目录
[二、主流索引数据结构演进:为什么最终选 B + 树?](#二、主流索引数据结构演进:为什么最终选 B + 树?)
[1. 二叉树:基础但存在致命缺陷](#1. 二叉树:基础但存在致命缺陷)
[2. 红黑树(平衡二叉树):解决失衡,但不适合磁盘存储](#2. 红黑树(平衡二叉树):解决失衡,但不适合磁盘存储)
[3. B 树:多叉平衡树,大幅降低树高](#3. B 树:多叉平衡树,大幅降低树高)
[4. B + 树:B 树的终极优化,MySQL 的最终选择](#4. B + 树:B 树的终极优化,MySQL 的最终选择)
[B 树 vs B + 树 核心区别对比](#B 树 vs B + 树 核心区别对比)
[B + 树作为 MySQL 索引的核心优势](#B + 树作为 MySQL 索引的核心优势)
[三、Hash 索引:适用场景与局限性](#三、Hash 索引:适用场景与局限性)
[四、聚集索引 vs 非聚集索引:InnoDB 与 MyISAM 的核心差异](#四、聚集索引 vs 非聚集索引:InnoDB 与 MyISAM 的核心差异)
[1. 存储结构基础](#1. 存储结构基础)
[2. 核心定义与结构](#2. 核心定义与结构)
[聚集索引(InnoDB 主键索引)](#聚集索引(InnoDB 主键索引))
[非聚集索引(MyISAM 索引、InnoDB 二级索引)](#非聚集索引(MyISAM 索引、InnoDB 二级索引))
[3. 核心区别对比表](#3. 核心区别对比表)
[4. InnoDB 的隐藏主键机制](#4. InnoDB 的隐藏主键机制)
[1. 为什么 MySQL 不用红黑树 / 二叉树做索引?](#1. 为什么 MySQL 不用红黑树 / 二叉树做索引?)
[2. 为什么 B + 树比 B 树更适合做索引?](#2. 为什么 B + 树比 B 树更适合做索引?)
[3. InnoDB 为什么建议用自增主键?](#3. InnoDB 为什么建议用自增主键?)
[4. 什么是回表?如何避免?](#4. 什么是回表?如何避免?)
[5. Hash 索引为什么不适合做 MySQL 默认索引?](#5. Hash 索引为什么不适合做 MySQL 默认索引?)
[自适应 Hash 索引(InnoDB)](#自适应 Hash 索引(InnoDB))
一、索引
1、什么是索引
索引 是一种帮助数据库高效获取数据的数据结构,类似于书籍的目录,可以快速定位到需要查询的数据行,避免全表扫描,提升查询效率。能够实现快速定位数据的一种存储结构,其设计思想是以空间换时间
索引是帮助 MySQL高效获取数据 的排好序的 数据结构。数据库索引设计的核心矛盾,本质是磁盘 I/O 性能瓶颈:
- 磁盘随机 I/O 的速度远慢于内存,一次磁盘 I/O 耗时约 10ms,百万级数据全表扫描需要数万次 I/O,完全不可用
- 索引的核心目标:尽可能减少磁盘 I/O 次数,通过优化数据结构,让树的高度尽可能低,从而减少查询时的磁盘访问次数
2、索引的种类
在MySQL中索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。常见的索引分类如下:
-
按数据结构分类:B+tree索引**(MySQL默认索引)**、Hash索引 、Full-text索引。
-
按物理存储分类:聚集索引、非聚集索引。
-
按字段特性分类:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(INDEX)、全文索引(FULLTEXT)。
-
按字段个数分类:单列索引、联合索引(也叫复合索引、组合索引)。
二、主流索引数据结构演进:为什么最终选 B + 树?
