1. 理解词嵌入(Understanding Word Embeddings)
为什么需要嵌入?------一个具体的例子
包括 LLM 在内的深度神经网络模型无法直接处理原始文本 。由于文本是类别型数据(categorical) ,它与用于实现和训练神经网络的数学运算不兼容。因此,我们需要一种方法来将词表示为连续值向量。
让我们用一个具体的例子看看问题所在。假设我们有三个词:cat、dog、car。一个朴素的想法是给每个词分配一个整数:
cat → 1
dog → 2
car → 3问题立刻出现:神经网络的运算会把这些数字当作数值来处理。
举例说明:假设神经网络的某一层需要计算"dog 和 cat 的平均":
dog+cat2=2+12=1.5 \frac{\text{dog} + \text{cat}}{2} = \frac{2 + 1}{2} = 1.5 2dog+cat=22+1=1.5
但 1.5 代表什么呢?半个 cat 加半个 dog?这毫无意义。
更糟的是,这种表示暗示了错误的关系:
∣cat−dog∣=∣1−2∣=1∣dog−car∣=∣2−3∣=1 |\text{cat} - \text{dog}| = |1 - 2| = 1 \\ |\text{dog} - \text{car}| = |2 - 3| = 1 ∣cat−dog∣=∣1−2∣=1∣dog−car∣=∣2−3∣=1
数学上看,cat 到 dog 的"距离"等于 dog 到 car 的"距离"。但语义上,cat 和 dog 都是动物,应该更接近;car 是汽车,应该离得更远。朴素的数字编码丢失了语义关系。
嵌入正是为了解决这个问题:把每个词映射到多维空间中的一个点,让语义关系通过向量之间的几何关系来表达。
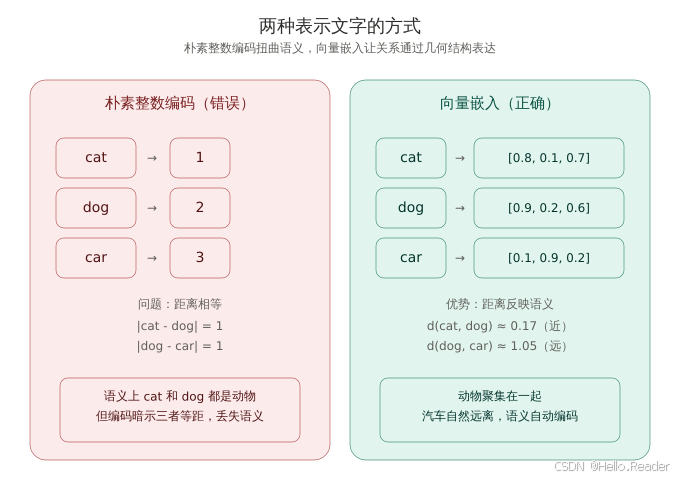
图1:同样是三个词,朴素整数编码让距离失去语义;向量嵌入则让语义关系通过几何距离自然表达。
嵌入(Embedding)是什么?
将数据转换为向量格式的概念通常被称为嵌入。使用特定的神经网络层或另一个预训练的神经网络模型,我们可以嵌入不同的数据类型,例如视频、音频和文本。
深度学习模型无法以原始形式处理视频、音频和文本等数据格式。因此,我们使用嵌入模型将这些原始数据转换为密集向量表示,使深度学习架构能够轻松理解和处理。具体来说,图中展示了将原始数据转换为三维数值向量的过程。
需要注意的是:不同的数据格式需要不同的嵌入模型。为文本设计的嵌入模型不适合用于嵌入音频或视频数据。
从核心来说,嵌入是一种从离散对象 (词、图像,甚至整个文档)到连续向量空间中的点 的映射。嵌入的主要目的是将非数值数据转换为神经网络可以处理的格式。
不同粒度的文本嵌入
虽然词嵌入是最常见的文本嵌入形式,但也存在面向句子、段落或整个文档的嵌入。句子或段落嵌入是**检索增强生成(Retrieval-Augmented Generation, RAG)**的流行选择。RAG 将生成与检索(如搜索外部知识库)相结合,在生成文本时拉取相关信息------这一技术超出了本书的范围。
由于我们的目标是训练类 GPT 的 LLM(它们学习逐词生成文本),因此本章专注于词嵌入。
2. 向量空间如何表达语义:具体数值推演
这部分原书并未展开,但为了真正理解嵌入的威力,我们用一个具体例子把它推导一遍。
示例:用三维向量表达四个词
假设我们有四个词:king(国王)、queen(王后)、man(男人)、woman(女人)。我们给每个词分配一个三维向量(维度的含义假设为:皇室程度, 男性程度, 年龄程度):
king = [0.9, 0.9, 0.5]
queen = [0.9, 0.1, 0.5]
man = [0.1, 0.9, 0.5]
woman = [0.1, 0.1, 0.5]推演 1:计算两个词的"相似度"
使用欧氏距离(向量间的直线距离):
d(A,B)=∑i=1n(Ai−Bi)2 d(A, B) = \sqrt{\sum_{i=1}^{n}(A_i - B_i)^2} d(A,B)=i=1∑n(Ai−Bi)2
计算 king 和 queen 的距离:
d(king,queen)=(0.9−0.9)2+(0.9−0.1)2+(0.5−0.5)2=0+0.64+0=0.8 d(\text{king}, \text{queen}) = \sqrt{(0.9-0.9)^2 + (0.9-0.1)^2 + (0.5-0.5)^2} = \sqrt{0 + 0.64 + 0} = 0.8 d(king,queen)=(0.9−0.9)2+(0.9−0.1)2+(0.5−0.5)2 =0+0.64+0 =0.8
