前面我们介绍了Docker部署➕ollama➕logging➕bm25等RAG项目中各个必不可少的tools,本篇主要讲的是mysql➕redis➕milvus!!!
我总结一下,整个RAG就是点多面广,全面开火/(ㄒoㄒ)/~~
前言
在RAG系统的数据架构中,单一数据库无法满足所有需求。今天,我们聚焦
数据存储的三驾马车:
| 工具 | 类型 | 在RAG中的角色 |
|---|---|---|
| MySQL | 关系型数据库 | 存储业务数据、文档元数据、用户信息 |
| Redis | 键值缓存 | 缓存检索结果、会话管理、去重 |
| Milvus | 向量数据库 | 向量存储与相似性检索 |
这三者不是竞争关系,而是互补协作的关系。
一、MySQL:结构化数据存储
1.1 为什么RAG需要MySQL?
在RAG系统中,向量数据库负责语义检索,但业务数据仍然需要关系型数据库:
python
# RAG系统中的数据分工
数据分工 = {
"MySQL": [
"文档元数据(标题、作者、时间)",
"用户信息(账号、权限)",
"问答日志(记录用户查询历史)",
"业务配置(知识库配置、模型参数)"
],
"Milvus": [
"文档向量(语义表示)",
"查询向量(实时检索)"
"各种参数的变换囊括了相似度算法的各种应用场景"
],
"Redis": [
"热点查询缓存",
"会话状态",
"频率限制计数器"
]
}1.2 基础操作代码
python
import pymysql
import pandas as pd
def getConnection():
connection = pymysql.connect(
host="127.0.0.1",
user="root",
password="123456",
database="test"
)
return connection重难点分析:
-
pymysql是纯Python实现,不需要额外安装MySQL驱动 -
每次操作后要
commit(),否则数据不会真正写入 -
必须
close()释放连接,否则会导致连接池耗尽
1.3 创建数据表
python
def createTable():
connection = getConnection()
cursor = connection.cursor() # ➕游标:给我们的mysql创建一只执行的手
create_table_query = '''CREATE TABLE IF NOT EXISTS jpkb (
id INT AUTO_INCREMENT PRIMARY KEY,
subject_name VARCHAR(20),
question VARCHAR(1000),
answer VARCHAR(1000))'''
cursor.execute(create_table_query)
connection.commit()
connection.close()字段设计分析:
| 字段 | 类型 | 长度 | 说明 |
|---|---|---|---|
| id | INT | AUTO_INCREMENT | 自增主键 |
| subject_name | VARCHAR | 20 | 学科名称 |
| question | VARCHAR | 1000 | 问题(检索的关键) |
| answer | VARCHAR | 1000 | 答案(生成的依据) |
1.4 批量插入数据
python
def insertData():
data = pd.read_csv("../data/JP学科知识问答.csv")
print(data.head())
connection = getConnection()
cursor = connection.cursor()
for _, row in data.iterrows():
insert_query = "INSERT INTO jpkb (subject_name, question, answer) VALUES (%s, %s, %s)"
cursor.execute(insert_query, (row["学科名称"], row["问题"], row["答案"]))
connection.commit()
connection.close()思考:
问:为什么用
pd.read_csv读CSV,而不是逐行INSERT?答:pandas可以批量处理数据,还提供了数据清洗功能。但注意
iterrows()逐行插入效率不高,数据量大时应该用executemany()批量插入。
优化版本:
python
def insertDataBatch():
data = pd.read_csv("../data/JP学科知识问答.csv")
connection = getConnection()
cursor = connection.cursor()
# 准备批量数据
batch_data = [(row["学科名称"], row["问题"], row["答案"])
for _, row in data.iterrows()]
# 批量插入(效率提升10倍+)
insert_query = "INSERT INTO jpkb (subject_name, question, answer) VALUES (%s, %s, %s)"
cursor.executemany(insert_query, batch_data)
connection.commit()
connection.close()1.5 查询数据
python
def getData():
connection = getConnection()
cursor = connection.cursor()
cursor.execute("SELECT subject_name, question, answer FROM jpkb limit 10")
results = cursor.fetchall()
for result in results:
print(result)
connection.close()重难点分析:
-
fetchall()一次性获取所有结果,数据量大时可能内存溢出 -
替代方案:
fetchmany(size)分批获取
二、Redis:高速缓存
2.1 Redis在RAG中的价值