1. 二叉树:基础但存在致命缺陷
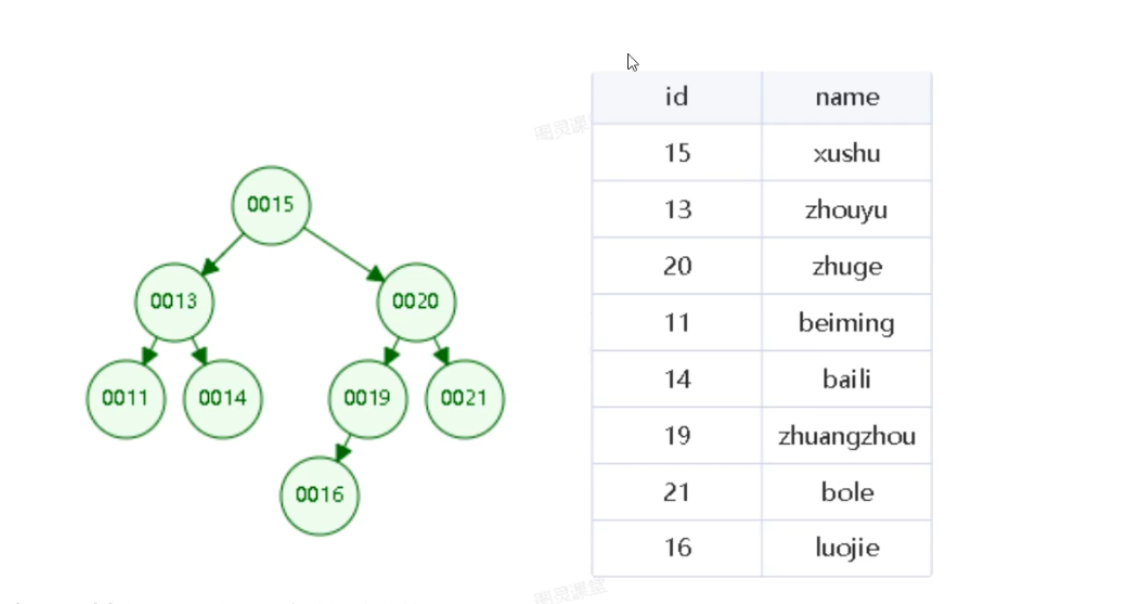
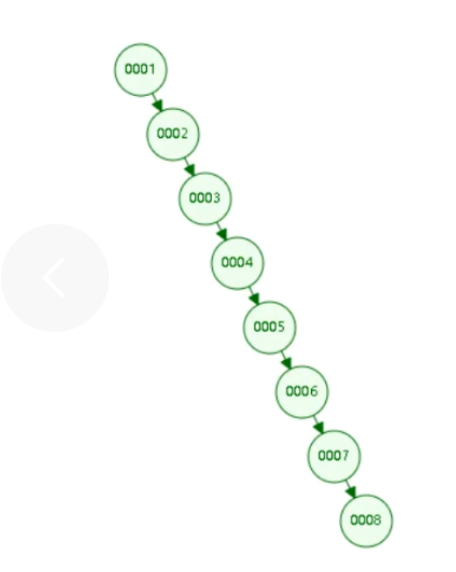
二叉树的特点:每个节点最多 2 个子节点,遵循「左小右大」规则,数据随机时查询效率 O (logn)。致命问题 :如果数据有序插入 (比如自增 ID),二叉树会退化成链表结构,查询效率直接降到 O (n),完全无法用于大数据量场景。
2. 红黑树(平衡二叉树):解决失衡,但不适合磁盘存储
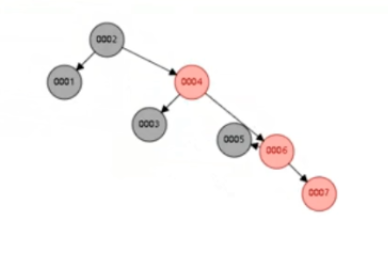
红黑树通过自旋平衡 机制,解决了二叉树退化成链表的问题,始终保持树的平衡,有序插入时性能远优于普通二叉树。核心缺陷:本质还是二叉树,数据量越大树高越高。比如百万级数据树高约 20,需要 20 次磁盘 I/O,依然无法满足性能要求。
3. B 树:多叉平衡树,大幅降低树高
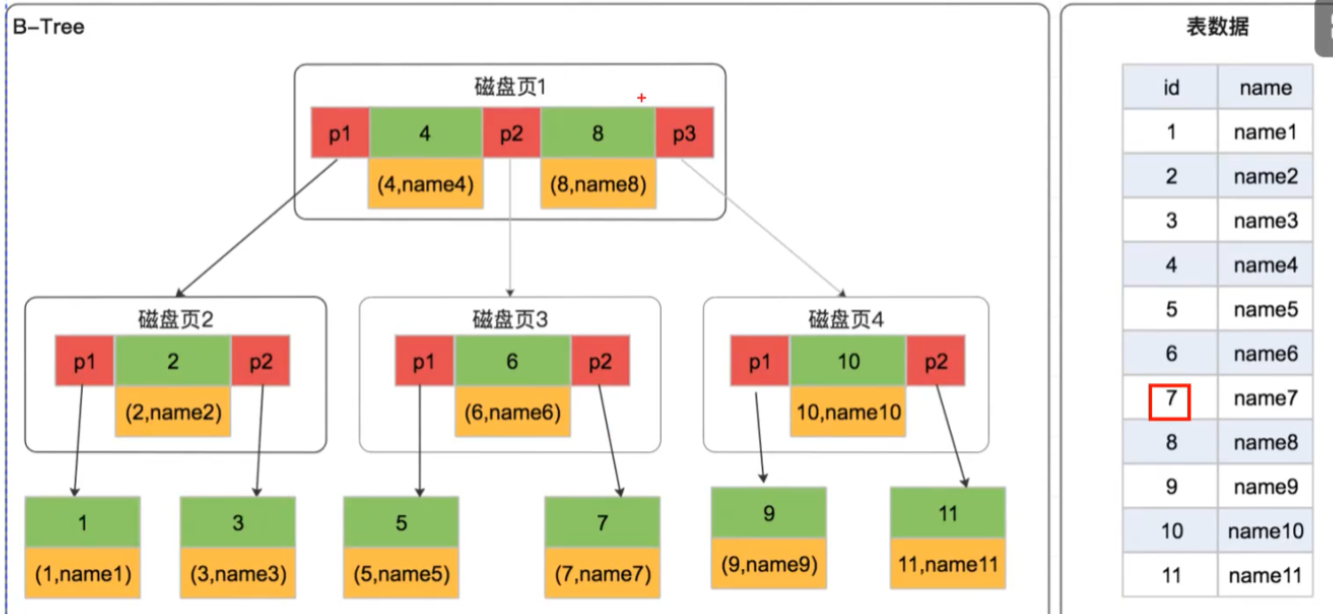
B 树是为磁盘存储设计的多叉平衡树,核心改进:
- 不再限制二叉结构,一个父节点允许 M 个子节点(M>2),一个节点可存储多个元素
- 所有节点(包括非叶子节点)都存储完整数据(键值 + 数据)
- 树高大幅降低,磁盘 I/O 次数显著减少
4. B + 树:B 树的终极优化,MySQL 的最终选择
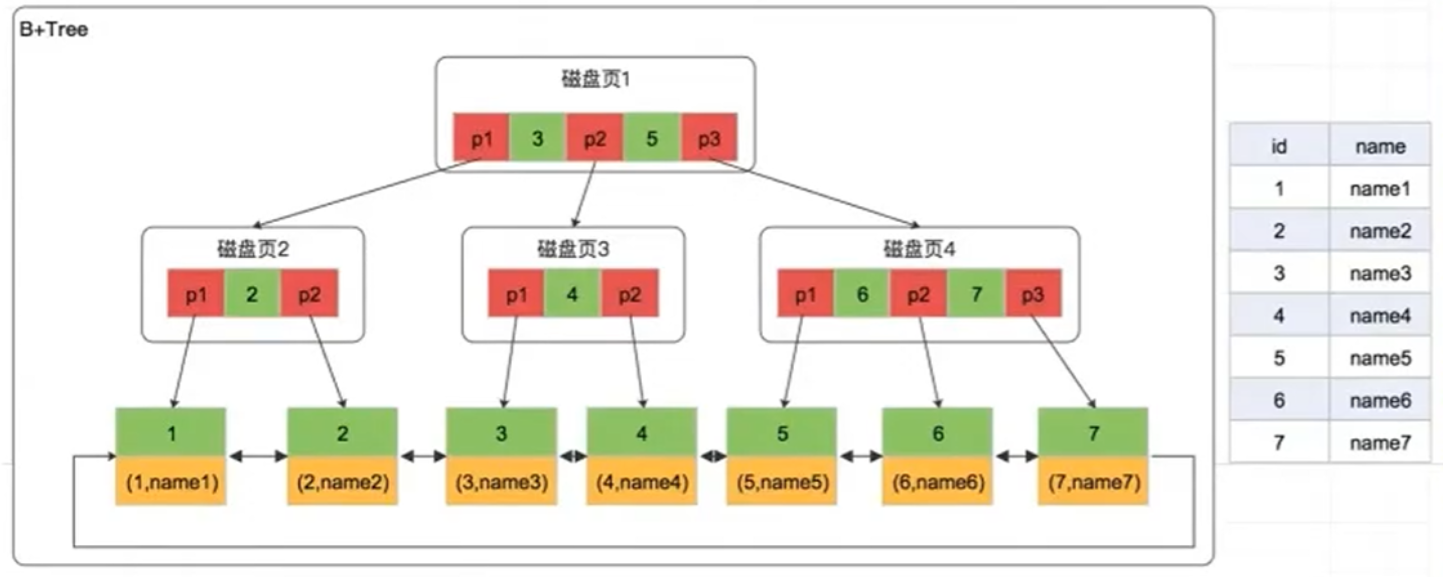
B + 树是 B 树的优化版本,完美适配数据库索引场景,核心特性:
- 非叶子节点仅存键值,不存数据:同样大小的磁盘页可存储更多键值,树更「矮胖」,磁盘 I/O 次数更少
- 所有数据都存储在叶子节点 :叶子节点按顺序排列,且通过双向链表串联
- 叶子节点数据有序:天然支持范围查询、排序、分组、去重
B 树 vs B + 树 核心区别对比
| 特性 | B 树 | B + 树 |
|---|---|---|