计算 king 和 man 的距离:
d(king,man)=(0.9−0.1)2+(0.9−0.9)2+(0.5−0.5)2=0.64+0+0=0.8 d(\text{king}, \text{man}) = \sqrt{(0.9-0.1)^2 + (0.9-0.9)^2 + (0.5-0.5)^2} = \sqrt{0.64 + 0 + 0} = 0.8 d(king,man)=(0.9−0.1)2+(0.9−0.9)2+(0.5−0.5)2 =0.64+0+0 =0.8
计算 king 和 woman 的距离:
d(king,woman)=(0.9−0.1)2+(0.9−0.1)2+(0.5−0.5)2=0.64+0.64+0≈1.13 d(\text{king}, \text{woman}) = \sqrt{(0.9-0.1)^2 + (0.9-0.1)^2 + (0.5-0.5)^2} = \sqrt{0.64 + 0.64 + 0} \approx 1.13 d(king,woman)=(0.9−0.1)2+(0.9−0.1)2+(0.5−0.5)2 =0.64+0.64+0 ≈1.13
结论 :king 离 queen 和 man 都很近(都是 0.8),但离 woman 较远(1.13)------这符合语义直觉。
推演 2:著名的"国王 - 男人 + 女人 ≈ 王后"
这是 Word2Vec 最著名的发现之一:词嵌入可以做向量算术。
king−man+woman=? \text{king} - \text{man} + \text{woman} = ? king−man+woman=?
逐分量计算:
0.9,0.9,0.5\]−\[0.1,0.9,0.5\]+\[0.1,0.1,0.5\]=\[0.9−0.1+0.1, 0.9−0.9+0.1, 0.5−0.5+0.5\]=\[0.9,0.1,0.5\] \\begin{aligned} \&\[0.9, 0.9, 0.5\] - \[0.1, 0.9, 0.5\] + \[0.1, 0.1, 0.5\] \\\\ \&= \[0.9-0.1+0.1,\\ 0.9-0.9+0.1,\\ 0.5-0.5+0.5\] \\\\ \&= \[0.9, 0.1, 0.5\] \\end{aligned} \[0.9,0.9,0.5\]−\[0.1,0.9,0.5\]+\[0.1,0.1,0.5\]=\[0.9−0.1+0.1, 0.9−0.9+0.1, 0.5−0.5+0.5\]=\[0.9,0.1,0.5
结果正好等于 queen 的向量!

图2:king − man + woman 的逐步推演过程。每一步都是简单的逐分量加减,最终结果恰好等于 queen 的向量。
这说明:嵌入空间中"性别"这个概念可以被表示为一个方向向量 (man - woman 或 king - queen)。减去"男性方向"再加上"女性方向",就能从 king 移动到 queen。
这就是向量空间的威力------几何关系自动编码了语义关系。
注意:这里的数值是人为构造的,真实的 Word2Vec 向量在高维空间中学到这种关系,不会这么整齐,但核心思想完全一致。
3.Word2Vec:早期的词嵌入方法
有多种算法和框架被开发来生成词嵌入。其中一个最早且最流行的例子是 Word2Vec 。Word2Vec 训练了一种神经网络架构,通过预测给定目标词的上下文(或反过来)来生成词嵌入。
Word2Vec 背后的核心思想是:出现在相似上下文中的词往往具有相似的含义。因此,当投影到二维词嵌入进行可视化时,可以看到相似的词项会聚集在一起。
Figure 2.3 说明 :如果词嵌入是二维的,我们可以将它们绘制在二维散点图中进行可视化。当使用像 Word2Vec 这样的词嵌入技术时,对应于相似概念的词在嵌入空间中往往彼此靠近。例如,不同类型的鸟在嵌入空间中彼此更接近,而与国家和城市相比距离更远。
嵌入维度:性能与效率的权衡
词嵌入的维度可以从 1 到数千不等。我们可以选择二维词嵌入以便于可视化。更高的维度可能捕获更细微的关系,但代价是计算效率降低。
这是一个典型的权衡:
- 维度太低 → 无法捕获足够的语义信息
- 维度太高 → 计算和内存成本过高
- 需要找到一个适合任务的平衡点
4.LLM 中的嵌入:为什么不用预训练的 Word2Vec?
