引言
在大模型(LLM)向推理模型(Reasoning Models)演进的过程中,DeepSeek-R1 的成功证明了 纯强化学习(RL) 在复杂逻辑空间内诱导 "涌现" 能力的巨大潜力。然而,R1 表现出的自我反思与逻辑校验,其底层逻辑与 60 年前诞生的经典控制问题并无二致。本文将通过一个经典且简单的回归强化学习的游戏------CartPole(倒倒立摆),来设计一个基于 PyTorch 的 DQN 智能体,拆解"推理能力"是如何在不确定性中试错收敛的。
一、 CartPole 为何是经典推理任务游戏?
CartPole 的目标任务是要求智能体在水平移动的推车上维持杆子垂直不掉落,类似人头顶花瓶的稳定性。尽管CartPole 任务目标简单,但它构建了一个标准的马尔可夫决策过程(MDP) ,其核心逻辑与现如今的大语言模型的思维链(CoT)训练高度一致性。
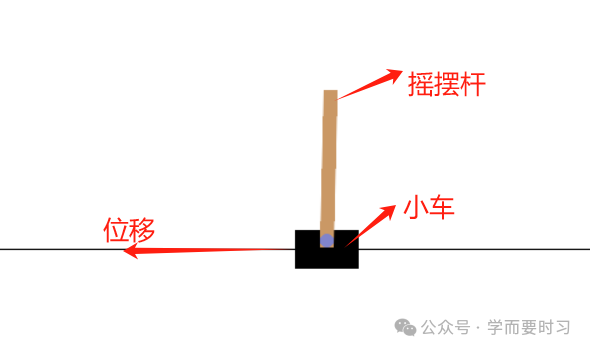
1.1 关系分析
| 维度 | DeepSeek-R1 (Reasoning RL) | CartPole (Classical DQN) | 技术本质 |
|---|---|---|---|
| 状态空间 (State) | 数千 Token 的上下文序列 | 四维向量(位置、速度、角度、角速度) | 环境信息的特征表示 |
| 动作空间 (Action) | 词表规模的 Token 选择(Next Token) | 离散动作(左推 / 右推) | 策略输出的决策边界 |
| 奖励机制 (Reward) | 结果正确性(准确性奖励 + 语言一致性) | 生存步数(每步 +1,倒下为 0) | 延迟反馈的信号稀疏性 |
| 核心挑战 | 逻辑链条的长程依赖(Credit Assignment) | 物理惯性的延迟响应 | 解决信用分配问题 |
1.2 "顿悟"的本质
DeepSeek-R1 在训练中出现的"Aha Moment",在 CartPole 训练中表现为收敛曲线的阶跃。当智能体通过不断试错,识别出"微调推车速度"与"维持长周期平衡"之间的因果关系时,本质上就是模型在策略空间中找到了最优解。
二、 实战架构:构建稳定型深度 Q 网络 (DQN)
在复杂的 RL 环境中,原生 DQN 极易因 Q 值过拟合导致训练崩溃。为了模拟 R1 级别的稳定性,我们在实现中引入相关的模型改进与优化。
2.1 网络拓扑结构
针对 4 维输入与 2 维输出,采用多层感知机(MLP)构建决策大脑。
python
# 经验最优配置:4 -> 128 -> 128 -> 2
self.policy_net = nn.Sequential(
nn.Linear(4, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 2)
)2.2 提升策略鲁棒性的核心技巧
-
双重网络架构 (Double DQN) :
DeepSeek-R1 使用组内对比(GRPO)来消除偏差,而 DQN 通过设置 Policy Net(动作选择) 与 Target Net(价值评估) 解耦。这解决了 QQQ 学习中常见的"过度自信"问题。
Qtarget=R+γQtarget(s′,argmaxa′Qpolicy(s′,a′))Q_{target} = R + \gamma Q_{target}(s', \text{argmax}{a'} Q{policy}(s', a'))Qtarget=R+γQtarget(s′,argmaxa′Qpolicy(s′,a′)) -
软更新机制 (Soft Update) :
为了避免权重更新过快导致的震荡,引入 Polyak 平均(参数 τ≈0.005\tau \approx 0.005τ≈0.005),使模型在保持稳定性的同时平滑演进。
-
梯度裁剪 (Gradient Clipping) :
在大规模强化学习中,异常梯度是训练失控的主因。将梯度范数限制在 0,100, 100,10 之间,可以保证模型不会跑偏。
-
经验回放 (Replay Buffer) :
打破数据间的时序相关性,类似于让模型"复习"不同场景下的决策得失,从而提升样本效率。
2.3 训练代码
c
import torch
import torch.nn as nn
import torch.optim as optim
import gymnasium as gym
from collections import deque
import random
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation
torch.manual_seed(42)
np.random.seed(42)
class StableDQN(nn.Module):
def __init__(self):
super(StableDQN, self).__init__()
self.net = nn.Sequential(
nn.Linear(4, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 2)
)
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
nn.init.constant_(m.bias, 0)
def forward(self, x):
return self.net(x)
class ReplayBuffer:
def __init__(self, capacity=50000):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size=64):
