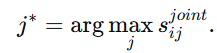定义
单个图内部。 实体-属性对是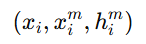
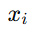 表示第 i 个实体,
表示第 i 个实体,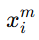 表示这个实体的第 m 个属性,
表示这个实体的第 m 个属性,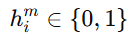 是一个二值标记,等于1表示它们之间存在有效的"实体内部对应关系";
是一个二值标记,等于1表示它们之间存在有效的"实体内部对应关系";
跨图的实体对齐。 实体-实体对为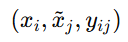
xi 来自第一个图,x~j 来自第二个图,波浪号 ~ 只是用来区分"另一个图里的对象"。其中 yij=1
表示 xi 和x~j 指的是同一个现实世界中的对象;
方法
不确定性建模
对于给定实体 xi ,对每个候选实体j ,模型会产生一个证据值eij 。这个eij 表示:对于" xi 应该和第j 个候选实体匹配"这件事,模型目前积累了多少支持证据。通常有 eij≥0,证据越大,说明模型越倾向于支持这个候选。
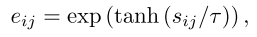
接着,作者定义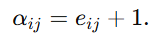 ,防止eij=0导致Qi=0
,防止eij=0导致Qi=0
然后定义"总置信强度"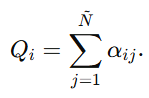 。可以把它理解为:模型对这个实体 xi 到底掌握了多少整体信息。Qi 越大,说明模型积累的总证据越多;Qi 越小,说明模型掌握的信息越少。
。可以把它理解为:模型对这个实体 xi 到底掌握了多少整体信息。Qi 越大,说明模型积累的总证据越多;Qi 越小,说明模型掌握的信息越少。
下面再看两个核心量。
第一个是belief mass:
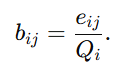
它表示:在所有总强度 Qi 中,有多少比例被分配给" xi 匹配第 j 个候选实体"这个判断。注意这里分子用的是 eij ,不是αij 。这说明belief mass 只统计"额外证据"本身,不把那个人为加进去的1 算作真正的支持信息。
第二个是 uncertainty:
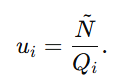
N~ 可以理解为"候选匹配目标个数"。这个式子说明不确定性 与 Qi 成反比。总强度 Qi 越大,不确定性 ui 越小;总强度越小,不确定性越大。
现在来验证为什么有

因为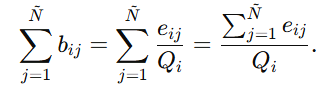 ,
,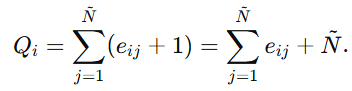
所以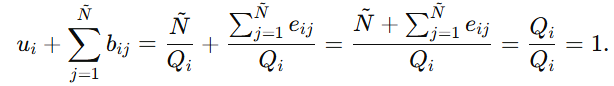
总结:
对于实体xi ,作者不是直接输出"它和谁匹配"的概率,而是先通过证据eij 构造 Dirichlet 分布,再把判断分解为"对各候选的信念" bij 和"整体不确定性" ui 。当证据充足时,信念集中且不确定性低;当证据不足或样本失配时,信念弱且不确定性高。
共识建模
前文的不确定性 uiu_iui 确实有助于识别噪声对应关系,但作者发现:低不确定性并不一定意味着当前实体对齐是对的 。也就是说,模型可能"很自信",但"自信地错了"。因此,单靠uncertainty 不够,还需要一个额外指标,去判断模型的高置信到底是不是落在真实标注对应上。这个额外指标就是 consensus。
只要总证据很多,Qi 就大,ui 就小。可这些证据可能集中在正确候选上,也可能集中在错误候选上。uncertainty 本身区分不了这两种情况。
对于给定的实体 xi,共识定义为:
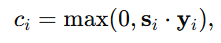
++其中 si = si1, si2, · · · , siN 表示相似度向量,即实体 xi 和所有候选实体之间的相似度向量。++ max(0, ·) 确保共识是非负的。++yi 是 one-hot向量,只有一个位置是 1,其余位置全是 0 的向量,用来表示"多个类别里只有一个是真的"。++
可是在测试阶段 ,不知道真实匹配对象是谁。既然不知道 yi ,那你就不能直接算这个 ci。
为了解决"测试时没有真实标签"这个问题,作者提出:不用真实标注 yi,而是通过一种基于 marginal contribution(边际贡献)的贪心策略,去估计哪个候选实体才是正确对应。