Redis是内存数据库,读写速度极快(微秒级),适合以下场景:
python
Redis使用场景 = {
"缓存热点查询": "相同问题直接返回缓存结果,避免重复检索和LLM调用",
"去重机制": "防止短时间内重复处理相同请求",
"会话管理": "存储多轮对话的上下文",
"频率限制": "防止API被滥用",
"任务队列": "异步处理耗时任务"
}2.2 基础操作
python
import redis
import json
def getConnection():
client = redis.Redis(
host="127.0.0.1",
port="6379",
password="1234",
charset="utf-8"
)
return client
def insertData(key, value):
client = getConnection()
client.set(key, value)
def getData(key):
client = getConnection()
data = client.get(key)
if data is not None:
print(data.decode("utf-8"))
else:
print(data)
def delData(key):
client = getConnection()
client.delete(key)2.3 存储JSON数据
python
if __name__ == '__main__':
key = "123"
# 存储JSON对象
insertData(key, json.dumps({"姓名": "张程", "年龄": 27}, ensure_ascii=False))
getData(key) # {"姓名": "张程", "年龄": 27}
delData(key)重难点分析:
-
Redis只能存储字符串,对象必须序列化为JSON
-
ensure_ascii=False保证中文正常显示 -
读取时
decode("utf-8")将bytes转为字符串,再用json.loads()解析
2.4 RAG中的缓存策略
python
class RAGCache:
def __init__(self):
self.redis = getConnection()
self.ttl = 3600 # 缓存1小时
def get_cached_answer(self, question):
"""获取缓存的答案"""
key = f"qa:{hash(question)}" # 使用问题哈希作为key
cached = self.redis.get(key)
if cached:
return json.loads(cached.decode('utf-8'))
return None
def cache_answer(self, question, answer):
"""缓存答案"""
key = f"qa:{hash(question)}"
self.redis.setex(key, self.ttl, json.dumps(answer, ensure_ascii=False))
def rate_limit(self, user_id, max_requests=10, window=60):
"""频率限制:每分钟最多10次请求"""
key = f"rate:{user_id}"
current = self.redis.get(key)
if current is None:
self.redis.setex(key, window, 1)
return True
elif int(current) < max_requests:
self.redis.incr(key)
return True
else:
return False # 超过限制思考:
问:Redis的key应该怎么设计?
答:遵循业务:标识符:属性 的模式。例如
qa:user:123:history、cache:question:hash。这种设计便于管理和调试。
qa:user:123:history │ │ │ │ │ │ │ └── 具体属性(这是什么数据) │ │ └────── 唯一标识(哪个用户) │ └─────────── 实体类型(用户相关) └────────────── 业务模块(问答系统)
qa:user:123:history就是:在问答系统(qa)中,用户123(user:123)的浏览历史记录(history),里面存储的是用户看过的问题ID列表。
cache:question:hash │ │ │ │ │ └── 具体属性(什么类型的缓存) │ └────────── 实体类型(问题相关) └─────────────── 业务模块(缓存层)
cache:question:hash是用问题的哈希值作为 key,缓存预计算结果(如 AI 答案、embedding 向量),避免相同问题重复计算,提升响应速度。
场景1:qa:user:123:history
真实场景:你在刷知乎,要看你最近看过的10个问题
python
# 用户123 看了问题 1001
LPUSH qa:user:123:history 1001
# 又看了 1002、1003
LPUSH qa:user:123:history 1002 1003
# 现在历史记录:[1003, 1002, 1001]
# 获取最近3条
LRANGE qa:user:123:history 0 2
# 返回:[1003, 1002, 1001]
一句话:存用户看过的问题ID列表,用来展示"最近浏览"。
场景2:cache:question:hash
真实场景:用户问"什么是Redis?",AI回答要2秒,相同问题别再问AI
python
import hashlib
text = "什么是Redis?"
hash_val = hashlib.md5(text.encode()).hexdigest()[:16]
key = f"cache:question:hash:{hash_val}" # cache:question:hash:5d41402abc4b2a76
# 第一次:查缓存 → 没有
result = r.get(key) # None
# 调用AI(2秒),然后存起来
answer = ai_call("什么是Redis?")
