损失函数
-
0-1 损失函数
公式:L(Y,f(x))={1,Y≠f(x)0,Y=f(x)L(Y, f(x)) = \begin{cases} 1, & Y \neq f(x) \\ 0, & Y = f(x) \end{cases}L(Y,f(x))={1,0,Y=f(x)Y=f(x)
这是最直观的分类损失函数,仅关注预测结果是否正确。如果预测类别与真实类别一致,损失为0;否则为1。虽然它直接对应分类准确率,但由于它是非连续、非凸且不可导的离散函数,无法直接使用梯度下降法进行优化,因此在实际训练深层模型时,通常使用对数损失或Hinge损失等作为其代理函数。
-
绝对损失函数
公式:L(Y,f(x))=∣Y−f(x)∣L(Y, f(x)) = |Y - f(x)|L(Y,f(x))=∣Y−f(x)∣
计算预测值与真实值之间差值的绝对值。与平方损失相比,绝对值损失不会对较大的误差进行平方放大,因此对数据中的异常值具有更好的鲁棒性。它的梯度是恒定的(除了零点不可导),这意味着无论误差大小,参数更新的步长相对稳定,适合处理含有噪声的数据集。
-
平方损失函数
公式:L(Y,f(x))=(Y−f(x))2L(Y, f(x)) = (Y - f(x))^2L(Y,f(x))=(Y−f(x))2
通过计算误差的平方来衡量差异。平方操作使得较大的误差会被显著放大,这促使模型在训练过程中优先修正那些偏离严重的样本。该函数是连续可导的凸函数,拥有全局最优解,数学性质非常优良。但在数据包含大量异常值时,模型容易受到干扰而产生过拟合。
-
指数损失函数
公式:L(Y,f(x))=e−Yf(x)L(Y, f(x)) = e^{-Y f(x)}L(Y,f(x))=e−Yf(x)
主要用于集成学习中的 Boosting 算法(如 AdaBoost)。当预测值与真实标签符号相反(即分类错误)时,指数项会迅速增大,导致损失急剧上升。这种特性使得算法在迭代过程中会赋予被错分的样本更高的权重,迫使后续的弱分类器更加关注这些"难分"样本,从而不断提升整体模型的准确率。
-
Hinge 损失函数
公式:L(Y,f(x))=max(0,1−Yf(x))L(Y, f(x)) = \max(0, 1 - Y f(x))L(Y,f(x))=max(0,1−Yf(x))
不仅要求样本被正确分类,还要求分类的置信度足够大。当样本被正确分类且距离决策边界足够远时,损失为0;否则产生线性惩罚。这种机制使得支持向量机能够最大化分类间隔,从而获得更好的泛化能力。只有靠近边界的样本(支持向量)才会对损失产生贡献。
-
对数损失函数
公式:L(Y,P(Y∣X))=−logP(Y∣X)L(Y, P(Y|X)) = -\log P(Y|X)L(Y,P(Y∣X))=−logP(Y∣X)
基于极大似然估计推导而来,用于衡量预测概率分布与真实分布的差异。它要求模型输出的不仅仅是类别,而是属于该类别的概率。当预测概率接近真实标签时,损失趋近于0;反之,如果预测概率与真实标签背道而驰,损失将趋向于无穷大,从而对错误的预测施加严厉惩罚。
-
交叉熵损失
公式:C=−1n∑ylog(y\^)+(1−y)log(1−y\^)C = -\frac{1}{n} \sum y \\log(\\hat{y}) + (1-y) \\log(1-\\hat{y})C=−n1∑ylog(y\^)+(1−y)log(1−y\^)
这是信息论中衡量两个概率分布差异的指标,在二分类问题中应用极广。其中 yyy 是真实标签(0或1),y^\hat{y}y^ 是模型预测为正类的概率。交叉熵损失本质上与对数损失一致,它能够很好地配合 Sigmoid 或 Softmax 激活函数,在梯度下降时避免出现梯度消失的问题,加速模型收敛。
