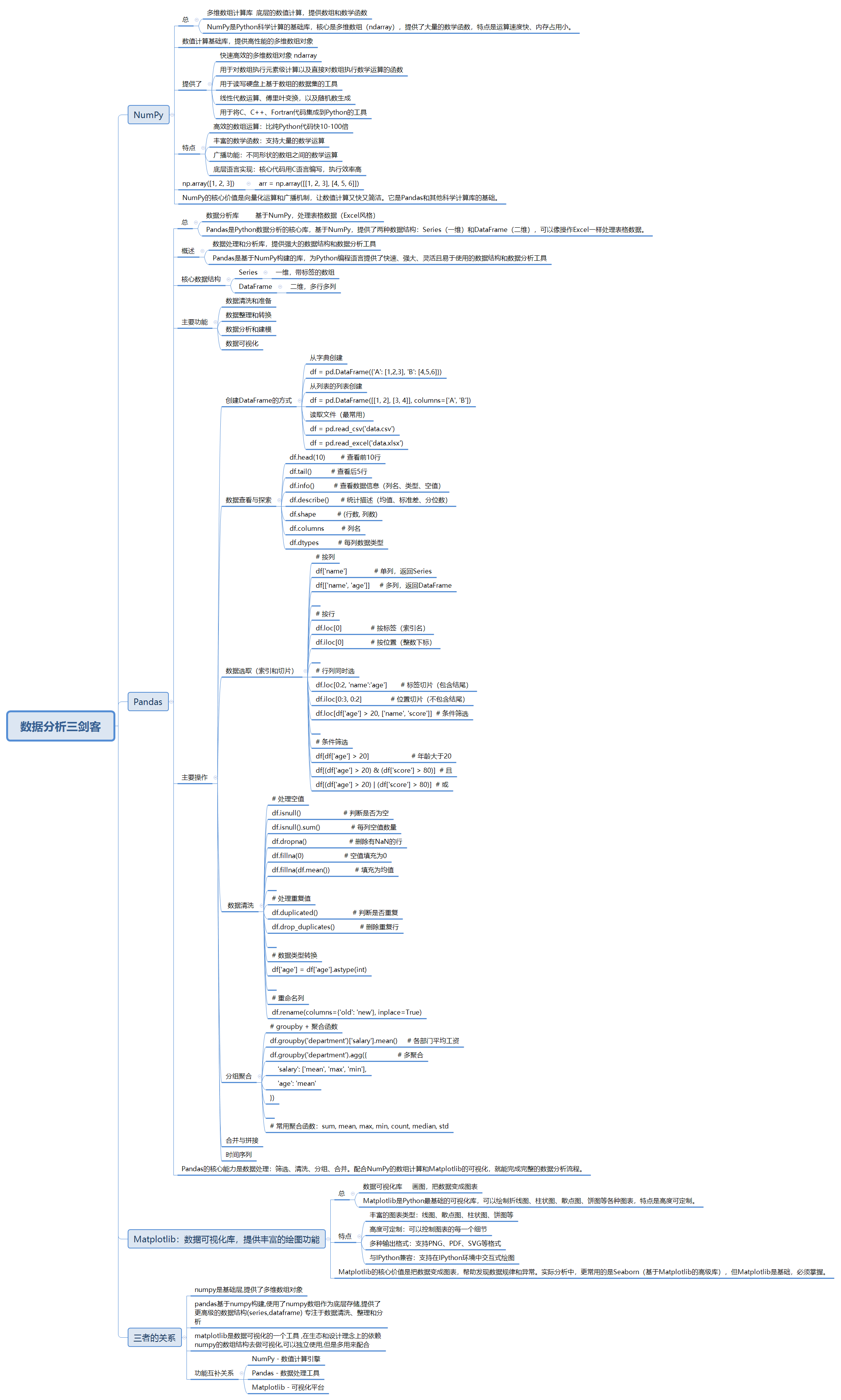
数据分析三剑客
一、数据分析三剑客简介¶
在Python数据分析领域,有三个不可或缺的核心库,被称为"数据分析三剑客":
- NumPy:数值计算基础库,提供高性能的多维数组对象
- Pandas:数据处理和分析库,提供强大的数据结构和数据分析工具
- Matplotlib:数据可视化库,提供丰富的绘图功能
二、NumPy 概述[¶](#二、NumPy 概述¶)
☆ 什么是 NumPy[¶](#☆ 什么是 NumPy¶)
NumPy(Numerical Python)是Python科学计算的基础包,它提供了:
- 快速高效的多维数组对象 ndarray
- 用于对数组执行元素级计算以及直接对数组执行数学运算的函数
- 用于读写硬盘上基于数组的数据集的工具
- 线性代数运算、傅里叶变换,以及随机数生成
- 用于将C、C++、Fortran代码集成到Python的工具
☆ NumPy 的特点[¶](#☆ NumPy 的特点¶)
- 高效的数组运算:比纯Python代码快10-100倍
- 丰富的数学函数:支持大量的数学运算
- 广播功能:不同形状的数组之间的数学运算
- 底层语言实现:核心代码用C语言编写,执行效率高
三、Pandas 概述[¶](#三、Pandas 概述¶)
☆ 什么是 Pandas[¶](#☆ 什么是 Pandas¶)
Pandas是基于NumPy构建的库,为Python编程语言提供了快速、强大、灵活且易于使用的数据结构和数据分析工具。
☆ Pandas 的核心数据结构[¶](#☆ Pandas 的核心数据结构¶)
- Series:一维带标签数组
- DataFrame:二维表格型数据结构
☆ Pandas 的主要功能[¶](#☆ Pandas 的主要功能¶)
- 数据清洗和准备
- 数据整理和转换
- 数据分析和建模
- 数据可视化
四、Matplotlib 概述[¶](#四、Matplotlib 概述¶)
☆ 什么是 Matplotlib[¶](#☆ 什么是 Matplotlib¶)
Matplotlib是Python最著名的绘图库,它提供了一整套和MATLAB类似的绘图API,非常适合交互式绘图。
☆ Matplotlib 的特点[¶](#☆ Matplotlib 的特点¶)
- 丰富的图表类型:线图、散点图、柱状图、饼图等
- 高度可定制:可以控制图表的每一个细节
- 多种输出格式:支持PNG、PDF、SVG等格式
- 与IPython兼容:支持在IPython环境中交互式绘图
五、三者的关系¶
1 层次依赖关系[¶](#1 层次依赖关系¶)
NumPy、Pandas 和 Matplotlib 三者构成了 Python 数据分析的完整技术栈,它们之间存在着清晰的层次依赖关系:
NumPy 是基础层
- 提供了高效的多维数组(ndarray)对象
- 是 Pandas 和 Matplotlib 的底层依赖
- 负责数值计算和数组操作
Pandas 是数据处理层
- 基于 NumPy 构建,使用 NumPy 数组作为底层存储
- 提供了更高级的数据结构(Series、DataFrame)
- 专注于数据清洗、整理和分析
Matplotlib 是可视化层
- 依赖于 NumPy 的数据结构
- 能够直接处理 Pandas 的数据对象
- 负责将数据转化为直观的图表
2 功能互补关系[¶](#2 功能互补关系¶)
三者各司其职,形成了完整的数据分析工作流:
NumPy - 数值计算引擎
- 核心功能:数学运算、线性代数、随机数生成
- 数据格式:ndarray 多维数组
- 优势:计算效率高,内存占用少
Pandas - 数据处理工具
- 核心功能:数据清洗、转换、聚合、分析
- 数据格式:Series(一维)、DataFrame(二维)
- 优势:数据操作便捷,支持缺失值处理
Matplotlib - 可视化平台
- 核心功能:图表绘制、图形定制、结果展示
- 输出形式:静态图片、交互式图表
- 优势:图表类型丰富,定制化程度高
3 代码示例[¶](#3 代码示例¶)
# 三者的典型工作流程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 注意:新版本需要指定 matplotlib 使用 TkAgg 作为图形后端来渲染和显示图表
import matplotlib
matplotlib.use('TkAgg')
# NumPy:数据生成和处理
data = np.random.randn(100, 3)
# Pandas:数据整理和分析
df = pd.DataFrame(data, columns=['A', 'B', 'C'])