batch = random.sample(self.buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
return (
torch.FloatTensor(np.array(states)),
torch.LongTensor(np.array(actions)),
torch.FloatTensor(np.array(rewards)),
torch.FloatTensor(np.array(next_states)),
torch.FloatTensor(np.array(dones))
)
def __len__(self):
return len(self.buffer)
class StableDQNTrainer:
def __init__(self):
self.env = gym.make('CartPole-v1')
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.policy_net = StableDQN().to(self.device)
self.target_net = StableDQN().to(self.device)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=0.0002)
self.memory = ReplayBuffer(50000)
self.batch_size = 64
self.gamma = 0.99
self.epsilon = 1.0
self.epsilon_decay = 0.995
self.epsilon_min = 0.01
self.tau = 0.005 # 软更新系数
self.total_steps = 0
self.episode_rewards = []
self.epsilon_history = []
self.losses = []
def select_action(self, state):
if random.random() < self.epsilon:
return self.env.action_space.sample()
else:
with torch.no_grad():
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
q_values = self.policy_net(state)
return q_values.argmax().item()
def train_step(self):
if len(self.memory) < self.batch_size:
return 0.0
states, actions, rewards, next_states, dones = self.memory.sample(self.batch_size)
states, actions, rewards = states.to(self.device), actions.to(self.device), rewards.to(self.device)
next_states, dones = next_states.to(self.device), dones.to(self.device)
current_q = self.policy_net(states).gather(1, actions.unsqueeze(1)).squeeze()
with torch.no_grad():
next_actions = self.policy_net(next_states).argmax(1)
next_q = self.target_net(next_states).gather(1, next_actions.unsqueeze(1)).squeeze()
target_q = rewards + self.gamma * next_q * (1 - dones)
loss = nn.MSELoss()(current_q, target_q)
self.optimizer.zero_grad()
loss.backward()
# 增加梯度裁剪防止更新过大
torch.nn.utils.clip_grad_norm_(self.policy_net.parameters(), max_norm=10.0)
self.optimizer.step()
self.total_steps += 1
self._soft_update() # 软更新
return loss.item()
def _soft_update(self):
for target_param, policy_param in zip(self.target_net.parameters(), self.policy_net.parameters()):
target_param.data.copy_(self.tau * policy_param.data + (1.0 - self.tau) * target_param.data)
def run_episode(self):
state, _ = self.env.reset()
total_reward = 0
episode_losses = []
while True:
action = self.select_action(state)
next_state, reward, terminated, truncated, _ = self.env.step(action)
done = terminated or truncated
self.memory.push(state, action, reward, next_state, done)