r.setex(key, 3600, answer) # 缓存1小时
# 第二次:同一个问题 → 直接命中
result = r.get(key) # 秒回,不用再调AI
一句话:用问题的MD5当key,缓存AI答案,相同问题不再重复计算。
三、Milvus:向量数据库
3.1 Milvus的核心概念
python
Milvus层级结构 = {
"Database": "数据库(类似MySQL的database)",
"Collection": "集合(类似MySQL的table)",
"Partition": "分区(逻辑分割,提升查询性能)",
"Index": "索引(加速向量检索)",
"Entity": "实体(一条记录,包含向量+标量)"
}3.2 数据库操作
python
from pymilvus import MilvusClient, DataType
def getConnection():
client = MilvusClient(uri="http://localhost:19530")
return client
def createDataBase():
client = getConnection()
databases = client.list_databases()
if "test" not in databases:
client.create_database(db_name="test")
else:
client.using_database(db_name='test')3.3 创建集合与Schema
python
def createCollection():
client = getConnection()
client.using_database(db_name='test')
# 定义schema
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name='id', datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name='vector', datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(field_name='scalar', datatype=DataType.VARCHAR, max_length=256)
# 创建集合
client.create_collection(collection_name="demo_v1", schema=schema)
# 创建向量索引
prepare_indexs = client.prepare_index_params()
prepare_indexs.add_index(field_name='vector', index_type='',
metric_type='COSINE', index_name='vector_index')
client.create_index(collection_name='demo_v1', index_params=prepare_indexs)
# 加载集合到内存(必须)
client.load_collection(collection_name='demo_v1')repare_indexs.add_index( field_name='vector',
index_type='',
metric_type='COSINE',
index_name='vector_index')
参数解析
field_name='vector' >>指定对哪个字段创建索引作用 :告诉数据库,我要给
vector这个字段加速检索。
index_type=''(这里是空的)>> 索引类型(用哪种算法加速搜索)不填的话, 标量会AUTOINDEX自动选择, 向量的话会报错,不建议不填
性能对比(真实数据)
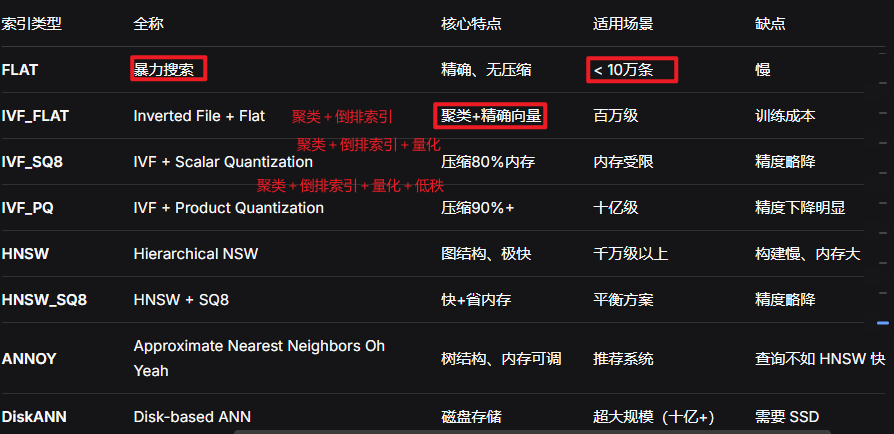
测试条件:100万条、128维、COSINE相似度
索引类型 查询耗时 内存占用 召回率(99%目标) 构建时间 FLAT 1000ms 512MB 100% 0 IVF_FLAT(nlist=1024) 50ms 520MB 95% 30秒 IVF_SQ8 45ms 130MB 92% 35秒 IVF_PQ(m=8) 30ms 65MB 88% 60秒 HNSW(M=16) 10ms 800MB 98% 5分钟 HNSW_SQ8 8ms 200MB 96% 5分钟 选择决策树
python""" 你的数据量多大? │ ├── < 10万 → FLAT(简单、精确) │ ├── 10万 ~ 500万 │ ├── 内存充足 → IVF_FLAT │ └── 内存紧张 → IVF_SQ8 │ ├── 500万 ~ 5000万 │ ├── 追求速度 → HNSW │ ├── 平衡方案 → HNSW_SQ8 │ └── 内存极度紧张 → IVF_PQ │ └── > 5000万 ├── 有SSD → DiskANN └── 纯内存 → HNSW_PQ """完整的选择逻辑:小数据用 FLAT,中等数据用 IVF_FLAT/SQ8,大数据用 HNSW,超大数据用 DiskANN;内存、速度、精度三者不可兼得,需要 trade-off (取舍)。
metric_type='COSINE' >>距离度量方式(怎么判断两个向量相似)
值 公式 范围 适用场景 COSINE余弦相似度 -1, 1 文本相似度(最常用) L2欧氏距离 [0, ∞) 图像、音频特征 IP内积 (-∞, ∞) 需归一化的向量 这里