对于给定的实体 xi ,其第 m个属性的边际贡献定义为
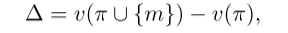
这里的 Δ 表示:把第 m 个属性加入当前属性子集 π 后,整体价值提高了多少。
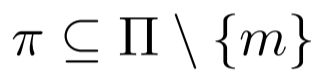 表示排除第 m 个属性的属性子集 π ,π 是可用属性的完整集合。
表示排除第 m 个属性的属性子集 π ,π 是可用属性的完整集合。
接下来最关键的是 value function ,也就是 v(⋅) 到底怎么定义。
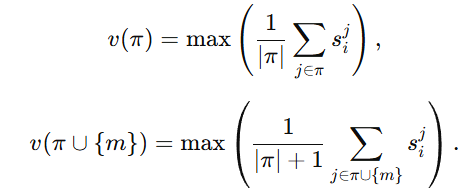
- sij 表示第 j 个属性产生的相似度信息;
- 对属性子集 π 里的各属性做平均,得到一个基于这些属性的综合相似度;
- 再在候选实体里选出最相似的那个候选,把这个最大相似度当成 v(π)。
第 m 个属性是否提升了实体 xi 的最佳匹配质量。
如果 Δ>0,说明加了这个属性以后,最优匹配更清晰了、质量更高了;如果 Δ<0,说明这个属性让匹配更模糊了,可能引入了错误干扰。
文中给出的贪心策略是:
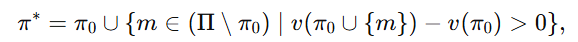
其中 π0是初始属性子集,满足
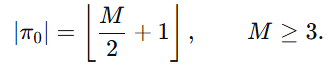
M 表示总属性数,π0 是一个初始子集。作者先从一个"过半"的属性子集开始,然后考察剩余属性:对每个尚未选入的属性 m;如果把它加进当前子集后,value function 提升,那就把它加入最终子集 π∗。这就是一个典型的贪心筛选:谁有正增益,就留下;谁没增益,就丢掉。
Pair Division
作者考虑的是那些满足 yij=1 的inter-graph pairs,也就是"当前标注为匹配"的跨图实体对。换句话说,这些样本在训练数据里都被当作正样本,但作者怀疑其中有些其实带噪声,所以不能一视同仁。因此,他们把这些正样本再细分成三类。
第一类是 noisy portion with high uncertainty,记作
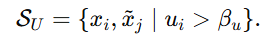
这类样本的特点是 不确定性高 。意思是:模型对这个实体xi 的匹配缺乏足够证据,总体判断不稳定。前面讲过,ui 高通常意味着证据不足,因此这类样本被认为是"不可靠的",很可能是噪声样本,或者至少是很难判断的样本。
第二类是noisy portion with low consensus,记作
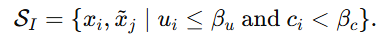
这类样本的特点是:虽然不确定性不高,也就是模型看起来"挺有把握",但 consensus 低,说明模型当前的高置信并没有落在真实标注对应上。这类样本很危险,因为它们属于"自信但可能错"。所以作者也把它们当作 noisy portion。
第三类是clean portion,记作
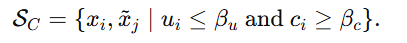
这类样本既满足低不确定性,又满足高 consensus。也就是说:模型有足够证据;而且这些证据与标注对应是相一致的。所以这一类才被看作相对干净、可信的样本。
接下来是阈值 βu 和 βc 怎么取。作者想用这两个阈值,把样本分成高 uncertainty、低 consensus、clean 三类。作者不是手工固定,而是做了self-adaptive 设定:
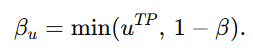
它表示:uncertainty 的阈值取两个值里较小的那个:
- 一个是当前正确样本中最大的 uncertainty,uTP;
- 一个是人为设置的上界 1−β。
- 如果某个样本的 uncertainty 比这个阈值还大,就说明它比"正常预测正确样本里最差的情况"还要更不确定,那它就比较可疑,应该被划进高 uncertainty 集合里。
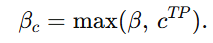
它表示:consensus 的阈值取两个值里较大的那个:
- 一个是人为设定的下界 β;
- 一个是当前正确样本中最小的 consensus,cTP。
- 如果一个样本的 consensus 连"正确样本里的最低水平"都达不到,或者甚至低于一个基本下界 β,那它就不能被看作可靠。
文中定义:
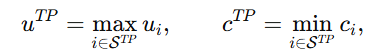
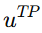 是在所有 true positive 样本里,取 最大的 uncertainty 。它表示:连那些已经预测对的样本里,最不确定的那个样本,不确定性有多大。