虽然我们可以使用像 Word2Vec 这样的预训练模型来为机器学习模型生成嵌入,但 LLM 通常产生自己的嵌入------这些嵌入是输入层的一部分,并在训练过程中被更新。
将嵌入优化作为 LLM 训练的一部分而不是使用 Word2Vec 的优势 在于:嵌入被优化为适合手头的特定任务和数据 。我们将在本章后面实现这样的嵌入层。此外,LLM 还可以创建上下文化的输出嵌入,这将在第3章中讨论。
静态嵌入 vs 上下文化嵌入
这是理解 LLM 的一个重要概念:
静态嵌入(如 Word2Vec):每个词有一个固定的向量,无论上下文如何。
"I went to the bank to deposit money" ← "bank" 对应向量 v
"I sat on the river bank" ← "bank" 对应同一个向量 v ❌两个句子中 bank 的含义完全不同(银行 vs 河岸),但 Word2Vec 给出相同的向量。
上下文化嵌入(LLM 产生的):同一个词在不同上下文中产生不同的向量。
"I went to the bank to deposit money" ← "bank" 对应向量 v₁(偏向"银行"语义)
"I sat on the river bank" ← "bank" 对应向量 v₂(偏向"河岸"语义) ✅这种能力是通过注意力机制 实现的(第3章详述)。本章我们先实现静态的输入嵌入层(即查找表),上下文化的部分由后续的 Transformer 层在运行时动态生成。
5. 实际 LLM 中的嵌入维度
遗憾的是,高维嵌入给可视化带来了挑战,因为我们的感知和常见的图形表示天然受限于三维或更少的维度 。然而,在使用 LLM 时,我们通常使用高得多的维度。
对于 GPT-2 和 GPT-3,嵌入大小(通常称为模型隐藏状态的维度)因特定的模型变体和大小而异:
| 模型 | 参数量 | 嵌入维度 |
|---|---|---|
| GPT-2(最小版本) | 117M / 125M | 768 |
| GPT-3(最大版本) | 175B | 12,288 |
推演:嵌入层的参数量有多大?
嵌入层本质上是一个查找表 ------一个形状为 [词汇表大小, 嵌入维度] 的矩阵。让我们具体算一下 GPT-3 的嵌入层有多大:
- 词汇表大小:50,257(GPT-2/3 的 BPE 词汇表大小)
- 嵌入维度:12,288
嵌入层参数量:
50,257×12,288=617,557,056≈6.18 亿 50{,}257 \times 12{,}288 = 617{,}557{,}056 \approx 6.18 \text{ 亿} 50,257×12,288=617,557,056≈6.18 亿
对比一下:GPT-3 总共 1750 亿参数,嵌入层就占了大约 6.18 亿------仅仅是一个查找表,就有 6 亿参数。这也解释了为什么高维嵌入那么"昂贵"。
如果换成 GPT-2(嵌入维度 768):
50,257×768=38,597,376≈3,860 万 50{,}257 \times 768 = 38{,}597{,}376 \approx 3{,}860 \text{ 万} 50,257×768=38,597,376≈3,860 万
相差 16 倍。

图3:GPT-2 和 GPT-3 嵌入层参数量对比。虽然嵌入层只是一个查找表,但随着维度从 768 扩大到 12,288,参数量也从 3,860 万跃升到 6.18 亿。
本章后续步骤预告
本章接下来的各节将逐步讲解为 LLM 准备嵌入所需的步骤:
- 将文本拆分为词(分词 --- 2.2 节)
- 将词转换为 Token ID(2.3 节)
- 添加特殊 Token(2.4 节)
- BPE 字节对编码(2.5 节)
- 滑动窗口数据采样(2.6 节)
- Token 嵌入层(2.7 节)
- 位置编码(2.8 节)
6. 本篇小结
| 概念 | 要点 |
|---|---|
| 为什么需要嵌入 | 神经网络无法直接处理类别型文本,朴素的整数编码会引入错误的语义关系 |
| 嵌入的本质 | 离散对象 → 连续向量空间中的点 |
| 向量空间的威力 | 语义关系可以通过几何关系表达(距离、方向) |
| Word2Vec | 早期词嵌入方法,"相似上下文中的词有相似含义" |
| 向量算术 | king - man + woman ≈ queen |
| 静态 vs 上下文化嵌入 | Word2Vec 给固定向量;LLM 根据上下文动态调整 |
| GPT-2 嵌入维度 | 768 维,约 3,860 万参数 |
| GPT-3 嵌入维度 | 12,288 维,约 6.18 亿参数 |
7. 预习思考
- 如果把
cat、dog、car放到二维嵌入空间中,你会如何摆放它们的坐标才能合理反映语义关系? - 为什么 GPT-3 要把嵌入维度提到 12,288 这么高?维度再高会发生什么?
- 静态嵌入无法区分多义词的不同含义。你能想到一种简单的"打补丁"方法吗?(提示:位置信息)