summary = df.describe()
# Matplotlib:数据可视化
df.plot(kind='hist', alpha=0.5)
plt.show()NumPy 安装和导入[¶](#NumPy 安装和导入¶)
☆ 安装 NumPy[¶](#☆ 安装 NumPy¶)
# 使用 pip 安装
pip install numpy
# 使用 conda 安装
conda install numpy☆ 导入 NumPy[¶](#☆ 导入 NumPy¶)
import numpy as np # 惯例缩写为 np二、NumPy 核心数据结构:ndarray[¶](#二、NumPy 核心数据结构:ndarray¶)
☆ 创建数组[¶](#☆ 创建数组¶)
import numpy as np
# 从列表创建数组
arr1 = np.array([1, 2, 3, 4, 5])
print("一维数组:", arr1)
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print("二维数组:\n", arr2)
# 创建特殊数组
zeros_arr = np.zeros((3, 4)) # 全0数组
print("全0数组:\n", zeros_arr)
ones_arr = np.ones((2, 3)) # 全1数组
print("全1数组:\n", ones_arr)
# 创建序列数组
range_arr = np.arange(0, 10, 2) # 0到10,步长为2
print("范围数组:", range_arr)
linspace_arr = np.linspace(0, 1, 5) # 0到1,等分5份
print("等分数组:", linspace_arr)
# 创建随机数组
random_arr = np.random.rand(3, 3) # 0-1均匀分布
print("随机数组:\n", random_arr)
normal_arr = np.random.randn(3, 3) # 标准正态分布
print("正态分布数组:\n", normal_arr)☆ 数组属性[¶](#☆ 数组属性¶)
import numpy as np
# 创建示例数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("数组:", arr)
print("数组维度:", arr.ndim) # 维度数
print("数组形状:", arr.shape) # 形状 (行数, 列数)
print("数组大小:", arr.size) # 元素总数
print("数据类型:", arr.dtype) # 数据类型三、NumPy 数组操作[¶](#三、NumPy 数组操作¶)
☆ 数组索引和切片[¶](#☆ 数组索引和切片¶)
import numpy as np
# 创建示例数组
arr = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
print("原始数组:\n", arr)
# 索引
print("第一个元素:", arr[0, 0]) # 第一行第一列
print("最后一行:", arr[-1]) # 最后一行
print("第二列:", arr[:, 1]) # 所有行的第二列
# 切片
print("前两行:\n", arr[:2]) # 前两行
print("前两行的前两列:\n", arr[:2, :2]) # 前两行前两列
print("每隔一个元素取一个:\n", arr[::2, ::2]) # 行和列都隔一个取一个
# 布尔索引
bool_idx = arr > 5
print("大于5的元素:\n", arr[bool_idx])
print("直接布尔索引:\n", arr[arr > 5])☆ 数组形状操作[¶](#☆ 数组形状操作¶)
import numpy as np
arr = np.arange(12)
print("原始一维数组:", arr)
# 重塑形状
arr_2d = arr.reshape(3, 4)
print("重塑为3x4数组:\n", arr_2d)
# 转置
arr_t = arr_2d.T
print("转置数组:\n", arr_t)
# 展平数组
arr_flat = arr_2d.flatten()
print("展平数组:", arr_flat)
# 调整大小
arr_resized = np.resize(arr, (3, 5))
print("调整大小:\n", arr_resized)四、NumPy 数学运算[¶](#四、NumPy 数学运算¶)