是在所有 true positive 样本里,取 最大的 uncertainty 。它表示:连那些已经预测对的样本里,最不确定的那个样本,不确定性有多大。
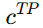 是在所有 true positive 样本里,取 最小的 consensus 。它表示:连那些已经预测对的样本里,共识最低的那个样本,共识值有多小。
是在所有 true positive 样本里,取 最小的 consensus 。它表示:连那些已经预测对的样本里,共识最低的那个样本,共识值有多小。
并且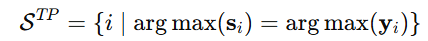 表示 true positive pairs 的集合,也就是那些"当前模型预测的最佳候选,恰好等于真实标注"的样本。
表示 true positive pairs 的集合,也就是那些"当前模型预测的最佳候选,恰好等于真实标注"的样本。
稳健的图间差异消除(discrepancy elimination)
作者后面想做一种"跨图表示对齐/差异消除"的训练,让匹配实体在表示空间里更一致、差异更小。但如果某个匹配对本来就很可疑,你再强行把它们往一起拉,可能会把表示空间学坏。
SU 里的样本因为 uncertainty 很高 ,说明模型对这些样本的判断本身就缺乏足够证据,所以作者认为它们是不可靠的 ,直接不让它们参与后续的 discrepancy elimination。
SI 里的样本表面上并不缺证据,模型看起来甚至还挺自信,但 consensus 低,说明模型当前支持的并不是标注对应关系,而可能是别的候选实体。所以它们也不能被简单看作 reliable pairs。
正因为 SU、SI、SC 三类样本的可靠性完全不同,所以作者提出一个 Dually Robust Learning, DRL ,针对这三类样本采用不同的处理策略,从而提高模型对跨图噪声对应关系的鲁棒性。
然后作者给出总体目标函数:
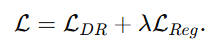
表示总损失由两部分组成。
第一部分是LDR 也就是 dually robust loss 。这是主损失,负责真正实现对不同样本类型的鲁棒学习。
第二部分是 LReg 也就是 regularization loss,正则项。它通常用来约束模型不要学得过于极端、过于自信,或者保持 evidential parameters 的合理性。
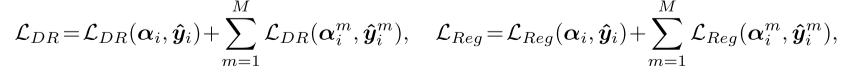
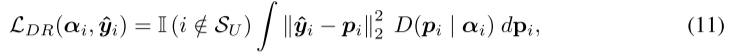
- 对于实体 xi ,模型不是直接输出一个固定概率向量,而是输出一个 Dirichlet 分布 D(pi∣αi) 。这里 pi 是一个"随机的类别概率向量",也就是:
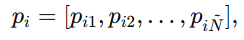 它表示" xi 与每个候选实体匹配的概率分布"。
它表示" xi 与每个候选实体匹配的概率分布"。 - αi是这个 Dirichlet 分布的参数,控制它的均值和不确定性。
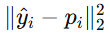 是欧氏距离平方,也就是均方误差型目标。它衡量的是:从 Dirichlet 分布中取出来的一个概率向量 pi ,与目标y^i相差多远。
是欧氏距离平方,也就是均方误差型目标。它衡量的是:从 Dirichlet 分布中取出来的一个概率向量 pi ,与目标y^i相差多远。- 它约束的是 Dirichlet 分布的均值 要接近目标y^i。
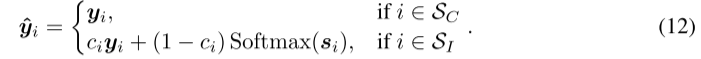
其中 y^i 就是 refined label ,也就是"修正后的标签"。ci 是 consensus,表示当前标注对应得到的支持程度。如果样本属于低共识集合SI ,作者就不再直接用原始 one-hot 标签 yi 了,而是把它和模型当前的相似度分布做加权融合。
可以这样理解这个设计:
对 SC 样本,作者说"这类样本大概率是干净的,直接信标签"。
对SI样本,作者说"这类样本标签可能有问题,因此不要全信标签,要让标签和当前模型判断折中一下"。
对 SU样本,作者说"这类样本太不确定,先别拿它训练"。
式 (11) 主要是在鼓励"可靠对应关系"产生更高证据,让预测分布靠近 refined label (式子12)。但它并没有显式保证"那些不相关的候选实体"一定只能产生很少的证据。
于是有式 (13):
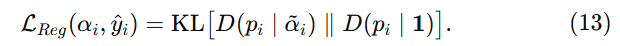
关键就在于
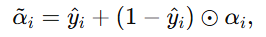
其中 ⊙ 表示逐元素乘法。
比如"极端情况"
当 y^ij=1 时: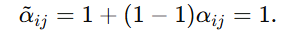 目标维直接被置为 1。