COSINE是对的,适合文本 embedding。建索引时的
metric_type= 告诉系统"我会用什么方式检索",系统按这个方式组织数据检索时的
metric_type= 告诉系统"请用这个方式计算相似度"两者必须一致,否则结果错误或报错。
index_name='vector_index' >>索引的名字(方便管理和删除索引)
field_name = 对哪个字段建索引,
index_type = 用什么算法(HNSW最快),
metric_type = 怎么算相似度(文本用COSINE),
index_name = 索引的名字
重难点分析:
| 参数 | 说明 | 注意事项 |
|---|---|---|
auto_id=False |
主键不自动生成 | 插入时必须提供id |
enable_dynamic_field=True |
允许动态字段 | 动态字段存入$meta |
metric_type='COSINE' |
距离计算方式 | 必须与查询时一致 |
load_collection() |
加载到内存 | 不加载无法搜索 |
3.4 插入数据
python
def insertData():
client = getConnection()
client.using_database(db_name='test')
# 简化创建:自动创建集合
client.create_collection(collection_name='demo_v2', dimension=5, metric_type='IP')
data = [
{"id": 0, "vector": [0.358, -0.602, 0.184, -0.262, 0.902], "color": "pink_8682"},
# ... 更多数据
]
client.insert(collection_name='demo_v2', data=data)
client.upsert(collection_name='demo_v2', data=data) # 去重更新insert vs upsert:
| 操作 | 行为 | 适用场景 |
|---|---|---|
insert() |
直接插入,可能重复 | 初次导入 |
upsert() |
存在则更新,不存在则插入 | 增量更新 |
3.5 分区操作
python
def insertDataToPatition():
client = getConnection()
client.using_database(db_name='test')
# 创建分区
client.create_partition(collection_name='demo_v2', partition_name="partitionA")
# 向分区插入数据
client.upsert(collection_name='demo_v2', data=data, partition_name="partitionA")分区的作用:
思考:
问:partition_name='partitionA'分区的作用就是让查询和操作变得更快对吧?
答:是的!分区的主要作用是通过缩小数据操作的范围来提升性能。删除一个分区比删除数百万条实体快得多,非常适合时序数据和多租户场景。
3.6 向量检索
python
def getData():
# 单一向量查询
result1 = client.search(
collection_name='demo_v2',
data=[[0.1988, 0.0602, 0.6977, 0.2614, 0.8387]],
limit=2,
search_params={"metric_type": "IP"},
output_fields=['id', "vector", "color"]
)
# 分区搜索
res3 = client.search(
collection_name="demo_v2",
data=[[0.0217, 0.0586, 0.6169, -0.7944, 0.5555]],
limit=5,
search_params={"metric_type": "IP"},
partition_names=["partitionA"] # 只搜索指定分区
)
# 带过滤的搜索
res5 = client.search(
collection_name="demo_v2",
data=[[0.3580, -0.6023, 0.1841, -0.2629, 0.9029]],
limit=5,
filter='color like "red%"', # 先过滤后搜索
output_fields=["color"]
)3.7 范围搜索(精确控制)
python
# 范围搜索:只返回相似度在 [0.8, 1.0] 的结果
search_params = {
"metric_type": "IP",
"params": {
"radius": 0.8, # 相似度下限
"range_filter": 1 # 相似度上限
}
}
res6 = client.search(
collection_name="demo_v2",
data=[[0.3580, -0.6023, 0.1841, -0.2629, 0.9029]],
limit=6,
search_params=search_params,
output_fields=["color"],
)思考:
问:用radius和range_filter这种方式感觉才是精确搜索的正确姿势。
答:完全正确!使用范围搜索是精确搜索的正确姿势。TopK搜索是"不管怎样都要凑够K个",可能会返回不相关结果;而范围搜索是"质量不达标就不返回",保证结果质量。