☆ 基本运算[¶](#☆ 基本运算¶)
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
print("数组a:", a)
print("数组b:", b)
# 算术运算
print("加法:", a + b)
print("减法:", a - b)
print("乘法:", a * b)
print("除法:", a / b)
print("幂运算:", a ** 2)
# 比较运算
print("大于比较:", a > 2)
print("等于比较:", a == b)
# 矩阵乘法
matrix_a = np.array([[1, 2], [3, 4]])
matrix_b = np.array([[5, 6], [7, 8]])
print("矩阵乘法:\n", np.dot(matrix_a, matrix_b))☆ 统计运算[¶](#☆ 统计运算¶)
import numpy as np
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print("数组:\n", arr)
print("总和:", np.sum(arr))
print("每列总和:", np.sum(arr, axis=0)) # 沿列方向
print("每行总和:", np.sum(arr, axis=1)) # 沿行方向
print("平均值:", np.mean(arr))
print("标准差:", np.std(arr))
print("方差:", np.var(arr))
print("最小值:", np.min(arr))
print("最大值:", np.max(arr))
print("最小值索引:", np.argmin(arr))
print("最大值索引:", np.argmax(arr))五、NumPy 广播机制[¶](#五、NumPy 广播机制¶)
import numpy as np
# 广播示例
a = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
b = np.array([10, 20, 30])
print("数组a:\n", a)
print("数组b:", b)
print("广播加法:\n", a + b) # b被广播到a的每一行
# 另一个广播例子
c = np.array([[1], [2], [3]])
print("数组c:\n", c)
print("广播乘法:\n", a * c) # c被广播到a的每一列Pandas
一、Pandas 安装和导入[¶](#一、Pandas 安装和导入¶)
☆ 安装 Pandas[¶](#☆ 安装 Pandas¶)
# 使用 pip 安装
pip install pandas
# 使用 conda 安装
conda install pandas☆ 导入 Pandas[¶](#☆ 导入 Pandas¶)
import pandas as pd # 惯例缩写为 pd二、Pandas 核心数据结构[¶](#二、Pandas 核心数据结构¶)
☆ Series:一维带标签数组[¶](#☆ Series:一维带标签数组¶)
import pandas as pd
import numpy as np
# 从列表创建Series
s1 = pd.Series([1, 3, 5, np.nan, 6, 8])
print("从列表创建的Series:")
print(s1)
# 从字典创建Series
s2 = pd.Series({'a': 1, 'b': 2, 'c': 3})
print("\n从字典创建的Series:")
print(s2)
# 指定索引
s3 = pd.Series([10, 20, 30], index=['x', 'y', 'z'])
print("\n指定索引的Series:")
print(s3)
# Series操作
print("\nSeries操作:")
print("值:", s3.values)
print("索引:", s3.index)☆ DataFrame:二维表格数据结构[¶](#☆ DataFrame:二维表格数据结构¶)
import pandas as pd
import numpy as np
# 从字典创建DataFrame
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 35, 28],
'城市': ['北京', '上海', '广州', '深圳'],
'工资': [5000, 7000, 6000, 8000]
}
df = pd.DataFrame(data)