-
L1 损失
公式:loss(x,y)=1n∑i=1n∣yi−f(xi)∣\text{loss}(x, y) = \frac{1}{n} \sum_{i=1}^{n} |y_i - f(x_i)|loss(x,y)=n1∑i=1n∣yi−f(xi)∣
即所有样本绝对误差的平均值,也就是平均绝对误差。它反映了预测值与真实值之间误差的实际情况。由于没有平方项,L1 损失对异常值不敏感,具有稀疏性解的特性(常配合正则化使用)。但在 y=f(x)y=f(x)y=f(x) 处导数不连续,优化时可能需要使用次梯度方法。
-
L2 损失
公式:loss(x,y)=1n∑i=1n(yi−f(xi))2\text{loss}(x, y) = \frac{1}{n} \sum_{i=1}^{n} (y_i - f(x_i))^2loss(x,y)=n1∑i=1n(yi−f(xi))2
即所有样本平方误差的平均值,也就是均方误差的一种形式。L2 损失函数处处可导且光滑,便于使用梯度下降等优化算法求解。它假设误差服从高斯分布,但在面对非高斯分布或含有离群点的数据时,由于平方项放大了大误差的影响,模型的稳定性不如 L1 损失。
-
均方误差
公式:J(w,b)=12m∑i=1m(ai−yi)2J(w, b) = \frac{1}{2m} \sum_{i=1}^{m} (a_i - y_i)^2J(w,b)=2m1∑i=1m(ai−yi)2
这是线性回归中常用的目标函数形式。其中 aia_iai 为预测值,yiy_iyi 为真实值,mmm 为样本总数。公式前的系数 12\frac{1}{2}21 是为了在求导时,利用幂函数的求导法则抵消平方项产生的系数 2,从而简化梯度的表达式,使参数更新公式更加整洁,不影响优化的最终结果。
求解算法
-
梯度下降法
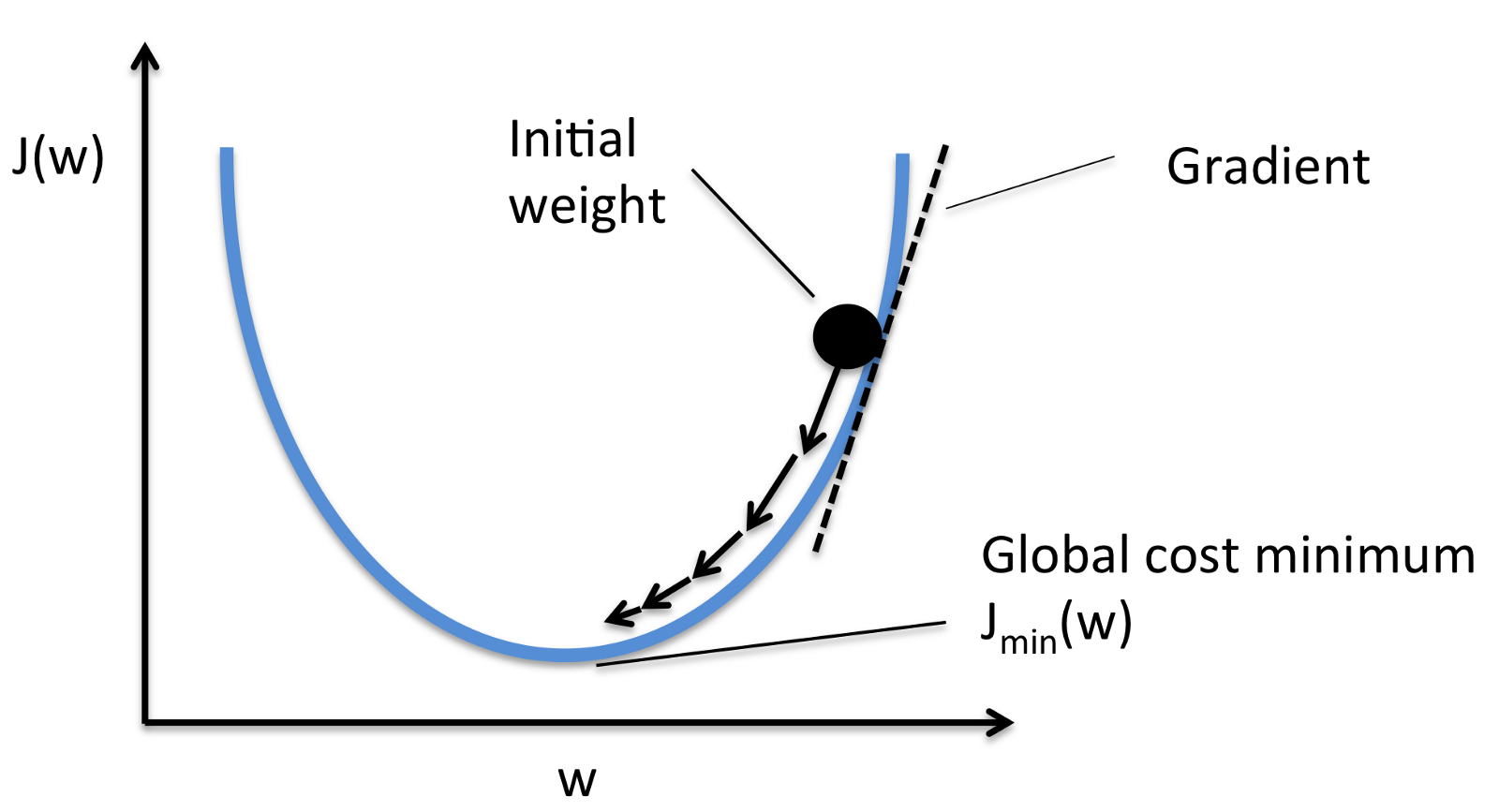
公式:∇L(w,b)=(∂L∂w,∂L∂b)\nabla L(w, b) = (\frac{\partial L}{\partial w}, \frac{\partial L}{\partial b})∇L(w,b)=(∂w∂L,∂b∂L)
这是最基础的迭代优化算法。形象地说,就像一个人被困在山上(损失函数的高点),为了最快下山(找到最小值),他每一步都沿着当前位置最陡峭的方向(负梯度方向)走。根据每次更新使用的样本量不同,可分为批量梯度下降、随机梯度下降和小批量梯度下降。
-
牛顿法
公式(Hessian 矩阵):H(f)=∇2f(x)=∂2f∂x12⋯∂2f∂x1∂xn⋮⋱⋮∂2f∂xn∂x1⋯∂2f∂xn2H(f) = \nabla^2 f(x) = \begin{bmatrix} \frac{\partial^2 f}{\partial x_1^2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial^2 f}{\partial x_n \partial x_1} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \end{bmatrix}H(f)=∇2f(x)= ∂x12∂2f⋮∂xn∂x1∂2f⋯⋱⋯∂x1∂xn∂2f⋮∂xn2∂2f
牛顿法不仅利用了梯度(一阶导数,切线斜率),还利用了 Hessian 矩阵(二阶导数,曲率信息)。它通过二阶泰勒展开来拟合目标函数,相当于用曲面去逼近函数。因此,牛顿法通常比梯度下降收敛速度更快(二次收敛),但计算 Hessian 矩阵及其逆矩阵的开销非常大。