| 数据存储位置 | 所有节点都存数据 | 仅叶子节点存数据,非叶子节点只存索引 |
| 树高 | 相对更高 | 更矮更胖,磁盘 I/O 更少 |
| 范围查询 | 需中序遍历,效率低 | 叶子节点链表串联,直接遍历,效率极高 |
| 排序支持 | 弱支持 | 天然有序,完美支持升序 / 降序 |
| 全表扫描 | 需遍历所有节点 | 仅需遍历叶子节点链表 |
B + 树作为 MySQL 索引的核心优势
- 磁盘 I/O 次数更少:非叶子节点不存数据,单页可存更多键值,树高极低(百万级数据树高仅 3-4 层,最多 4 次磁盘 I/O)
- 范围查询性能拉满 :叶子节点有序且链表串联,
BETWEEN、ORDER BY、GROUP BY等操作无需回溯,直接遍历链表 - 排序操作高效:链表结构天然支持升序 / 降序遍历,无需额外排序
- 查询性能稳定:所有查询都必须走到叶子节点,查询时间复杂度稳定 O (logn),无波动
三、Hash 索引:适用场景与局限性
Hash 索引基于哈希表实现,核心原理:对索引列值做 Hash 计算,映射到哈希槽,槽中存储行指针,Hash 冲突时用链表解决。
核心特点:
✅ 优点 :等值查询(=、IN)效率极高,时间复杂度 O (1)❌ 致命缺点:
- 不支持范围查询 (
>、<、BETWEEN),因为哈希值无序 - 不支持排序、分组、模糊查询(
LIKE %xxx) - 存在 Hash 冲突,冲突严重时性能下降
- 无法使用覆盖索引
存储引擎支持情况:
- InnoDB :不支持显式创建 Hash 索引,仅支持自适应 Hash 索引 (自动为热点数据构建,无需手动干预),即使声明
USING HASH也会被忽略,实际仍用 B + 树 - Memory:默认 Hash 索引,支持显式创建
- MyISAM:不支持 Hash 索引
四、聚集索引 vs 非聚集索引:InnoDB 与 MyISAM 的核心差异
1. 存储结构基础
- InnoDB :索引与数据存储在同一个
.ibd文件中,是聚集索引 - MyISAM :数据(