四、三库协同:RAG完整数据流
python
class RAGSystem:
def __init__(self):
self.mysql = MySQLClient()
self.redis = RedisClient()
self.milvus = MilvusClient()
self.cache_ttl = 3600
def answer_question(self, user_id, question):
# 1. 频率限制(Redis)
if not self.redis.rate_limit(user_id):
return {"error": "请求过于频繁,请稍后再试"}
# 2. 检查缓存(Redis)
cache_key = f"qa:{hash(question)}"
cached = self.redis.get(cache_key)
if cached:
return json.loads(cached)
# 3. 生成查询向量(假设有embedding模型)
query_vector = self.get_embedding(question)
# 4. 向量检索(Milvus)
search_results = self.milvus.search(
collection_name="knowledge_base",
data=[query_vector],
limit=5,
output_fields=["doc_id", "chunk_text"]
)
# 5. 获取完整文档(MySQL)
doc_ids = [r['entity']['doc_id'] for r in search_results[0]]
documents = self.mysql.get_documents_by_ids(doc_ids)
# 6. 构建Prompt并调用LLM
answer = self.generate_answer(question, documents)
# 7. 缓存结果(Redis)
self.redis.setex(cache_key, self.cache_ttl, json.dumps(answer))
# 8. 记录日志(MySQL)
self.mysql.log_query(user_id, question, answer)
return {"answer": answer, "sources": documents}五、清理资源
python
def deleteDataBase():
client = getConnection()
client.using_database(db_name='test')
# 必须按顺序清理
client.release_collection(collection_name='demo_v1') # 1. 释放集合
client.release_collection(collection_name='demo_v2')
client.drop_index(collection_name="demo_v1", index_name="vector_index") # 2. 删除索引
client.drop_index(collection_name="demo_v2", index_name="vector_index")
client.drop_collection(collection_name='demo_v1') # 3. 删除集合
client.drop_collection(collection_name='demo_v2')
client.drop_database(db_name="test") # 4. 删除数据库重难点分析:
-
删除顺序:释放集合 → 删除索引 → 删除集合 → 删除数据库
-
必须先
release_collection才能删除索引
六、总结对比
6.1 三种数据库的特点
| 特性 | MySQL | Redis | Milvus |
|---|---|---|---|
| 存储介质 | 磁盘 | 内存 | 磁盘+内存 |
| 读写速度 | 毫秒级 | 微秒级 | 毫秒级(检索) |
| 数据模型 | 表格 | 键值对 | 向量+标量 |
| 查询方式 | SQL | 命令 | 向量相似度 |
| 在RAG中的角色 | 业务数据 | 缓存 | 语义检索 |
6.2 选择策略
python
数据存储选择策略 = {
"需要持久化、关联查询、事务": "MySQL",
"需要极速读写、临时存储、缓存": "Redis",
"需要语义检索、相似度匹配": "Milvus"
}6.3 最佳实践
-
MySQL存元数据,Milvus存向量:通过公共ID关联
-
Redis缓存热点查询:减少重复计算
-
分区提升Milvus性能:按时序或类别分区
-
混合检索BM25+向量:兼顾关键词和语义
附录:常见问题
Q1: 为什么不用MongoDB代替MySQL?
MongoDB适合文档存储,但MySQL的关系查询和事务支持更成熟。RAG系统中元数据之间的关联查询(如用户-文档-权限)用MySQL更合适。
Q2: Redis数据丢了怎么办?
Redis默认不持久化,生产环境应开启RDB或AOF持久化。缓存数据丢失不影响核心功能,只是会重新计算。
Q3: Milvus的dimension怎么选?
取决于Embedding模型:BGE-large是1024维,OpenAI ada是1536维,Qwen是896维。保持一致即可。
写在最后:MySQL、Redis、Milvus各司其职,共同构成了RAG系统的数据底座。理解它们的特点和使用场景,是构建生产级RAG系统的关键。