-
阻尼牛顿法
这是对经典牛顿法的改进。经典牛顿法在步长选择不当时可能导致函数值不降反升。阻尼牛顿法在牛顿方向确定后,引入了一维搜索来确定最佳步长,或者加入一个阻尼因子,确保每次迭代都能使目标函数值下降,从而提高了算法的全局收敛性和稳定性。
-
拟牛顿法
为了解决牛顿法计算 Hessian 矩阵及其逆矩阵成本过高的问题,拟牛顿法(如 BFGS、L-BFGS)通过构造一个正定矩阵来近似 Hessian 矩阵的逆。它只需要利用一阶导数信息,就能达到接近牛顿法的收敛速度,同时大大降低了计算复杂度,是实际应用中非常高效的优化算法。
线性回归
-
普通线性回归
公式(R-squared):Score=1−∑(yi−y^i)2∑(yi−yˉ)2Score = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2}Score=1−∑(yi−yˉ)2∑(yi−y^i)2
R2R^2R2 决定了系数,用于评估回归模型的拟合优度。分子是残差平方和(模型未能解释的变异),分母是总离差平方和(数据本身的总变异)。R2R^2R2 越接近 1,说明模型解释了数据中大部分的波动,拟合效果越好;越接近 0,说明模型拟合效果越差。
-
Lasso 回归
公式(正则项):α∥w∥1,α≥0\alpha \|w\|_1, \alpha \ge 0α∥w∥1,α≥0
Lasso 在普通线性回归的损失函数中加入了权重向量的 L1 范数作为惩罚项。L1 正则化的特性是倾向于产生稀疏解,即它可以将许多不重要的特征对应的权重压缩为严格的 0。因此,Lasso 回归不仅可以防止过拟合,还能进行特征选择,自动筛选出对预测最有用的特征。
-
岭回归
公式(正则项):α∥w∥22,α≥0\alpha \|w\|_2^2, \alpha \ge 0α∥w∥22,α≥0
岭回归在损失函数中加入了权重向量的 L2 范数平方作为惩罚项。它通过限制权重的大小,防止模型参数过大导致的过拟合。与 Lasso 不同,岭回归会将权重压缩得很小但不会为 0,因此它保留了所有特征,适合处理特征之间存在多重共线性的问题,能提高模型的稳定性。
-
弹性网络回归
公式(正则项):αρ∥w∥1+α(1−ρ)2∥w∥22,α≥0,1≥ρ≥0\alpha \rho \|w\|_1 + \frac{\alpha(1-\rho)}{2} \|w\|_2^2, \alpha \ge 0, 1 \ge \rho \ge 0αρ∥w∥1+2α(1−ρ)∥w∥22,α≥0,1≥ρ≥0
弹性网络结合了 Lasso 和岭回归的优点。它同时包含 L1 和 L2 正则项,通过超参数 ρ\rhoρ 来调节两者的比例。当特征数量远大于样本数量,或者特征之间存在强相关性时,弹性网络通常比单独使用 Lasso 或岭回归表现更好,既能进行特征选择,又能保持模型的稳定性。
聚类分析
一种无监督学习方法,目标是将数据划分为若干个簇。其核心思想是使得同一簇内的样本相似度高,而不同簇之间的样本相似度低。常见的聚类算法包括 K-Means、层次聚类等,常用于市场细分、社交网络分析等。
-
欧氏距离
公式:d=∑k=1n(x1k−x2k)2=(α⃗−β⃗)(α⃗−β⃗)Td = \sqrt{\sum_{k=1}^{n} (x_{1k} - x_{2k})^2} = \sqrt{(\vec{\alpha} - \vec{\beta})(\vec{\alpha} - \vec{\beta})^T}d=∑k=1n(x1k−x2k)2 =(α −β )(α −β )T
