此它并未引起广泛关注。即便我们能控制它,也无法精确指定我们希望生成的内容。即便我们能够控制并明确指定生成内容,这一过程对于用户而言也并不容易理解。
随着 ChatGPT、DeepSeek 等模型的发布,能够通过文本描述来获取我们希望生成的内容,甚至一些模型能够接受图像或语音形式的输入,这使得生成式 AI 技术可以更容易地为广大用户所使用。
在下一节中,我们将详细解释 Stable Diffusion 在文本到图像生成中的工作原理,并展示其在实际图像生成中的应用。
3. Stable Diffusion
3.1 扩散模型
文本生成图像是生成式 AI 的一种应用。通过文本生成图像,特别是生成高质量图像,具有广泛的应用场景,包括游戏设计、市场营销等。为了理解这类模型的工作原理,我们需要首先了解关于扩散模型 (diffusion model) 的基本原理。
扩散 (Diffusion) 这一术语源自物理学。类似于墨水在水中溶解的物理反应,AI 中的扩散过程也是如此。例如,以一张普通图像为起点,正向扩散是向图像中添加噪声的过程。如下图所示,这一过程会将图像逐渐转化为噪声(随着噪声水平的增加),使图像与原始图像无法区分。

正向扩散过程会生成同一图像带有不同噪声量的版本,我们可以用它来训练模型以逆转该过程,即去除噪声。这是一种非常高效的技术,可以生成非常逼真的图像。但这种方法的一个主要问题是:它的生成速度非常慢。必须逐步去除图像中的噪声。这一过程也称为采样:在每一步中,将含噪图像输入到模型中,模型预测噪声像素,然后从图像中去除噪声。这个迭代过程会持续进行,直到最终从纯噪声生成一张逼真的图像。
调度器 (Scheduler) 用于控制添加到图像中的噪声量。调度器遵循一定的模式,在每一步为图像添加一定量的噪声,这确保了在整个过程中噪声量按照一定的规律变化。
变分自编码器 (Variational Auto-Encoders, VAE)是一种更快的方法,首先压缩输入,然后再尝试解压。经典的 VAE 架构如下图所示:
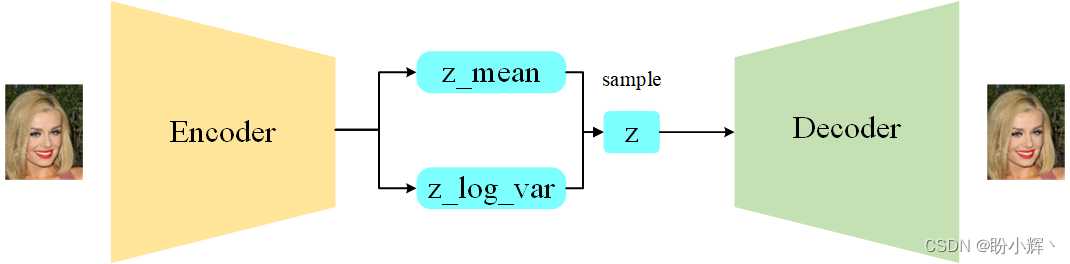
Stable Diffusion 使用的另一种更快噪声添加的方法是 VAE,因为它们不是直接对图像应用噪声,而是将噪声应用于图像的潜空间表示。与原始图像相比,潜空间的大小要小得多。这个过程可以重新表述为在图像的潜空间表示中生成具有特定调度器约束的噪声,并将其添加到图像中。
上述过程是一种生成图像的方法。但如果无法控制这个过程,它只能用来随机生成图像。为了解决这个问题,使用文本编码器(例如,CLIP )将文本编码成密集向量。然后,这个密集向量用来在去噪和解码过程中引导 UNet (一种卷积神经网络架构) 生成图像。
我们已经了解了 Stable Diffusion 及其工作原理。接下来,将学习如何使用它生成图像。
3.2 Stable Diffusion 应用
在本节中,将学习如何使用 Stable Diffusion 进行实际操作。通过使用 diffusers 和 transformers 库,可以极大简化这一过程。
(1) 为了以最简单的方式使用 Stable Diffusion,首先需要安装以下库:
shell
$ pip install diffusers transformers accelerate safetensors(2) diffusers 是用来加载 Stable Diffusion 模型的库:
python
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
model_id = "stabilityai/stable-diffusion-2-1"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")(3) 管道构建完成后,向其提供提示生成图像:
python
prompt = " hyperrealistic portrait of unicorn"
image = pipe(prompt).images[0](4) 生成的图像如下图所示:
python
from matplotlib import pyplot as plt
plt.axis('off')
plt.imshow(image)
(5) 可以看到,虽然生成的图像并不像预期的那样逼真,但生成图像质量非常高。通过使用提示工程可以改进生成结果:
python
prompt = "hyperrealistic portrait of unicorn, cosmic survival, Hyper quality, photography, digital art"
image = pipe(prompt).images[0]
plt.axis('off')
plt.imshow(image)通过提示工程改进后的输出如下:

可以看到,使用提升工程能够显著改进生成质量,这也就是提示工程逐渐流行的原因。
Stable Diffusion 不仅可以通过文本提示进行控制,还可以通过另一张图像作为生成源进行控制。在 Stable Diffusion 基础上应用的新技术(如 ControlNet)可以实现这种能力。