loss = self.train_step()
if loss > 0: episode_losses.append(loss)
total_reward += reward
state = next_state
if done: break
self.losses.append(np.mean(episode_losses) if episode_losses else 0)
return total_reward
def train(self, num_episodes=1000):
for episode in range(num_episodes):
reward = self.run_episode()
self.episode_rewards.append(reward)
self.epsilon_history.append(self.epsilon)
self.epsilon = max(self.epsilon_min, self.epsilon * self.epsilon_decay)
if (episode + 1) % 10 == 0:
avg_reward = np.mean(self.episode_rewards[-100:])
print(f"Episode {episode + 1:4d} | 100轮均分: {avg_reward:6.1f} | ε: {self.epsilon:.3f}")
if avg_reward >= 475: break
self.plot_results()
self.save_model()
return self.episode_rewards
def plot_results(self):
plt.figure(figsize=(15, 4))
plt.subplot(1, 3, 1)
plt.plot(self.episode_rewards, alpha=0.3)
if len(self.episode_rewards) >= 100:
ma100 = np.convolve(self.episode_rewards, np.ones(100)/100, mode='valid')
plt.plot(range(99, len(self.episode_rewards)), ma100, 'r-')
plt.title('Training Reward')
plt.subplot(1, 3, 2)
plt.plot(self.epsilon_history)
plt.title('Epsilon')
plt.subplot(1, 3, 3)
plt.plot(self.losses)
plt.title('Loss')
plt.tight_layout()
plt.show()
def save_model(self):
torch.save(self.policy_net.state_dict(), 'stable_dqn.pth')
def evaluate(self, episodes=10):
for ep in range(episodes):
state, _ = self.env.reset()
total_reward = 0
while True:
with torch.no_grad():
state_tensor = torch.FloatTensor(state).unsqueeze(0).to(self.device)
action = self.policy_net(state_tensor).argmax().item()
state, reward, terminated, truncated, _ = self.env.step(action)
total_reward += reward
if terminated or truncated: break
print(f"评估第{ep + 1}局: {total_reward}")
if __name__ == "__main__":
trainer = StableDQNTrainer()
trainer.train(num_episodes=200)
trainer.evaluate(episodes=5)三、 可视化分析:透视 AI 的"潜意识"决策
训练后的模型仅仅只是一个权重文件,我们无法去非常直观的感受AI的相关控制,我们通过设计可视化工具,可以观察到 AI 是如何产生"物理直觉"去控制小车运行的。
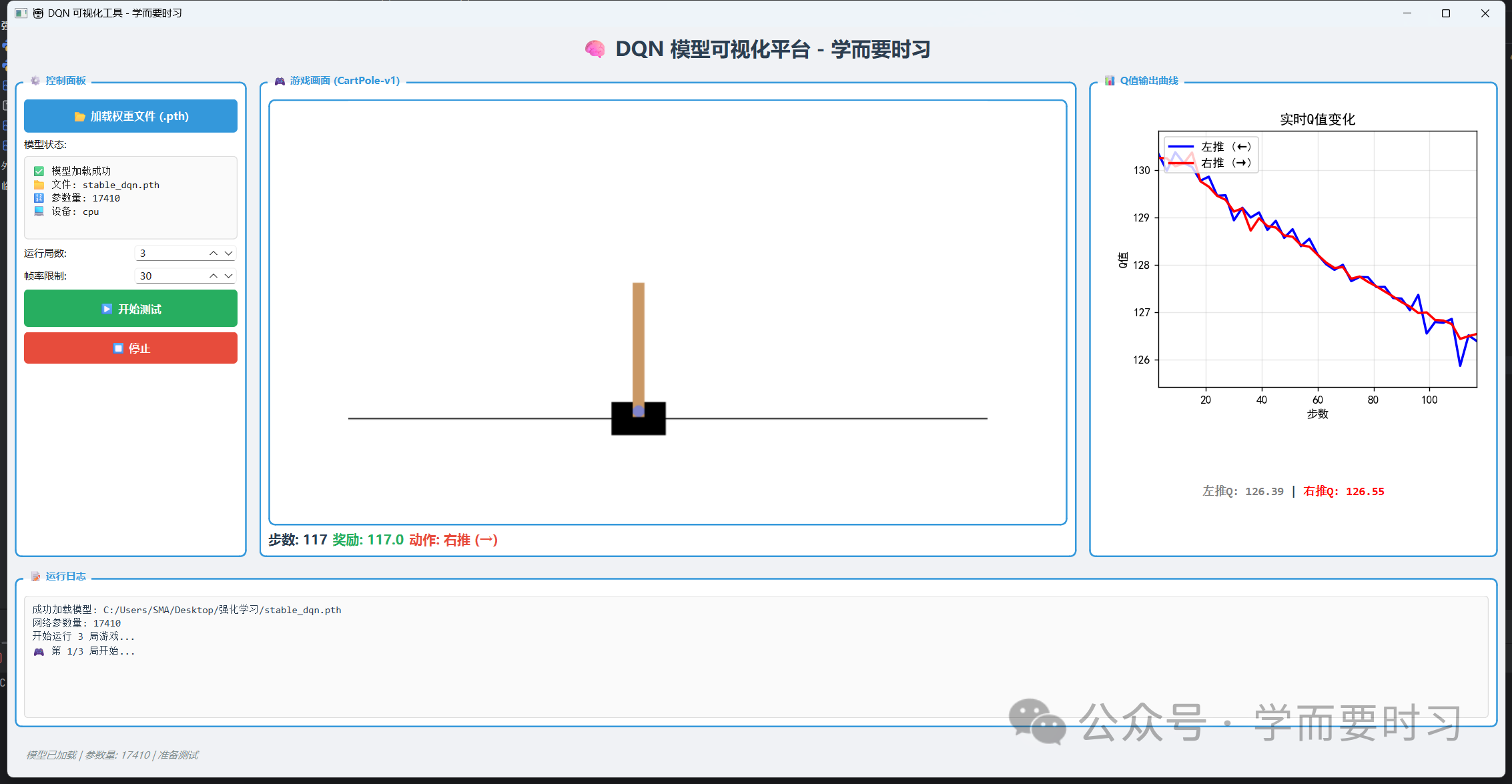
3.1 决策置信度解析
通过实时监控两个动作的 Q 值输出的大小,我们可以读出智能体的"心理波动":我需要往左还是往右推,用多大得劲??
- 确定性决策 :当 Qright≫QleftQ_{right} \gg Q_{left}Qright≫Qleft 时,智能体表现出极强的平衡信心,他会知道往右推会保证平衡杆不会偏移。
- 逻辑纠偏 :当杆子向左倾斜但具有向右的角速度时,智能体可能会提前输出向左的预判。这种"前瞻性决策"正是现如今大模型能够进行预判式反思的底层物理映射。
四、总结
尽管 CartPole 与 DeepSeek-R1 在参数量级上相差亿倍,但它们共享相同的缩放律(Scaling Law)反思:
- 搜索与推理的平衡 :在 CartPole 中,这体现为 ϵ\epsilonϵ-greedy 的探索策略;在 R1 中,体现为推理链的深度搜索。
- 验证的代价:强化学习不需要昂贵的标注数据,它只需要一个"规则明确的环境"与"客观的评估指标"。
- 能力的涌现:当训练量跨越某个临界点,模型从"无序震荡"转为"长效平衡",这种相变在所有 RL 模型中都是一致的。