print("创建的DataFrame:")
print(df)
# 从列表创建DataFrame
data_list = [
['张三', 25, '北京', 5000],
['李四', 30, '上海', 7000],
['王五', 35, '广州', 6000],
['赵六', 28, '深圳', 8000]
]
df2 = pd.DataFrame(data_list, columns=['姓名', '年龄', '城市', '工资'])
print("\n从列表创建的DataFrame:")
print(df2)
# 查看DataFrame基本信息
print("\nDataFrame基本信息:")
print("形状:", df.shape)
print("列名:", df.columns)
print("索引:", df.index)
print("数据类型:\n", df.dtypes)三、DataFrame 基本操作[¶](#三、DataFrame 基本操作¶)
☆ 数据查看和选择[¶](#☆ 数据查看和选择¶)
import pandas as pd
import numpy as np
# 创建示例DataFrame
data_list = [
['张三', 25, '北京', 5000],
['李四', 30, '上海', 7000],
['王五', 35, '广州', 6000],
['赵六', 28, '深圳', 8000]
]
df = pd.DataFrame(data_list, columns=['姓名', '年龄', '城市', '工资'], index=["s1", "s2", "s3", "s4"])
print("\n从列表创建的DataFrame:")
print(df)
# 查看数据
print("\n前3行:")
print(df.head(3))
print("\n后2行:")
print(df.tail(2))
print("\n描述性统计:")
print(df.describe())
# 选择数据
print("\n选择单列:")
print(df['姓名'])
print("\n选择多列:")
print(df[['姓名', '年龄']])
print("\n使用loc选择(标签索引):")
print(df.loc['s1']) # 选择一行
print(df.loc[['s1', 's3']]) # 选择多行
print(df.loc['s1':'s3']) # 切片选择
print("\n使用iloc选择(位置索引):")
print(df.iloc[0]) # 第一行
print(df.iloc[[0, 2]]) # 选择多行
print(df.iloc[0:3]) # 切片选择☆ 数据筛选和过滤[¶](#☆ 数据筛选和过滤¶)
import pandas as pd
import numpy as np
# 创建示例数据
df = pd.DataFrame({
'姓名': ['张三', '李四', '王五', '赵六', '钱七'],
'年龄': [25, 30, 35, 28, 32],
'部门': ['技术部', '销售部', '技术部', '人事部', '销售部'],
'工资': [5000, 7000, 6000, 5500, 7500]
})
print("原始数据:")
print(df)
# 条件筛选
print("\n年龄大于30的员工:")
print(df[df['年龄'] > 30])
print("\n技术部的员工:")
print(df[df['部门'] == '技术部'])
print("\n使用query方法筛选:")
print(df.query('年龄 > 28 and 工资 < 7000'))
# 排序
print("\n按工资降序排序:")
print(df.sort_values('工资', ascending=False))
print("\n按多列排序(部门升序,工资降序):")
print(df.sort_values(['部门', '工资'], ascending=[True, False]))四、数据处理和清洗¶
☆ 处理缺失值[¶](#☆ 处理缺失值¶)
已知数据如下:
A,B,C
1.0,5.0,9
2.0,,10
,,11
4.0,8.0,12
,,缺失值处理代码如下:
import pandas as pd
import numpy as np
# 读取包含缺失值的数据
df = pd.read_csv("清洗数据.csv", sep=",")
print("原始数据(包含缺失值):")
print(df)
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum())