.MYD)、索引(.MYI)、表结构(.frm)完全分离,是非聚集索引
2. 核心定义与结构
聚集索引(InnoDB 主键索引)
- 定义 :索引的叶子节点直接存储完整行数据,索引与数据物理存储在一起
- 特点 :
- 一个表只能有一个聚集索引(通常是主键)
- 数据物理存储顺序与索引顺序完全一致
- 主键查询效率极高,直接通过索引定位数据
- 结构:
非聚集索引(MyISAM 索引、InnoDB 二级索引)
- 定义 :索引的叶子节点存储数据行的地址(指针),不存储完整数据
- 特点 :
- 一个表可以有多个非聚集索引
- 索引顺序与数据物理存储顺序无关
- 查询时需要先查索引拿到地址,再回表查数据(回表操作)
- 结构:
3. 核心区别对比表
| 维度 | 聚集索引(InnoDB) | 非聚集索引(MyISAM/InnoDB 二级索引) |
|---|---|---|
| 数据存储位置 | 索引叶子节点存完整行数据 | 索引叶子节点存数据行地址 / 主键 |
| 表中数量 | 最多 1 个 | 可多个 |
| 数据存储顺序 | 与索引顺序一致 | 与索引顺序无关 |
| 主键查询效率 | 极高(无需回表) | 需回表,效率低于聚集索引 |
| 范围查询效率 | 极高(叶子节点有序) | 需回表,效率较低 |
| 回表操作 | 无 | 必须回表(InnoDB 二级索引) |
| 存储文件 | .ibd(索引 + 数据一体) |
.MYD(数据)+.MYI(索引)分离 |
4. InnoDB 的隐藏主键机制
问题 :如果表没有显式主键,InnoDB 还会创建 B + 树吗?答案:会!InnoDB 强制要求每个表必须有聚集索引:
- 有显式主键:用主键作为聚集索引
- 无主键:选第一个非空唯一索引作为聚集索引
- 无合适唯一索引:自动生成一个 6 字节的隐藏 ROWID ,用其构建 B + 树聚集索引因此,InnoDB 中所有表都一定有 B + 树结构的聚集索引,即使你没建主键。
五、高频面试题深度解答
1. 为什么 MySQL 不用红黑树 / 二叉树做索引?