目标维直接被置为 1。
当 y^ij=0 时: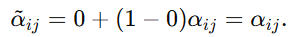 非目标维完全保留。
非目标维完全保留。
这里的 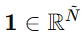 是全 1 向量,因此
是全 1 向量,因此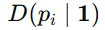 就是一个均匀 Dirichlet 分布。它对应的语义是:没有额外证据支持任何类别。所以它就是一个"无信息先验"或"无偏先验"。
就是一个均匀 Dirichlet 分布。它对应的语义是:没有额外证据支持任何类别。所以它就是一个"无信息先验"或"无偏先验"。
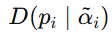 它是根据当前样本构造出来的"改造版预测分布",里面保留了非目标类上的证据。
它是根据当前样本构造出来的"改造版预测分布",里面保留了非目标类上的证据。
计算它们的KL 散度是指:拿两个概率分布作比较,计算它们有多不一样,并把这个差异当成损失项来优化。这里的意思是让当前这个改造后的 Dirichlet 分布,尽量接近"无额外证据"的均匀先验。
稳健的实体内属性融合
作者前面已经为不同层面的对应关系估计了可靠性,现在就可以把某个属性对应关系的可靠性记为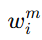 ,然后在实体内部做属性融合时,把这个可靠性当成权重。
,然后在实体内部做属性融合时,把这个可靠性当成权重。
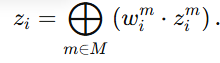
测试时对应推理
到了推理时,仍然可能遇到一种困难:**有些属性看起来很像,但其实只是表面相似,它们会干扰真正等价实体的识别。**所以作者又加了一个专门在测试时使用的模块,叫做:Test-time correspondence Reasoning (TTR),它的目标不是重新训练模型,而是在推理阶段进一步利用属性级对应关系做一次"推理增强",从而把最终的实体匹配结果修正得更准确。

最终实体匹配分数 = 各个属性相似度分数的加权和。
其中:
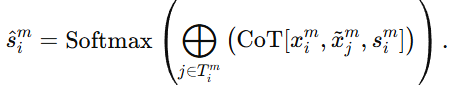
作者不满足于直接使用原来的属性相似度 sim ,因为那可能只是浅层匹配结果。于是他们引入了一个 MLLM ,并让它对一组候选属性对应关系做推理。这里的推理不是简单打分,而是让 MLLM 按照 CoT,也就是 Chain-of-Thought,逐步分析。
下面逐个看符号:
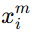 表示实体 xi 的第 m个属性。
表示实体 xi 的第 m个属性。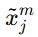 表示另一张图中第 j 个候选实体的第 m 个属性。
表示另一张图中第 j 个候选实体的第 m 个属性。- 这里的
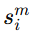 含义变成:对于实体 xi 的第 m 个属性,拿它去和另一张图中各个候选实体的第 m 个属性分别比较,得到一组属性级相似度:
含义变成:对于实体 xi 的第 m 个属性,拿它去和另一张图中各个候选实体的第 m 个属性分别比较,得到一组属性级相似度: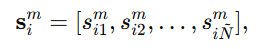
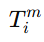 表示第 m 个属性下的一组候选对应集合。意思是:作者不会把所有候选都丢给 MLLM 去推理,而是先根据已有的属性相似度 sim,挑出一批最相近的候选对应关系,构成集合
表示第 m 个属性下的一组候选对应集合。意思是:作者不会把所有候选都丢给 MLLM 去推理,而是先根据已有的属性相似度 sim,挑出一批最相近的候选对应关系,构成集合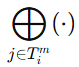 表示把这些候选对应的 CoT 推理结果拼接或汇总起来。最后再经过Softmax(⋅)得到一个归一化后的属性级相似度分布
表示把这些候选对应的 CoT 推理结果拼接或汇总起来。最后再经过Softmax(⋅)得到一个归一化后的属性级相似度分布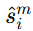 ,再通过式 (15) 和其他属性一起加权融合,形成最终实体相似度
,再通过式 (15) 和其他属性一起加权融合,形成最终实体相似度 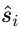
最后得到联合相似度向量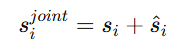
最终预测的候选实体下标