print("\n非缺失值统计:")
print(df.notnull().sum())
# 删除缺失值
print("\n删除包含缺失值的行:")
print(df.dropna())
print("\n删除全部为缺失值的列:")
print(df.dropna(how='all'))
# 填充缺失值
print("\n用指定值填充缺失值:")
print(df.fillna(0))
print("\n用均值填充:")
print(df.fillna(df.mean()))☆ 数据转换[¶](#☆ 数据转换¶)
已知数据:
产品,销售额,地区
A,100,北京
B,200,上海
C,150,广州
A,300,北京
B,250,上海
C,180,广州分组聚合代码如下:
import pandas as pd
# 创建示例数据
df = pd.read_csv("分组聚合数据.csv", sep=",")
print("原始数据:")
print(df)
# 分组聚合
print("\n按产品分组计算总销售额:")
print(df.groupby('产品')['销售额'].sum())
print("\n按产品和地区分组计算统计量:")
print(df.groupby(['产品', '地区'])['销售额'].agg(['sum', 'mean']))
# 数据透视表
print("\n数据透视表:")
pivot_df = df.pivot_table(index='产品', values="销售额", aggfunc='sum')
print(pivot_df)
print("\n数据透视表:")
pivot_df = df.pivot_table(index=['产品', '地区'], values="销售额", aggfunc=['sum', 'mean'])
print(pivot_df)Matplotlib
一、Matplotlib 安装和导入[¶](#一、Matplotlib 安装和导入¶)
☆ 安装 Matplotlib[¶](#☆ 安装 Matplotlib¶)
# 使用 pip 安装
pip install matplotlib
# 使用 conda 安装
conda install matplotlib☆ 导入 Matplotlib[¶](#☆ 导入 Matplotlib¶)
import matplotlib.pyplot as plt # 惯例缩写为 plt二、基本绘图功能¶
折线图¶
import numpy as np
import matplotlib.pyplot as plt
# 注意:新版本需要指定 matplotlib 使用 TkAgg 作为图形后端来渲染和显示图表
import matplotlib
matplotlib.use('TkAgg')
# 注意:中文显示需要额外设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 创建数据
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 1, 5, 3])
# 绘制折线图
plt.figure(figsize=(8, 5))
plt.plot(x, y,color='blue')
# 添加标题和标签
plt.title("折线图示例")
plt.xlabel("X轴")
plt.ylabel("Y轴")
# 显示网格
plt.grid()
# 显示图表
plt.show()☆ 散点图[¶](#☆ 散点图¶)
import numpy as np
import matplotlib.pyplot as plt
# 注意:新版本需要指定 matplotlib 使用 TkAgg 作为图形后端来渲染和显示图表
import matplotlib
matplotlib.use('TkAgg')
# 注意:中文显示需要额外设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 创建数据
np.random.seed(42) # 设置随机种子,保证结果可重复
x = np.random.randn(50)
y = x * 2 + np.random.randn(50) * 0.8 # 添加一些随机噪声
# 绘制散点图
plt.figure(figsize=(8, 5))
plt.scatter(x, y, color='red')
# 添加标题和标签
plt.title("散点图示例")
plt.xlabel("X值")
plt.ylabel("Y值")
# 显示网格
plt.grid()
# 显示图表
plt.show()