简单来说,ControlNet 通过将 Stable Diffusion 与特定输入条件结合来控制生成过程。例如,可以使用涂鸦、边缘图、姿态关键点、深度图、分割图等。
4. 使用 MusicGen 生成音乐
大语言模型在许多领域都取得了巨大成功。除了生成文本和图像外,也可以将大模型(通常基于 Transformer )用于其他任务。例如,可以创建一个大音乐模型,接受文本提示作为输入,并生成音乐作为输出。MusicGen 是音乐生成大模型中的前沿代表,使用 audiocraft 库可以轻松使用 MusicGen。
(1) 首先,安装 Audiocraft 库:
shell
$ pip install audiocraft(2) 接下来,加载模型并设置音乐生成时长:
python
from audiocraft.models import musicgen
import torch
model = musicgen.MusicGen.get_pretrained("facebook/musicgen-medium", device="cuda")
model.set_generation_params(duration=8)(3) 最后,向模型传递提示,并生成音乐:
python
generated_music = model.generate(
["80s rock music with drums and electric guitar", "90s retro action game music"],
progress=True,
)(4) 在 notebook 中播放音乐:
python
from audiocraft.utils.notebook import display_audio
display_audio(generated_music, 32000)可以使用不同的提示生成音乐。可以将这些生成的音乐用于创意工作,例如为正在开发的游戏制作大量音乐,或者可以创建一个应用程序,让用户生成音乐并相互分享。MusicGen 还支持音频提示,这意味着可以输入一段特定音乐样本,改变其风格。在下一节中,我们将学习如何使用语音生成模型。
5. 基于 Transformer 文本转语音
文本转语音生成一直是 AI 助手的重要组成部分,因为它们通常需要与用户进行语音交互。可以使用 Transformer 来完成这一任务,Transformer 能够学习如何复制不同的声音。
BARK 是文本转语音生成领域最成功的模型之一。这个模型可以生成逼真的人类语音,还可以添加背景噪声、音乐和音效。它支持多语言和多个说话者。使用 transformers 库可以非常简单的调用 BARK 模型。
(1) 首先,导入所需库和模块:
python
from transformers import AutoProcessor, AutoModel(2) 接下来加载处理器和模型。处理器用于处理输入:
python
processor = AutoProcessor.from_pretrained("suno/bark")
model = AutoModel.from_pretrained("suno/bark")(3) 使用处理器和模型生成语音。需要注意的是,我们可以使用特殊词元,比如 [clears throat] (清喉咙)或 [laughs] (笑声),来在语音中添加效果:
python
inputs = processor(
text=["Hi! My name is Superman. I like superpower [laughs] I mean, I really like it [clears throat] I have been working in field on saving world for almost a decade"],
return_tensors="pt",
)
speech = model.generate(**inputs, do_sample=True)(4) 在 notebook 中播放生成的音频:
python
from IPython.display import Audio
Audio(speech.cpu().numpy().squeeze(), rate=model.generation_config.sample_rate)我们已经学习了如何使用多模态模型生成图像、音乐和语音,这些模型能够实现更加智能和多样化的应用。内容创作者可以使用它们来生成创意性内容,用于广告、游戏等。
小结
在本节中,我们学习了如何使用多模态生成式 Transformer,生成图像、音乐和语音,同时这一领域发展迅速,几乎每天都会有新的生成式 AI 工具被创建。通过本节,我们已经掌握了如何使用这些模型,并将它们集成到日常内容创作任务中。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型
Transformer实战(35)------跨语言相似性任务
Transformer实战(36)------Transformer模型部署
Transformer实战(37)------Transformer模型训练追踪与监测
Transformer实战(38)------视觉Transformer