- 红黑树本质是二叉树,数据量越大树高越高,磁盘 I/O 次数过多
- 有序插入时二叉树退化成链表,查询效率 O (n),完全无法用于生产环境
- B + 树通过多叉结构大幅降低树高,磁盘 I/O 次数仅为红黑树的 1/5 甚至更少
2. 为什么 B + 树比 B 树更适合做索引?
- B + 树非叶子节点不存数据,单页可存更多键值,树更矮,磁盘 I/O 更少
- B + 树叶子节点链表串联,范围查询、排序、分组性能碾压 B 树
- B + 树所有查询都走到叶子节点,性能稳定;B 树查询可能在非叶子节点结束,性能波动大
3. InnoDB 为什么建议用自增主键?
- 自增主键是有序的,插入数据时 B + 树叶子节点顺序追加,无页分裂,性能极高
- 自增主键占用空间小(int/bigint),非叶子节点可存储更多键值,树更矮
- 若用无序主键(如 UUID),插入时会频繁页分裂,导致性能骤降,产生碎片
4. 什么是回表?如何避免?
- 回表:InnoDB 二级索引查询时,先通过二级索引拿到主键,再用主键去聚集索引查完整数据的过程
- 避免回表 :使用覆盖索引 ,即查询的列全部包含在索引中,无需回表例:
SELECT id,name FROM user WHERE name='张三';,给(name,id)建联合索引,直接从索引中拿到数据,无需回表
5. Hash 索引为什么不适合做 MySQL 默认索引?
- 不支持范围查询、排序、分组,无法满足业务绝大多数查询场景
- InnoDB 不支持显式 Hash 索引,仅 Memory 引擎支持,适用场景极窄
- 存在 Hash 冲突,冲突严重时性能下降,稳定性不如 B + 树
六、总结与最佳实践
核心结论
- MySQL InnoDB 默认索引结构是 B + 树,这是磁盘存储场景下的最优解
- B + 树的核心优势:矮胖树减少磁盘 I/O、叶子节点链表支持高效范围查询
- 聚集索引与非聚集索引的本质差异:数据是否与索引存储在一起
- Hash 索引仅适用于等值查询场景,无法替代 B + 树
- InnoDB 必须有聚集索引,无显式主键时自动生成隐藏 ROWID
索引设计最佳实践
- 优先用自增 int/bigint作为主键,避免 UUID 等无序主键
- 为高频查询条件建索引,避免冗余索引
- 联合索引遵循最左前缀原则,将区分度高的列放在左边
- 用覆盖索引避免回表,提升查询性能
- 避免在低区分度列(如性别、状态)建索引
- 定期维护索引,删除无用索引,减少写入开销
七、扩展知识
自适应 Hash 索引(InnoDB)
InnoDB 会自动监控索引的使用情况,为热点数据页构建 Hash 索引,加速等值查询,无需手动配置,完全自动管理。
全文索引
针对大文本字段的特殊索引,用于MATCH AGAINST模糊查询,底层基于倒排索引,不属于 B + 树 / Hash 索引范畴。
空间索引
用于地理空间数据(如经纬度)的索引,底层基于 R 树,适用于 GIS 场景。