最常见的距离度量,即空间中两点间的直线距离。它计算的是各维度数值差的平方和的平方根,符合人们对几何距离的直观认知。
-
标准化欧氏距离
公式(标准化):X∗=X−μSX^* = \frac{X - \mu}{S}X∗=SX−μ d=∑k=1n(x1k−x2kSk)2d = \sqrt{\sum_{k=1}^{n} ({\frac{x_{1k} - x_{2k}}{S_k}})^2}d=∑k=1n(Skx1k−x2k)2
针对普通欧氏距离受量纲影响的缺点,先将数据标准化(减去均值除以标准差)再计算距离。这种方法消除了不同维度量纲和方差的影响,使得各个特征在距离计算中具有平等的地位。
-
曼哈顿距离
公式:d=∑k=1n∣x1k−x2k∣d = \sum_{k=1}^{n} |x_{1k} - x_{2k}|d=∑k=1n∣x1k−x2k∣
也称为城市街区距离。它计算的是在标准坐标系上,两点在各个维度上绝对轴距的总和。想象你在棋盘式的城市街道中从一个路口走到另一个路口,只能沿街道直角转弯行走,所经过的最短路径长度就是曼哈顿距离。
-
切比雪夫距离
公式:d=maxi(∣x1i−x2i∣)=limk→∞(∑i=1n∣x1i−x2i∣k)1kd = \max_{i} (|x_{1i} - x_{2i}|) = \lim_{k \to \infty} (\sum_{i=1}^{n} |x_{1i} - x_{2i}|^k)^{\frac{1}{k}}d=maxi(∣x1i−x2i∣)=limk→∞(∑i=1n∣x1i−x2i∣k)k1
各坐标数值差的最大值。在国际象棋中,国王从一个格子走到另一个格子所需的最少步数就是切比雪夫距离,因为国王可以向周围8个方向移动。它关注的是维度间差异最大的那个分量。
-
闵可夫斯基距离
公式:d=∑k=1n(x1k−x2k)ppd = \sqrtp{\sum_{k=1}^{n} (x_{1k} - x_{2k})^p}d=p∑k=1n(x1k−x2k)p
这是一组距离的通用定义,不是指某一个特定的距离。通过调整参数 ppp 的值,它可以演变成不同的距离度量:当 p=1p=1p=1 时为曼哈顿距离;当 p=2p=2p=2 时为欧氏距离;当 p=3p=3p=3 时,则为切比雪夫距离。
-
余弦距离
公式:cosθ=A⃗⋅B⃗∥A⃗∥∥B⃗∥=∑k=1nx1kx2k∑k=1nx1k2∑k=1nx2k2\cos\theta = \frac{\vec{A} \cdot \vec{B}}{\|\vec{A}\| \|\vec{B}\|} = \frac{\sum_{k=1}^{n} x_{1k} x_{2k}}{\sqrt{\sum_{k=1}^{n} x_{1k}^2} \sqrt{\sum_{k=1}^{n} x_{2k}^2}}cosθ=∥A ∥∥B ∥A ⋅B =∑k=1nx1k2 ∑k=1nx2k2 ∑k=1nx1kx2k
通过计算两个向量夹角的余弦值来衡量相似度。余弦值越接近 1,夹角越小,相似度越高。与欧氏距离关注数值大小的差异不同,余弦距离更关注向量在方向上的差异,常用于文本分类、信息检索中衡量文档的相似性。
-
马氏距离
公式:D(x)=(x−μ)TS−1(x−μ)D(x) = \sqrt{(x-\mu)^T S^{-1} (x-\mu)}D(x)=(x−μ)TS−1(x−μ) D(xi⃗,xj⃗)=(xi⃗−xj⃗)TS−1(xi⃗−xj⃗)D(\vec{x_i}, \vec{x_j}) = \sqrt{(\vec{x_i} - \vec{x_j})^T S^{-1} (\vec{x_i} - \vec{x_j})}D(xi ,xj )=(xi −xj )TS−1(xi −xj )
一种考虑了数据分布特性的距离度量。其中 SSS 是协方差矩阵。马氏距离排除了变量之间相关性的干扰,并且不受量纲(单位)的影响。它表示一个点与一个分布中心的距离,常用于异常点检测和分类任务。
-
海明距离
公式:dH(x,y)=∑i=1nxi≠yid_H(x, y) = \sum_{i=1}^{n} x_i \\neq y_idH(x,y)=∑i=1nxi=yi
主要用于衡量两个等长字符串(通常是二进制串)之间的差异。它定义为将一个字符串变换成另一个字符串所需要替换的字符个数。例如,1011101 和 1001001 的海明距离是 2。在编码理论和信息论中应用广泛。
-
杰卡德距离
公式(杰卡德相似系数):J(A,B)=∣A∩B∣∣A∪B∣J(A, B) = \frac{|A \cap B|}{|A \cup B|}J(A,B)=∣A∪B∣∣A∩B∣
公式(杰卡德距离):J′(A,B)=1−J(A,B)=∣A∪B∣−∣A∩B∣∣A∪B∣J'(A, B) = 1 - J(A, B) = \frac{|A \cup B| - |A \cap B|}{|A \cup B|}J′(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣
基于杰卡德相似系数。相似系数是两个集合交集大小与并集大小的比值。杰卡德距离则用 1 减去相似系数,用来衡量两个集合的不相似度。它非常适合处理符号度量或布尔值度量的数据,如计算两个用户购买商品的集合差异。
-
相关距离
公式(相关系数):ρXY=Cov(X,Y)D(X)D(Y)=E{X−E(X)Y−E(Y)}D(X)D(Y)\rho_{XY} = \frac{Cov(X, Y)}{\sqrt{D(X)}\sqrt{D(Y)}} = \frac{E\{X-E(X)Y-E(Y)\}}{\sqrt{D(X)}\sqrt{D(Y)}}ρXY=D(X) D(Y) Cov(X,Y)=D(X) D(Y) E{X−E(X)Y−E(Y)}
公式(相关距离):DXY=1−ρXYD_{XY} = 1 - \rho_{XY}DXY=1−ρXY
基于皮尔逊相关系数。相关系数衡量的是两个变量之间的线性相关程度,取值在 -1, 1 之间。相关距离通过 1−ρ1 - \rho1−ρ 将相关性转化为距离度量。如果两个变量完全正相关,距离为 0;如果完全不相关或负相关,距离则较大。
-
信息熵
公式:Entropy(X)=−∑i=1npilogpiEntropy(X) = -\sum_{i=1}^{n} p_i \log p_iEntropy(X)=−∑i=1npilogpi
信息熵是衡量系统不确定性或混乱程度的指标。熵越大,系统的不确定性越高,包含的信息量越大;熵越小,系统越有序。在决策树算法中,通过计算信息增益(熵的减少量)来选择最优的特征进行分裂。
卷积神经网络卷积后尺寸计算
公式:Output=Input−Kernel+2×PaddingStride+1Output = \frac{Input - Kernel + 2 \times Padding}{Stride} + 1Output=StrideInput−Kernel+2×Padding+1
是计算卷积层输出特征图尺寸的通用公式。其中 Input 为输入图像的尺寸,Kernel 为卷积核的尺寸,Padding 为在输入边缘填充的像素层数,Stride 为卷积核滑动的步长。该公式确保了在网络设计时,能够精确控制每一层输出数据的维度。